 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Efficient Tensor Contraction via Fast Count Sketch
Jun 24, 2021

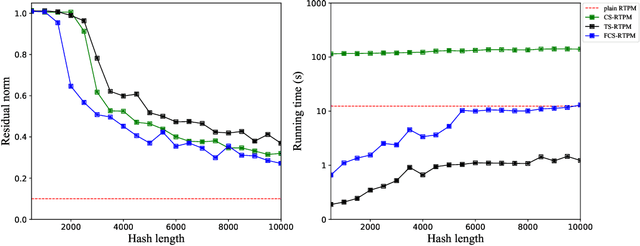
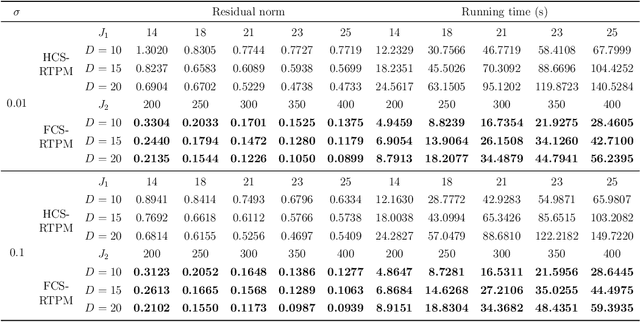
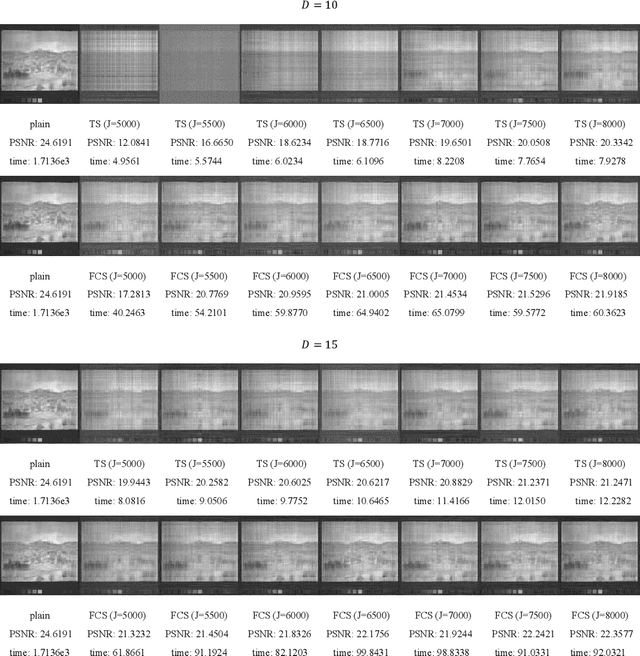
Sketching uses randomized Hash functions for dimensionality reduction and acceleration. The existing sketching methods, such as count sketch (CS), tensor sketch (TS), and higher-order count sketch (HCS), either suffer from low accuracy or slow speed in some tensor based applications. In this paper, the proposed fast count sketch (FCS) applies multiple shorter Hash functions based CS to the vector form of the input tensor, which is more accurate than TS since the spatial information of the input tensor can be preserved more sufficiently. When the input tensor admits CANDECOMP/PARAFAC decomposition (CPD), FCS can accelerate CS and HCS by using fast Fourier transform, which exhibits a computational complexity asymptotically identical to TS for low-order tensors. The effectiveness of FCS is validated by CPD, tensor regression network compression, and Kronecker product compression. Experimental results show its superior performance in terms of approximation accuracy and computational efficiency.
Exploring Stronger Feature for Temporal Action Localization
Jun 24, 2021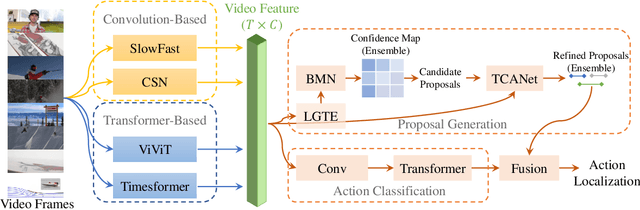
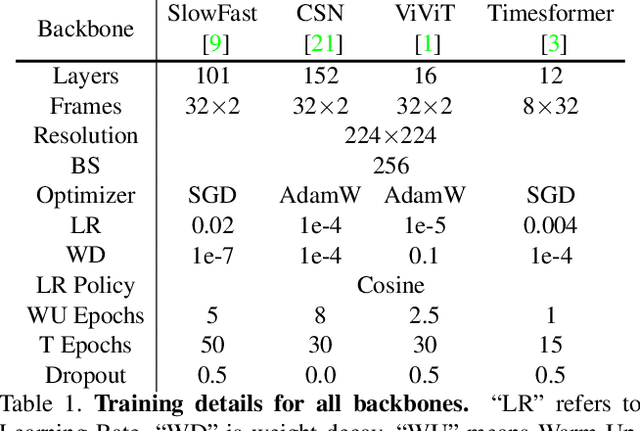
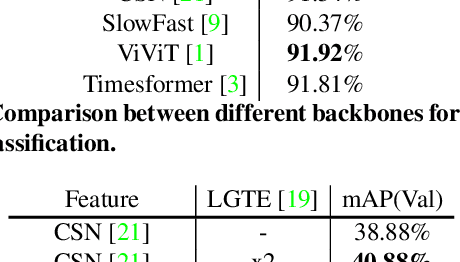

Temporal action localization aims to localize starting and ending time with action category. Limited by GPU memory, mainstream methods pre-extract features for each video. Therefore, feature quality determines the upper bound of detection performance. In this technical report, we explored classic convolution-based backbones and the recent surge of transformer-based backbones. We found that the transformer-based methods can achieve better classification performance than convolution-based, but they cannot generate accuracy action proposals. In addition, extracting features with larger frame resolution to reduce the loss of spatial information can also effectively improve the performance of temporal action localization. Finally, we achieve 42.42% in terms of mAP on validation set with a single SlowFast feature by a simple combination: BMN+TCANet, which is 1.87% higher than the result of 2020's multi-model ensemble. Finally, we achieve Rank 1st on the CVPR2021 HACS supervised Temporal Action Localization Challenge.
Finding Concept-specific Biases in Form--Meaning Associations
Apr 13, 2021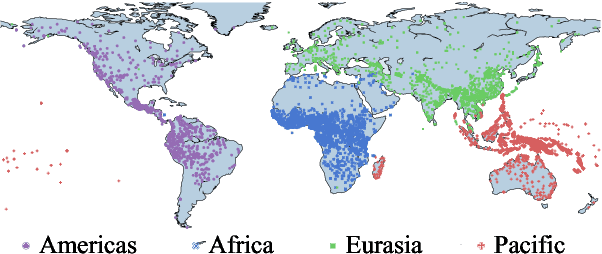
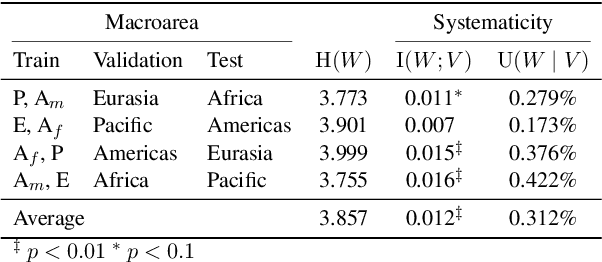
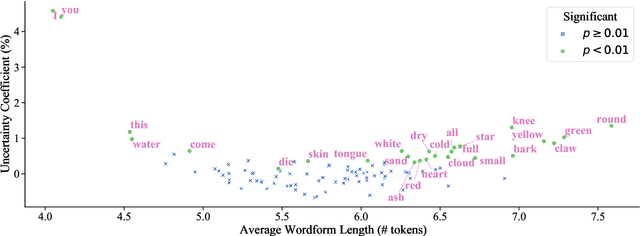
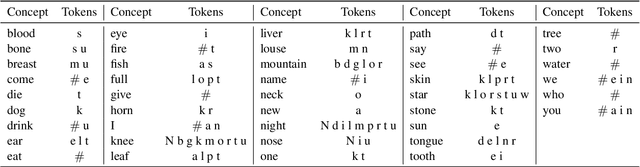
This work presents an information-theoretic operationalisation of cross-linguistic non-arbitrariness. It is not a new idea that there are small, cross-linguistic associations between the forms and meanings of words. For instance, it has been claimed (Blasi et al., 2016) that the word for "tongue" is more likely than chance to contain the phone [l]. By controlling for the influence of language family and geographic proximity within a very large concept-aligned cross-lingual lexicon, we extend methods previously used to detect within language non-arbitrariness (Pimentel et al., 2019) to measure cross-linguistic associations. We find that there is a significant effect of non-arbitrariness, but it is unsurprisingly small (less than 0.5% on average according to our information-theoretic estimate). We also provide a concept-level analysis which shows that a quarter of the concepts considered in our work exhibit a significant level of cross-linguistic non-arbitrariness. In sum, the paper provides new methods to detect cross-linguistic associations at scale.
Analysis of GraphSum's Attention Weights to Improve the Explainability of Multi-Document Summarization
May 19, 2021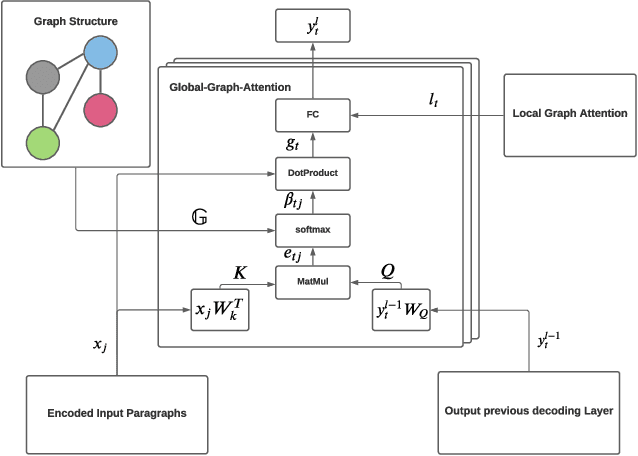
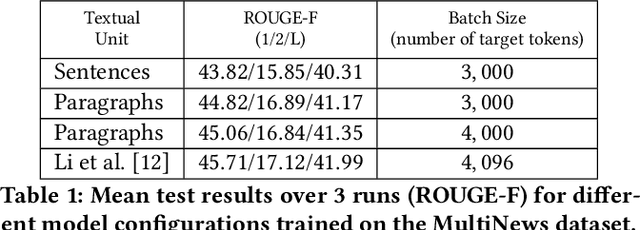
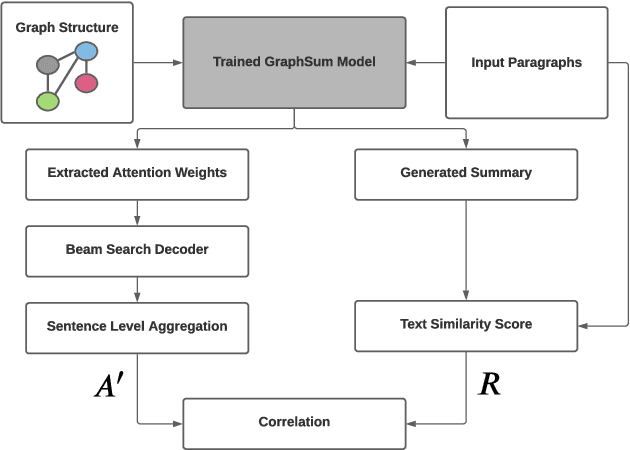
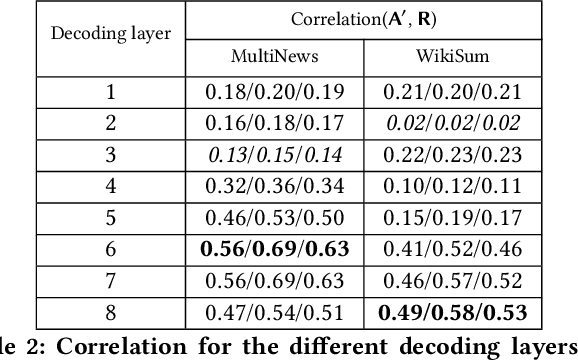
Modern multi-document summarization (MDS) methods are based on transformer architectures. They generate state of the art summaries, but lack explainability. We focus on graph-based transformer models for MDS as they gained recent popularity. We aim to improve the explainability of the graph-based MDS by analyzing their attention weights. In a graph-based MDS such as GraphSum, vertices represent the textual units, while the edges form some similarity graph over the units. We compare GraphSum's performance utilizing different textual units, i. e., sentences versus paragraphs, on two news benchmark datasets, namely WikiSum and MultiNews. Our experiments show that paragraph-level representations provide the best summarization performance. Thus, we subsequently focus oAnalysisn analyzing the paragraph-level attention weights of GraphSum's multi-heads and decoding layers in order to improve the explainability of a transformer-based MDS model. As a reference metric, we calculate the ROUGE scores between the input paragraphs and each sentence in the generated summary, which indicate source origin information via text similarity. We observe a high correlation between the attention weights and this reference metric, especially on the the later decoding layers of the transformer architecture. Finally, we investigate if the generated summaries follow a pattern of positional bias by extracting which paragraph provided the most information for each generated summary. Our results show that there is a high correlation between the position in the summary and the source origin.
CVEH: A Dynamic Framework To Profile Vehicle Movements To Mitigate Hit And Run Cases Using Crowdsourcing
Jun 28, 2021
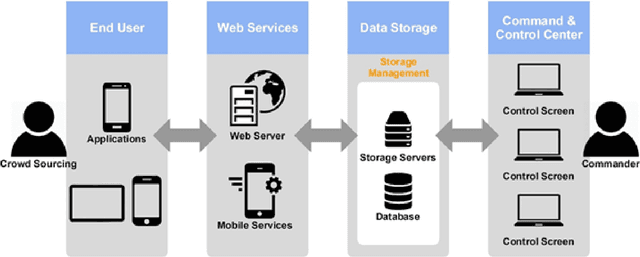
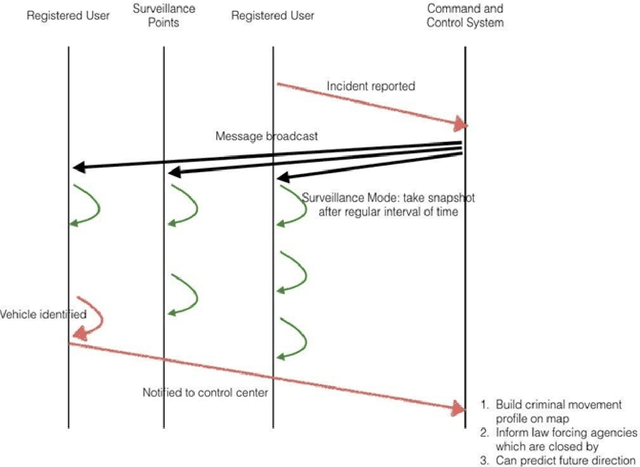
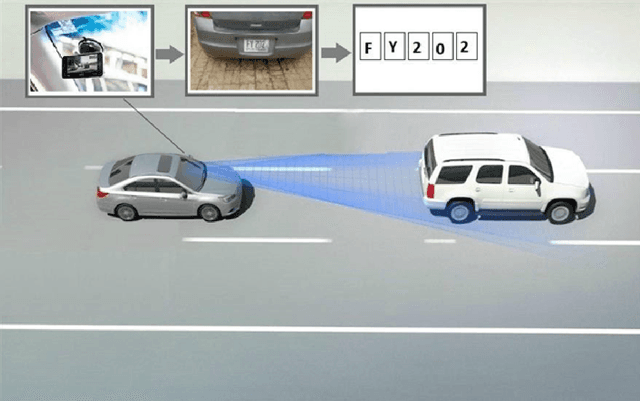
In developed countries like the USA, Germany, and the UK, the security forces used highly sophisticated equipment, fast vehicles, drones, and helicopters to catch offenders' vehicles. Whereas, in developing countries with limited resources such schemes cannot be utilized due to management cost and other constraints. In this paper, we proposed a framework called CVEH that enables developing countries to profile the offender vehicle movements through crowdsourcing technique and act as an early warning system to the law forcing agencies. It also engages citizens to play their role in improving security conditions. The proposed CVEH framework allows Vehicle-to-Infrastructure (V2I) communication to monitor the movement of the offender's vehicle and shared its information with the Command and Control (CC) centre. The CC centre projects the path and engages nearly located law enforcement agencies. CVEH is developed and evaluated on android smartphones. Simulations conducted for this study exhibit the effectiveness of our framework.
End-to-End User Behavior Retrieval in Click-Through RatePrediction Model
Aug 10, 2021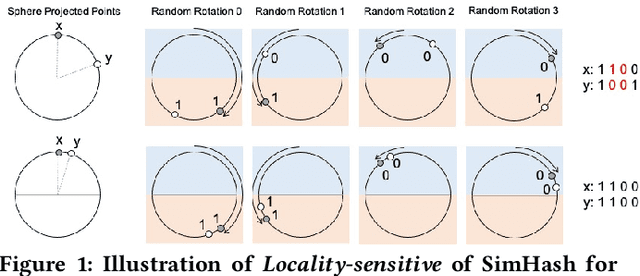

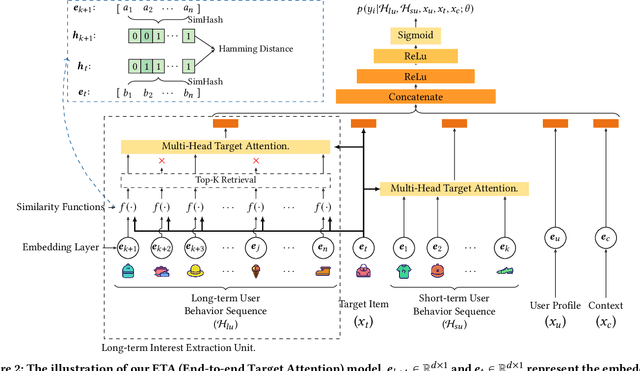

Click-Through Rate (CTR) prediction is one of the core tasks in recommender systems (RS). It predicts a personalized click probability for each user-item pair. Recently, researchers have found that the performance of CTR model can be improved greatly by taking user behavior sequence into consideration, especially long-term user behavior sequence. The report on an e-commerce website shows that 23\% of users have more than 1000 clicks during the past 5 months. Though there are numerous works focus on modeling sequential user behaviors, few works can handle long-term user behavior sequence due to the strict inference time constraint in real world system. Two-stage methods are proposed to push the limit for better performance. At the first stage, an auxiliary task is designed to retrieve the top-$k$ similar items from long-term user behavior sequence. At the second stage, the classical attention mechanism is conducted between the candidate item and $k$ items selected in the first stage. However, information gap happens between retrieval stage and the main CTR task. This goal divergence can greatly diminishing the performance gain of long-term user sequence. In this paper, inspired by Reformer, we propose a locality-sensitive hashing (LSH) method called ETA (End-to-end Target Attention) which can greatly reduce the training and inference cost and make the end-to-end training with long-term user behavior sequence possible. Both offline and online experiments confirm the effectiveness of our model. We deploy ETA into a large-scale real world E-commerce system and achieve extra 3.1\% improvements on GMV (Gross Merchandise Value) compared to a two-stage long user sequence CTR model.
Programmable 3D snapshot microscopy with Fourier convolutional networks
Apr 21, 2021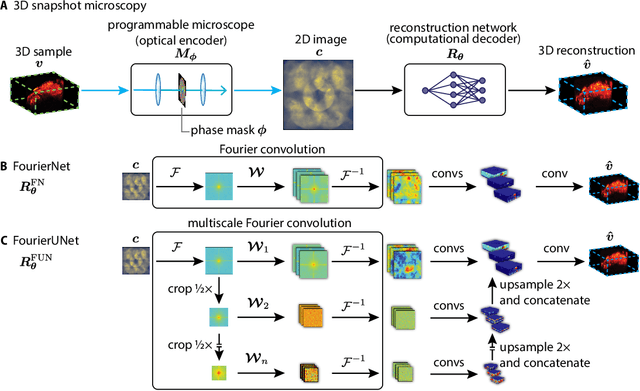


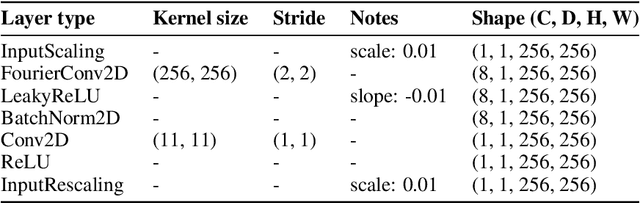
3D snapshot microscopy enables volumetric imaging as fast as a camera allows by capturing a 3D volume in a single 2D camera image, and has found a variety of biological applications such as whole brain imaging of fast neural activity in larval zebrafish. The optimal microscope design for this optical 3D-to-2D encoding to preserve as much 3D information as possible is generally unknown and sample-dependent. Highly-programmable optical elements create new possibilities for sample-specific computational optimization of microscope parameters, e.g. tuning the collection of light for a given sample structure, especially using deep learning. This involves a differentiable simulation of light propagation through the programmable microscope and a neural network to reconstruct volumes from the microscope image. We introduce a class of global kernel Fourier convolutional neural networks which can efficiently integrate the globally mixed information encoded in a 3D snapshot image. We show in silico that our proposed global Fourier convolutional networks succeed in large field-of-view volume reconstruction and microscope parameter optimization where traditional networks fail.
Adaptive wavelet distillation from neural networks through interpretations
Jul 19, 2021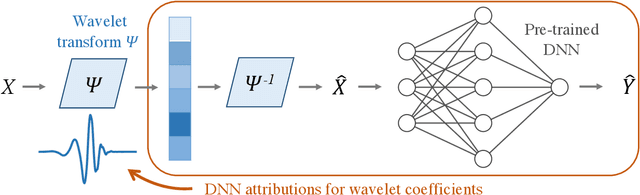

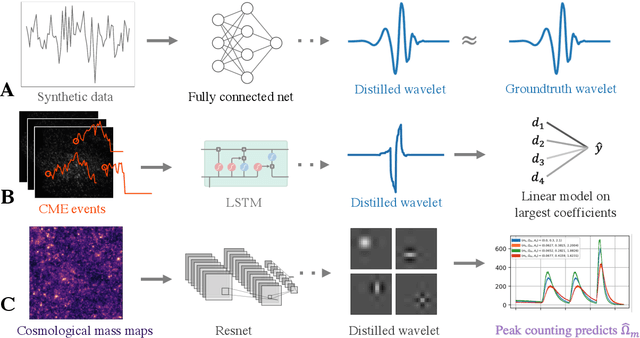

Recent deep-learning models have achieved impressive prediction performance, but often sacrifice interpretability and computational efficiency. Interpretability is crucial in many disciplines, such as science and medicine, where models must be carefully vetted or where interpretation is the goal itself. Moreover, interpretable models are concise and often yield computational efficiency. Here, we propose adaptive wavelet distillation (AWD), a method which aims to distill information from a trained neural network into a wavelet transform. Specifically, AWD penalizes feature attributions of a neural network in the wavelet domain to learn an effective multi-resolution wavelet transform. The resulting model is highly predictive, concise, computationally efficient, and has properties (such as a multi-scale structure) which make it easy to interpret. In close collaboration with domain experts, we showcase how AWD addresses challenges in two real-world settings: cosmological parameter inference and molecular-partner prediction. In both cases, AWD yields a scientifically interpretable and concise model which gives predictive performance better than state-of-the-art neural networks. Moreover, AWD identifies predictive features that are scientifically meaningful in the context of respective domains. All code and models are released in a full-fledged package available on Github (https://github.com/Yu-Group/adaptive-wavelets).
Defending against Adversarial Denial-of-Service Attacks
Apr 21, 2021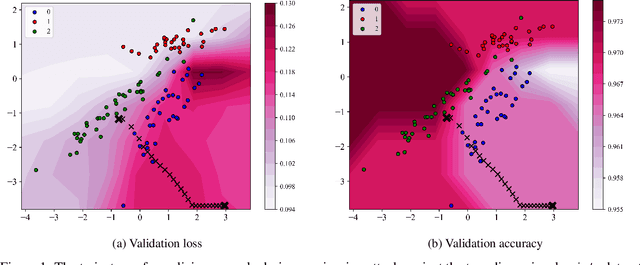
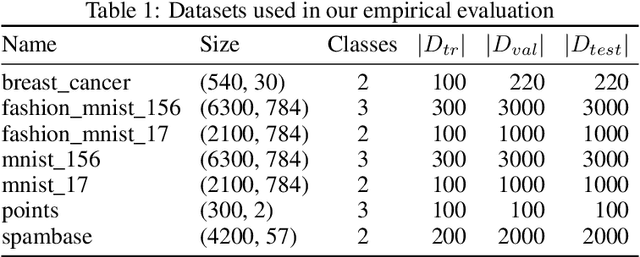
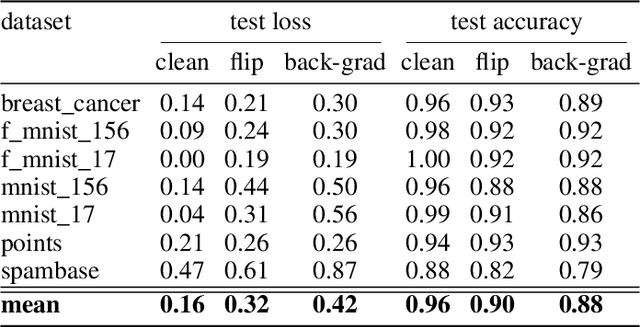
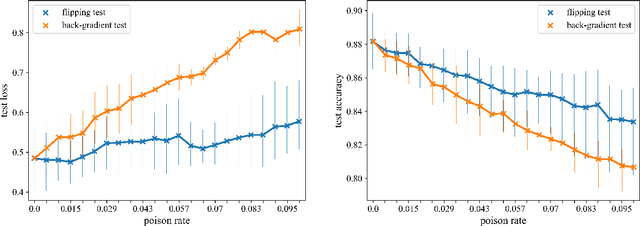
Data poisoning is one of the most relevant security threats against machine learning and data-driven technologies. Since many applications rely on untrusted training data, an attacker can easily craft malicious samples and inject them into the training dataset to degrade the performance of machine learning models. As recent work has shown, such Denial-of-Service (DoS) data poisoning attacks are highly effective. To mitigate this threat, we propose a new approach of detecting DoS poisoned instances. In comparison to related work, we deviate from clustering and anomaly detection based approaches, which often suffer from the curse of dimensionality and arbitrary anomaly threshold selection. Rather, our defence is based on extracting information from the training data in such a generalized manner that we can identify poisoned samples based on the information present in the unpoisoned portion of the data. We evaluate our defence against two DoS poisoning attacks and seven datasets, and find that it reliably identifies poisoned instances. In comparison to related work, our defence improves false positive / false negative rates by at least 50%, often more.
Enhancing Network Embedding with Auxiliary Information: An Explicit Matrix Factorization Perspective
Mar 05, 2018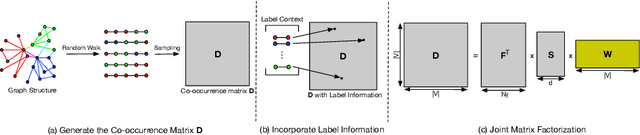
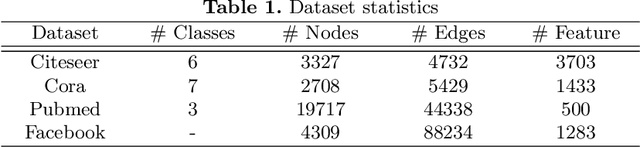
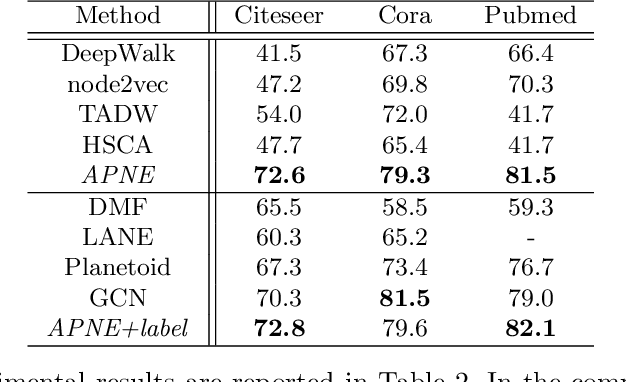
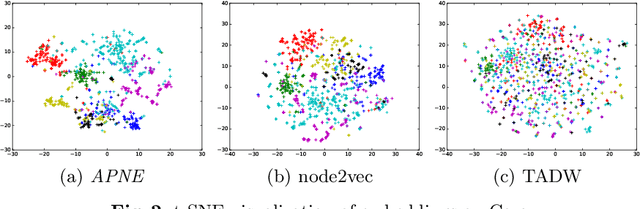
Recent advances in the field of network embedding have shown the low-dimensional network representation is playing a critical role in network analysis. However, most of the existing principles of network embedding do not incorporate auxiliary information such as content and labels of nodes flexibly. In this paper, we take a matrix factorization perspective of network embedding, and incorporate structure, content and label information of the network simultaneously. For structure, we validate that the matrix we construct preserves high-order proximities of the network. Label information can be further integrated into the matrix via the process of random walk sampling to enhance the quality of embedding in an unsupervised manner, i.e., without leveraging downstream classifiers. In addition, we generalize the Skip-Gram Negative Sampling model to integrate the content of the network in a matrix factorization framework. As a consequence, network embedding can be learned in a unified framework integrating network structure and node content as well as label information simultaneously. We demonstrate the efficacy of the proposed model with the tasks of semi-supervised node classification and link prediction on a variety of real-world benchmark network datasets.