 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Pan-sharpening via High-pass Modification Convolutional Neural Network
May 24, 2021
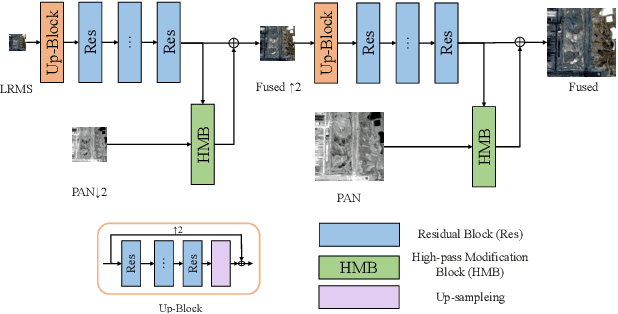
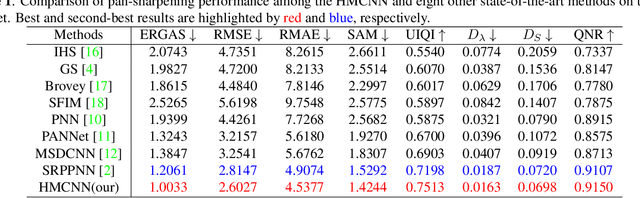
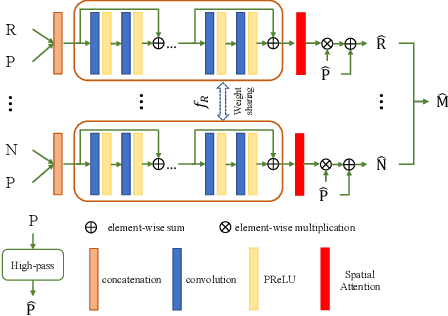

Most existing deep learning-based pan-sharpening methods have several widely recognized issues, such as spectral distortion and insufficient spatial texture enhancement, we propose a novel pan-sharpening convolutional neural network based on a high-pass modification block. Different from existing methods, the proposed block is designed to learn the high-pass information, leading to enhance spatial information in each band of the multi-spectral-resolution images. To facilitate the generation of visually appealing pan-sharpened images, we propose a perceptual loss function and further optimize the model based on high-level features in the near-infrared space. Experiments demonstrate the superior performance of the proposed method compared to the state-of-the-art pan-sharpening methods, both quantitatively and qualitatively. The proposed model is open-sourced at https://github.com/jiaming-wang/HMB.
Neural Human Deformation Transfer
Sep 03, 2021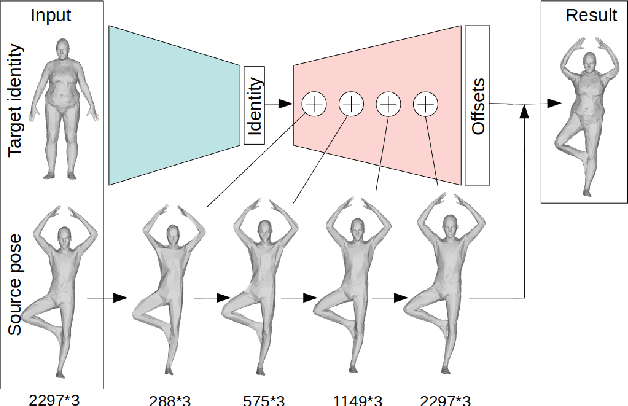

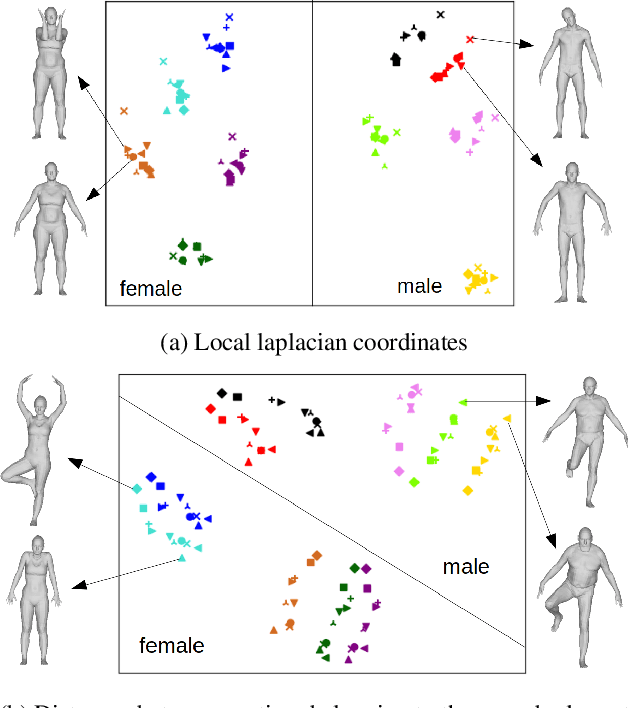
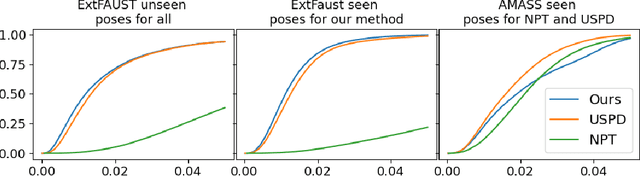
We consider the problem of human deformation transfer, where the goal is to retarget poses between different characters. Traditional methods that tackle this problem require a clear definition of the pose, and use this definition to transfer poses between characters. In this work, we take a different approach and transform the identity of a character into a new identity without modifying the character's pose. This offers the advantage of not having to define equivalences between 3D human poses, which is not straightforward as poses tend to change depending on the identity of the character performing them, and as their meaning is highly contextual. To achieve the deformation transfer, we propose a neural encoder-decoder architecture where only identity information is encoded and where the decoder is conditioned on the pose. We use pose independent representations, such as isometry-invariant shape characteristics, to represent identity features. Our model uses these features to supervise the prediction of offsets from the deformed pose to the result of the transfer. We show experimentally that our method outperforms state-of-the-art methods both quantitatively and qualitatively, and generalises better to poses not seen during training. We also introduce a fine-tuning step that allows to obtain competitive results for extreme identities, and allows to transfer simple clothing.
Uncoded Binary Signaling through Modulo AWGN Channel
May 20, 2021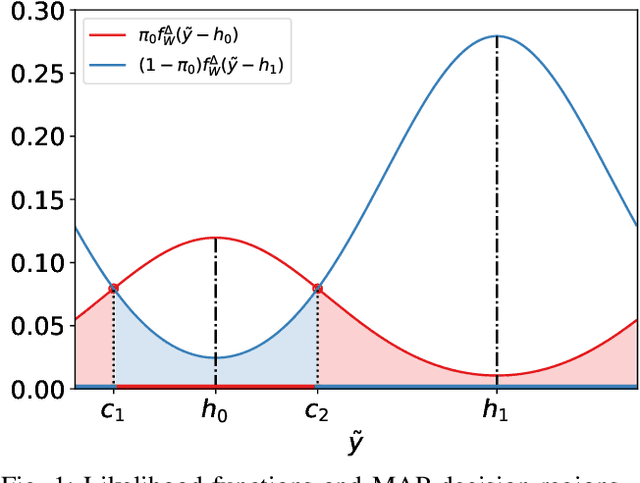
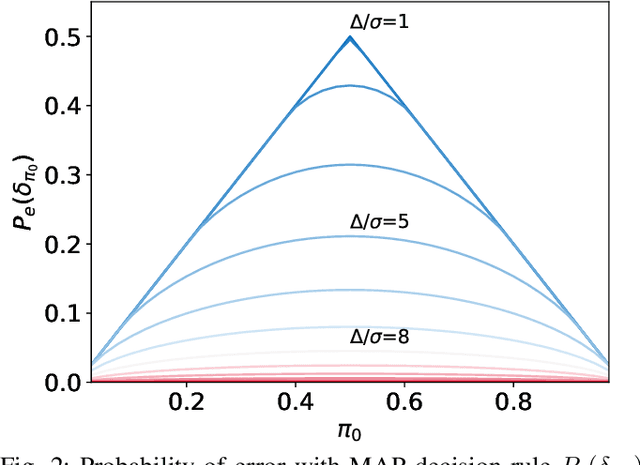
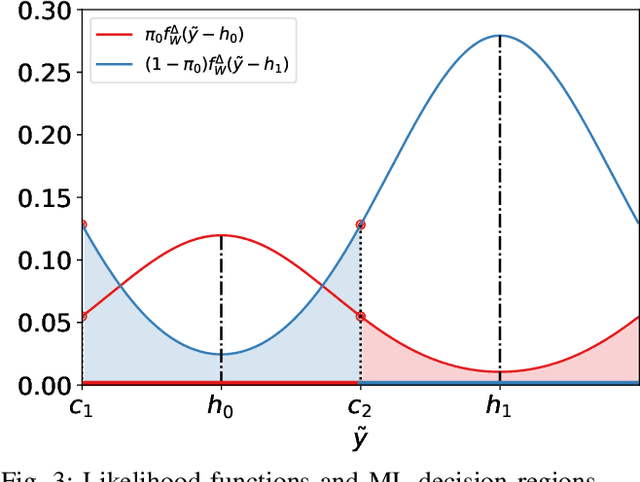
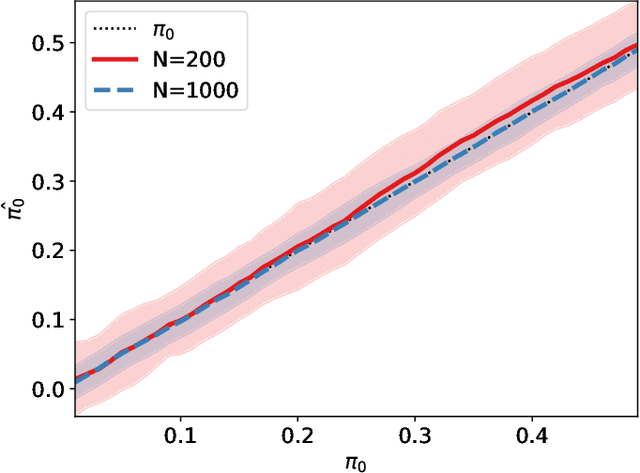
Modulo-wrapping receivers have attracted interest in several areas of digital communications, including precoding and lattice coding. The asymptotic capacity and error performance of the modulo AWGN channel have been well established. However, due to underlying assumptions of the asymptotic analyses, these findings might not always be realistic in physical world applications, which are often dimension- or delay-limited. In this work, the optimum ways to achieve minimum probability of error for binary signaling through a scalar modulo AWGN channel is examined under different scenarios where the receiver has access to full or partial information. In case of partial information at the receiver, an iterative estimation rule is proposed to reduce the error rate, and the performance of different estimators are demonstrated in simulated experiments.
Situated Conditional Reasoning
Sep 03, 2021
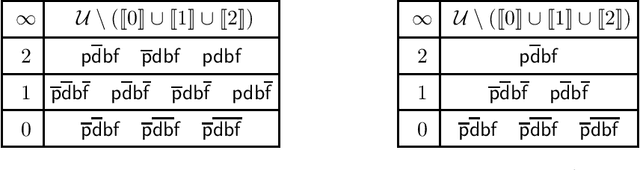

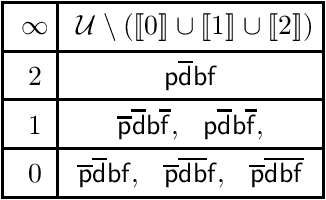
Conditionals are useful for modelling, but are not always sufficiently expressive for capturing information accurately. In this paper we make the case for a form of conditional that is situation-based. These conditionals are more expressive than classical conditionals, are general enough to be used in several application domains, and are able to distinguish, for example, between expectations and counterfactuals. Formally, they are shown to generalise the conditional setting in the style of Kraus, Lehmann, and Magidor. We show that situation-based conditionals can be described in terms of a set of rationality postulates. We then propose an intuitive semantics for these conditionals, and present a representation result which shows that our semantic construction corresponds exactly to the description in terms of postulates. With the semantics in place, we proceed to define a form of entailment for situated conditional knowledge bases, which we refer to as minimal closure. It is reminiscent of and, indeed, inspired by, the version of entailment for propositional conditional knowledge bases known as rational closure. Finally, we proceed to show that it is possible to reduce the computation of minimal closure to a series of propositional entailment and satisfiability checks. While this is also the case for rational closure, it is somewhat surprising that the result carries over to minimal closure.
Including Sparse Production Knowledge into Variational Autoencoders to Increase Anomaly Detection Reliability
Mar 24, 2021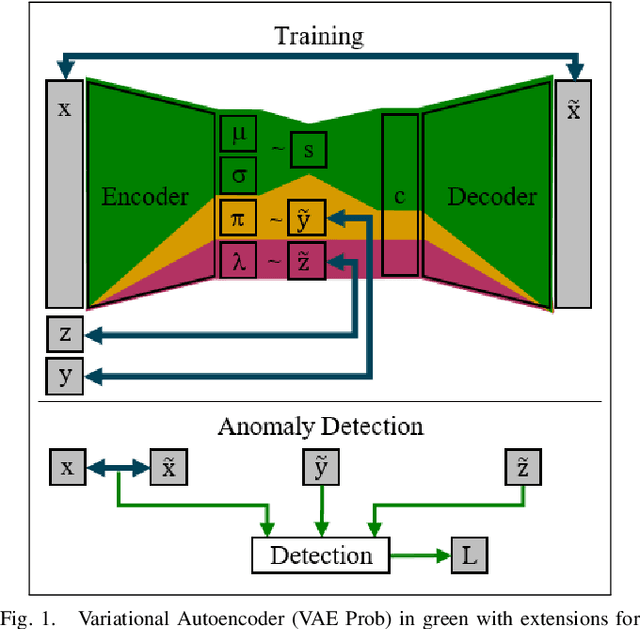
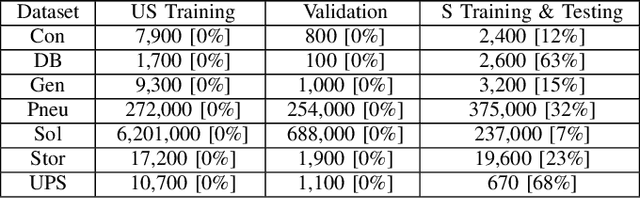
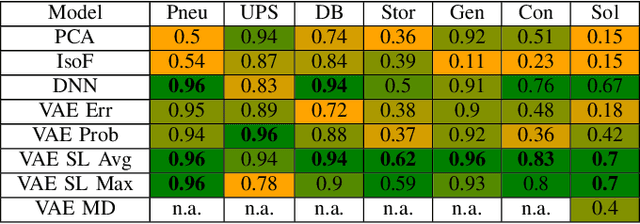
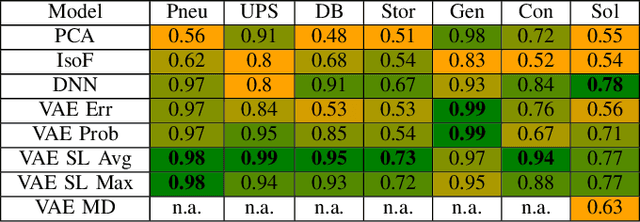
Digitalization leads to data transparency for production systems that we can benefit from with data-driven analysis methods like neural networks. For example, automated anomaly detection enables saving resources and optimizing the production. We study using rarely occurring information about labeled anomalies into Variational Autoencoder neural network structures to overcome information deficits of supervised and unsupervised approaches. This method outperforms all other models in terms of accuracy, precision, and recall. We evaluate the following methods: Principal Component Analysis, Isolation Forest, Classifying Neural Networks, and Variational Autoencoders on seven time series datasets to find the best performing detection methods. We extend this idea to include more infrequently occurring meta information about production processes. This use of sparse labels, both of anomalies or production data, allows to harness any additional information available for increasing anomaly detection performance.
YES SIR!Optimizing Semantic Space of Negatives with Self-Involvement Ranker
Sep 14, 2021
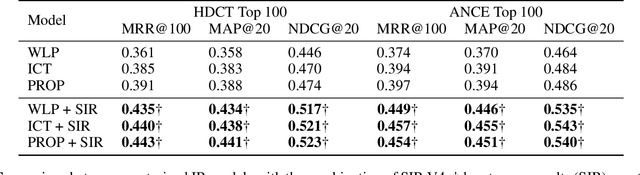
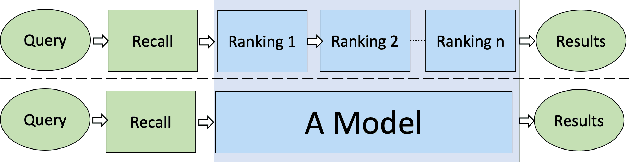
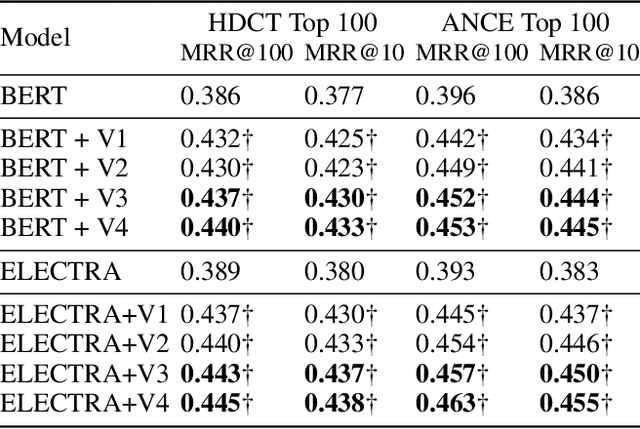
Pre-trained model such as BERT has been proved to be an effective tool for dealing with Information Retrieval (IR) problems. Due to its inspiring performance, it has been widely used to tackle with real-world IR problems such as document ranking. Recently, researchers have found that selecting "hard" rather than "random" negative samples would be beneficial for fine-tuning pre-trained models on ranking tasks. However, it remains elusive how to leverage hard negative samples in a principled way. To address the aforementioned issues, we propose a fine-tuning strategy for document ranking, namely Self-Involvement Ranker (SIR), to dynamically select hard negative samples to construct high-quality semantic space for training a high-quality ranking model. Specifically, SIR consists of sequential compressors implemented with pre-trained models. Front compressor selects hard negative samples for rear compressor. Moreover, SIR leverages supervisory signal to adaptively adjust semantic space of negative samples. Finally, supervisory signal in rear compressor is computed based on condition probability and thus can control sample dynamic and further enhance the model performance. SIR is a lightweight and general framework for pre-trained models, which simplifies the ranking process in industry practice. We test our proposed solution on MS MARCO with document ranking setting, and the results show that SIR can significantly improve the ranking performance of various pre-trained models. Moreover, our method became the new SOTA model anonymously on MS MARCO Document ranking leaderboard in May 2021.
LightMove: A Lightweight Next-POI Recommendation for Taxicab Rooftop Advertising
Aug 11, 2021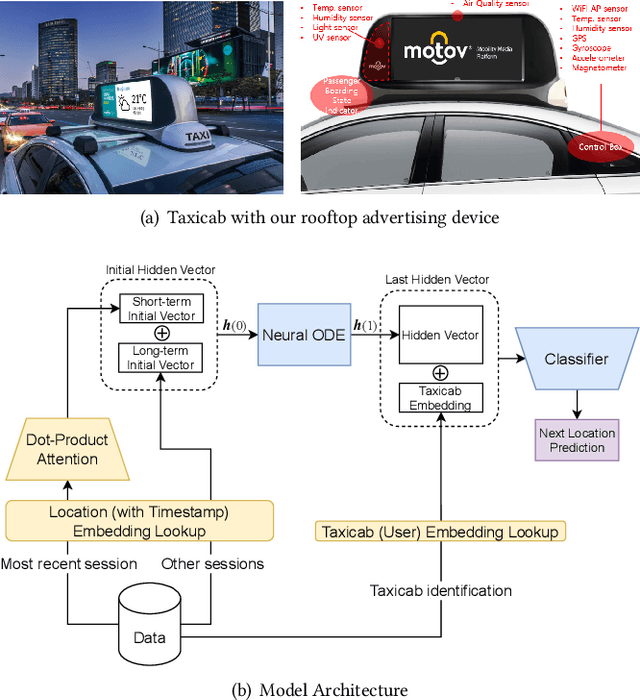

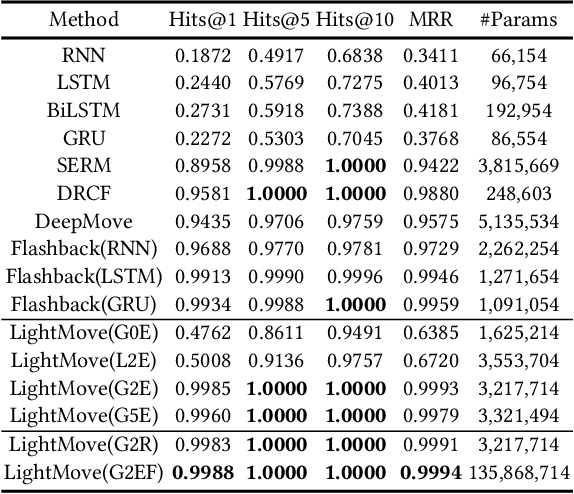
Mobile digital billboards are an effective way to augment brand-awareness. Among various such mobile billboards, taxicab rooftop devices are emerging in the market as a brand new media. Motov is a leading company in South Korea in the taxicab rooftop advertising market. In this work, we present a lightweight yet accurate deep learning-based method to predict taxicabs' next locations to better prepare for targeted advertising based on demographic information of locations. Considering the fact that next POI recommendation datasets are frequently sparse, we design our presented model based on neural ordinary differential equations (NODEs), which are known to be robust to sparse/incorrect input, with several enhancements. Our model, which we call LightMove, has a larger prediction accuracy, a smaller number of parameters, and/or a smaller training/inference time, when evaluating with various datasets, in comparison with state-of-the-art models.
An Interaction-based Convolutional Neural Network (ICNN) Towards Better Understanding of COVID-19 X-ray Images
Jun 13, 2021
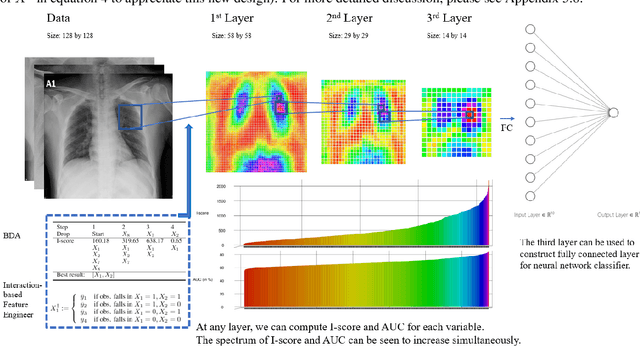

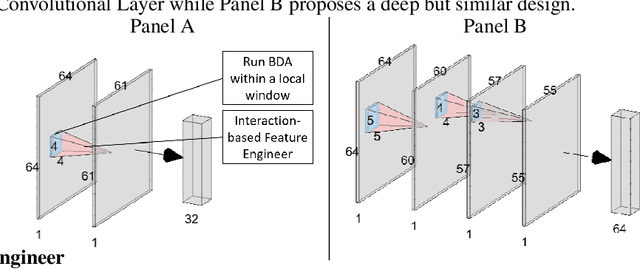
The field of Explainable Artificial Intelligence (XAI) aims to build explainable and interpretable machine learning (or deep learning) methods without sacrificing prediction performance. Convolutional Neural Networks (CNNs) have been successful in making predictions, especially in image classification. However, these famous deep learning models use tens of millions of parameters based on a large number of pre-trained filters which have been repurposed from previous data sets. We propose a novel Interaction-based Convolutional Neural Network (ICNN) that does not make assumptions about the relevance of local information. Instead, we use a model-free Influence Score (I-score) to directly extract the influential information from images to form important variable modules. We demonstrate that the proposed method produces state-of-the-art prediction performance of 99.8% on a real-world data set classifying COVID-19 Chest X-ray images without sacrificing the explanatory power of the model. This proposed design can efficiently screen COVID-19 patients before human diagnosis, and will be the benchmark for addressing future XAI problems in large-scale data sets.
Throughput Maximization for IRS-Assisted Wireless Powered Hybrid NOMA and TDMA
Apr 27, 2021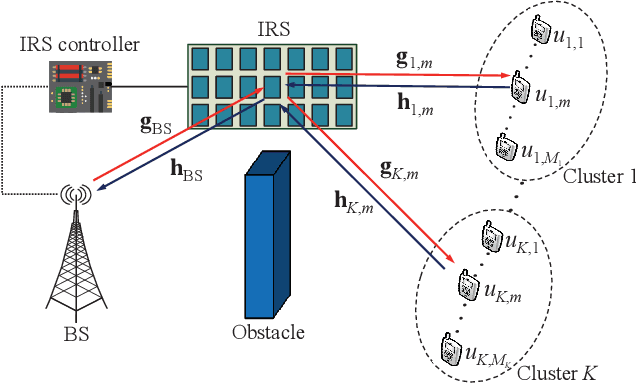
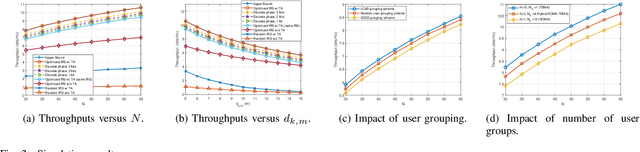
The high reflect beamforming gain of the intelligent reflecting surface (IRS) makes it appealing not only for wireless information transmission but also for wireless power transfer. In this letter, we consider an IRS-assisted wireless powered communication network, where a base station (BS) transmits energy to multiple users grouped into multiple clusters in the downlink, and the clustered users transmit information to the BS in the manner of hybrid non-orthogonal multiple access and time division multiple access in the uplink. We investigate optimizing the reflect beamforming of the IRS and the time allocation among the BS's power transfer and different user clusters' information transmission to maximize the throughput of the network, and we propose an efficient algorithm based on the block coordinate ascent, semidefinite relaxation, and sequential rank-one constraint relaxation techniques to solve the resultant problem. Simulation results have verified the effectiveness of the proposed algorithm and have shown the impact of user clustering setup on the throughput performance of the network.
Ethical AI for Social Good
Jul 14, 2021

The concept of AI for Social Good(AI4SG) is gaining momentum in both information societies and the AI community. Through all the advancement of AI-based solutions, it can solve societal issues effectively. To date, however, there is only a rudimentary grasp of what constitutes AI socially beneficial in principle, what constitutes AI4SG in reality, and what are the policies and regulations needed to ensure it. This paper fills the vacuum by addressing the ethical aspects that are critical for future AI4SG efforts. Some of these characteristics are new to AI, while others have greater importance due to its usage.