 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Diagonal Nonlinear Transformations Preserve Structure in Covariance and Precision Matrices
Jul 08, 2021
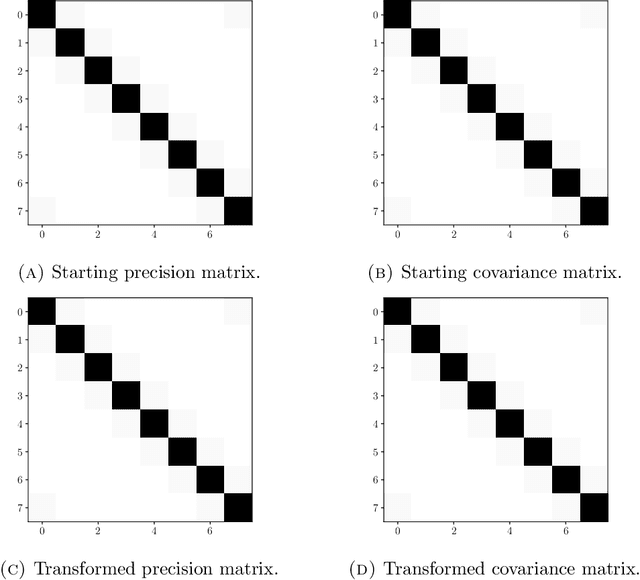
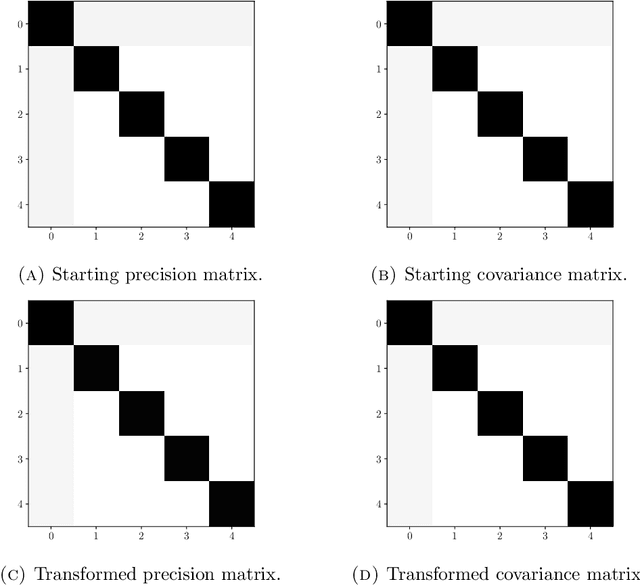
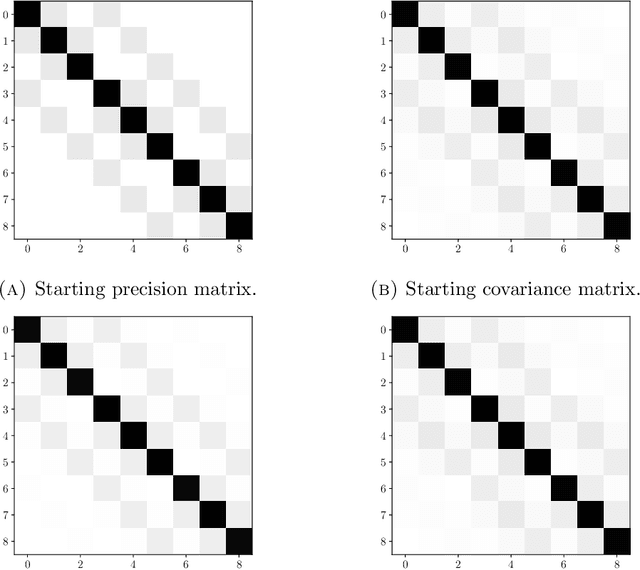
For a multivariate normal distribution, the sparsity of the covariance and precision matrices encodes complete information about independence and conditional independence properties. For general distributions, the covariance and precision matrices reveal correlations and so-called partial correlations between variables, but these do not, in general, have any correspondence with respect to independence properties. In this paper, we prove that, for a certain class of non-Gaussian distributions, these correspondences still hold, exactly for the covariance and approximately for the precision. The distributions -- sometimes referred to as "nonparanormal" -- are given by diagonal transformations of multivariate normal random variables. We provide several analytic and numerical examples illustrating these results.
A stepped sampling method for video detection using LSTM
Jul 18, 2021
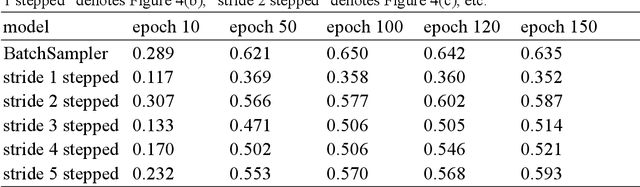


Artificial neural networks that simulate human achieves great successes. From the perspective of simulating human memory method, we propose a stepped sampler based on the "repeated input". We repeatedly inputted data to the LSTM model stepwise in a batch. The stepped sampler is used to strengthen the ability of fusing the temporal information in LSTM. We tested the stepped sampler on the LSTM built-in in PyTorch. Compared with the traditional sampler of PyTorch, such as sequential sampler, batch sampler, the training loss of the proposed stepped sampler converges faster in the training of the model, and the training loss after convergence is more stable. Meanwhile, it can maintain a higher test accuracy. We quantified the algorithm of the stepped sampler.
An Interpretable Music Similarity Measure Based on Path Interestingness
Aug 04, 2021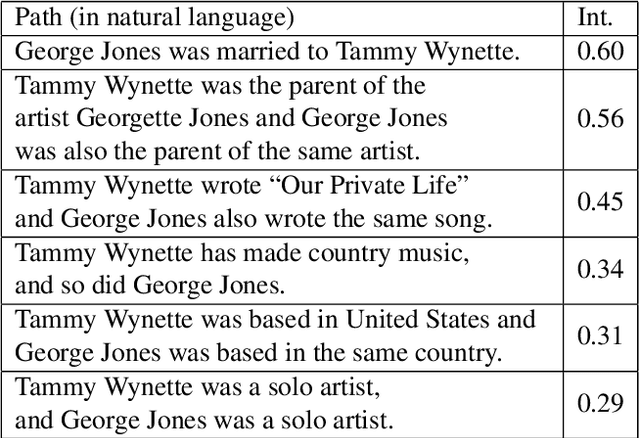

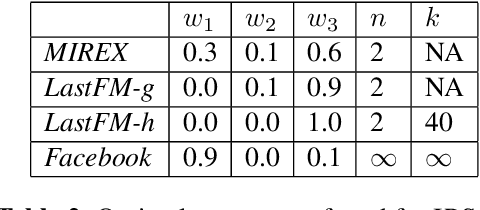
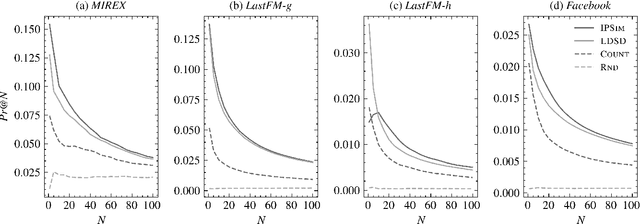
We introduce a novel and interpretable path-based music similarity measure. Our similarity measure assumes that items, such as songs and artists, and information about those items are represented in a knowledge graph. We find paths in the graph between a seed and a target item; we score those paths based on their interestingness; and we aggregate those scores to determine the similarity between the seed and the target. A distinguishing feature of our similarity measure is its interpretability. In particular, we can translate the most interesting paths into natural language, so that the causes of the similarity judgements can be readily understood by humans. We compare the accuracy of our similarity measure with other competitive path-based similarity baselines in two experimental settings and with four datasets. The results highlight the validity of our approach to music similarity, and demonstrate that path interestingness scores can be the basis of an accurate and interpretable similarity measure.
Did you miss it? Automatic lung nodule detection combined with gaze information improves radiologists' screening performance
Oct 09, 2019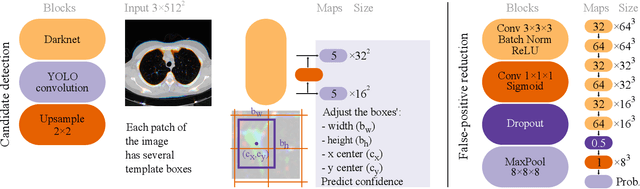
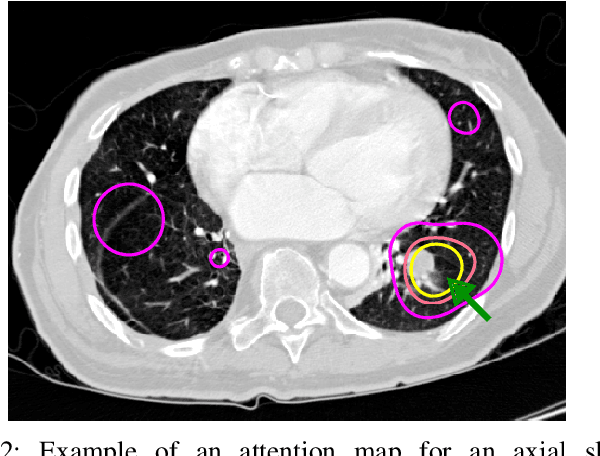
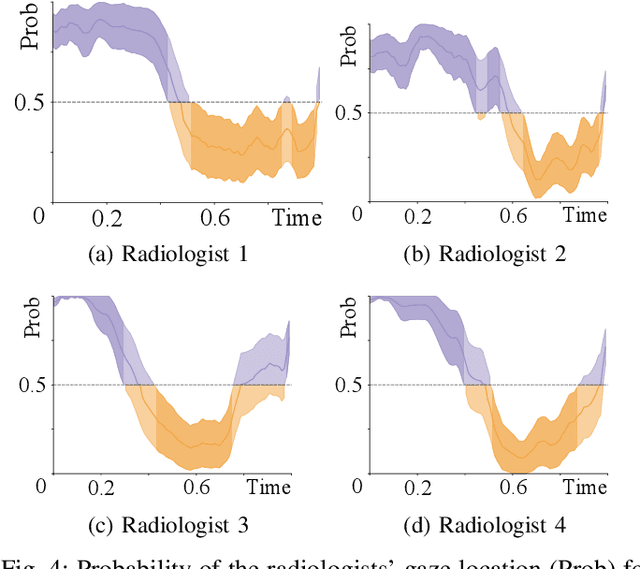
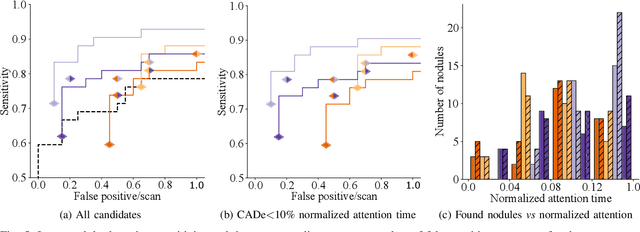
Early diagnosis of lung cancer via computed tomography can significantly reduce the morbidity and mortality rates associated with the pathology. However, search lung nodules is a high complexity task, which affects the success of screening programs. Whilst computer-aided detection systems can be used as second observers, they may bias radiologists and introduce significant time overheads. With this in mind, this study assesses the potential of using gaze information for integrating automatic detection systems in the clinical practice. For that purpose, 4 radiologists were asked to annotate 20 scans from a public dataset while being monitored by an eye tracker device and an automatic lung nodule detection system was developed. Our results show that radiologists follow a similar search routine and tend to have lower fixation periods in regions where finding errors occur. The overall detection sensitivity of the specialists was 0.67$\pm$0.07, whereas the system achieved 0.69. Combining the annotations of one radiologist with the automatic system significantly improves the detection performance to similar levels of two annotators. Likewise, combining the findings of radiologist with the detection algorithm only for low fixation regions still significantly improves the detection sensitivity without increasing the number of false-positives. The combination of the automatic system with the gaze information allows to mitigate possible errors of the radiologist without some of the issues usually associated with automatic detection system.
StyleAugment: Learning Texture De-biased Representations by Style Augmentation without Pre-defined Textures
Aug 24, 2021
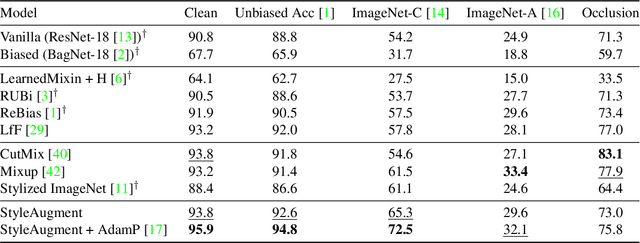


Recent powerful vision classifiers are biased towards textures, while shape information is overlooked by the models. A simple attempt by augmenting training images using the artistic style transfer method, called Stylized ImageNet, can reduce the texture bias. However, Stylized ImageNet approach has two drawbacks in fidelity and diversity. First, the generated images show low image quality due to the significant semantic gap betweeen natural images and artistic paintings. Also, Stylized ImageNet training samples are pre-computed before training, resulting in showing the lack of diversity for each sample. We propose a StyleAugment by augmenting styles from the mini-batch. StyleAugment does not rely on the pre-defined style references, but generates augmented images on-the-fly by natural images in the mini-batch for the references. Hence, StyleAugment let the model observe abundant confounding cues for each image by on-the-fly the augmentation strategy, while the augmented images are more realistic than artistic style transferred images. We validate the effectiveness of StyleAugment in the ImageNet dataset with robustness benchmarks, such as texture de-biased accuracy, corruption robustness, natural adversarial samples, and occlusion robustness. StyleAugment shows better generalization performances than previous unsupervised de-biasing methods and state-of-the-art data augmentation methods in our experiments.
Knowledge Transfer for Few-shot Segmentation of Novel White Matter Tracts
Jun 01, 2021



Convolutional neural networks (CNNs) have achieved stateof-the-art performance for white matter (WM) tract segmentation based on diffusion magnetic resonance imaging (dMRI). These CNNs require a large number of manual delineations of the WM tracts of interest for training, which are generally labor-intensive and costly. The expensive manual delineation can be a particular disadvantage when novel WM tracts, i.e., tracts that have not been included in existing manual delineations, are to be analyzed. To accurately segment novel WM tracts, it is desirable to transfer the knowledge learned about existing WM tracts, so that even with only a few delineations of the novel WM tracts, CNNs can learn adequately for the segmentation. In this paper, we explore the transfer of such knowledge to the segmentation of novel WM tracts in the few-shot setting. Although a classic fine-tuning strategy can be used for the purpose, the information in the last task-specific layer for segmenting existing WM tracts is completely discarded. We hypothesize that the weights of this last layer can bear valuable information for segmenting the novel WM tracts and thus completely discarding the information is not optimal. In particular, we assume that the novel WM tracts can correlate with existing WM tracts and the segmentation of novel WM tracts can be predicted with the logits of existing WM tracts. In this way, better initialization of the last layer than random initialization can be achieved for fine-tuning. Further, we show that a more adaptive use of the knowledge in the last layer for segmenting existing WM tracts can be conveniently achieved by simply inserting a warmup stage before classic fine-tuning. The proposed method was evaluated on a publicly available dMRI dataset, where we demonstrate the benefit of our method for few-shot segmentation of novel WM tracts.
Making Person Search Enjoy the Merits of Person Re-identification
Aug 24, 2021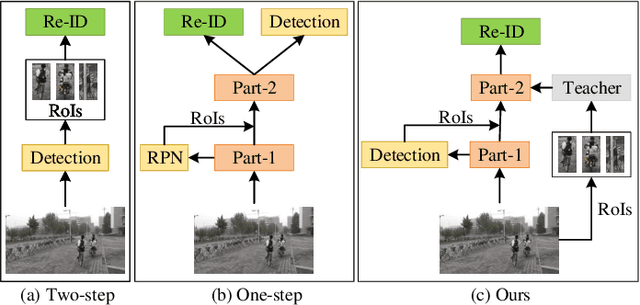
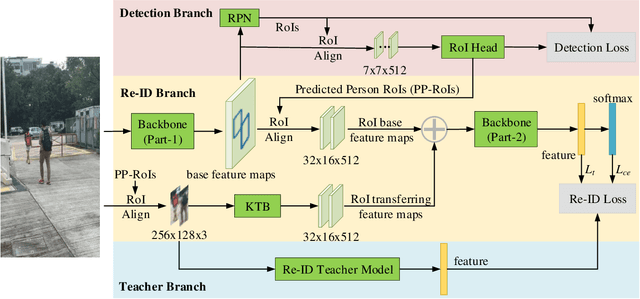

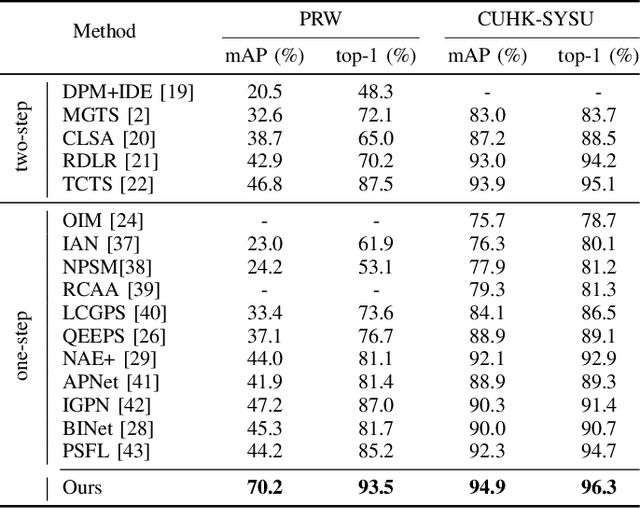
Person search is an extended task of person re-identification (Re-ID). However, most existing one-step person search works have not studied how to employ existing advanced Re-ID models to boost the one-step person search performance due to the integration of person detection and Re-ID. To address this issue, we propose a faster and stronger one-step person search framework, the Teacher-guided Disentangling Networks (TDN), to make the one-step person search enjoy the merits of the existing Re-ID researches. The proposed TDN can significantly boost the person search performance by transferring the advanced person Re-ID knowledge to the person search model. In the proposed TDN, for better knowledge transfer from the Re-ID teacher model to the one-step person search model, we design a strong one-step person search base framework by partially disentangling the two subtasks. Besides, we propose a Knowledge Transfer Bridge module to bridge the scale gap caused by different input formats between the Re-ID model and one-step person search model. During testing, we further propose the Ranking with Context Persons strategy to exploit the context information in panoramic images for better retrieval. Experiments on two public person search datasets demonstrate the favorable performance of the proposed method.
Cross-sentence Neural Language Models for Conversational Speech Recognition
Jun 15, 2021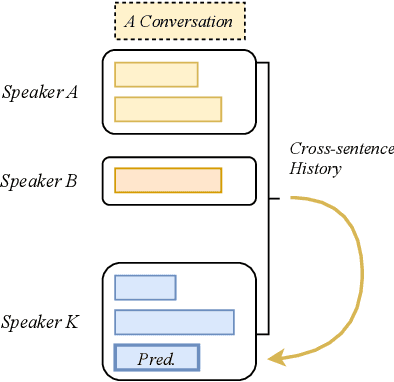
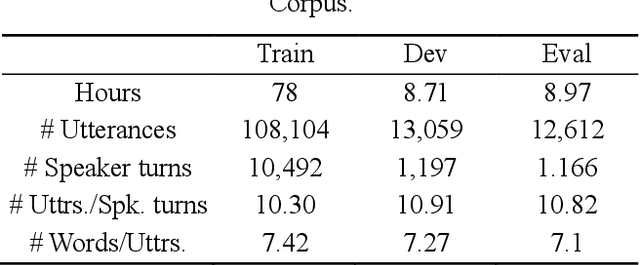
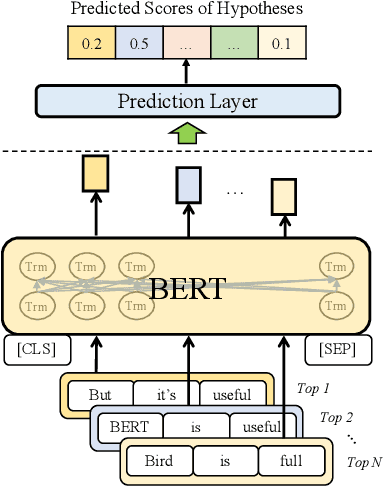
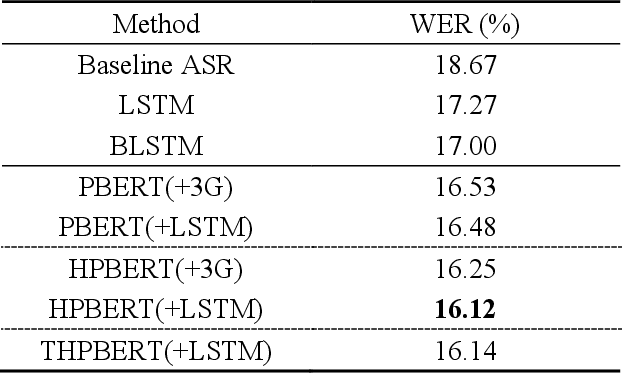
An important research direction in automatic speech recognition (ASR) has centered around the development of effective methods to rerank the output hypotheses of an ASR system with more sophisticated language models (LMs) for further gains. A current mainstream school of thoughts for ASR N-best hypothesis reranking is to employ a recurrent neural network (RNN)-based LM or its variants, with performance superiority over the conventional n-gram LMs across a range of ASR tasks. In real scenarios such as a long conversation, a sequence of consecutive sentences may jointly contain ample cues of conversation-level information such as topical coherence, lexical entrainment and adjacency pairs, which however remains to be underexplored. In view of this, we first formulate ASR N-best reranking as a prediction problem, putting forward an effective cross-sentence neural LM approach that reranks the ASR N-best hypotheses of an upcoming sentence by taking into consideration the word usage in its precedent sentences. Furthermore, we also explore to extract task-specific global topical information of the cross-sentence history in an unsupervised manner for better ASR performance. Extensive experiments conducted on the AMI conversational benchmark corpus indicate the effectiveness and feasibility of our methods in comparison to several state-of-the-art reranking methods.
Unsupervised Domain Adaptive 3D Detection with Multi-Level Consistency
Aug 18, 2021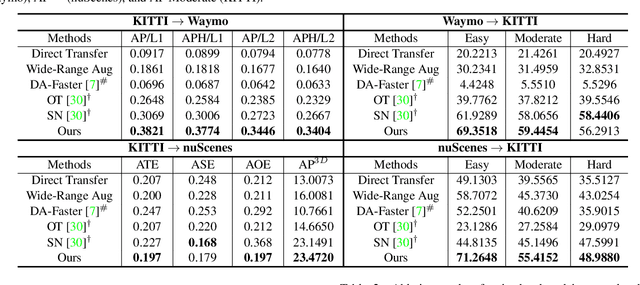
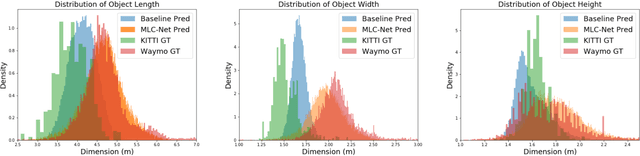
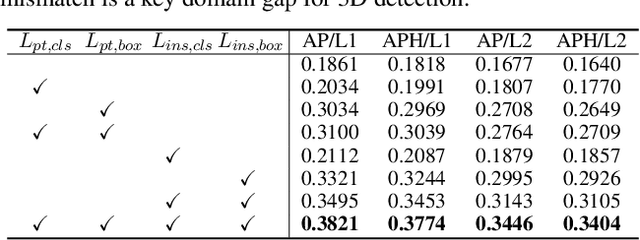
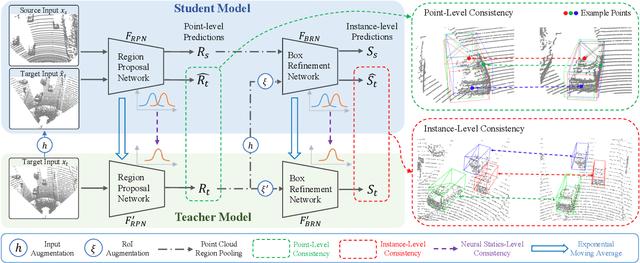
Deep learning-based 3D object detection has achieved unprecedented success with the advent of large-scale autonomous driving datasets. However, drastic performance degradation remains a critical challenge for cross-domain deployment. In addition, existing 3D domain adaptive detection methods often assume prior access to the target domain annotations, which is rarely feasible in the real world. To address this challenge, we study a more realistic setting, unsupervised 3D domain adaptive detection, which only utilizes source domain annotations. 1) We first comprehensively investigate the major underlying factors of the domain gap in 3D detection. Our key insight is that geometric mismatch is the key factor of domain shift. 2) Then, we propose a novel and unified framework, Multi-Level Consistency Network (MLC-Net), which employs a teacher-student paradigm to generate adaptive and reliable pseudo-targets. MLC-Net exploits point-, instance- and neural statistics-level consistency to facilitate cross-domain transfer. Extensive experiments demonstrate that MLC-Net outperforms existing state-of-the-art methods (including those using additional target domain information) on standard benchmarks. Notably, our approach is detector-agnostic, which achieves consistent gains on both single- and two-stage 3D detectors.
A Comprehensive Exploration of Pre-training Language Models
Jun 22, 2021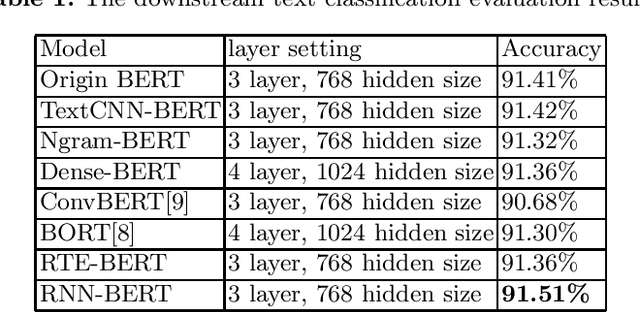
Recently, the development of pre-trained language models has brought natural language processing (NLP) tasks to the new state-of-the-art. In this paper we explore the efficiency of various pre-trained language models. We pre-train a list of transformer-based models with the same amount of text and the same training steps. The experimental results shows that the most improvement upon the origin BERT is adding the RNN-layer to capture more contextual information for the transformer-encoder layers.