 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio Question Answering with GRPO-Based Fine-Tuning and Calibrated Segment-Level Predictions
Nov 18, 2025In this report, we describe our submission to Track 5 of the DCASE 2025 Challenge for the task of Audio Question Answering(AQA). Our system leverages the SSL backbone BEATs to extract frame-level audio features, which are then processed by a classification head to generate segment-level predictions of acoustic events, following the Audioset ontology. These segment-level predictions are subsequently calibrated before producing event-level predictions. Finally, these predictions are incorporated into a structured prompt, along with the question and candidate answers. This prompt is then fed to a fine-tuned version of Qwen2.5-7B-Instruct, trained using the GRPO algorithm with a simple reward function. Our method achieves an accuracy of 62.6 % on the development set, demonstrating the effectiveness of combining acoustic event reasoning with instruction-tuned large language models for AQA.
Segmentwise Pruning in Audio-Language Models
Nov 18, 2025



Recent audio-language models have shown impressive performance across a wide range of audio tasks and are increasingly capable of handling long audio inputs. However, the computing costs in these models heavily depend on sequence length, which can become very large given the nature of audio data. In the vision-language domain, token pruning methods have proven effective in reducing token counts while preserving strong performance on standard benchmarks. In this work, we investigate the relevance and effectiveness of such token selection strategies in the context of audio-language models. We also improve them by proposing a lightweight strategy that takes the time dimension into account. While retaining only a quarter of the initial tokens, our approach results in a relative maximum decrease of 2% in CIDEr on Clotho v2 and a relative maximum decrease of 4% in accuracy on MMAU.
The distribution of calibrated likelihood functions on the probability-likelihood Aitchison simplex
Sep 03, 2025



While calibration of probabilistic predictions has been widely studied, this paper rather addresses calibration of likelihood functions. This has been discussed, especially in biometrics, in cases with only two exhaustive and mutually exclusive hypotheses (classes) where likelihood functions can be written as log-likelihood-ratios (LLRs). After defining calibration for LLRs and its connection with the concept of weight-of-evidence, we present the idempotence property and its associated constraint on the distribution of the LLRs. Although these results have been known for decades, they have been limited to the binary case. Here, we extend them to cases with more than two hypotheses by using the Aitchison geometry of the simplex, which allows us to recover, in a vector form, the additive form of the Bayes' rule; extending therefore the LLR and the weight-of-evidence to any number of hypotheses. Especially, we extend the definition of calibration, the idempotence, and the constraint on the distribution of likelihood functions to this multiple hypotheses and multiclass counterpart of the LLR: the isometric-log-ratio transformed likelihood function. This work is mainly conceptual, but we still provide one application to machine learning by presenting a non-linear discriminant analysis where the discriminant components form a calibrated likelihood function over the classes, improving therefore the interpretability and the reliability of the method.
Explaining a probabilistic prediction on the simplex with Shapley compositions
Aug 02, 2024Originating in game theory, Shapley values are widely used for explaining a machine learning model's prediction by quantifying the contribution of each feature's value to the prediction. This requires a scalar prediction as in binary classification, whereas a multiclass probabilistic prediction is a discrete probability distribution, living on a multidimensional simplex. In such a multiclass setting the Shapley values are typically computed separately on each class in a one-vs-rest manner, ignoring the compositional nature of the output distribution. In this paper, we introduce Shapley compositions as a well-founded way to properly explain a multiclass probabilistic prediction, using the Aitchison geometry from compositional data analysis. We prove that the Shapley composition is the unique quantity satisfying linearity, symmetry and efficiency on the Aitchison simplex, extending the corresponding axiomatic properties of the standard Shapley value. We demonstrate this proper multiclass treatment in a range of scenarios.
SynVox2: Towards a privacy-friendly VoxCeleb2 dataset
Sep 12, 2023



The success of deep learning in speaker recognition relies heavily on the use of large datasets. However, the data-hungry nature of deep learning methods has already being questioned on account the ethical, privacy, and legal concerns that arise when using large-scale datasets of natural speech collected from real human speakers. For example, the widely-used VoxCeleb2 dataset for speaker recognition is no longer accessible from the official website. To mitigate these concerns, this work presents an initiative to generate a privacy-friendly synthetic VoxCeleb2 dataset that ensures the quality of the generated speech in terms of privacy, utility, and fairness. We also discuss the challenges of using synthetic data for the downstream task of speaker verification.
Federated Learning for ASR based on Wav2vec 2.0
Feb 20, 2023



This paper presents a study on the use of federated learning to train an ASR model based on a wav2vec 2.0 model pre-trained by self supervision. Carried out on the well-known TED-LIUM 3 dataset, our experiments show that such a model can obtain, with no use of a language model, a word error rate of 10.92% on the official TED-LIUM 3 test set, without sharing any data from the different users. We also analyse the ASR performance for speakers depending to their participation to the federated learning. Since federated learning was first introduced for privacy purposes, we also measure its ability to protect speaker identity. To do that, we exploit an approach to analyze information contained in exchanged models based on a neural network footprint on an indicator dataset. This analysis is made layer-wise and shows which layers in an exchanged wav2vec 2.0 based model bring the speaker identity information.
Hiding speaker's sex in speech using zero-evidence speaker representation in an analysis/synthesis pipeline
Nov 29, 2022The use of modern vocoders in an analysis/synthesis pipeline allows us to investigate high-quality voice conversion that can be used for privacy purposes. Here, we propose to transform the speaker embedding and the pitch in order to hide the sex of the speaker. ECAPA-TDNN-based speaker representation fed into a HiFiGAN vocoder is protected using a neural-discriminant analysis approach, which is consistent with the zero-evidence concept of privacy. This approach significantly reduces the information in speech related to the speaker's sex while preserving speech content and some consistency in the resulting protected voices.
The VoicePrivacy 2020 Challenge Evaluation Plan
May 14, 2022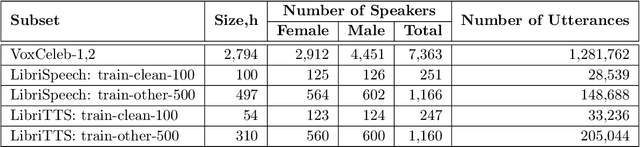
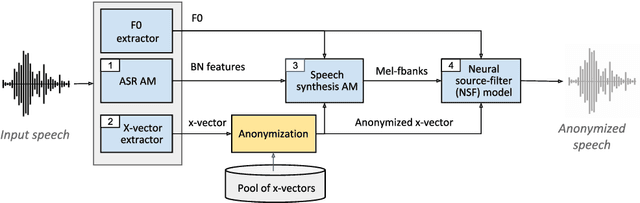
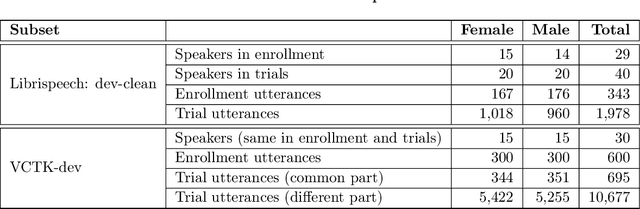
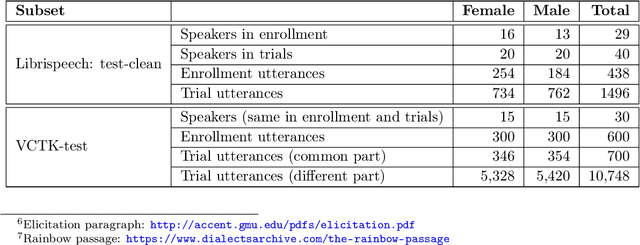
The VoicePrivacy Challenge aims to promote the development of privacy preservation tools for speech technology by gathering a new community to define the tasks of interest and the evaluation methodology, and benchmarking solutions through a series of challenges. In this document, we formulate the voice anonymization task selected for the VoicePrivacy 2020 Challenge and describe the datasets used for system development and evaluation. We also present the attack models and the associated objective and subjective evaluation metrics. We introduce two anonymization baselines and report objective evaluation results.
The VoicePrivacy 2022 Challenge Evaluation Plan
Mar 27, 2022For new participants - Executive summary: (1) The task is to develop a voice anonymization system for speech data which conceals the speaker's voice identity while protecting linguistic content, paralinguistic attributes, intelligibility and naturalness. (2) Training, development and evaluation datasets are provided in addition to 3 different baseline anonymization systems, evaluation scripts, and metrics. Participants apply their developed anonymization systems, run evaluation scripts and submit objective evaluation results and anonymized speech data to the organizers. (3) Results will be presented at a workshop held in conjunction with INTERSPEECH 2022 to which all participants are invited to present their challenge systems and to submit additional workshop papers. For readers familiar with the VoicePrivacy Challenge - Changes w.r.t. 2020: (1) A stronger, semi-informed attack model in the form of an automatic speaker verification (ASV) system trained on anonymized (per-utterance) speech data. (2) Complementary metrics comprising the equal error rate (EER) as a privacy metric, the word error rate (WER) as a primary utility metric, and the pitch correlation and gain of voice distinctiveness as secondary utility metrics. (3) A new ranking policy based upon a set of minimum target privacy requirements.
Retrieving Speaker Information from Personalized Acoustic Models for Speech Recognition
Nov 07, 2021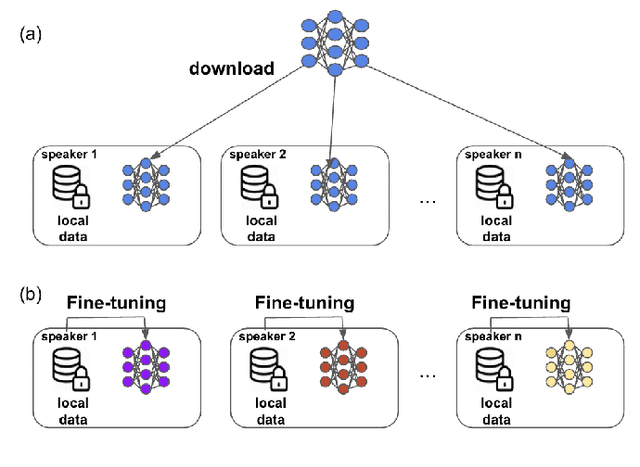

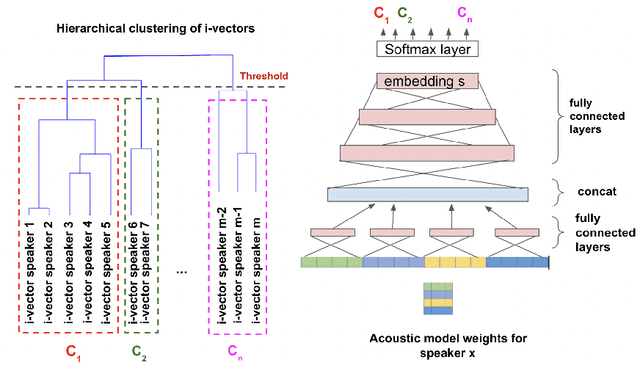
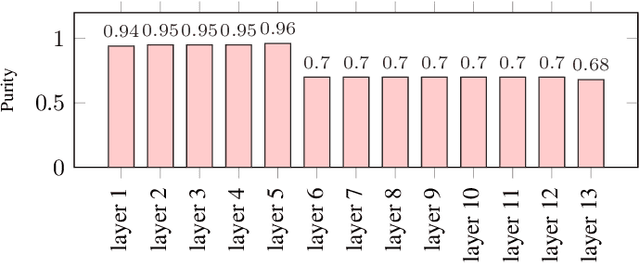
The widespread of powerful personal devices capable of collecting voice of their users has opened the opportunity to build speaker adapted speech recognition system (ASR) or to participate to collaborative learning of ASR. In both cases, personalized acoustic models (AM), i.e. fine-tuned AM with specific speaker data, can be built. A question that naturally arises is whether the dissemination of personalized acoustic models can leak personal information. In this paper, we show that it is possible to retrieve the gender of the speaker, but also his identity, by just exploiting the weight matrix changes of a neural acoustic model locally adapted to this speaker. Incidentally we observe phenomena that may be useful towards explainability of deep neural networks in the context of speech processing. Gender can be identified almost surely using only the first layers and speaker verification performs well when using middle-up layers. Our experimental study on the TED-LIUM 3 dataset with HMM/TDNN models shows an accuracy of 95% for gender detection, and an Equal Error Rate of 9.07% for a speaker verification task by only exploiting the weights from personalized models that could be exchanged instead of user data.