 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Apr 14, 2026We describe the pre-training, post-training, and quantization of Nemotron 3 Super, a 120 billion (active 12 billion) parameter hybrid Mamba-Attention Mixture-of-Experts model. Nemotron 3 Super is the first model in the Nemotron 3 family to 1) be pre-trained in NVFP4, 2) leverage LatentMoE, a new Mixture-of-Experts architecture that optimizes for both accuracy per FLOP and accuracy per parameter, and 3) include MTP layers for inference acceleration through native speculative decoding. We pre-trained Nemotron 3 Super on 25 trillion tokens followed by post-training using supervised fine tuning (SFT) and reinforcement learning (RL). The final model supports up to 1M context length and achieves comparable accuracy on common benchmarks, while also achieving up to 2.2x and 7.5x higher inference throughput compared to GPT-OSS-120B and Qwen3.5-122B, respectively. Nemotron 3 Super datasets, along with the base, post-trained, and quantized checkpoints, are open-sourced on HuggingFace.
NVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model
Aug 21, 2025



We introduce Nemotron-Nano-9B-v2, a hybrid Mamba-Transformer language model designed to increase throughput for reasoning workloads while achieving state-of-the-art accuracy compared to similarly-sized models. Nemotron-Nano-9B-v2 builds on the Nemotron-H architecture, in which the majority of the self-attention layers in the common Transformer architecture are replaced with Mamba-2 layers, to achieve improved inference speed when generating the long thinking traces needed for reasoning. We create Nemotron-Nano-9B-v2 by first pre-training a 12-billion-parameter model (Nemotron-Nano-12B-v2-Base) on 20 trillion tokens using an FP8 training recipe. After aligning Nemotron-Nano-12B-v2-Base, we employ the Minitron strategy to compress and distill the model with the goal of enabling inference on up to 128k tokens on a single NVIDIA A10G GPU (22GiB of memory, bfloat16 precision). Compared to existing similarly-sized models (e.g., Qwen3-8B), we show that Nemotron-Nano-9B-v2 achieves on-par or better accuracy on reasoning benchmarks while achieving up to 6x higher inference throughput in reasoning settings like 8k input and 16k output tokens. We are releasing Nemotron-Nano-9B-v2, Nemotron-Nano12B-v2-Base, and Nemotron-Nano-9B-v2-Base checkpoints along with the majority of our pre- and post-training datasets on Hugging Face.
Nemotron-CC-Math: A 133 Billion-Token-Scale High Quality Math Pretraining Dataset
Aug 20, 2025Pretraining large language models (LLMs) on high-quality, structured data such as mathematics and code substantially enhances reasoning capabilities. However, existing math-focused datasets built from Common Crawl suffer from degraded quality due to brittle extraction heuristics, lossy HTML-to-text conversion, and the failure to reliably preserve mathematical structure. In this work, we introduce Nemotron-CC-Math, a large-scale, high-quality mathematical corpus constructed from Common Crawl using a novel, domain-agnostic pipeline specifically designed for robust scientific text extraction. Unlike previous efforts, our pipeline recovers math across various formats (e.g., MathJax, KaTeX, MathML) by leveraging layout-aware rendering with lynx and a targeted LLM-based cleaning stage. This approach preserves the structural integrity of equations and code blocks while removing boilerplate, standardizing notation into LaTeX representation, and correcting inconsistencies. We collected a large, high-quality math corpus, namely Nemotron-CC-Math-3+ (133B tokens) and Nemotron-CC-Math-4+ (52B tokens). Notably, Nemotron-CC-Math-4+ not only surpasses all prior open math datasets-including MegaMath, FineMath, and OpenWebMath-but also contains 5.5 times more tokens than FineMath-4+, which was previously the highest-quality math pretraining dataset. When used to pretrain a Nemotron-T 8B model, our corpus yields +4.8 to +12.6 gains on MATH and +4.6 to +14.3 gains on MBPP+ over strong baselines, while also improving general-domain performance on MMLU and MMLU-Stem. We present the first pipeline to reliably extract scientific content--including math--from noisy web-scale data, yielding measurable gains in math, code, and general reasoning, and setting a new state of the art among open math pretraining corpora. To support open-source efforts, we release our code and datasets.
TESS: Text-to-Text Self-Conditioned Simplex Diffusion
May 15, 2023



Diffusion models have emerged as a powerful paradigm for generation, obtaining strong performance in various domains with continuous-valued inputs. Despite the promises of fully non-autoregressive text generation, applying diffusion models to natural language remains challenging due to its discrete nature. In this work, we propose Text-to-text Self-conditioned Simplex Diffusion (TESS), a text diffusion model that is fully non-autoregressive, employs a new form of self-conditioning, and applies the diffusion process on the logit simplex space rather than the typical learned embedding space. Through extensive experiments on natural language understanding and generation tasks including summarization, text simplification, paraphrase generation, and question generation, we demonstrate that TESS outperforms state-of-the-art non-autoregressive models and is competitive with pretrained autoregressive sequence-to-sequence models.
PERFECT: Prompt-free and Efficient Few-shot Learning with Language Models
Apr 03, 2022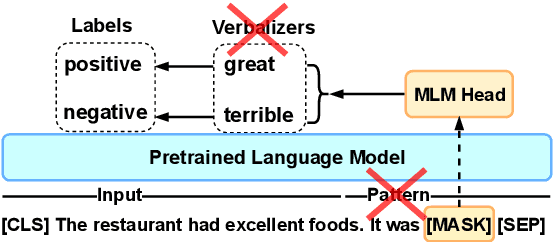
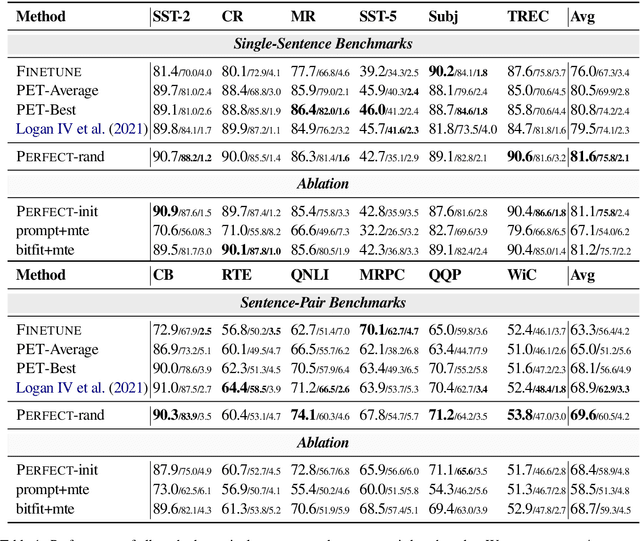
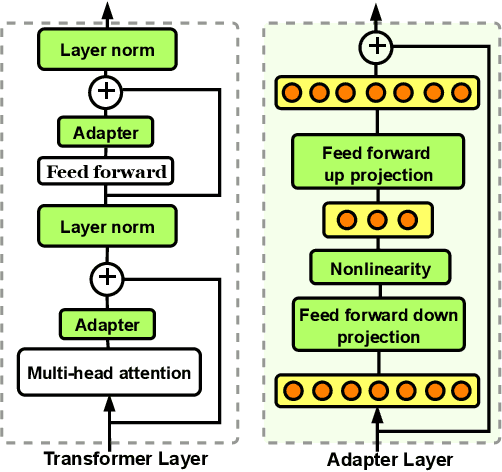
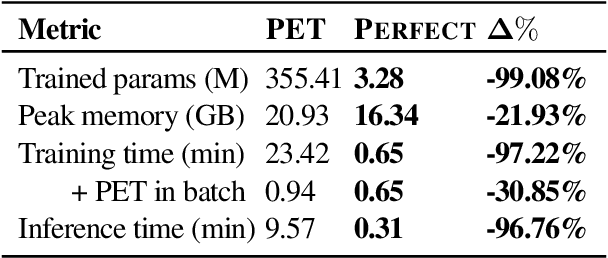
Current methods for few-shot fine-tuning of pretrained masked language models (PLMs) require carefully engineered prompts and verbalizers for each new task to convert examples into a cloze-format that the PLM can score. In this work, we propose PERFECT, a simple and efficient method for few-shot fine-tuning of PLMs without relying on any such handcrafting, which is highly effective given as few as 32 data points. PERFECT makes two key design choices: First, we show that manually engineered task prompts can be replaced with task-specific adapters that enable sample-efficient fine-tuning and reduce memory and storage costs by roughly factors of 5 and 100, respectively. Second, instead of using handcrafted verbalizers, we learn new multi-token label embeddings during fine-tuning, which are not tied to the model vocabulary and which allow us to avoid complex auto-regressive decoding. These embeddings are not only learnable from limited data but also enable nearly 100x faster training and inference. Experiments on a wide range of few-shot NLP tasks demonstrate that PERFECT, while being simple and efficient, also outperforms existing state-of-the-art few-shot learning methods. Our code is publicly available at https://github.com/rabeehk/perfect.
Variational Information Bottleneck for Effective Low-Resource Fine-Tuning
Jun 10, 2021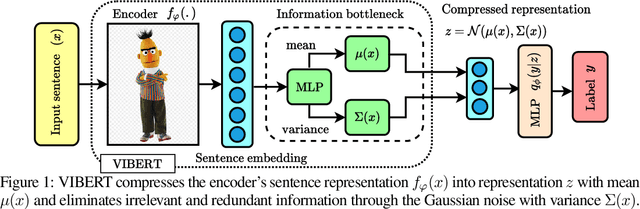
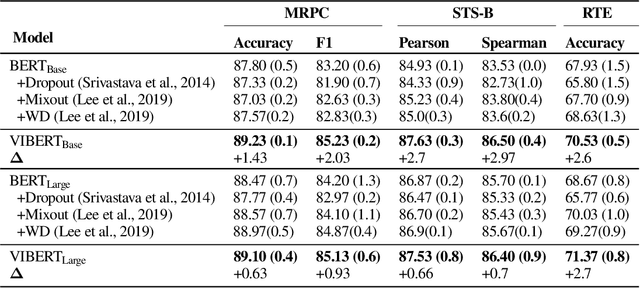
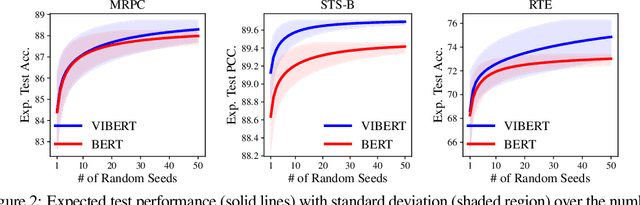
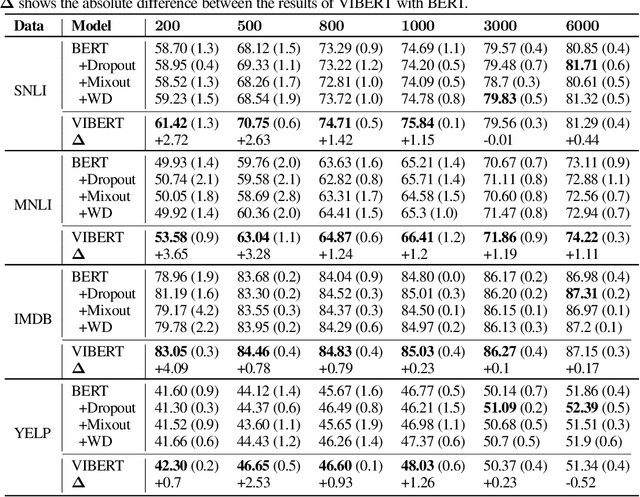
While large-scale pretrained language models have obtained impressive results when fine-tuned on a wide variety of tasks, they still often suffer from overfitting in low-resource scenarios. Since such models are general-purpose feature extractors, many of these features are inevitably irrelevant for a given target task. We propose to use Variational Information Bottleneck (VIB) to suppress irrelevant features when fine-tuning on low-resource target tasks, and show that our method successfully reduces overfitting. Moreover, we show that our VIB model finds sentence representations that are more robust to biases in natural language inference datasets, and thereby obtains better generalization to out-of-domain datasets. Evaluation on seven low-resource datasets in different tasks shows that our method significantly improves transfer learning in low-resource scenarios, surpassing prior work. Moreover, it improves generalization on 13 out of 15 out-of-domain natural language inference benchmarks. Our code is publicly available in https://github.com/rabeehk/vibert.
Compacter: Efficient Low-Rank Hypercomplex Adapter Layers
Jun 08, 2021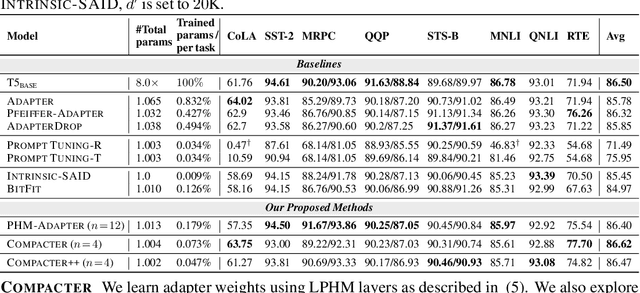
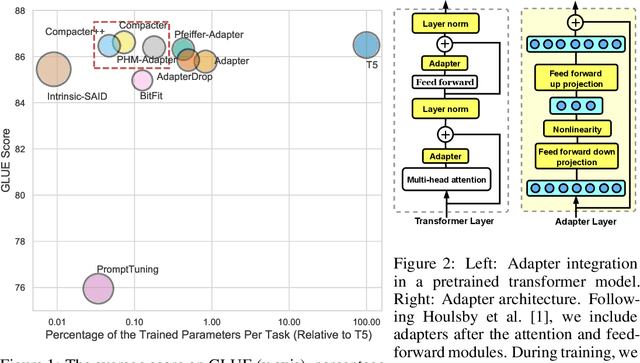
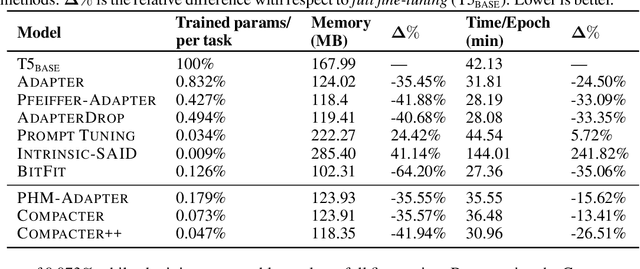
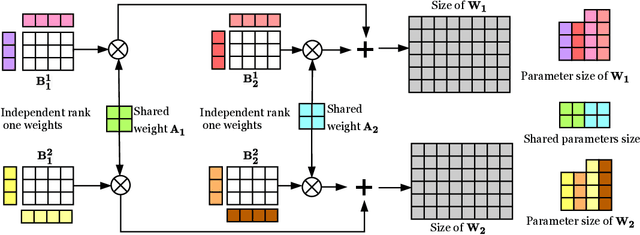
Adapting large-scale pretrained language models to downstream tasks via fine-tuning is the standard method for achieving state-of-the-art performance on NLP benchmarks. However, fine-tuning all weights of models with millions or billions of parameters is sample-inefficient, unstable in low-resource settings, and wasteful as it requires storing a separate copy of the model for each task. Recent work has developed parameter-efficient fine-tuning methods, but these approaches either still require a relatively large number of parameters or underperform standard fine-tuning. In this work, we propose Compacter, a method for fine-tuning large-scale language models with a better trade-off between task performance and the number of trainable parameters than prior work. Compacter accomplishes this by building on top of ideas from adapters, low-rank optimization, and parameterized hypercomplex multiplication layers. Specifically, Compacter inserts task-specific weight matrices into a pretrained model's weights, which are computed efficiently as a sum of Kronecker products between shared ``slow'' weights and ``fast'' rank-one matrices defined per Compacter layer. By only training 0.047% of a pretrained model's parameters, Compacter performs on par with standard fine-tuning on GLUE and outperforms fine-tuning in low-resource settings. Our code is publicly available in https://github.com/rabeehk/compacter/
Parameter-efficient Multi-task Fine-tuning for Transformers via Shared Hypernetworks
Jun 08, 2021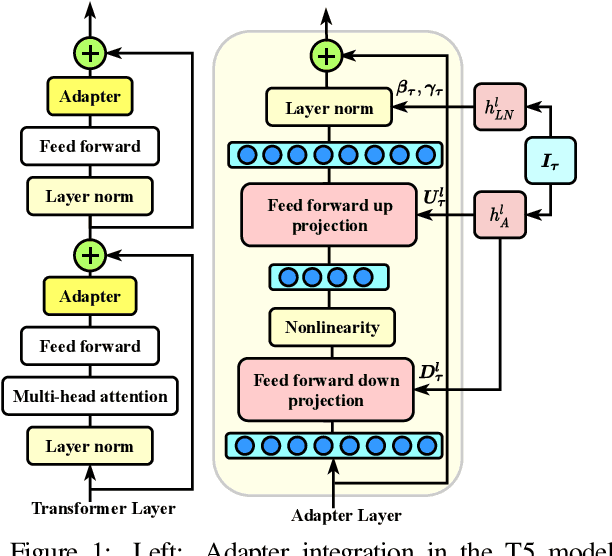
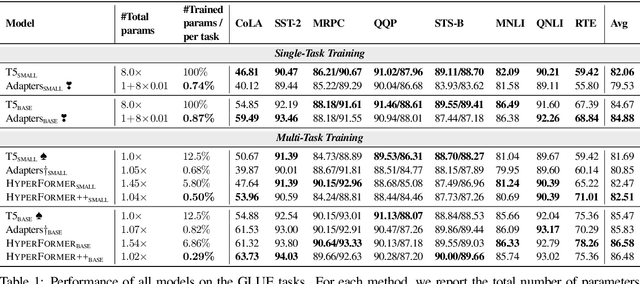
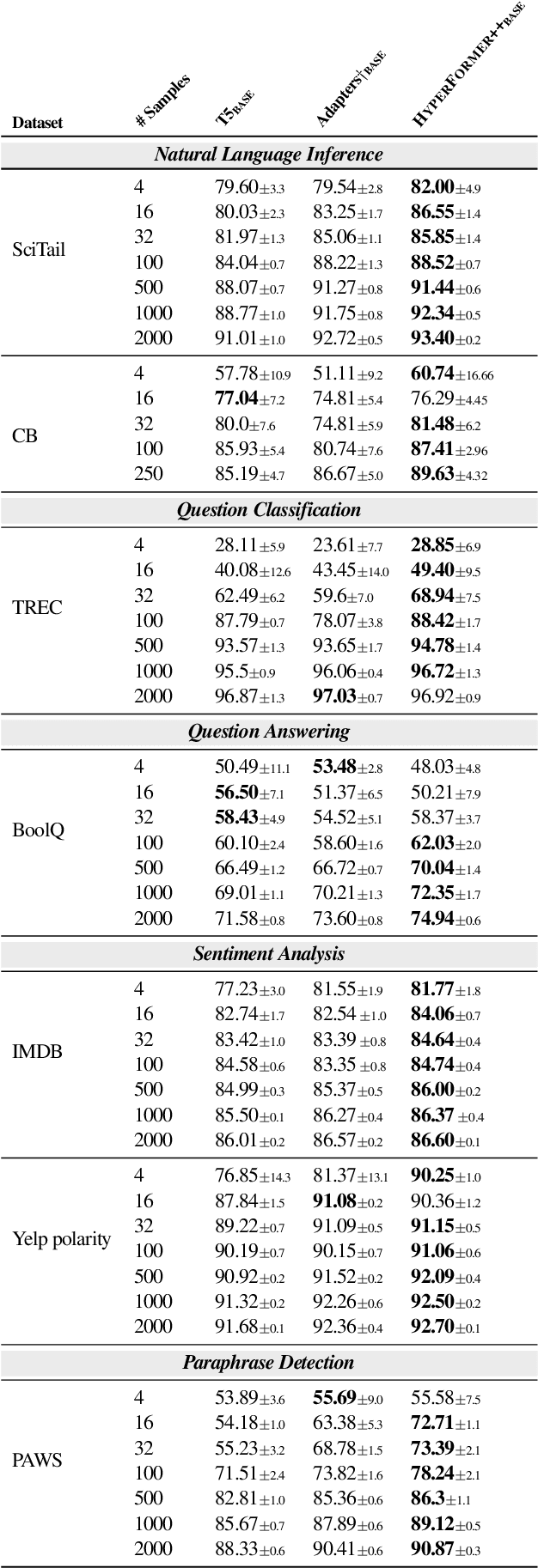
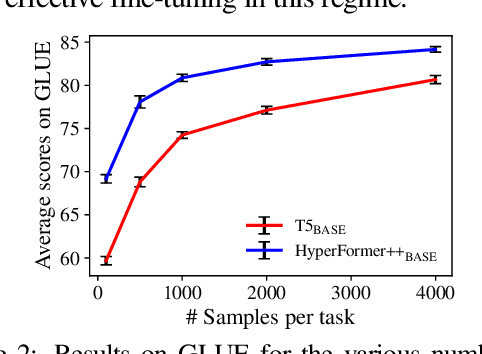
State-of-the-art parameter-efficient fine-tuning methods rely on introducing adapter modules between the layers of a pretrained language model. However, such modules are trained separately for each task and thus do not enable sharing information across tasks. In this paper, we show that we can learn adapter parameters for all layers and tasks by generating them using shared hypernetworks, which condition on task, adapter position, and layer id in a transformer model. This parameter-efficient multi-task learning framework allows us to achieve the best of both worlds by sharing knowledge across tasks via hypernetworks while enabling the model to adapt to each individual task through task-specific adapters. Experiments on the well-known GLUE benchmark show improved performance in multi-task learning while adding only 0.29% parameters per task. We additionally demonstrate substantial performance improvements in few-shot domain generalization across a variety of tasks. Our code is publicly available in https://github.com/rabeehk/hyperformer.