 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Distributed Actor-Critic Architecture for Multitask Deep Reinforcement Learning
Oct 23, 2021We propose a fully distributed actor-critic architecture, named Diff-DAC, with application to multitask reinforcement learning (MRL). During the learning process, agents communicate their value and policy parameters to their neighbours, diffusing the information across a network of agents with no need for a central station. Each agent can only access data from its local task, but aims to learn a common policy that performs well for the whole set of tasks. The architecture is scalable, since the computational and communication cost per agent depends on the number of neighbours rather than the overall number of agents. We derive Diff-DAC from duality theory and provide novel insights into the actor-critic framework, showing that it is actually an instance of the dual ascent method. We prove almost sure convergence of Diff-DAC to a common policy under general assumptions that hold even for deep-neural network approximations. For more restrictive assumptions, we also prove that this common policy is a stationary point of an approximation of the original problem. Numerical results on multitask extensions of common continuous control benchmarks demonstrate that Diff-DAC stabilises learning and has a regularising effect that induces higher performance and better generalisation properties than previous architectures.
* 27 pages, 8 figures
Compatible features for Monotonic Policy Improvement
Oct 30, 2019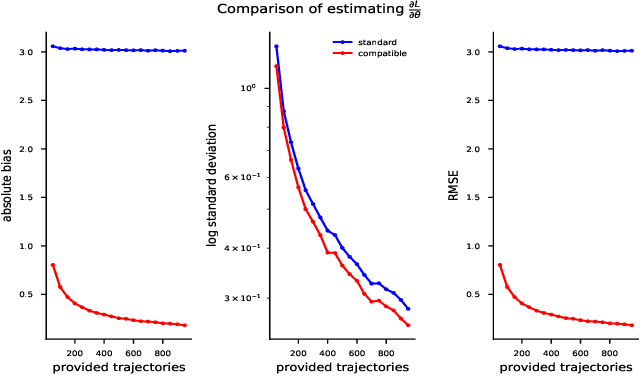
Recent policy optimization approaches have achieved substantial empirical success by constructing surrogate optimization objectives. The Approximate Policy Iteration objective (Schulman et al., 2015a; Kakade and Langford, 2002) has become a standard optimization target for reinforcement learning problems. Using this objective in practice requires an estimator of the advantage function. Policy optimization methods such as those proposed in Schulman et al. (2015b) estimate the advantages using a parametric critic. In this work we establish conditions under which the parametric approximation of the critic does not introduce bias to the updates of surrogate objective. These results hold for a general class of parametric policies, including deep neural networks. We obtain a result analogous to the compatible features derived for the original Policy Gradient Theorem (Sutton et al., 1999). As a result, we also identify a previously unknown bias that current state-of-the-art policy optimization algorithms (Schulman et al., 2015a, 2017) have introduced by not employing these compatible features.
Adaptive Sensor Placement for Continuous Spaces
May 16, 2019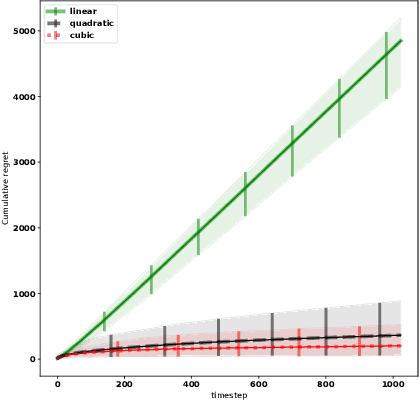
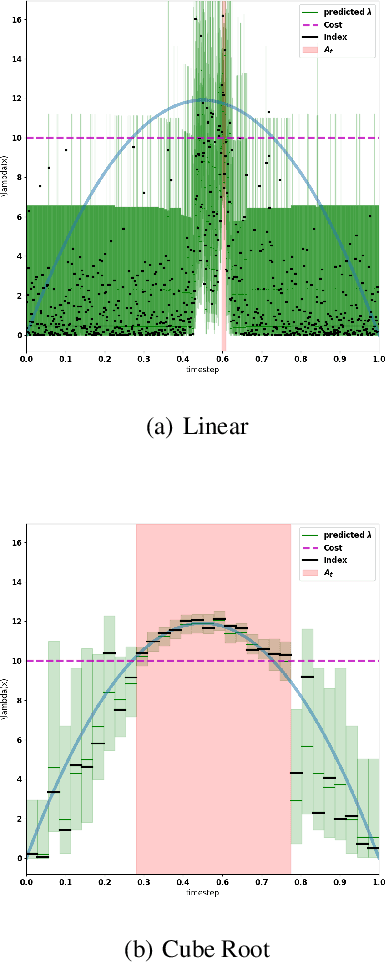
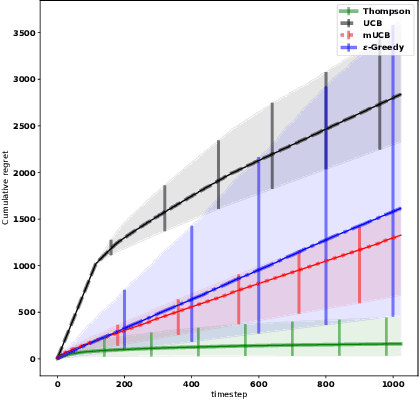
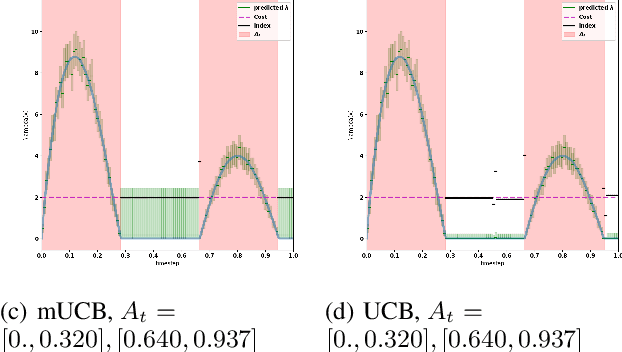
We consider the problem of adaptively placing sensors along an interval to detect stochastically-generated events. We present a new formulation of the problem as a continuum-armed bandit problem with feedback in the form of partial observations of realisations of an inhomogeneous Poisson process. We design a solution method by combining Thompson sampling with nonparametric inference via increasingly granular Bayesian histograms and derive an $\tilde{O}(T^{2/3})$ bound on the Bayesian regret in $T$ rounds. This is coupled with the design of an efficent optimisation approach to select actions in polynomial time. In simulations we demonstrate our approach to have substantially lower and less variable regret than competitor algorithms.
Diff-DAC: Distributed Actor-Critic for Average Multitask Deep Reinforcement Learning
Apr 22, 2018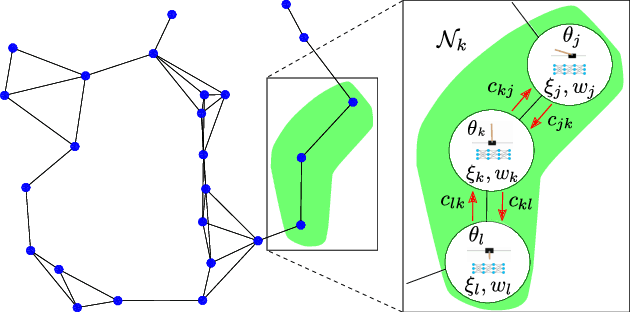
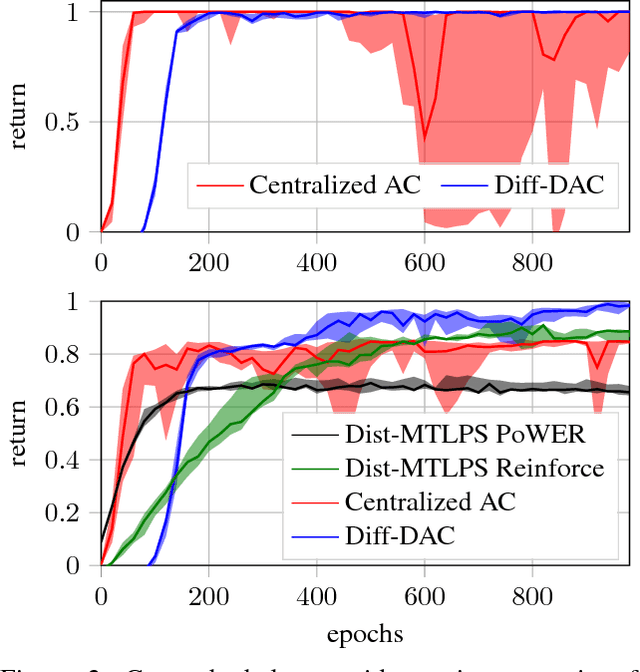
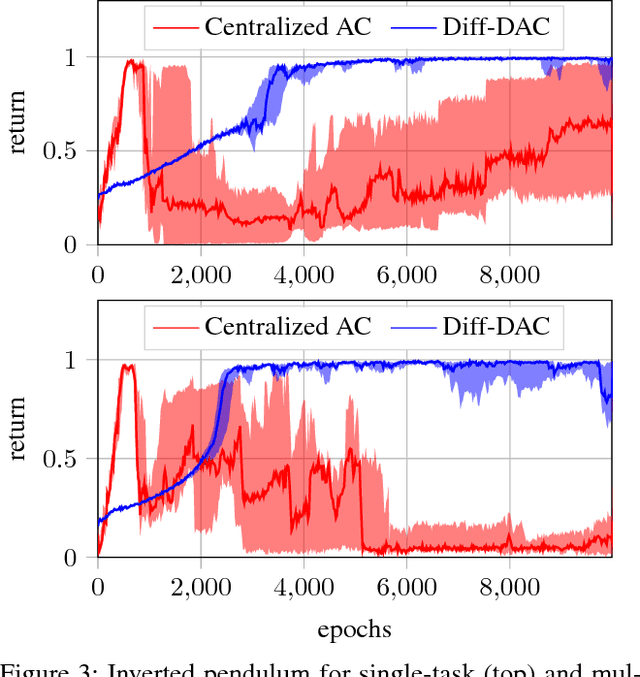
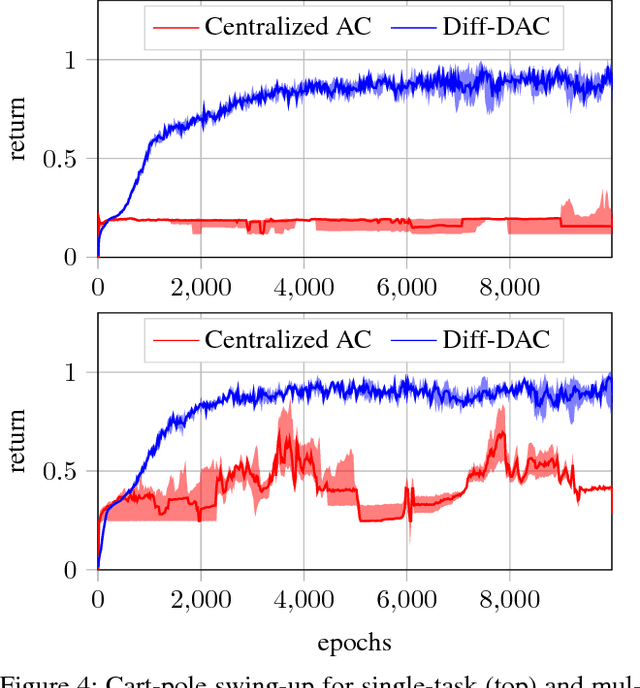
We propose a fully distributed actor-critic algorithm approximated by deep neural networks, named \textit{Diff-DAC}, with application to single-task and to average multitask reinforcement learning (MRL). Each agent has access to data from its local task only, but it aims to learn a policy that performs well on average for the whole set of tasks. During the learning process, agents communicate their value-policy parameters to their neighbors, diffusing the information across the network, so that they converge to a common policy, with no need for a central node. The method is scalable, since the computational and communication costs per agent grow with its number of neighbors. We derive Diff-DAC's from duality theory and provide novel insights into the standard actor-critic framework, showing that it is actually an instance of the dual ascent method that approximates the solution of a linear program. Experiments suggest that Diff-DAC can outperform the single previous distributed MRL approach (i.e., Dist-MTLPS) and even the centralized architecture.
A Survey of Learning in Multiagent Environments: Dealing with Non-Stationarity
Jul 28, 2017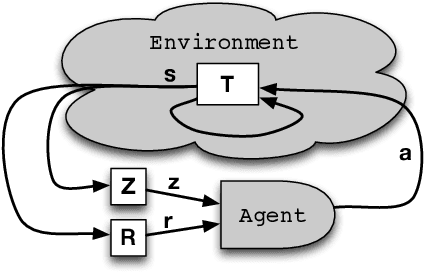
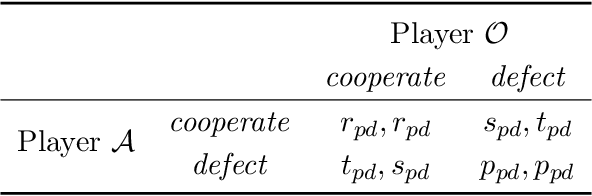
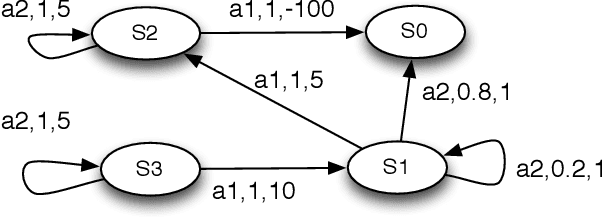
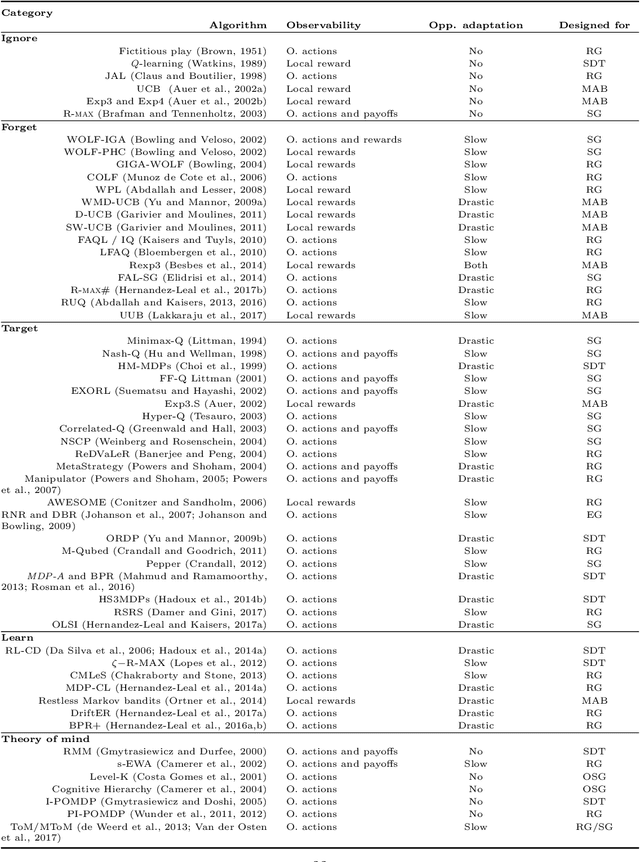
The key challenge in multiagent learning is learning a best response to the behaviour of other agents, which may be non-stationary: if the other agents adapt their strategy as well, the learning target moves. Disparate streams of research have approached non-stationarity from several angles, which make a variety of implicit assumptions that make it hard to keep an overview of the state of the art and to validate the innovation and significance of new works. This survey presents a coherent overview of work that addresses opponent-induced non-stationarity with tools from game theory, reinforcement learning and multi-armed bandits. Further, we reflect on the principle approaches how algorithms model and cope with this non-stationarity, arriving at a new framework and five categories (in increasing order of sophistication): ignore, forget, respond to target models, learn models, and theory of mind. A wide range of state-of-the-art algorithms is classified into a taxonomy, using these categories and key characteristics of the environment (e.g., observability) and adaptation behaviour of the opponents (e.g., smooth, abrupt). To clarify even further we present illustrative variations of one domain, contrasting the strengths and limitations of each category. Finally, we discuss in which environments the different approaches yield most merit, and point to promising avenues of future research.
Automated Planning in Repeated Adversarial Games
Mar 15, 2012
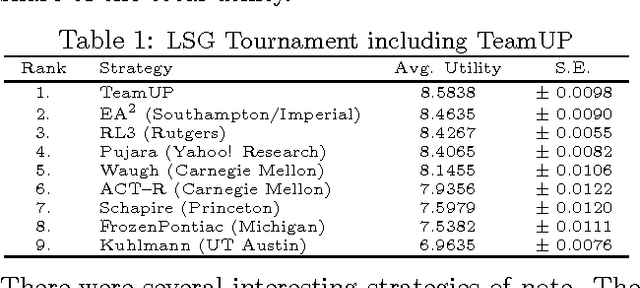
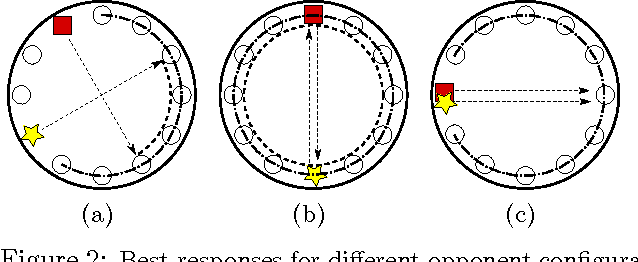

Game theory's prescriptive power typically relies on full rationality and/or self-play interactions. In contrast, this work sets aside these fundamental premises and focuses instead on heterogeneous autonomous interactions between two or more agents. Specifically, we introduce a new and concise representation for repeated adversarial (constant-sum) games that highlight the necessary features that enable an automated planing agent to reason about how to score above the game's Nash equilibrium, when facing heterogeneous adversaries. To this end, we present TeamUP, a model-based RL algorithm designed for learning and planning such an abstraction. In essence, it is somewhat similar to R-max with a cleverly engineered reward shaping that treats exploration as an adversarial optimization problem. In practice, it attempts to find an ally with which to tacitly collude (in more than two-player games) and then collaborates on a joint plan of actions that can consistently score a high utility in adversarial repeated games. We use the inaugural Lemonade Stand Game Tournament to demonstrate the effectiveness of our approach, and find that TeamUP is the best performing agent, demoting the Tournament's actual winning strategy into second place. In our experimental analysis, we show hat our strategy successfully and consistently builds collaborations with many different heterogeneous (and sometimes very sophisticated) adversaries.