 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SSSNET: Semi-Supervised Signed Network Clustering
Oct 13, 2021
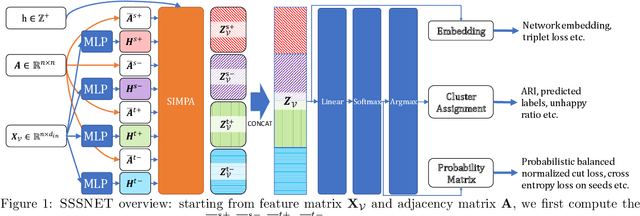
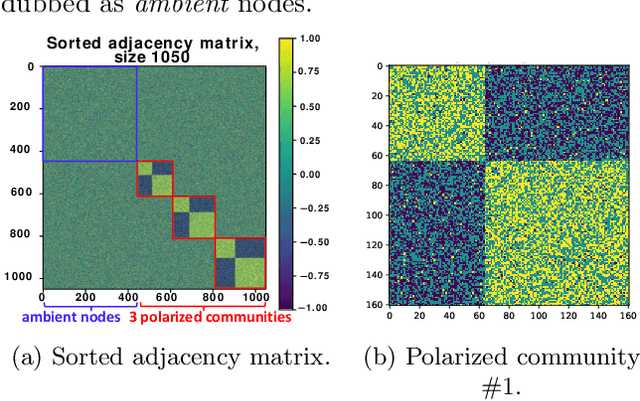
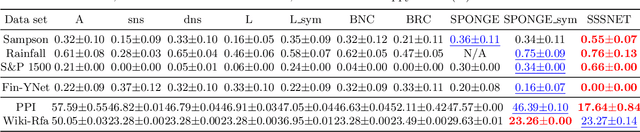
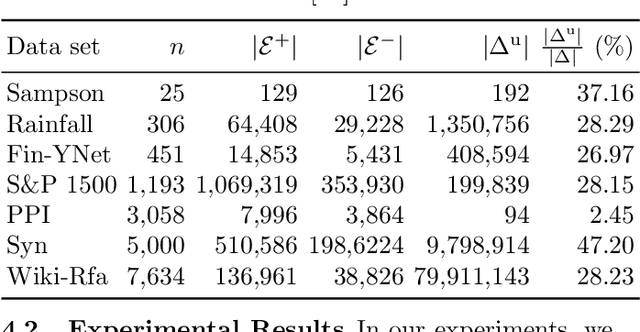
Node embeddings are a powerful tool in the analysis of networks; yet, their full potential for the important task of node clustering has not been fully exploited. In particular, most state-of-the-art methods generating node embeddings of signed networks focus on link sign prediction, and those that pertain to node clustering are usually not graph neural network (GNN) methods. Here, we introduce a novel probabilistic balanced normalized cut loss for training nodes in a GNN framework for semi-supervised signed network clustering, called SSSNET. The method is end-to-end in combining embedding generation and clustering without an intermediate step; it has node clustering as main focus, with an emphasis on polarization effects arising in networks. The main novelty of our approach is a new take on the role of social balance theory for signed network embeddings. The standard heuristic for justifying the criteria for the embeddings hinges on the assumption that "an enemy's enemy is a friend". Here, instead, a neutral stance is assumed on whether or not the enemy of an enemy is a friend. Experimental results on various data sets, including a synthetic signed stochastic block model, a polarized version of it, and real-world data at different scales, demonstrate that SSSNET can achieve comparable or better results than state-of-the-art spectral clustering methods, for a wide range of noise and sparsity levels. SSSNET complements existing methods through the possibility of including exogenous information, in the form of node-level features or labels.
S3G-ARM: Highly Compressive Visual Self-localization from Sequential Semantic Scene Graph Using Absolute and Relative Measurements
Sep 09, 2021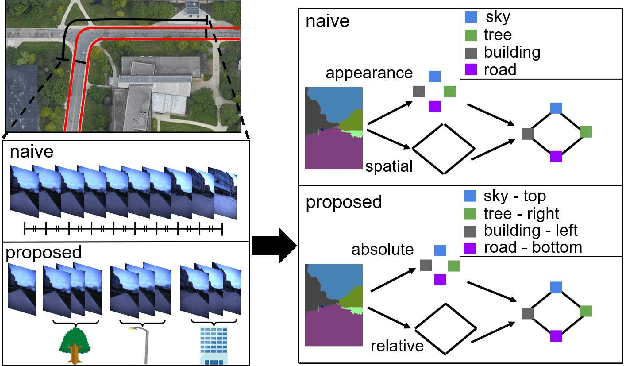
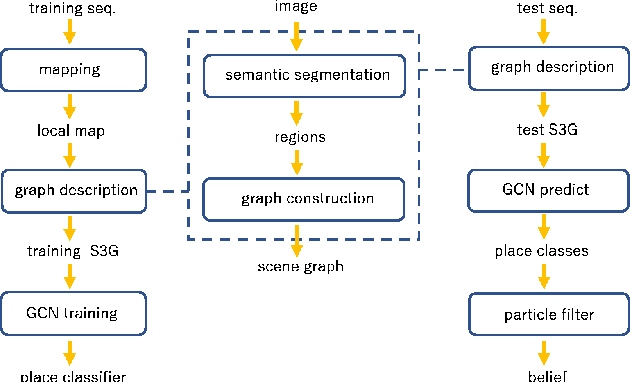
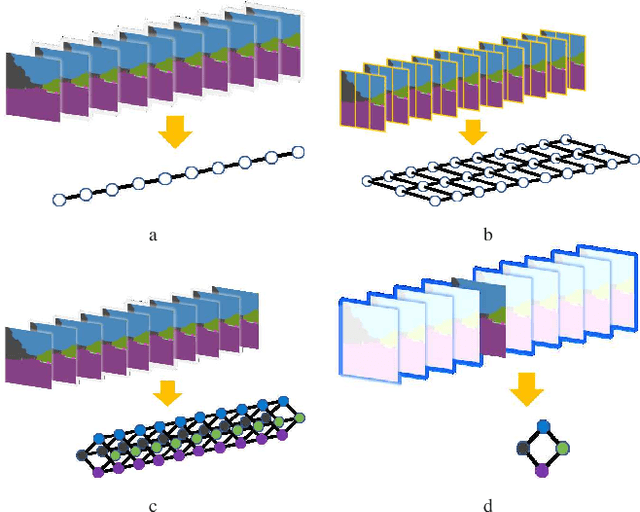
In this paper, we address the problem of image sequence-based self-localization (ISS) from a new highly compressive scene representation called sequential semantic scene graph (S3G). Recent developments in deep graph convolutional neural networks (GCNs) have enabled a highly compressive visual place classifier (VPC) that can use a scene graph as the input modality. However, in such a highly compressive application, the amount of information lost in the image-to-graph mapping is significant and can damage the classification performance. To address this issue, we propose a pair of similarity-preserving mappings, image-to-nodes and image-to-edges, such that the nodes and edges act as absolute and relative features, respectively, that complement each other. Moreover, the proposed GCN-VPC is applied to a new task of viewpoint planning (VP) of the query image sequence, which contributes to further improvement in the VPC performance. Experiments using the public NCLT dataset validated the effectiveness of the proposed method.
SlowFast Rolling-Unrolling LSTMs for Action Anticipation in Egocentric Videos
Sep 02, 2021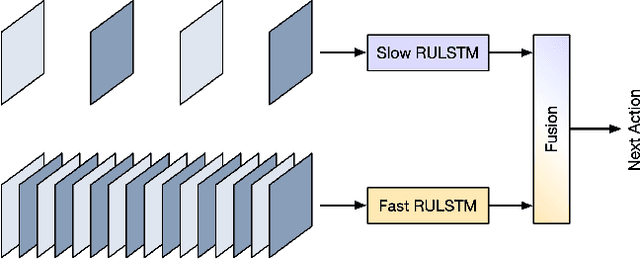
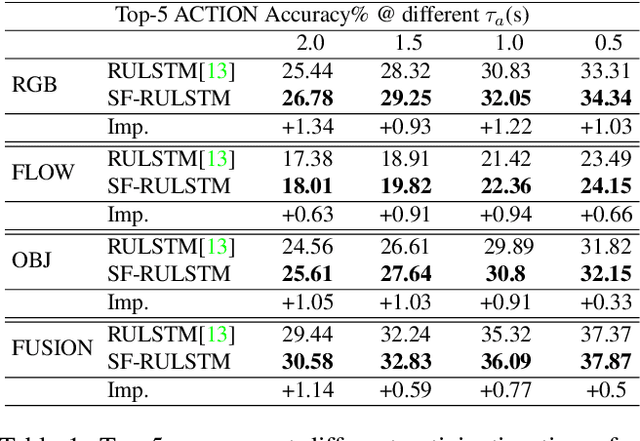
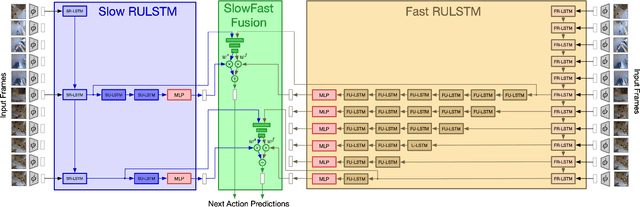
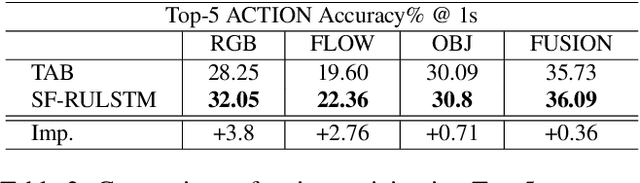
Action anticipation in egocentric videos is a difficult task due to the inherently multi-modal nature of human actions. Additionally, some actions happen faster or slower than others depending on the actor or surrounding context which could vary each time and lead to different predictions. Based on this idea, we build upon RULSTM architecture, which is specifically designed for anticipating human actions, and propose a novel attention-based technique to evaluate, simultaneously, slow and fast features extracted from three different modalities, namely RGB, optical flow, and extracted objects. Two branches process information at different time scales, i.e., frame-rates, and several fusion schemes are considered to improve prediction accuracy. We perform extensive experiments on EpicKitchens-55 and EGTEA Gaze+ datasets, and demonstrate that our technique systematically improves the results of RULSTM architecture for Top-5 accuracy metric at different anticipation times.
Index Modulation with Circularly-Shifted Chirps for Dual-Function Radar and Communications
Sep 28, 2021

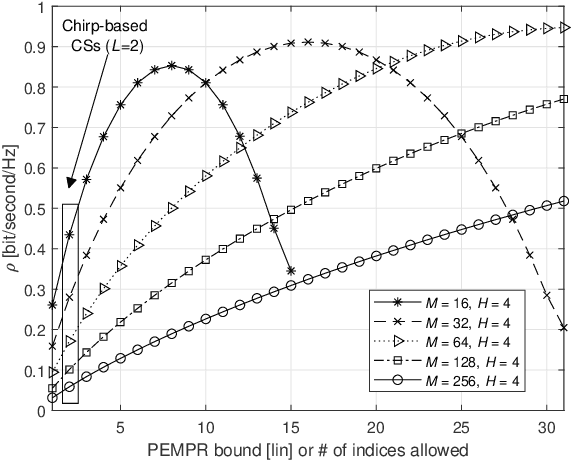
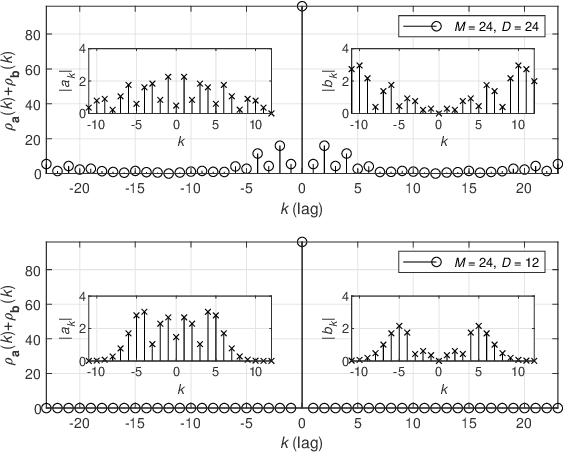
In this study, we propose index modulation (IM) with circularly-shifted chirps (CSCs) (CSC-IM) for dual-function radar and communication (DFRC) systems. The proposed scheme encodes the information bits with the CSC indices and the phase-shift keying (PSK) symbols. It allows the receiver to exploit the frequency selectivity naturally in fading channels by combining IM and wideband CSCs. It also leverages the fact that a CSC is a constant-envelope signal to achieve a controllable peak-to-mean envelope power ratio (PMEPR). For radar functionality, CSC-IM maintains the good autocorrelation (AC) properties of a chirp by ensuring that the transmitted CSCs are separated apart sufficiently in the time domain through index separation (IS). We investigate the impact of IS on spectral efficiency (SE) and obtain the corresponding mapping functions. For theoretical results, we derive the union bound (UB) of the block error rate (BLER) for arbitrary chirps and the Cramer-Rao lower bounds (CRLBs) for the range and reflection coefficients for the matched filter (MF)-based estimation. We also prove that complementary sequences (CSs) can be constructed through CSCs by linearly combining the Fourier series of CSCs. Finally, through comprehensive comparisons, we demonstrate the efficacy of the proposed scheme for DFRC scenarios.
A First-Occupancy Representation for Reinforcement Learning
Sep 28, 2021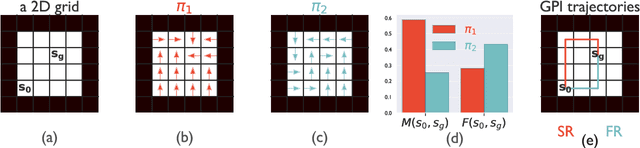
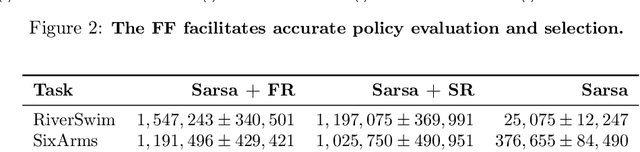
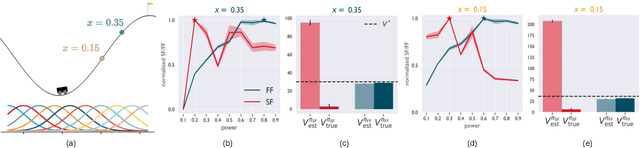
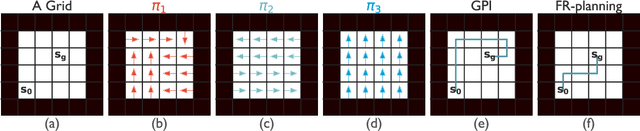
Both animals and artificial agents benefit from state representations that support rapid transfer of learning across tasks and which enable them to efficiently traverse their environments to reach rewarding states. The successor representation (SR), which measures the expected cumulative, discounted state occupancy under a fixed policy, enables efficient transfer to different reward structures in an otherwise constant Markovian environment and has been hypothesized to underlie aspects of biological behavior and neural activity. However, in the real world, rewards may move or only be available for consumption once, may shift location, or agents may simply aim to reach goal states as rapidly as possible without the constraint of artificially imposed task horizons. In such cases, the most behaviorally-relevant representation would carry information about when the agent was likely to first reach states of interest, rather than how often it should expect to visit them over a potentially infinite time span. To reflect such demands, we introduce the first-occupancy representation (FR), which measures the expected temporal discount to the first time a state is accessed. We demonstrate that the FR facilitates the selection of efficient paths to desired states, allows the agent, under certain conditions, to plan provably optimal trajectories defined by a sequence of subgoals, and induces similar behavior to animals avoiding threatening stimuli.
Early ICU Mortality Prediction and Survival Analysis for Respiratory Failure
Sep 06, 2021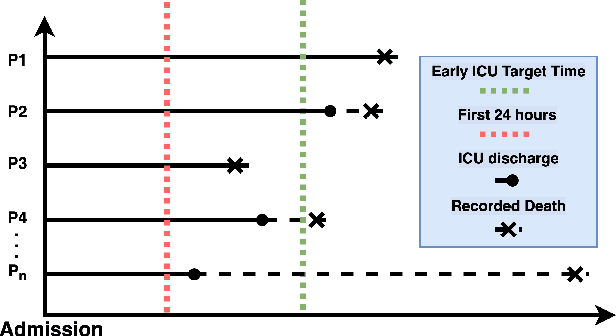
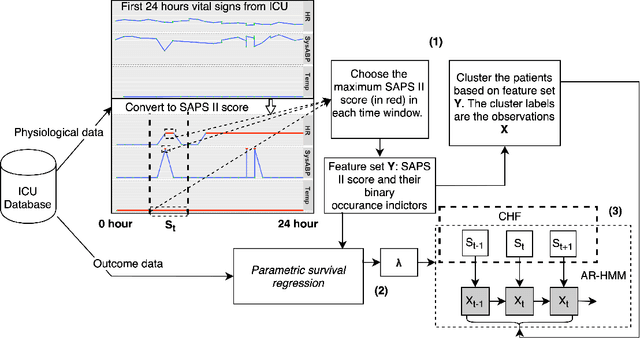
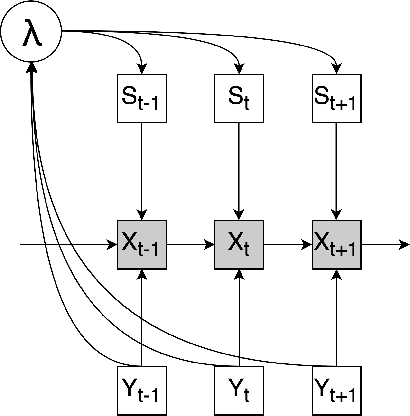
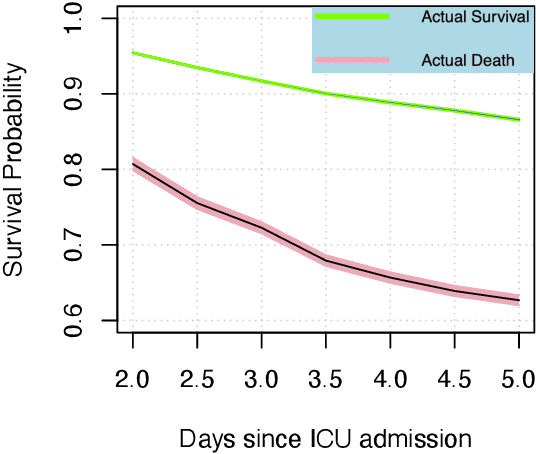
Respiratory failure is the one of major causes of death in critical care unit. During the outbreak of COVID-19, critical care units experienced an extreme shortage of mechanical ventilation because of respiratory failure related syndromes. To help this, the early mortality risk prediction in patients who suffer respiratory failure can provide timely support for clinical treatment and resource management. In the study, we propose a dynamic modeling approach for early mortality risk prediction of the respiratory failure patients based on the first 24 hours ICU physiological data. Our proposed model is validated on the eICU collaborate database. We achieved a high AUROC performance (80-83%) and significantly improved AUCPR 4% on Day 5 since ICU admission, compared to the state-of-art prediction models. In addition, we illustrated that the survival curve includes the time-varying information for the early ICU admission survival analysis.
STaCK: Sentence Ordering with Temporal Commonsense Knowledge
Sep 06, 2021
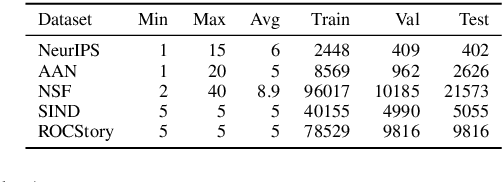
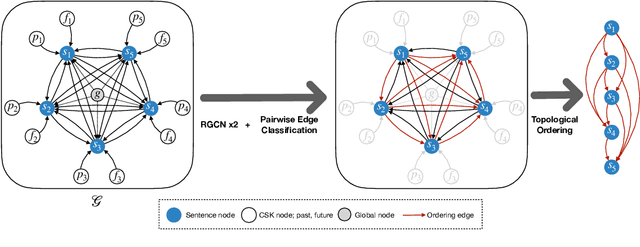
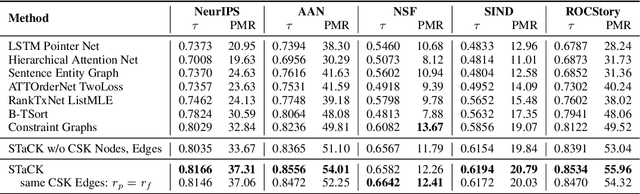
Sentence order prediction is the task of finding the correct order of sentences in a randomly ordered document. Correctly ordering the sentences requires an understanding of coherence with respect to the chronological sequence of events described in the text. Document-level contextual understanding and commonsense knowledge centered around these events are often essential in uncovering this coherence and predicting the exact chronological order. In this paper, we introduce STaCK -- a framework based on graph neural networks and temporal commonsense knowledge to model global information and predict the relative order of sentences. Our graph network accumulates temporal evidence using knowledge of `past' and `future' and formulates sentence ordering as a constrained edge classification problem. We report results on five different datasets, and empirically show that the proposed method is naturally suitable for order prediction. The implementation of this work is publicly available at: https://github.com/declare-lab/sentence-ordering.
AtrialJSQnet: A New Framework for Joint Segmentation and Quantification of Left Atrium and Scars Incorporating Spatial and Shape Information
Aug 11, 2020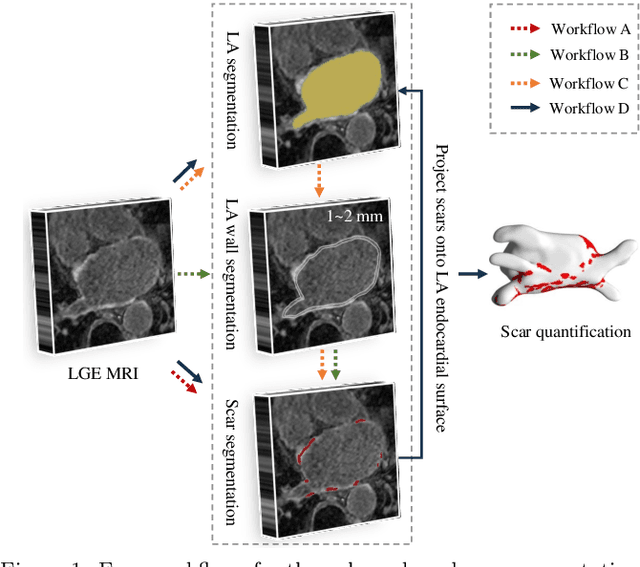
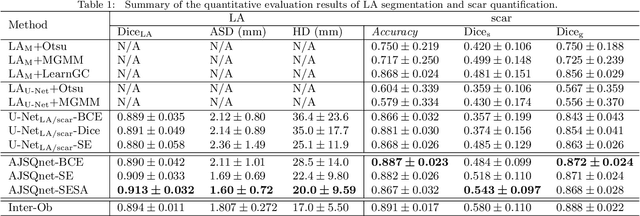
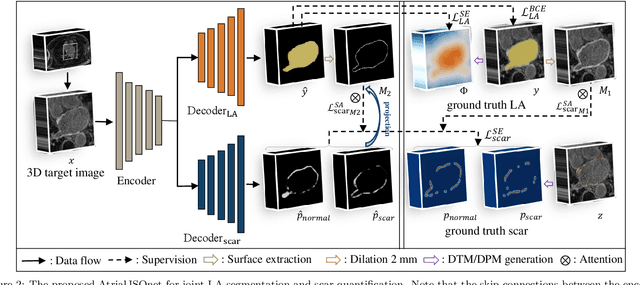
Left atrial (LA) and atrial scar segmentation from late gadolinium enhanced magnetic resonance imaging (LGE MRI) is an important task in clinical practice. %, to guide ablation therapy and predict treatment results for atrial fibrillation (AF) patients. The automatic segmentation is however still challenging, due to the poor image quality, the various LA shapes, the thin wall, and the surrounding enhanced regions. Previous methods normally solved the two tasks independently and ignored the intrinsic spatial relationship between LA and scars. In this work, we develop a new framework, namely AtrialJSQnet, where LA segmentation, scar projection onto the LA surface, and scar quantification are performed simultaneously in an end-to-end style. We propose a mechanism of shape attention (SA) via an explicit surface projection, to utilize the inherent correlation between LA and LA scars. In specific, the SA scheme is embedded into a multi-task architecture to perform joint LA segmentation and scar quantification. Besides, a spatial encoding (SE) loss is introduced to incorporate continuous spatial information of the target, in order to reduce noisy patches in the predicted segmentation. We evaluated the proposed framework on 60 LGE MRIs from the MICCAI2018 LA challenge. Extensive experiments on a public dataset demonstrated the effect of the proposed AtrialJSQnet, which achieved competitive performance over the state-of-the-art. The relatedness between LA segmentation and scar quantification was explicitly explored and has shown significant performance improvements for both tasks. The code and results will be released publicly once the manuscript is accepted for publication via https://zmiclab.github.io/projects.html.
Two-Way Reflecting Communication with UAV-Borne Reconfigurable Intelligent Surfaces
Aug 25, 2021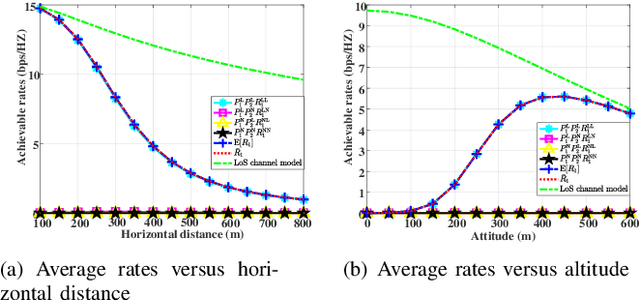
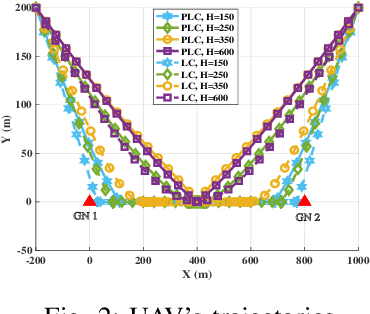
This paper investigates the unmanned aerial vehicle (UAV)-aided two-way reflecting (TWR) communication system under the probabilistic line-of-sight (LoS) channel, where a UAV equipped with an RIS is deployed to assist two ground nodes in their information exchange. An optimization problem with the objective of maximizing the minimum average (expected) achievable rate is formulated to design the communication scheduling, the RIS's phase, and the UAV trajectory. To solve such a non-convex problem, we propose an efficient iterative algorithm to obtain its suboptimal solution. Simulation results show that our proposed design provides new insights into the elevation angle-distance trade-off for the UAV-aided TWR communication system, and improves the rate by 28% compared to the scheme under the conventional LoS channel.
A deep learned nanowire segmentation model using synthetic data augmentation
Sep 28, 2021
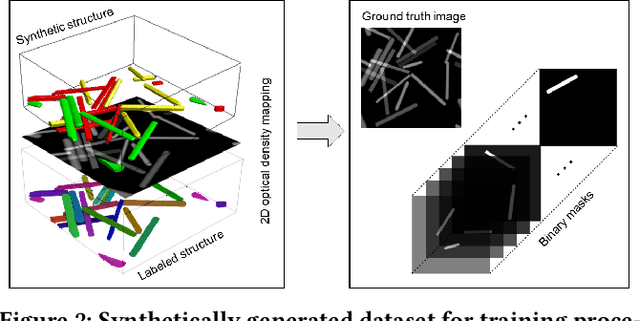
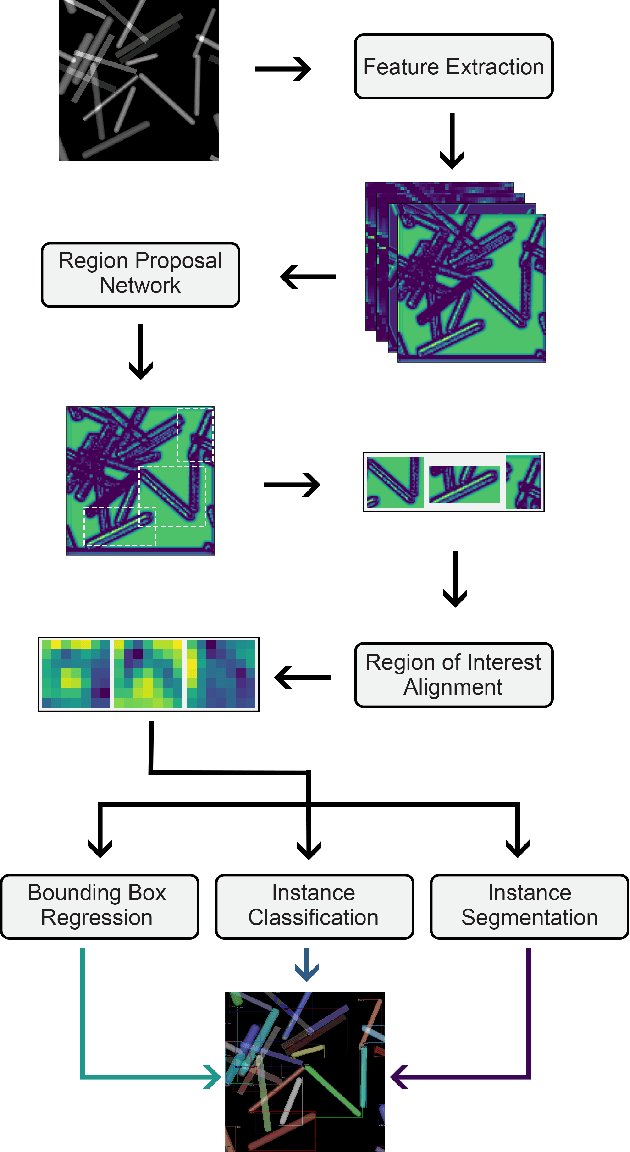
Automatized object identification and feature analysis of experimental image data are indispensable for data-driven material science; deep-learning-based segmentation algorithms have been shown to be a promising technique to achieve this goal. However, acquiring high-resolution experimental images and assigning labels in order to train such algorithms is challenging and costly in terms of both time and labor. In the present work, we apply synthetic images, which resemble the experimental image data in terms of geometrical and visual features, to train state-of-art deep learning-based Mask R-CNN algorithms to segment vanadium pentoxide (V2O5) nanowires, a canonical cathode material, within optical intensity-based images from spectromicroscopy. The performance evaluation demonstrates that even though the deep learning model is trained on pure synthetically generated structures, it can segment real optical intensity-based spectromicroscopy images of complex V2O5 nanowire structures in overlapped particle networks, thus providing reliable statistical information. The model can further be used to segment nanowires in scanning electron microscopy (SEM) images, which are fundamentally different from the training dataset known to the model. The proposed methodology of using a purely synthetic dataset to train the deep learning model can be extended to any optical intensity-based images of variable particle morphology, extent of agglomeration, material class, and beyond.