 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Analysing Mixed Initiatives and Search Strategies during Conversational Search
Sep 13, 2021
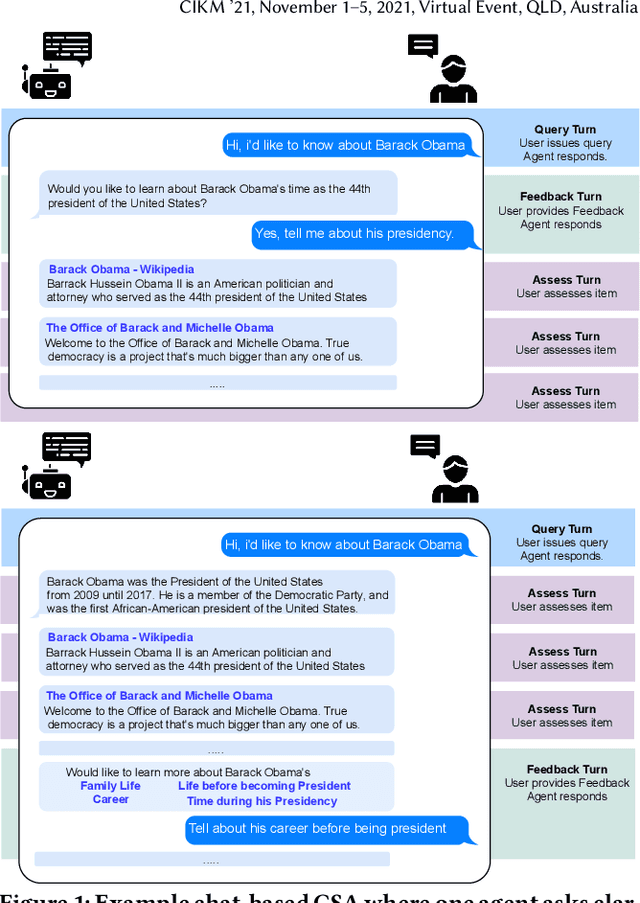
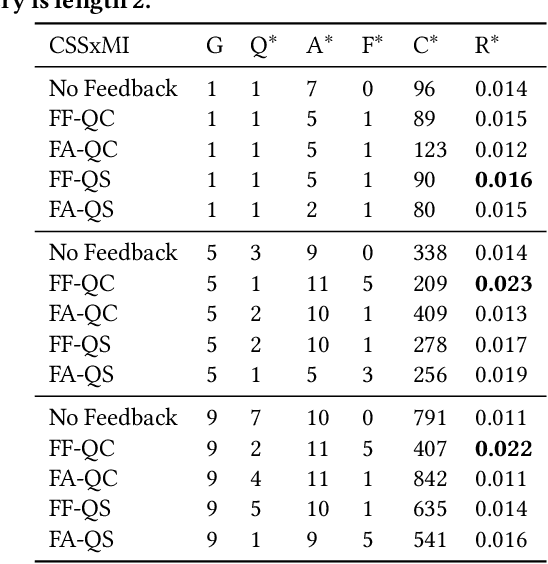
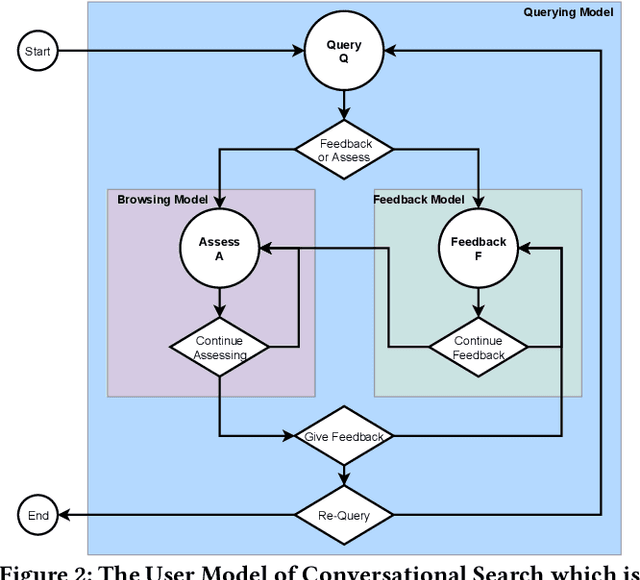
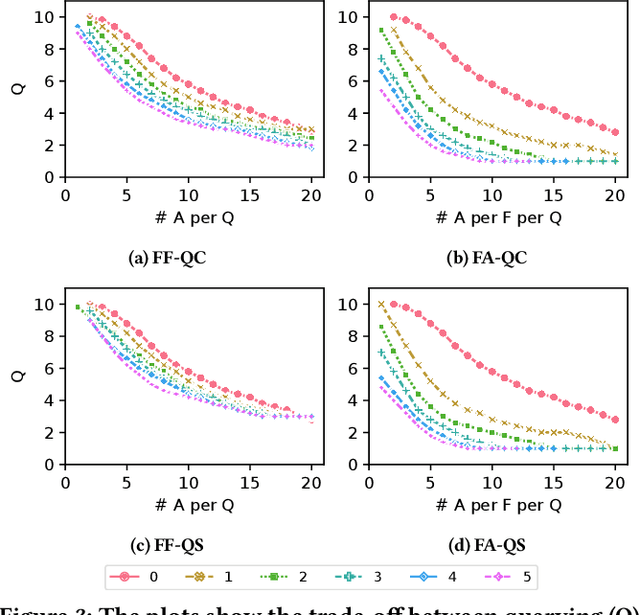
Information seeking conversations between users and Conversational Search Agents (CSAs) consist of multiple turns of interaction. While users initiate a search session, ideally a CSA should sometimes take the lead in the conversation by obtaining feedback from the user by offering query suggestions or asking for query clarifications i.e. mixed initiative. This creates the potential for more engaging conversational searches, but substantially increases the complexity of modelling and evaluating such scenarios due to the large interaction space coupled with the trade-offs between the costs and benefits of the different interactions. In this paper, we present a model for conversational search -- from which we instantiate different observed conversational search strategies, where the agent elicits: (i) Feedback-First, or (ii) Feedback-After. Using 49 TREC WebTrack Topics, we performed an analysis comparing how well these different strategies combine with different mixed initiative approaches: (i) Query Suggestions vs. (ii) Query Clarifications. Our analysis reveals that there is no superior or dominant combination, instead it shows that query clarifications are better when asked first, while query suggestions are better when asked after presenting results. We also show that the best strategy and approach depends on the trade-offs between the relative costs between querying and giving feedback, the performance of the initial query, the number of assessments per query, and the total amount of gain required. While this work highlights the complexities and challenges involved in analyzing CSAs, it provides the foundations for evaluating conversational strategies and conversational search agents in batch/offline settings.
Multi-Channel Automatic Music Transcription Using Tensor Algebra
Jul 23, 2021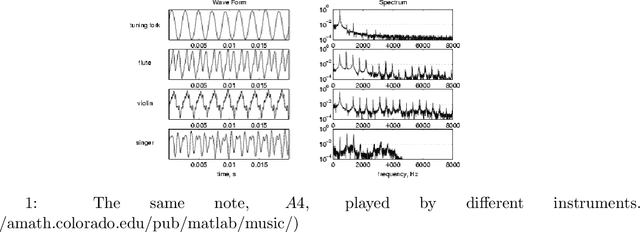
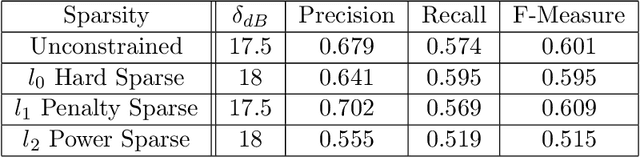

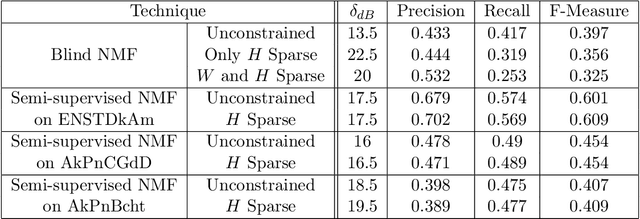
Music is an art, perceived in unique ways by every listener, coming from acoustic signals. In the meantime, standards as musical scores exist to describe it. Even if humans can make this transcription, it is costly in terms of time and efforts, even more with the explosion of information consecutively to the rise of the Internet. In that sense, researches are driven in the direction of Automatic Music Transcription. While this task is considered solved in the case of single notes, it is still open when notes superpose themselves, forming chords. This report aims at developing some of the existing techniques towards Music Transcription, particularly matrix factorization, and introducing the concept of multi-channel automatic music transcription. This concept will be explored with mathematical objects called tensors.
AppQ: Warm-starting App Recommendation Based on View Graphs
Sep 08, 2021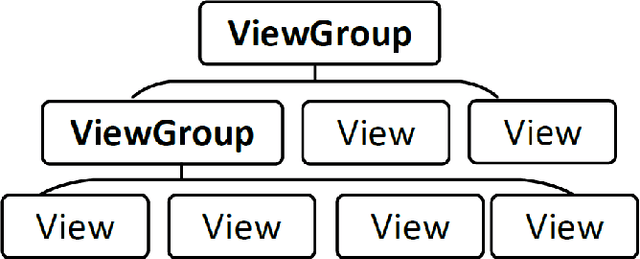
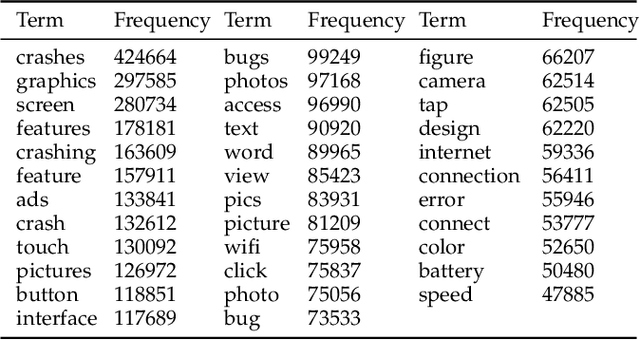
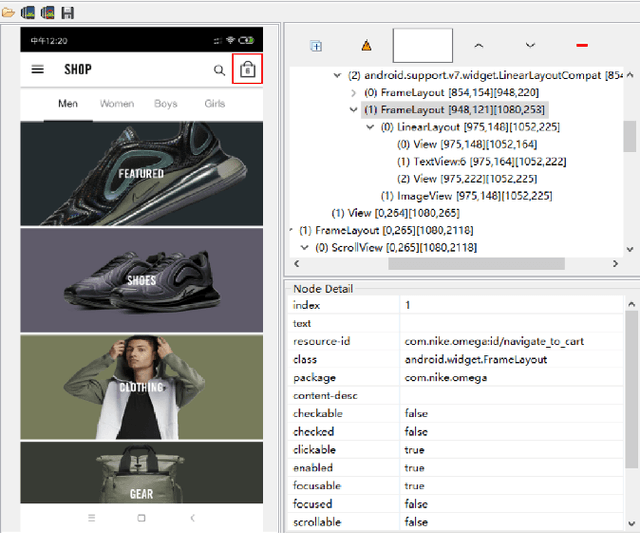
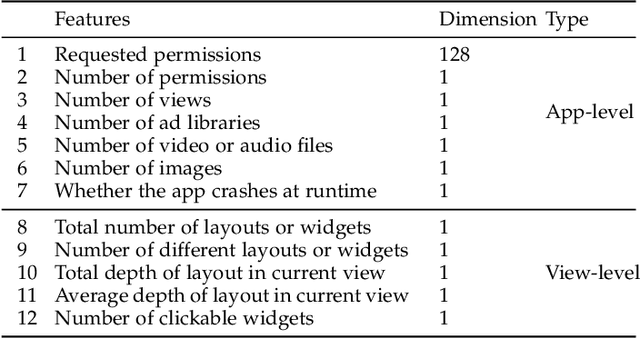
Current app ranking and recommendation systems are mainly based on user-generated information, e.g., number of downloads and ratings. However, new apps often have few (or even no) user feedback, suffering from the classic cold-start problem. How to quickly identify and then recommend new apps of high quality is a challenging issue. Here, a fundamental requirement is the capability to accurately measure an app's quality based on its inborn features, rather than user-generated features. Since users obtain first-hand experience of an app by interacting with its views, we speculate that the inborn features are largely related to the visual quality of individual views in an app and the ways the views switch to one another. In this work, we propose AppQ, a novel app quality grading and recommendation system that extracts inborn features of apps based on app source code. In particular, AppQ works in parallel to perform code analysis to extract app-level features as well as dynamic analysis to capture view-level layout hierarchy and the switching among views. Each app is then expressed as an attributed view graph, which is converted into a vector and fed to classifiers for recognizing its quality classes. Our evaluation with an app dataset from Google Play reports that AppQ achieves the best performance with accuracy of 85.0\%. This shows a lot of promise to warm-start app grading and recommendation systems with AppQ.
Online Learning of Optimally Diverse Rankings
Sep 13, 2021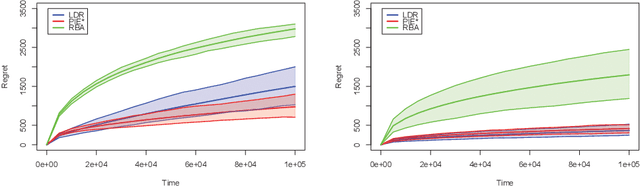
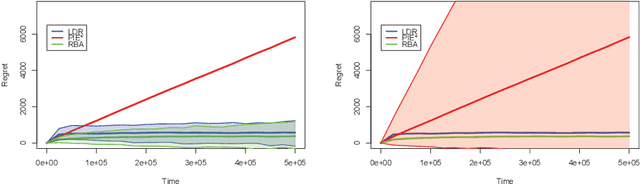
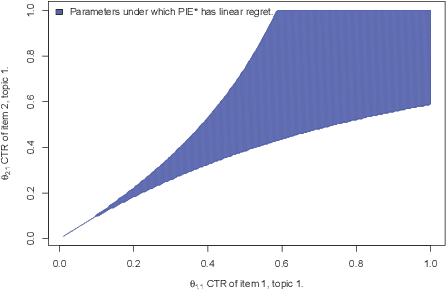
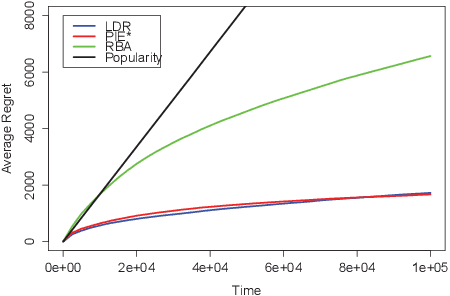
Search engines answer users' queries by listing relevant items (e.g. documents, songs, products, web pages, ...). These engines rely on algorithms that learn to rank items so as to present an ordered list maximizing the probability that it contains relevant item. The main challenge in the design of learning-to-rank algorithms stems from the fact that queries often have different meanings for different users. In absence of any contextual information about the query, one often has to adhere to the {\it diversity} principle, i.e., to return a list covering the various possible topics or meanings of the query. To formalize this learning-to-rank problem, we propose a natural model where (i) items are categorized into topics, (ii) users find items relevant only if they match the topic of their query, and (iii) the engine is not aware of the topic of an arriving query, nor of the frequency at which queries related to various topics arrive, nor of the topic-dependent click-through-rates of the items. For this problem, we devise LDR (Learning Diverse Rankings), an algorithm that efficiently learns the optimal list based on users' feedback only. We show that after $T$ queries, the regret of LDR scales as $O((N-L)\log(T))$ where $N$ is the number of all items. We further establish that this scaling cannot be improved, i.e., LDR is order optimal. Finally, using numerical experiments on both artificial and real-world data, we illustrate the superiority of LDR compared to existing learning-to-rank algorithms.
* 26 pages, 4 Figures, accepted in ACM SIGMETRICS 2018
Contextual Mood Analysis with Knowledge Graph Representation for Hindi Song Lyrics in Devanagari Script
Aug 16, 2021
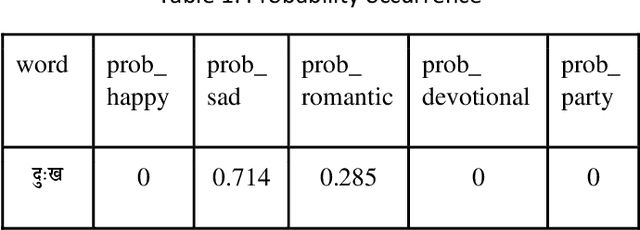
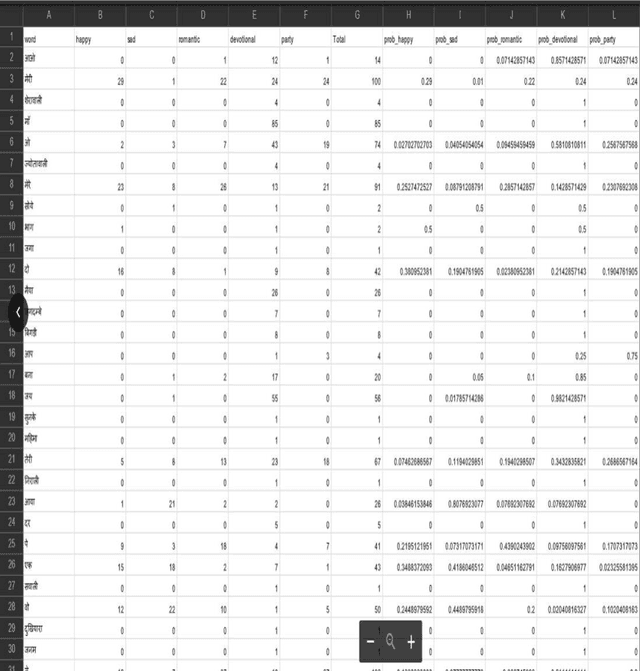
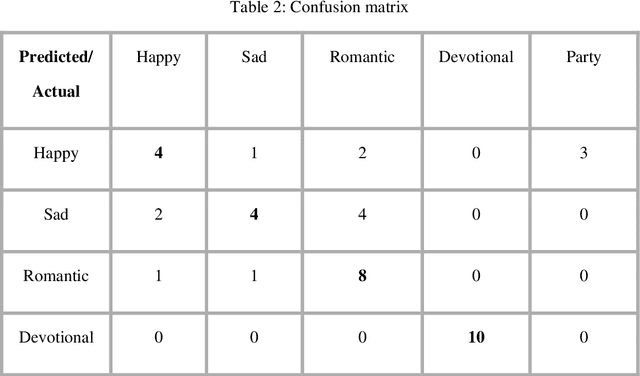
Lyrics play a significant role in conveying the song's mood and are information to understand and interpret music communication. Conventional natural language processing approaches use translation of the Hindi text into English for analysis. This approach is not suitable for lyrics as it is likely to lose the inherent intended contextual meaning. Thus, the need was identified to develop a system for Devanagari text analysis. The data set of 300 song lyrics with equal distribution in five different moods is used for the experimentation. The proposed system performs contextual mood analysis of Hindi song lyrics in Devanagari text format. The contextual analysis is stored as a knowledge base, updated using an incremental learning approach with new data. Contextual knowledge graph with moods and associated important contextual terms provides the graphical representation of the lyric data set used. The testing results show 64% accuracy for the mood prediction. This work can be easily extended to applications related to Hindi literary work such as summarization, indexing, contextual retrieval, context-based classification and grouping of documents.
VGF-Net: Visual-Geometric Fusion Learning for Simultaneous Drone Navigation and Height Mapping
Apr 07, 2021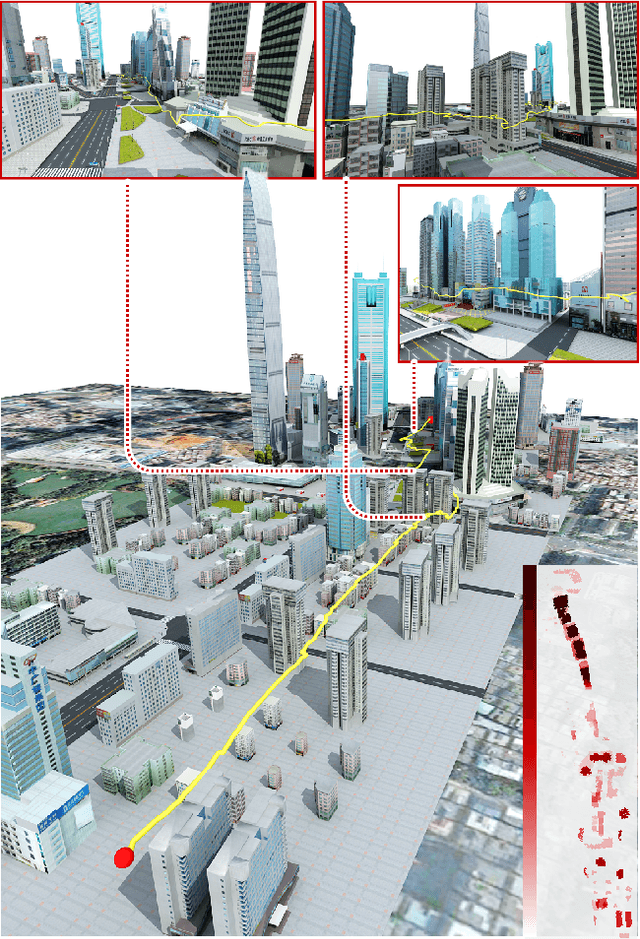
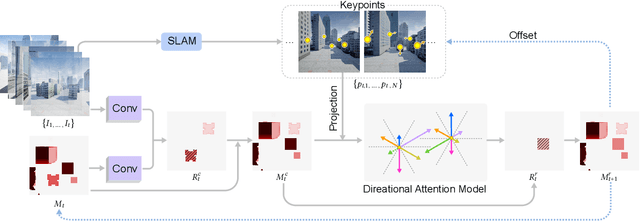
The drone navigation requires the comprehensive understanding of both visual and geometric information in the 3D world. In this paper, we present a Visual-Geometric Fusion Network(VGF-Net), a deep network for the fusion analysis of visual/geometric data and the construction of 2.5D height maps for simultaneous drone navigation in novel environments. Given an initial rough height map and a sequence of RGB images, our VGF-Net extracts the visual information of the scene, along with a sparse set of 3D keypoints that capture the geometric relationship between objects in the scene. Driven by the data, VGF-Net adaptively fuses visual and geometric information, forming a unified Visual-Geometric Representation. This representation is fed to a new Directional Attention Model(DAM), which helps enhance the visual-geometric object relationship and propagates the informative data to dynamically refine the height map and the corresponding keypoints. An entire end-to-end information fusion and mapping system is formed, demonstrating remarkable robustness and high accuracy on the autonomous drone navigation across complex indoor and large-scale outdoor scenes. The dataset can be found in http://vcc.szu.edu.cn/research/2021/VGFNet.
* Accepted by CVM 2021
Multiscale Laplacian Learning
Sep 08, 2021
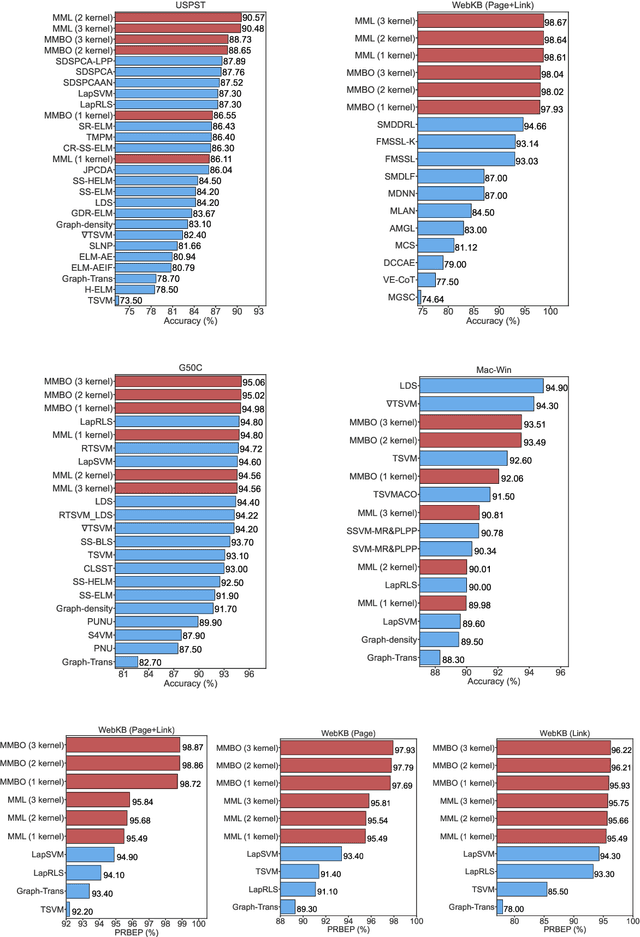
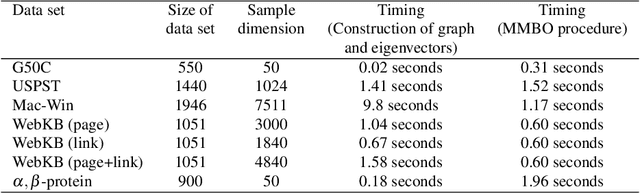
Machine learning methods have greatly changed science, engineering, finance, business, and other fields. Despite the tremendous accomplishments of machine learning and deep learning methods, many challenges still remain. In particular, the performance of machine learning methods is often severely affected in case of diverse data, usually associated with smaller data sets or data related to areas of study where the size of the data sets is constrained by the complexity and/or high cost of experiments. Moreover, data with limited labeled samples is a challenge to most learning approaches. In this paper, the aforementioned challenges are addressed by integrating graph-based frameworks, multiscale structure, modified and adapted optimization procedures and semi-supervised techniques. This results in two innovative multiscale Laplacian learning (MLL) approaches for machine learning tasks, such as data classification, and for tackling diverse data, data with limited samples and smaller data sets. The first approach, called multikernel manifold learning (MML), integrates manifold learning with multikernel information and solves a regularization problem consisting of a loss function and a warped kernel regularizer using multiscale graph Laplacians. The second approach, called the multiscale MBO (MMBO) method, introduces multiscale Laplacians to a modification of the famous classical Merriman-Bence-Osher (MBO) scheme, and makes use of fast solvers for finding the approximations to the extremal eigenvectors of the graph Laplacian. We demonstrate the performance of our methods experimentally on a variety of data sets, such as biological, text and image data, and compare them favorably to existing approaches.
Deep Learning Approach for Hyperspectral Image Demosaicking, Spectral Correction and High-resolution RGB Reconstruction
Sep 03, 2021

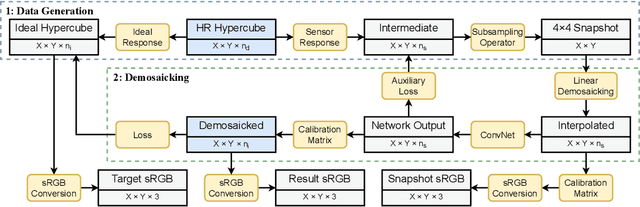
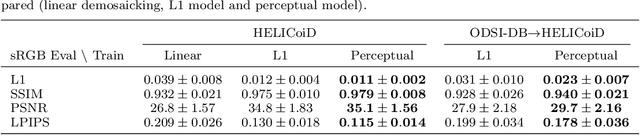
Hyperspectral imaging is one of the most promising techniques for intraoperative tissue characterisation. Snapshot mosaic cameras, which can capture hyperspectral data in a single exposure, have the potential to make a real-time hyperspectral imaging system for surgical decision-making possible. However, optimal exploitation of the captured data requires solving an ill-posed demosaicking problem and applying additional spectral corrections to recover spatial and spectral information of the image. In this work, we propose a deep learning-based image demosaicking algorithm for snapshot hyperspectral images using supervised learning methods. Due to the lack of publicly available medical images acquired with snapshot mosaic cameras, a synthetic image generation approach is proposed to simulate snapshot images from existing medical image datasets captured by high-resolution, but slow, hyperspectral imaging devices. Image reconstruction is achieved using convolutional neural networks for hyperspectral image super-resolution, followed by cross-talk and leakage correction using a sensor-specific calibration matrix. The resulting demosaicked images are evaluated both quantitatively and qualitatively, showing clear improvements in image quality compared to a baseline demosaicking method using linear interpolation. Moreover, the fast processing time of~45\,ms of our algorithm to obtain super-resolved RGB or oxygenation saturation maps per image frame for a state-of-the-art snapshot mosaic camera demonstrates the potential for its seamless integration into real-time surgical hyperspectral imaging applications.
Generation of the NIR spectral Band for Satellite Images with Convolutional Neural Networks
Jun 13, 2021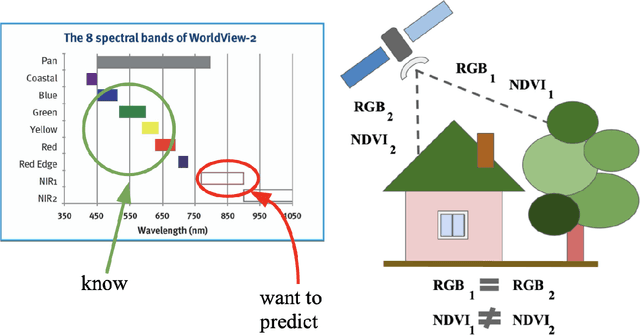
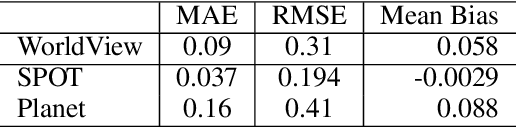
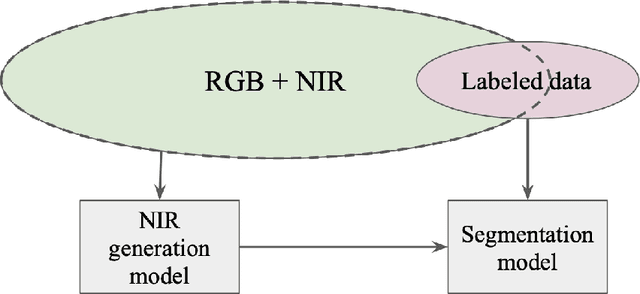
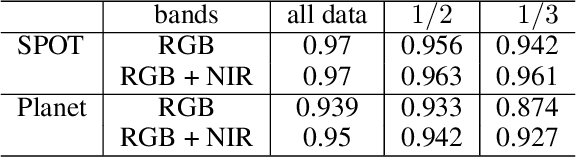
The near-infrared (NIR) spectral range (from 780 to 2500 nm) of the multispectral remote sensing imagery provides vital information for the landcover classification, especially concerning the vegetation assessment. Despite the usefulness of NIR, common RGB is not always accompanied by it. Modern achievements in image processing via deep neural networks allow generating artificial spectral information, such as for the image colorization problem. In this research, we aim to investigate whether this approach can produce not only visually similar images but also an artificial spectral band that can improve the performance of computer vision algorithms for solving remote sensing tasks. We study the generative adversarial network (GAN) approach in the task of the NIR band generation using just RGB channels of high-resolution satellite imagery. We evaluate the impact of a generated channel on the model performance for solving the forest segmentation task. Our results show an increase in model accuracy when using generated NIR comparing to the baseline model that uses only RGB (0.947 and 0.914 F1-score accordingly). Conducted study shows the advantages of generating the extra band and its implementation in applied challenges reducing the required amount of labeled data.
Z-GCNETs: Time Zigzags at Graph Convolutional Networks for Time Series Forecasting
May 10, 2021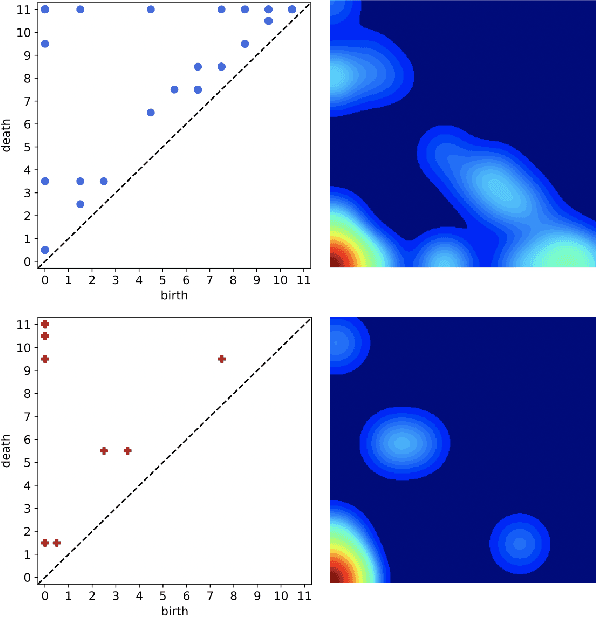
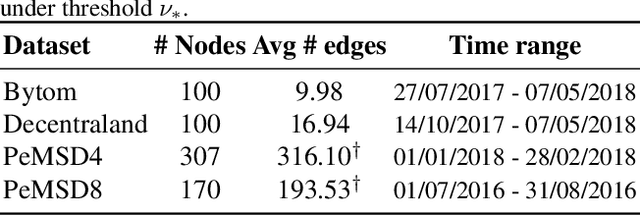
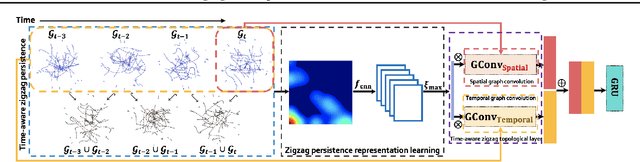
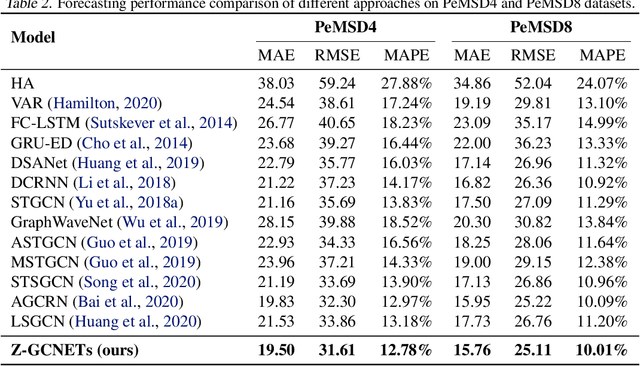
There recently has been a surge of interest in developing a new class of deep learning (DL) architectures that integrate an explicit time dimension as a fundamental building block of learning and representation mechanisms. In turn, many recent results show that topological descriptors of the observed data, encoding information on the shape of the dataset in a topological space at different scales, that is, persistent homology of the data, may contain important complementary information, improving both performance and robustness of DL. As convergence of these two emerging ideas, we propose to enhance DL architectures with the most salient time-conditioned topological information of the data and introduce the concept of zigzag persistence into time-aware graph convolutional networks (GCNs). Zigzag persistence provides a systematic and mathematically rigorous framework to track the most important topological features of the observed data that tend to manifest themselves over time. To integrate the extracted time-conditioned topological descriptors into DL, we develop a new topological summary, zigzag persistence image, and derive its theoretical stability guarantees. We validate the new GCNs with a time-aware zigzag topological layer (Z-GCNETs), in application to traffic forecasting and Ethereum blockchain price prediction. Our results indicate that Z-GCNET outperforms 13 state-of-the-art methods on 4 time series datasets.