 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Deep Collaborative Multi-Modal Learning for Unsupervised Kinship Estimation
Sep 07, 2021
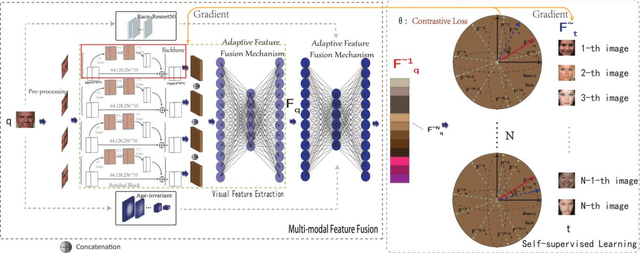
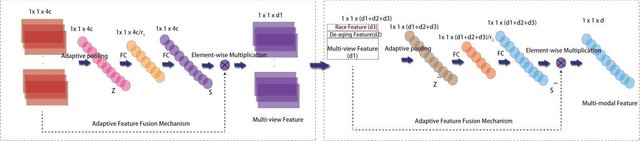
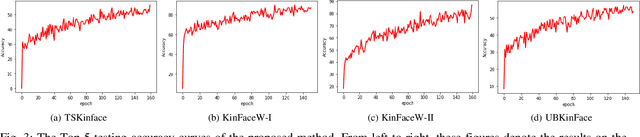
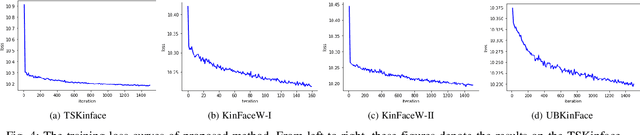
Kinship verification is a long-standing research challenge in computer vision. The visual differences presented to the face have a significant effect on the recognition capabilities of the kinship systems. We argue that aggregating multiple visual knowledge can better describe the characteristics of the subject for precise kinship identification. Typically, the age-invariant features can represent more natural facial details. Such age-related transformations are essential for face recognition due to the biological effects of aging. However, the existing methods mainly focus on employing the single-view image features for kinship identification, while more meaningful visual properties such as race and age are directly ignored in the feature learning step. To this end, we propose a novel deep collaborative multi-modal learning (DCML) to integrate the underlying information presented in facial properties in an adaptive manner to strengthen the facial details for effective unsupervised kinship verification. Specifically, we construct a well-designed adaptive feature fusion mechanism, which can jointly leverage the complementary properties from different visual perspectives to produce composite features and draw greater attention to the most informative components of spatial feature maps. Particularly, an adaptive weighting strategy is developed based on a novel attention mechanism, which can enhance the dependencies between different properties by decreasing the information redundancy in channels in a self-adaptive manner. To validate the effectiveness of the proposed method, extensive experimental evaluations conducted on four widely-used datasets show that our DCML method is always superior to some state-of-the-art kinship verification methods.
Development of a miniaturized laser-communication terminal for small satellites
Nov 11, 2021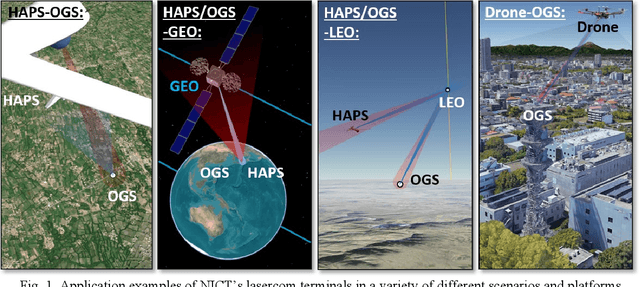
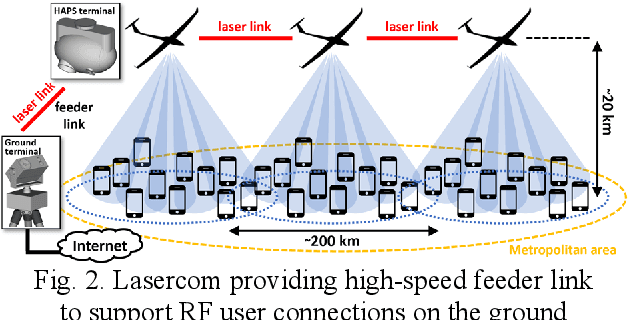
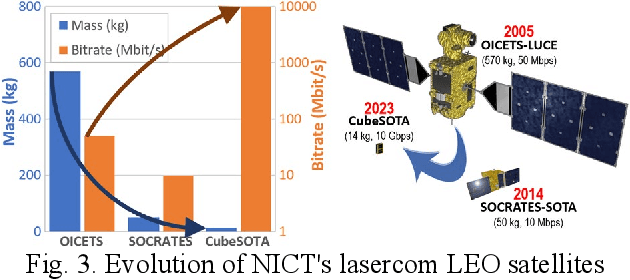
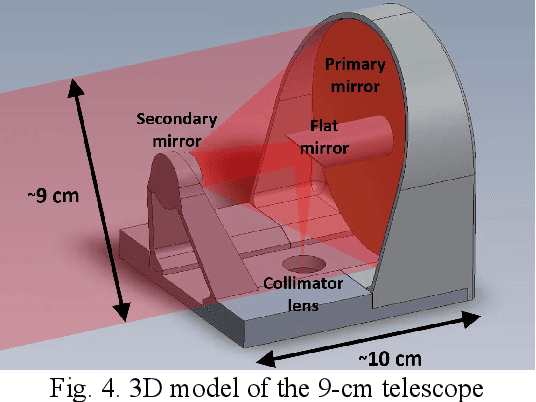
Free-space optical communication is becoming a mature technology that has been demonstrated in space a number of times in the last few years. The Japanese National Institute of Information and Communications Technology (NICT) has carried out some of the most-significant in-orbit demonstrations over the last three decades. However, this technology has not reached a wide commercial adoption yet. For this reason, NICT is currently working towards the development of a miniaturized laser-communication terminal that can be installed in very-small satellites, while also compatible with a variety of other different platforms, meeting a wide span of bandwidth requirements. The strategy adopted in this design has been to create a versatile lasercom terminal that can operate in multiple scenarios and platforms without the need of extensive customization. This manuscript describes the current efforts in NICT towards the development of this terminal, and it shows the prototype that has been already developed for the preliminary tests, which are described as well. These tests will include the performance verification using drones first with the goal of installing the prototype on High-Altitude Platform Systems (HAPS) to carry out communication links between HAPS and ground, and later with the Geostationary (GEO) orbit, covering this way a wide range of operating conditions. For these tests, in the former case the counter terminal is a simple transmitter in the case of the drone, and a transportable ground station in the case of the HAPS; and in the latter case the counter terminal is the GEO satellite ETS-IX, foreseen to be launched by NICT in 2023.
* 5 pages, 9 figures
Dimension-free Information Concentration via Exp-Concavity
Feb 26, 2018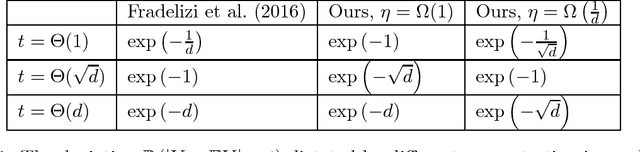
Information concentration of probability measures have important implications in learning theory. Recently, it is discovered that the information content of a log-concave distribution concentrates around their differential entropy, albeit with an unpleasant dependence on the ambient dimension. In this work, we prove that if the potentials of the log-concave distribution are exp-concave, which is a central notion for fast rates in online and statistical learning, then the concentration of information can be further improved to depend only on the exp-concavity parameter, and hence, it can be dimension independent. Central to our proof is a novel yet simple application of the variance Brascamp-Lieb inequality. In the context of learning theory, our concentration-of-information result immediately implies high-probability results to many of the previous bounds that only hold in expectation.
Fully Distributed Actor-Critic Architecture for Multitask Deep Reinforcement Learning
Oct 23, 2021We propose a fully distributed actor-critic architecture, named Diff-DAC, with application to multitask reinforcement learning (MRL). During the learning process, agents communicate their value and policy parameters to their neighbours, diffusing the information across a network of agents with no need for a central station. Each agent can only access data from its local task, but aims to learn a common policy that performs well for the whole set of tasks. The architecture is scalable, since the computational and communication cost per agent depends on the number of neighbours rather than the overall number of agents. We derive Diff-DAC from duality theory and provide novel insights into the actor-critic framework, showing that it is actually an instance of the dual ascent method. We prove almost sure convergence of Diff-DAC to a common policy under general assumptions that hold even for deep-neural network approximations. For more restrictive assumptions, we also prove that this common policy is a stationary point of an approximation of the original problem. Numerical results on multitask extensions of common continuous control benchmarks demonstrate that Diff-DAC stabilises learning and has a regularising effect that induces higher performance and better generalisation properties than previous architectures.
* 27 pages, 8 figures
Greedy Gradient Ensemble for Robust Visual Question Answering
Aug 03, 2021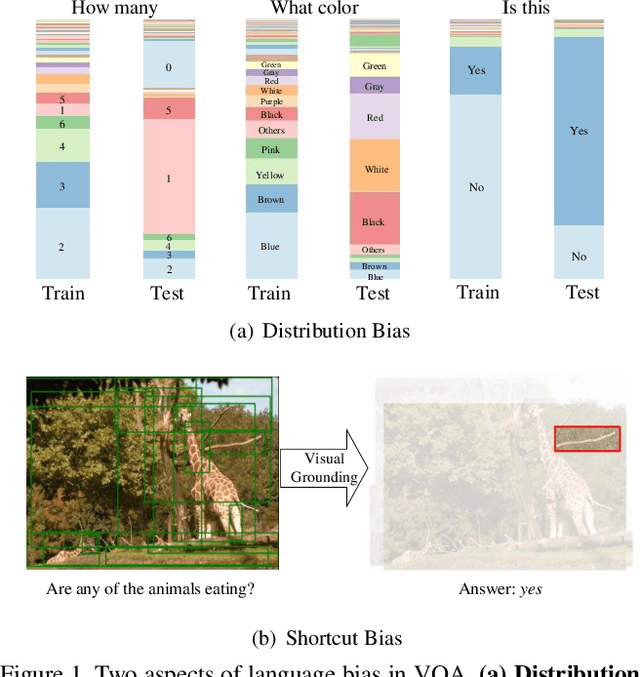
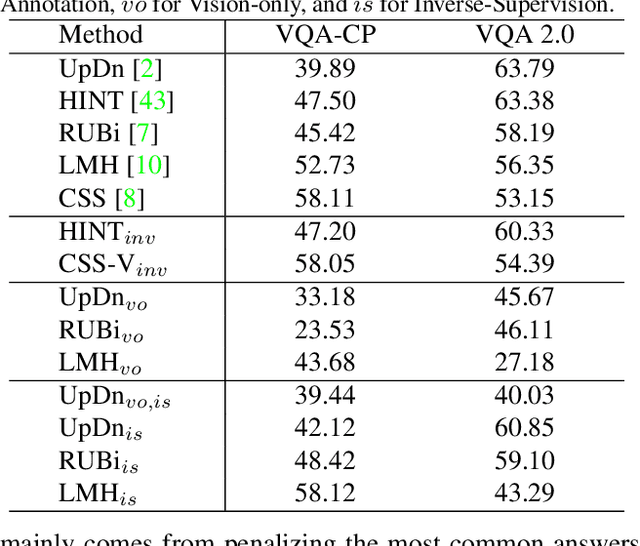
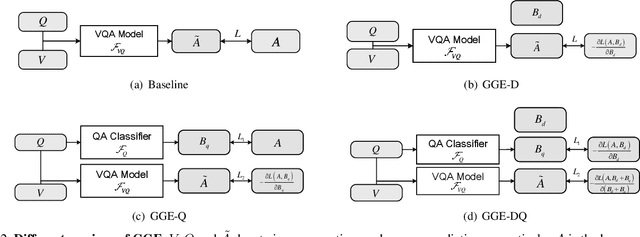
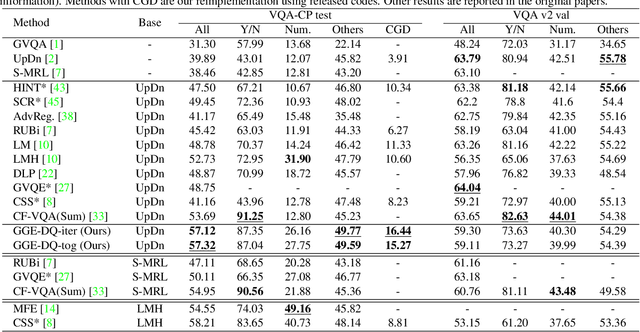
Language bias is a critical issue in Visual Question Answering (VQA), where models often exploit dataset biases for the final decision without considering the image information. As a result, they suffer from performance drop on out-of-distribution data and inadequate visual explanation. Based on experimental analysis for existing robust VQA methods, we stress the language bias in VQA that comes from two aspects, i.e., distribution bias and shortcut bias. We further propose a new de-bias framework, Greedy Gradient Ensemble (GGE), which combines multiple biased models for unbiased base model learning. With the greedy strategy, GGE forces the biased models to over-fit the biased data distribution in priority, thus makes the base model pay more attention to examples that are hard to solve by biased models. The experiments demonstrate that our method makes better use of visual information and achieves state-of-the-art performance on diagnosing dataset VQA-CP without using extra annotations.
Fine-Grained Adversarial Semi-supervised Learning
Oct 12, 2021

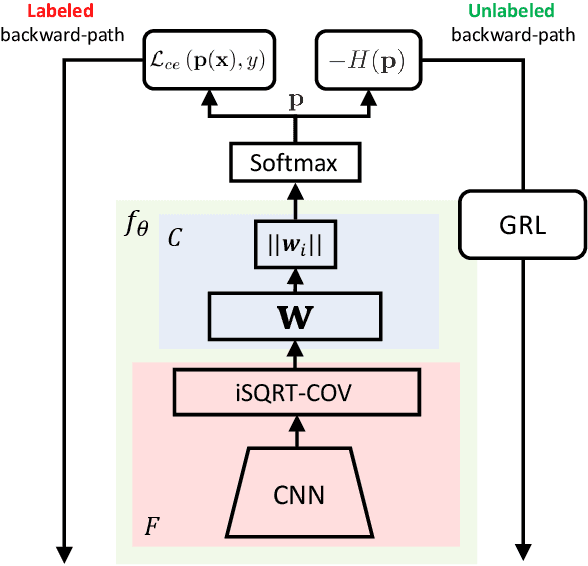
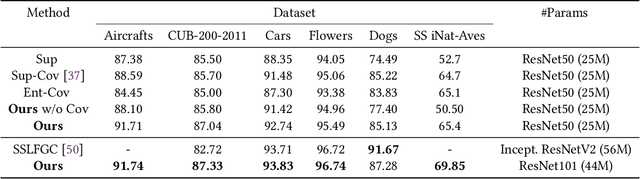
In this paper we exploit Semi-Supervised Learning (SSL) to increase the amount of training data to improve the performance of Fine-Grained Visual Categorization (FGVC). This problem has not been investigated in the past in spite of prohibitive annotation costs that FGVC requires. Our approach leverages unlabeled data with an adversarial optimization strategy in which the internal features representation is obtained with a second-order pooling model. This combination allows to back-propagate the information of the parts, represented by second-order pooling, onto unlabeled data in an adversarial training setting. We demonstrate the effectiveness of the combined use by conducting experiments on six state-of-the-art fine-grained datasets, which include Aircrafts, Stanford Cars, CUB-200-2011, Oxford Flowers, Stanford Dogs, and the recent Semi-Supervised iNaturalist-Aves. Experimental results clearly show that our proposed method has better performance than the only previous approach that examined this problem; it also obtained higher classification accuracy with respect to the supervised learning methods with which we compared.
Adaptive Sampling Quasi-Newton Methods for Zeroth-Order Stochastic Optimization
Sep 24, 2021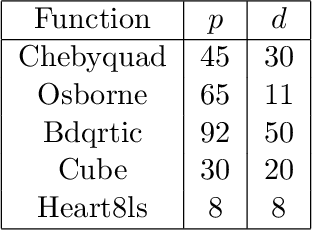
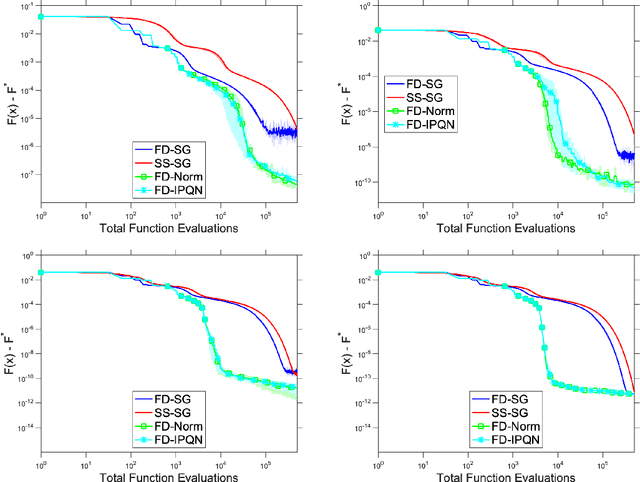
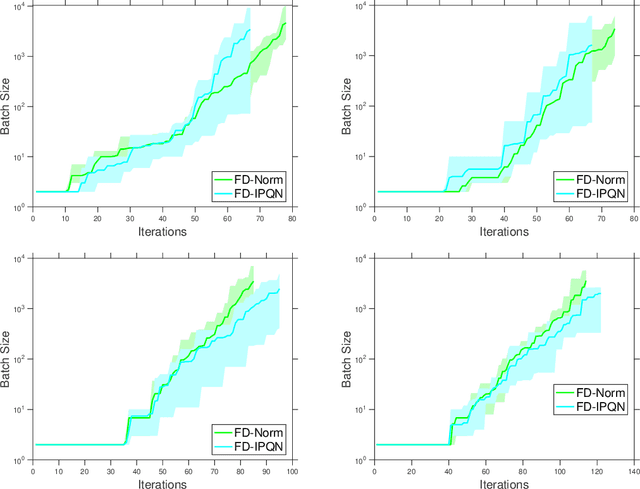
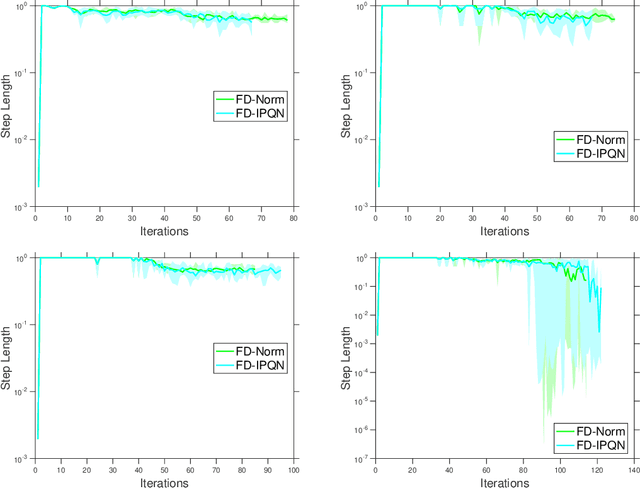
We consider unconstrained stochastic optimization problems with no available gradient information. Such problems arise in settings from derivative-free simulation optimization to reinforcement learning. We propose an adaptive sampling quasi-Newton method where we estimate the gradients of a stochastic function using finite differences within a common random number framework. We develop modified versions of a norm test and an inner product quasi-Newton test to control the sample sizes used in the stochastic approximations and provide global convergence results to the neighborhood of the optimal solution. We present numerical experiments on simulation optimization problems to illustrate the performance of the proposed algorithm. When compared with classical zeroth-order stochastic gradient methods, we observe that our strategies of adapting the sample sizes significantly improve performance in terms of the number of stochastic function evaluations required.
Learning to Learn a Cold-start Sequential Recommender
Oct 18, 2021
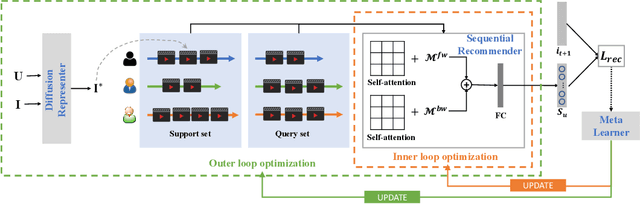
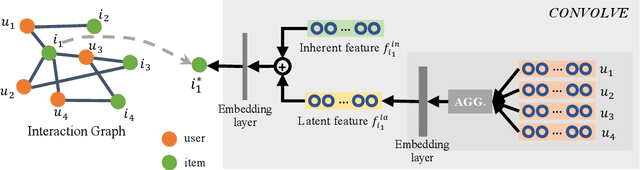
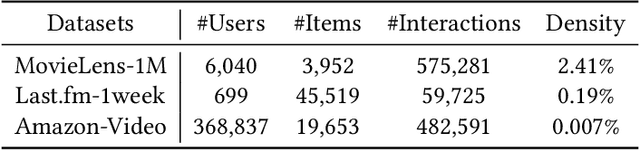
The cold-start recommendation is an urgent problem in contemporary online applications. It aims to provide users whose behaviors are literally sparse with as accurate recommendations as possible. Many data-driven algorithms, such as the widely used matrix factorization, underperform because of data sparseness. This work adopts the idea of meta-learning to solve the user's cold-start recommendation problem. We propose a meta-learning based cold-start sequential recommendation framework called metaCSR, including three main components: Diffusion Representer for learning better user/item embedding through information diffusion on the interaction graph; Sequential Recommender for capturing temporal dependencies of behavior sequences; Meta Learner for extracting and propagating transferable knowledge of prior users and learning a good initialization for new users. metaCSR holds the ability to learn the common patterns from regular users' behaviors and optimize the initialization so that the model can quickly adapt to new users after one or a few gradient updates to achieve optimal performance. The extensive quantitative experiments on three widely-used datasets show the remarkable performance of metaCSR in dealing with user cold-start problem. Meanwhile, a series of qualitative analysis demonstrates that the proposed metaCSR has good generalization.
A bridge between features and evidence for binary attribute-driven perfect privacy
Oct 12, 2021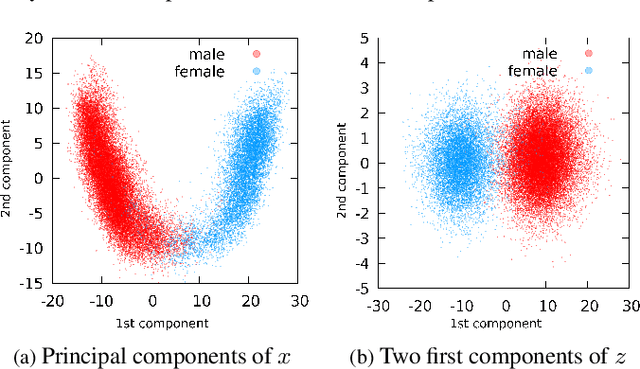
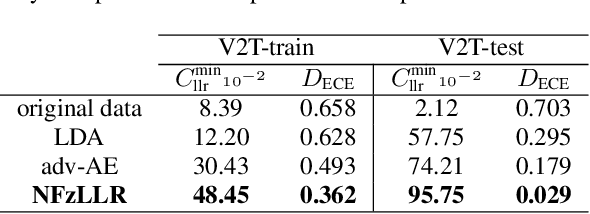
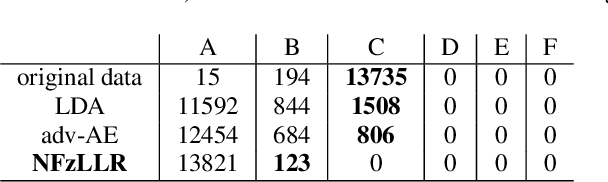
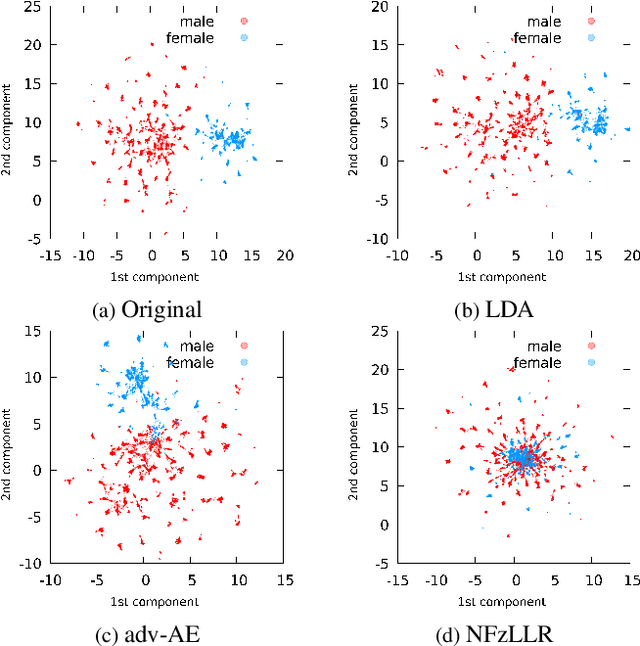
Attribute-driven privacy aims to conceal a single user's attribute, contrary to anonymisation that tries to hide the full identity of the user in some data. When the attribute to protect from malicious inferences is binary, perfect privacy requires the log-likelihood-ratio to be zero resulting in no strength-of-evidence. This work presents an approach based on normalizing flow that maps a feature vector into a latent space where the strength-of-evidence, related to the binary attribute, and an independent residual are disentangled. It can be seen as a non-linear discriminant analysis where the mapping is invertible allowing generation by mapping the latent variable back to the original space. This framework allows to manipulate the log-likelihood-ratio of the data and thus to set it to zero for privacy. We show the applicability of the approach on an attribute-driven privacy task where the sex information is removed from speaker embeddings. Results on VoxCeleb2 dataset show the efficiency of the method that outperforms in terms of privacy and utility our previous experiments based on adversarial disentanglement.
Discovery-and-Selection: Towards Optimal Multiple Instance Learning for Weakly Supervised Object Detection
Oct 18, 2021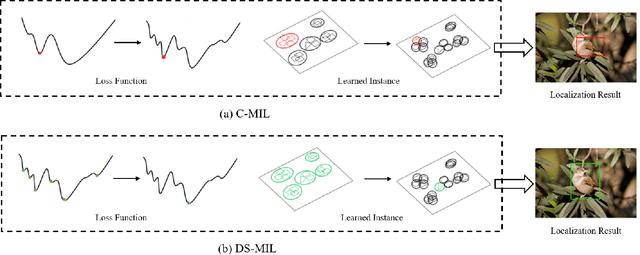
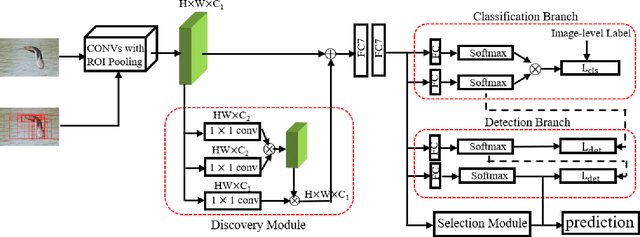
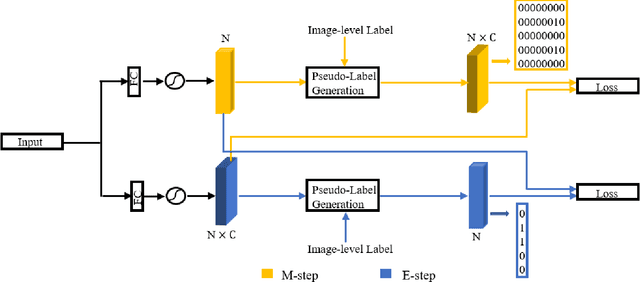

Weakly supervised object detection (WSOD) is a challenging task that requires simultaneously learn object classifiers and estimate object locations under the supervision of image category labels. A major line of WSOD methods roots in multiple instance learning which regards images as bags of instance and selects positive instances from each bag to learn the detector. However, a grand challenge emerges when the detector inclines to converge to discriminative parts of objects rather than the whole objects. In this paper, under the hypothesis that optimal solutions are included in local minima, we propose a discoveryand-selection approach fused with multiple instance learning (DS-MIL), which finds rich local minima and select optimal solutions from multiple local minima. To implement DS-MIL, an attention module is designed so that more context information can be captured by feature maps and more valuable proposals can be collected during training. With proposal candidates, a re-rank module is designed to select informative instances for object detector training. Experimental results on commonly used benchmarks show that our proposed DS-MIL approach can consistently improve the baselines, reporting state-of-the-art performance.