 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Popularity Bias Is Not Always Evil: Disentangling Benign and Harmful Bias for Recommendation
Sep 16, 2021
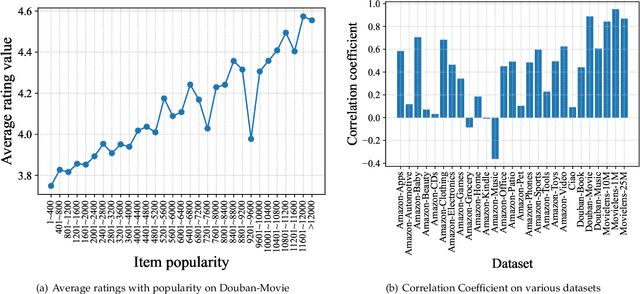

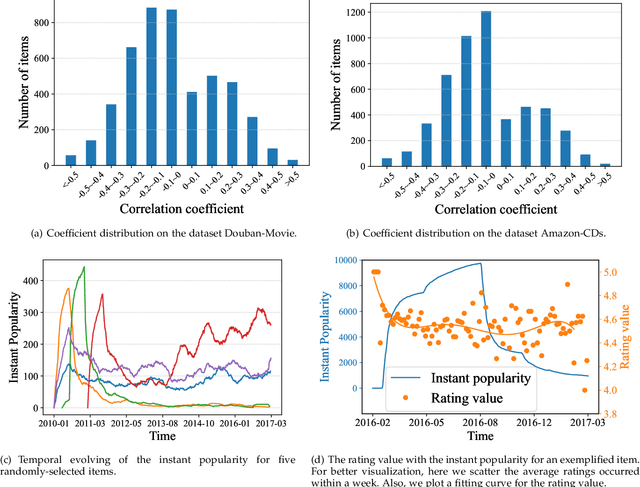

Recommender system usually suffers from severe popularity bias -- the collected interaction data usually exhibits quite imbalanced or even long-tailed distribution over items. Such skewed distribution may result from the users' conformity to the group, which deviates from reflecting users' true preference. Existing efforts for tackling this issue mainly focus on completely eliminating popularity bias. However, we argue that not all popularity bias is evil. Popularity bias not only results from conformity but also item quality, which is usually ignored by existing methods. Some items exhibit higher popularity as they have intrinsic better property. Blindly removing the popularity bias would lose such important signal, and further deteriorate model performance. To sufficiently exploit such important information for recommendation, it is essential to disentangle the benign popularity bias caused by item quality from the harmful popularity bias caused by conformity. Although important, it is quite challenging as we lack an explicit signal to differentiate the two factors of popularity bias. In this paper, we propose to leverage temporal information as the two factors exhibit quite different patterns along the time: item quality revealing item inherent property is stable and static while conformity that depends on items' recent clicks is highly time-sensitive. Correspondingly, we further propose a novel Time-aware DisEntangled framework (TIDE), where a click is generated from three components namely the static item quality, the dynamic conformity effect, as well as the user-item matching score returned by any recommendation model. Lastly, we conduct interventional inference such that the recommendation can benefit from the benign popularity bias while circumvent the harmful one. Extensive experiments on three real-world datasets demonstrated the effectiveness of TIDE.
Attentive Cross-modal Connections for Deep Multimodal Wearable-based Emotion Recognition
Aug 04, 2021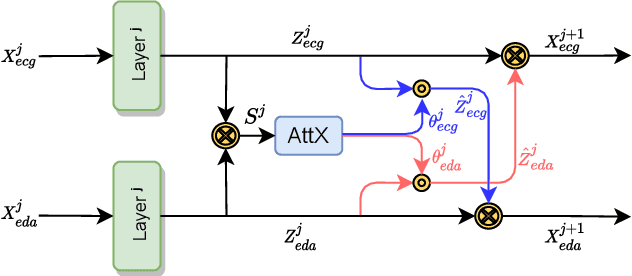
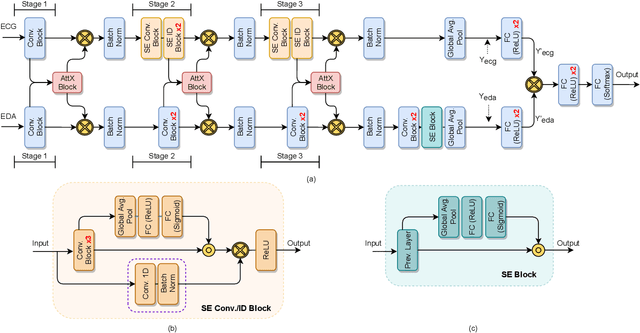
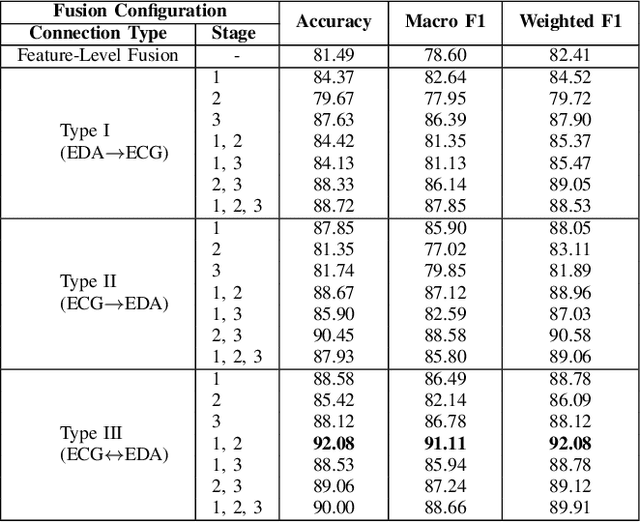

Classification of human emotions can play an essential role in the design and improvement of human-machine systems. While individual biological signals such as Electrocardiogram (ECG) and Electrodermal Activity (EDA) have been widely used for emotion recognition with machine learning methods, multimodal approaches generally fuse extracted features or final classification/regression results to boost performance. To enhance multimodal learning, we present a novel attentive cross-modal connection to share information between convolutional neural networks responsible for learning individual modalities. Specifically, these connections improve emotion classification by sharing intermediate representations among EDA and ECG and apply attention weights to the shared information, thus learning more effective multimodal embeddings. We perform experiments on the WESAD dataset to identify the best configuration of the proposed method for emotion classification. Our experiments show that the proposed approach is capable of learning strong multimodal representations and outperforms a number of baselines methods.
Multi-Branch with Attention Network for Hand-Based Person Recognition
Aug 04, 2021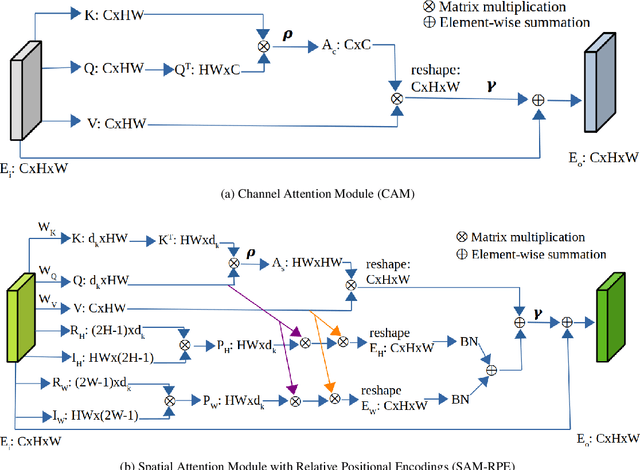

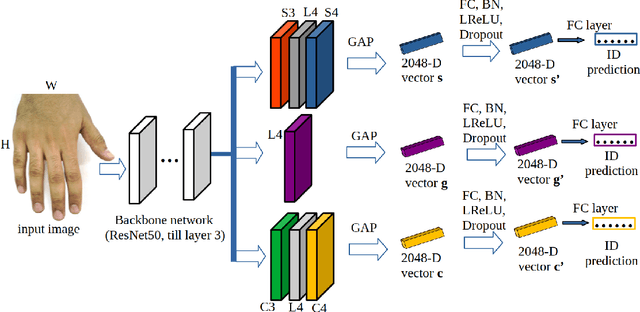

In this paper, we propose a novel hand-based person recognition method for the purpose of criminal investigations since the hand image is often the only available information in cases of serious crime such as sexual abuse. Our proposed method, Multi-Branch with Attention Network (MBA-Net), incorporates both channel and spatial attention modules in branches in addition to a global (without attention) branch to capture global structural information for discriminative feature learning. The attention modules focus on the relevant features of the hand image while suppressing the irrelevant backgrounds. In order to overcome the weakness of the attention mechanisms, equivariant to pixel shuffling, we integrate relative positional encodings into the spatial attention module to capture the spatial positions of pixels. Extensive evaluations on two large multi-ethnic and publicly available hand datasets demonstrate that our proposed method achieves state-of-the-art performance, surpassing the existing hand-based identification methods.
A Novel Structured Natural Gradient Descent for Deep Learning
Sep 21, 2021

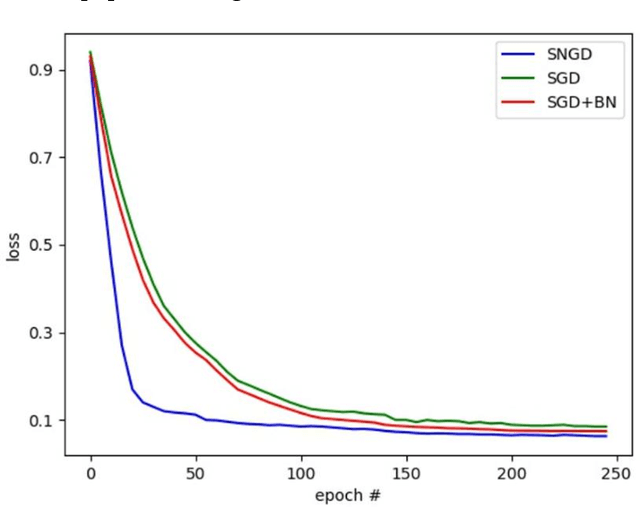
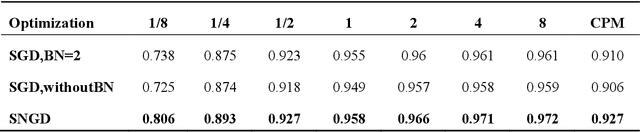
Natural gradient descent (NGD) provided deep insights and powerful tools to deep neural networks. However the computation of Fisher information matrix becomes more and more difficult as the network structure turns large and complex. This paper proposes a new optimization method whose main idea is to accurately replace the natural gradient optimization by reconstructing the network. More specifically, we reconstruct the structure of the deep neural network, and optimize the new network using traditional gradient descent (GD). The reconstructed network achieves the effect of the optimization way with natural gradient descent. Experimental results show that our optimization method can accelerate the convergence of deep network models and achieve better performance than GD while sharing its computational simplicity.
Uniform Information Segmentation
Nov 27, 2016

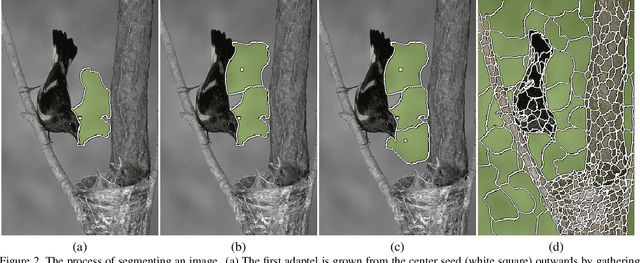
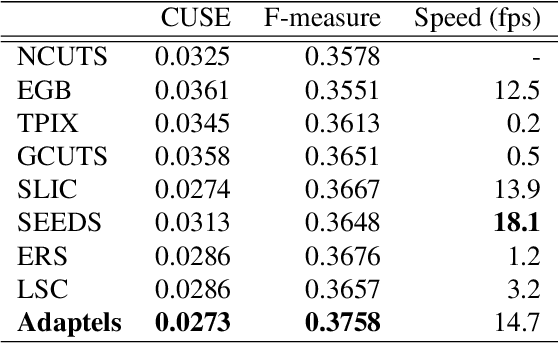
Size uniformity is one of the main criteria of superpixel methods. But size uniformity rarely conforms to the varying content of an image. The chosen size of the superpixels therefore represents a compromise - how to obtain the fewest superpixels without losing too much important detail. We propose that a more appropriate criterion for creating image segments is information uniformity. We introduce a novel method for segmenting an image based on this criterion. Since information is a natural way of measuring image complexity, our proposed algorithm leads to image segments that are smaller and denser in areas of high complexity and larger in homogeneous regions, thus simplifying the image while preserving its details. Our algorithm is simple and requires just one input parameter - a threshold on the information content. On segmentation comparison benchmarks it proves to be superior to the state-of-the-art. In addition, our method is computationally very efficient, approaching real-time performance, and is easily extensible to three-dimensional image stacks and video volumes.
OCKELM+: Kernel Extreme Learning Machine based One-class Classification using Privileged Information (or KOC+: Kernel Ridge Regression or Least Square SVM with zero bias based One-class Classification using Privileged Information)
Apr 13, 2019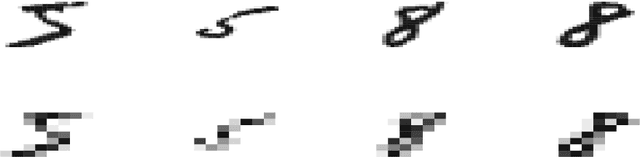
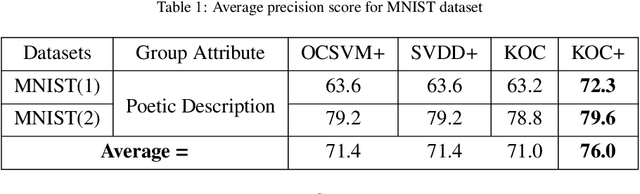
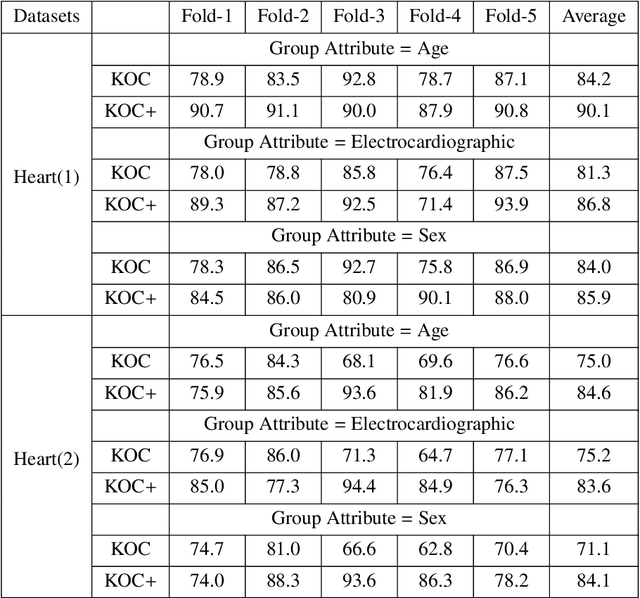
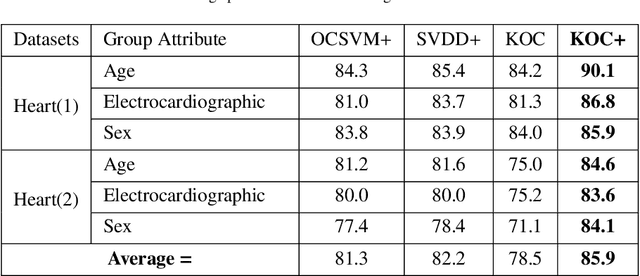
Kernel method-based one-class classifier is mainly used for outlier or novelty detection. In this letter, kernel ridge regression (KRR) based one-class classifier (KOC) has been extended for learning using privileged information (LUPI). LUPI-based KOC method is referred to as KOC+. This privileged information is available as a feature with the dataset but only for training (not for testing). KOC+ utilizes the privileged information differently compared to normal feature information by using a so-called correction function. Privileged information helps KOC+ in achieving better generalization performance which is exhibited in this letter by testing the classifiers with and without privileged information. Existing and proposed classifiers are evaluated on the datasets from UCI machine learning repository and also on MNIST dataset. Moreover, experimental results evince the advantage of KOC+ over KOC and support vector machine (SVM) based one-class classifiers.
Towards High-fidelity Singing Voice Conversion with Acoustic Reference and Contrastive Predictive Coding
Oct 10, 2021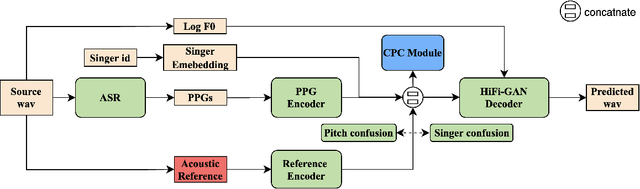
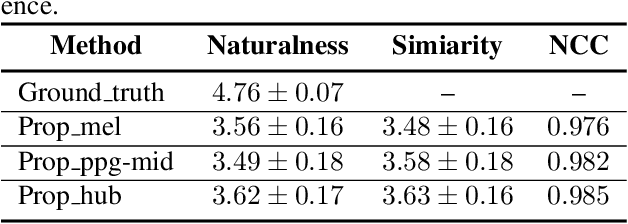
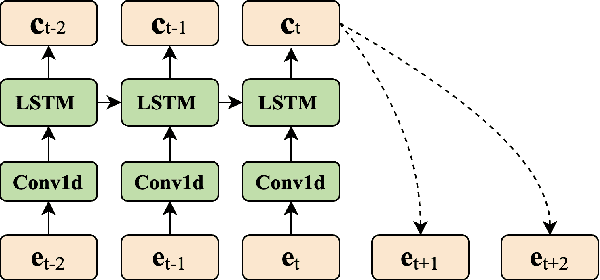

Recently, phonetic posteriorgrams (PPGs) based methods have been quite popular in non-parallel singing voice conversion systems. However, due to the lack of acoustic information in PPGs, style and naturalness of the converted singing voices are still limited. To solve these problems, in this paper, we utilize an acoustic reference encoder to implicitly model singing characteristics. We experiment with different auxiliary features, including mel spectrograms, HuBERT, and the middle hidden feature (PPG-Mid) of pretrained automatic speech recognition (ASR) model, as the input of the reference encoder, and finally find the HuBERT feature is the best choice. In addition, we use contrastive predictive coding (CPC) module to further smooth the voices by predicting future observations in latent space. Experiments show that, compared with the baseline models, our proposed model can significantly improve the naturalness of converted singing voices and the similarity with the target singer. Moreover, our proposed model can also make the speakers with just speech data sing.
Local-Global Associative Frame Assemble in Video Re-ID
Oct 22, 2021
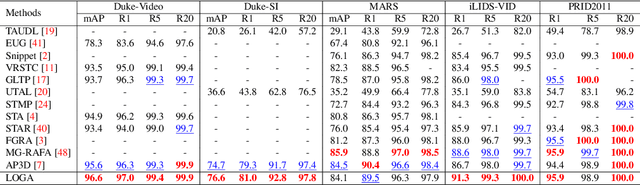
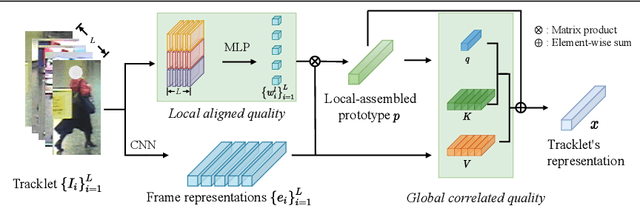

Noisy and unrepresentative frames in automatically generated object bounding boxes from video sequences cause significant challenges in learning discriminative representations in video re-identification (Re-ID). Most existing methods tackle this problem by assessing the importance of video frames according to either their local part alignments or global appearance correlations separately. However, given the diverse and unknown sources of noise which usually co-exist in captured video data, existing methods have not been effective satisfactorily. In this work, we explore jointly both local alignments and global correlations with further consideration of their mutual promotion/reinforcement so to better assemble complementary discriminative Re-ID information within all the relevant frames in video tracklets. Specifically, we concurrently optimise a local aligned quality (LAQ) module that distinguishes the quality of each frame based on local alignments, and a global correlated quality (GCQ) module that estimates global appearance correlations. With the help of a local-assembled global appearance prototype, we associate LAQ and GCQ to exploit their mutual complement. Extensive experiments demonstrate the superiority of the proposed model against state-of-the-art methods on five Re-ID benchmarks, including MARS, Duke-Video, Duke-SI, iLIDS-VID, and PRID2011.
Semi-Supervised Semantic Segmentation of Vessel Images using Leaking Perturbations
Oct 22, 2021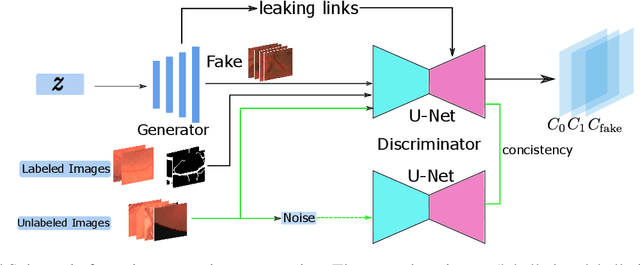
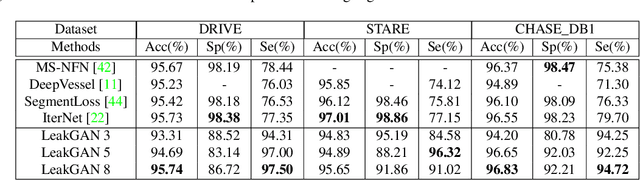
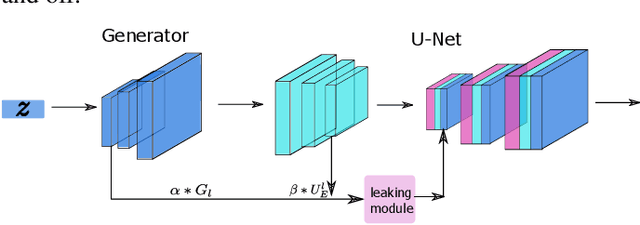

Semantic segmentation based on deep learning methods can attain appealing accuracy provided large amounts of annotated samples. However, it remains a challenging task when only limited labelled data are available, which is especially common in medical imaging. In this paper, we propose to use Leaking GAN, a GAN-based semi-supervised architecture for retina vessel semantic segmentation. Our key idea is to pollute the discriminator by leaking information from the generator. This leads to more moderate generations that benefit the training of GAN. As a result, the unlabelled examples can be better utilized to boost the learning of the discriminator, which eventually leads to stronger classification performance. In addition, to overcome the variations in medical images, the mean-teacher mechanism is utilized as an auxiliary regularization of the discriminator. Further, we modify the focal loss to fit it as the consistency objective for mean-teacher regularizer. Extensive experiments demonstrate that the Leaking GAN framework achieves competitive performance compared to the state-of-the-art methods when evaluated on benchmark datasets including DRIVE, STARE and CHASE\_DB1, using as few as 8 labelled images in the semi-supervised setting. It also outperforms existing algorithms on cross-domain segmentation tasks.
Revisiting Negation in Neural Machine Translation
Jul 26, 2021
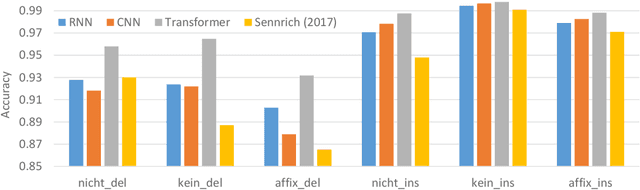

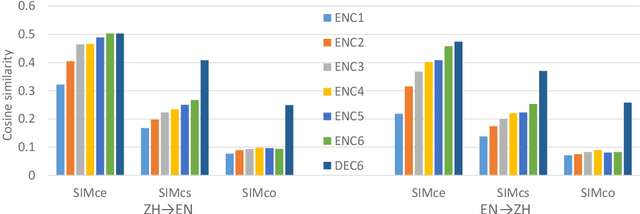
In this paper, we evaluate the translation of negation both automatically and manually, in English--German (EN--DE) and English--Chinese (EN--ZH). We show that the ability of neural machine translation (NMT) models to translate negation has improved with deeper and more advanced networks, although the performance varies between language pairs and translation directions. The accuracy of manual evaluation in EN-DE, DE-EN, EN-ZH, and ZH-EN is 95.7%, 94.8%, 93.4%, and 91.7%, respectively. In addition, we show that under-translation is the most significant error type in NMT, which contrasts with the more diverse error profile previously observed for statistical machine translation. To better understand the root of the under-translation of negation, we study the model's information flow and training data. While our information flow analysis does not reveal any deficiencies that could be used to detect or fix the under-translation of negation, we find that negation is often rephrased during training, which could make it more difficult for the model to learn a reliable link between source and target negation. We finally conduct intrinsic analysis and extrinsic probing tasks on negation, showing that NMT models can distinguish negation and non-negation tokens very well and encode a lot of information about negation in hidden states but nevertheless leave room for improvement.