 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScientific Theory of a Black-Box: A Life Cycle-Scale XAI Framework Based on Constructive Empiricism
Feb 02, 2026Explainable AI (XAI) offers a growing number of algorithms that aim to answer specific questions about black-box models. What is missing is a principled way to consolidate explanatory information about a fixed black-box model into a persistent, auditable artefact, that accompanies the black-box throughout its life cycle. We address this gap by introducing the notion of a scientific theory of a black (SToBB). Grounded in Constructive Empiricism, a SToBB fulfils three obligations: (i) empirical adequacy with respect to all available observations of black-box behaviour, (ii) adaptability via explicit update commitments that restore adequacy when new observations arrive, and (iii) auditability through transparent documentation of assumptions, construction choices, and update behaviour. We operationalise these obligations as a general framework that specifies an extensible observation base, a traceable hypothesis class, algorithmic components for construction and revision, and documentation sufficient for third-party assessment. Explanations for concrete stakeholder needs are then obtained by querying the maintained record through interfaces, rather than by producing isolated method outputs. As a proof of concept, we instantiate a complete SToBB for a neural-network classifier on a tabular task and introduce the Constructive Box Theoriser (CoBoT) algorithm, an online procedure that constructs and maintains an empirically adequate rule-based surrogate as observations accumulate. Together, these contributions position SToBBs as a life cycle-scale, inspectable point of reference that supports consistent, reusable analyses and systematic external scrutiny.
Improving Compactness and Reducing Ambiguity of CFIRE Rule-Based Explanations
Jan 07, 2026Models trained on tabular data are widely used in sensitive domains, increasing the demand for explanation methods to meet transparency needs. CFIRE is a recent algorithm in this domain that constructs compact surrogate rule models from local explanations. While effective, CFIRE may assign rules associated with different classes to the same sample, introducing ambiguity. We investigate this ambiguity and propose a post-hoc pruning strategy that removes rules with low contribution or conflicting coverage, yielding smaller and less ambiguous models while preserving fidelity. Experiments across multiple datasets confirm these improvements with minimal impact on predictive performance.
Four Quadrants of Difficulty: A Simple Categorisation and its Limits
Jan 04, 2026Curriculum Learning (CL) aims to improve the outcome of model training by estimating the difficulty of samples and scheduling them accordingly. In NLP, difficulty is commonly approximated using task-agnostic linguistic heuristics or human intuition, implicitly assuming that these signals correlate with what neural models find difficult to learn. We propose a four-quadrant categorisation of difficulty signals -- human vs. model and task-agnostic vs. task-dependent -- and systematically analyse their interactions on a natural language understanding dataset. We find that task-agnostic features behave largely independently and that only task-dependent features align. These findings challenge common CL intuitions and highlight the need for lightweight, task-dependent difficulty estimators that better reflect model learning behaviour.
INTELLECT-3: Technical Report
Dec 18, 2025We present INTELLECT-3, a 106B-parameter Mixture-of-Experts model (12B active) trained with large-scale reinforcement learning on our end-to-end RL infrastructure stack. INTELLECT-3 achieves state of the art performance for its size across math, code, science and reasoning benchmarks, outperforming many larger frontier models. We open-source the model together with the full infrastructure stack used to create it, including RL frameworks, complete recipe, and a wide collection of environments, built with the verifiers library, for training and evaluation from our Environments Hub community platform. Built for this effort, we introduce prime-rl, an open framework for large-scale asynchronous reinforcement learning, which scales seamlessly from a single node to thousands of GPUs, and is tailored for agentic RL with first-class support for multi-turn interactions and tool use. Using this stack, we run both SFT and RL training on top of the GLM-4.5-Air-Base model, scaling RL training up to 512 H200s with high training efficiency.
Beyond Shallow Heuristics: Leveraging Human Intuition for Curriculum Learning
Aug 27, 2025Curriculum learning (CL) aims to improve training by presenting data from "easy" to "hard", yet defining and measuring linguistic difficulty remains an open challenge. We investigate whether human-curated simple language can serve as an effective signal for CL. Using the article-level labels from the Simple Wikipedia corpus, we compare label-based curricula to competence-based strategies relying on shallow heuristics. Our experiments with a BERT-tiny model show that adding simple data alone yields no clear benefit. However, structuring it via a curriculum -- especially when introduced first -- consistently improves perplexity, particularly on simple language. In contrast, competence-based curricula lead to no consistent gains over random ordering, probably because they fail to effectively separate the two classes. Our results suggest that human intuition about linguistic difficulty can guide CL for language model pre-training.
Immersive Explainability: Visualizing Robot Navigation Decisions through XAI Semantic Scene Projections in Virtual Reality
Apr 01, 2025End-to-end robot policies achieve high performance through neural networks trained via reinforcement learning (RL). Yet, their black box nature and abstract reasoning pose challenges for human-robot interaction (HRI), because humans may experience difficulty in understanding and predicting the robot's navigation decisions, hindering trust development. We present a virtual reality (VR) interface that visualizes explainable AI (XAI) outputs and the robot's lidar perception to support intuitive interpretation of RL-based navigation behavior. By visually highlighting objects based on their attribution scores, the interface grounds abstract policy explanations in the scene context. This XAI visualization bridges the gap between obscure numerical XAI attribution scores and a human-centric semantic level of explanation. A within-subjects study with 24 participants evaluated the effectiveness of our interface for four visualization conditions combining XAI and lidar. Participants ranked scene objects across navigation scenarios based on their importance to the robot, followed by a questionnaire assessing subjective understanding and predictability. Results show that semantic projection of attributions significantly enhances non-expert users' objective understanding and subjective awareness of robot behavior. In addition, lidar visualization further improves perceived predictability, underscoring the value of integrating XAI and sensor for transparent, trustworthy HRI.
CFIRE: A General Method for Combining Local Explanations
Apr 01, 2025



We propose a novel eXplainable AI algorithm to compute faithful, easy-to-understand, and complete global decision rules from local explanations for tabular data by combining XAI methods with closed frequent itemset mining. Our method can be used with any local explainer that indicates which dimensions are important for a given sample for a given black-box decision. This property allows our algorithm to choose among different local explainers, addressing the disagreement problem, \ie the observation that no single explanation method consistently outperforms others across models and datasets. Unlike usual experimental methodology, our evaluation also accounts for the Rashomon effect in model explainability. To this end, we demonstrate the robustness of our approach in finding suitable rules for nearly all of the 700 black-box models we considered across 14 benchmark datasets. The results also show that our method exhibits improved runtime, high precision and F1-score while generating compact and complete rules.
An Empirical Evaluation of the Rashomon Effect in Explainable Machine Learning
Jun 29, 2023The Rashomon Effect describes the following phenomenon: for a given dataset there may exist many models with equally good performance but with different solution strategies. The Rashomon Effect has implications for Explainable Machine Learning, especially for the comparability of explanations. We provide a unified view on three different comparison scenarios and conduct a quantitative evaluation across different datasets, models, attribution methods, and metrics. We find that hyperparameter-tuning plays a role and that metric selection matters. Our results provide empirical support for previously anecdotal evidence and exhibit challenges for both scientists and practitioners.
Multi-level Geometric Optimization for Regularised Constrained Linear Inverse Problems
Jul 11, 2022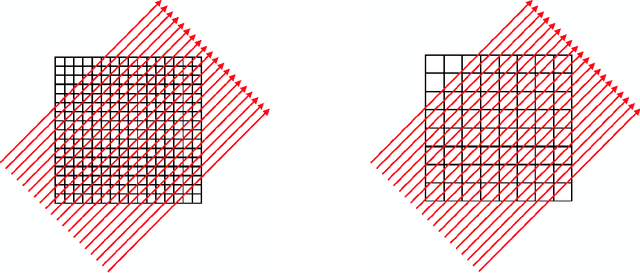

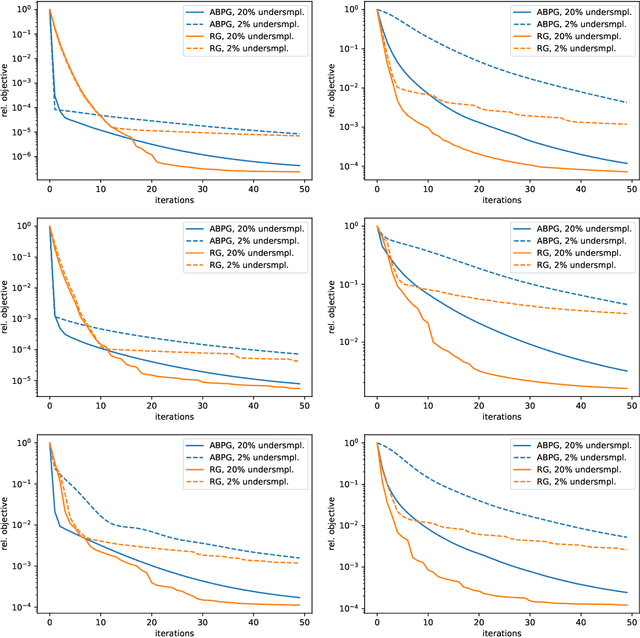
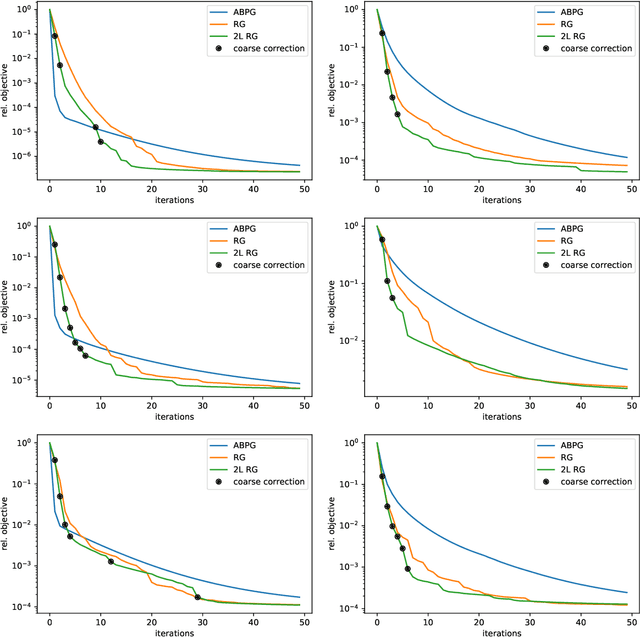
We present a geometric multi-level optimization approach that smoothly incorporates box constraints. Given a box constrained optimization problem, we consider a hierarchy of models with varying discretization levels. Finer models are accurate but expensive to compute, while coarser models are less accurate but cheaper to compute. When working at the fine level, multi-level optimisation computes the search direction based on a coarser model which speeds up updates at the fine level. Moreover, exploiting geometry induced by the hierarchy the feasibility of the updates is preserved. In particular, our approach extends classical components of multigrid methods like restriction and prolongation to the Riemannian structure of our constraints.
Explainable Machine Learning with Prior Knowledge: An Overview
May 21, 2021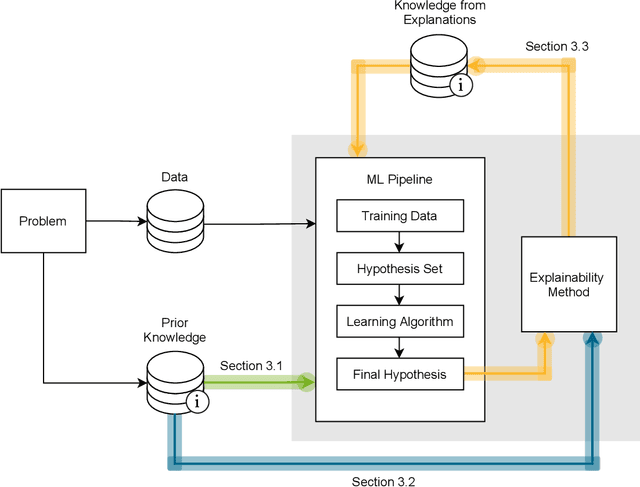

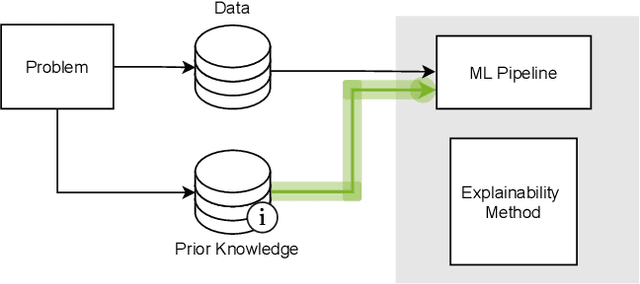
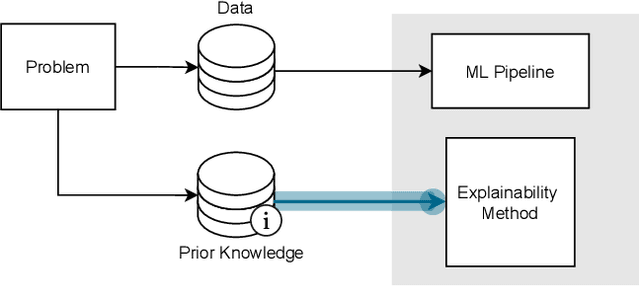
This survey presents an overview of integrating prior knowledge into machine learning systems in order to improve explainability. The complexity of machine learning models has elicited research to make them more explainable. However, most explainability methods cannot provide insight beyond the given data, requiring additional information about the context. We propose to harness prior knowledge to improve upon the explanation capabilities of machine learning models. In this paper, we present a categorization of current research into three main categories which either integrate knowledge into the machine learning pipeline, into the explainability method or derive knowledge from explanations. To classify the papers, we build upon the existing taxonomy of informed machine learning and extend it from the perspective of explainability. We conclude with open challenges and research directions.