 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Stereo Video Reconstruction Without Explicit Depth Maps for Endoscopic Surgery
Sep 16, 2021

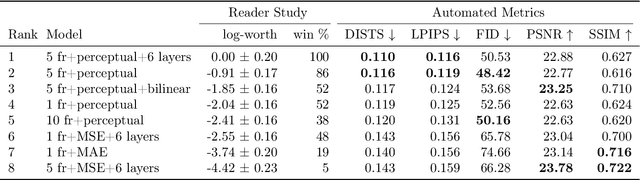
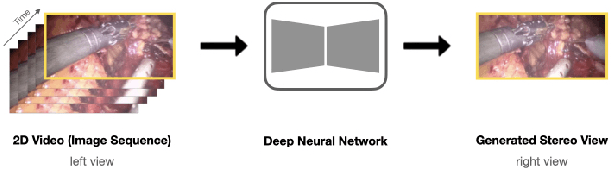
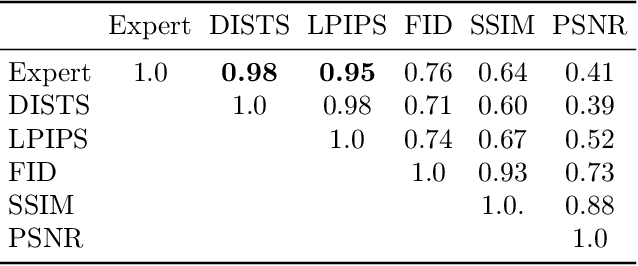
We introduce the task of stereo video reconstruction or, equivalently, 2D-to-3D video conversion for minimally invasive surgical video. We design and implement a series of end-to-end U-Net-based solutions for this task by varying the input (single frame vs. multiple consecutive frames), loss function (MSE, MAE, or perceptual losses), and network architecture. We evaluate these solutions by surveying ten experts - surgeons who routinely perform endoscopic surgery. We run two separate reader studies: one evaluating individual frames and the other evaluating fully reconstructed 3D video played on a VR headset. In the first reader study, a variant of the U-Net that takes as input multiple consecutive video frames and outputs the missing view performs best. We draw two conclusions from this outcome. First, motion information coming from multiple past frames is crucial in recreating stereo vision. Second, the proposed U-Net variant can indeed exploit such motion information for solving this task. The result from the second study further confirms the effectiveness of the proposed U-Net variant. The surgeons reported that they could successfully perceive depth from the reconstructed 3D video clips. They also expressed a clear preference for the reconstructed 3D video over the original 2D video. These two reader studies strongly support the usefulness of the proposed task of stereo reconstruction for minimally invasive surgical video and indicate that deep learning is a promising approach to this task. Finally, we identify two automatic metrics, LPIPS and DISTS, that are strongly correlated with expert judgement and that could serve as proxies for the latter in future studies.
GNN-LM: Language Modeling based on Global Contexts via GNN
Oct 17, 2021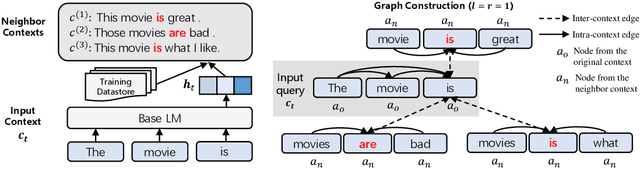
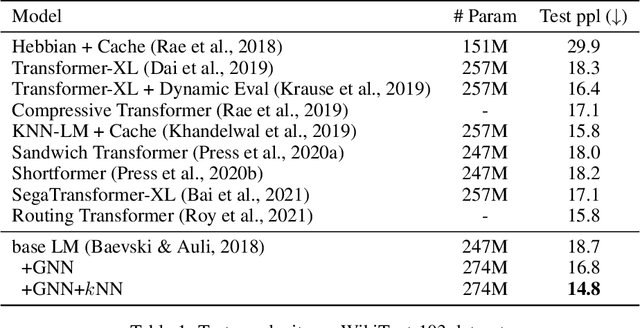
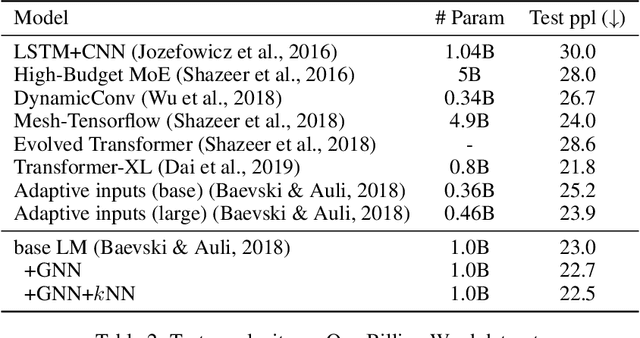
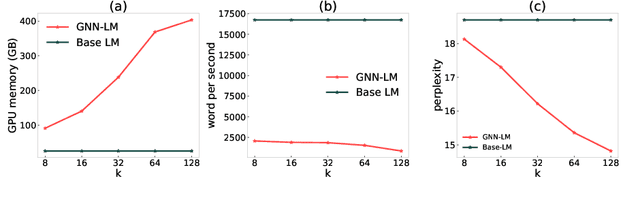
Inspired by the notion that ``{\it to copy is easier than to memorize}``, in this work, we introduce GNN-LM, which extends the vanilla neural language model (LM) by allowing to reference similar contexts in the entire training corpus. We build a directed heterogeneous graph between an input context and its semantically related neighbors selected from the training corpus, where nodes are tokens in the input context and retrieved neighbor contexts, and edges represent connections between nodes. Graph neural networks (GNNs) are constructed upon the graph to aggregate information from similar contexts to decode the token. This learning paradigm provides direct access to the reference contexts and helps improve a model's generalization ability. We conduct comprehensive experiments to validate the effectiveness of the GNN-LM: GNN-LM achieves a new state-of-the-art perplexity of 14.8 on WikiText-103 (a 4.5 point improvement over its counterpart of the vanilla LM model) and shows substantial improvement on One Billion Word and Enwiki8 datasets against strong baselines. In-depth ablation studies are performed to understand the mechanics of GNN-LM.
MGPSN: Motion-Guided Pseudo Siamese Network for Indoor Video Head Detection
Oct 07, 2021
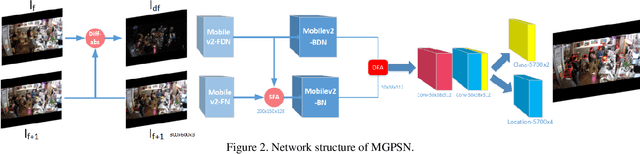
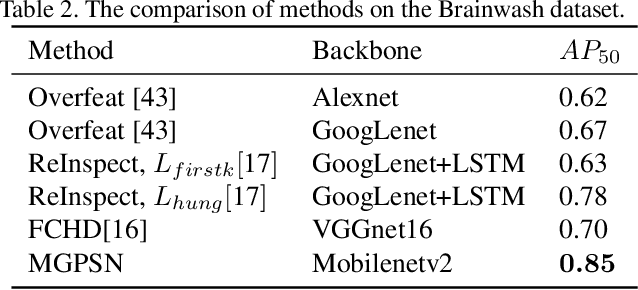
Head detection in real-world videos is an important research topic in computer vision. However, existing studies face some challenges in complex scenes. The performance of head detectors deteriorates when objects which have similar head appearance exist for indoor videos. Moreover, heads have small scales and diverse poses, which increases the difficulty in detection. To handle these issues, we propose Motion-Guided Pseudo Siamese Network for Indoor Video Head Detection (MGPSN), an end-to-end model to learn the robust head motion features. MGPSN integrates spatial-temporal information on pixel level, guiding the model to extract effective head features. Experiments show that MGPSN is able to suppress static objects and enhance motion instances. Compared with previous methods, it achieves state-of-the-art performance on the crowd Brainwash dataset. Different backbone networks and detectors are evaluated to verify the flexibility and generality of MGPSN.
Optimizing Alignment of Speech and Language Latent Spaces for End-to-End Speech Recognition and Understanding
Oct 23, 2021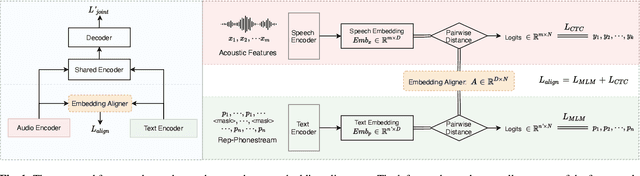
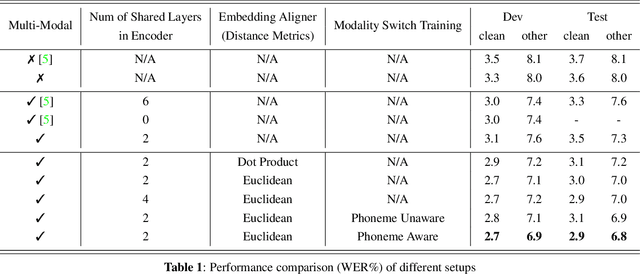
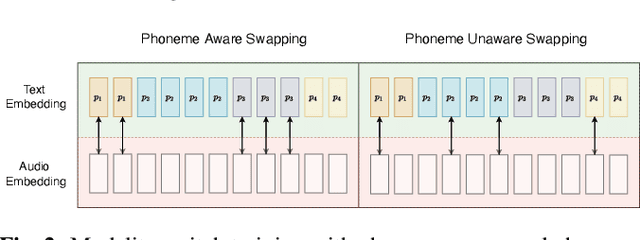
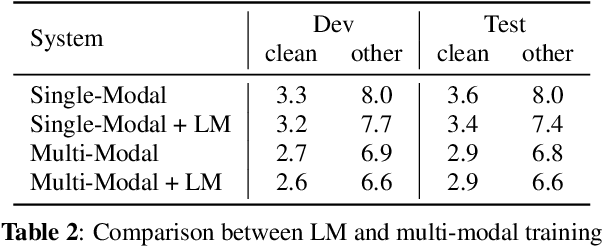
The advances in attention-based encoder-decoder (AED) networks have brought great progress to end-to-end (E2E) automatic speech recognition (ASR). One way to further improve the performance of AED-based E2E ASR is to introduce an extra text encoder for leveraging extensive text data and thus capture more context-aware linguistic information. However, this approach brings a mismatch problem between the speech encoder and the text encoder due to the different units used for modeling. In this paper, we propose an embedding aligner and modality switch training to better align the speech and text latent spaces. The embedding aligner is a shared linear projection between text encoder and speech encoder trained by masked language modeling (MLM) loss and connectionist temporal classification (CTC), respectively. The modality switch training randomly swaps speech and text embeddings based on the forced alignment result to learn a joint representation space. Experimental results show that our proposed approach achieves a relative 14% to 19% word error rate (WER) reduction on Librispeech ASR task. We further verify its effectiveness on spoken language understanding (SLU), i.e., an absolute 2.5% to 2.8% F1 score improvement on SNIPS slot filling task.
Discriminative Latent Semantic Graph for Video Captioning
Aug 08, 2021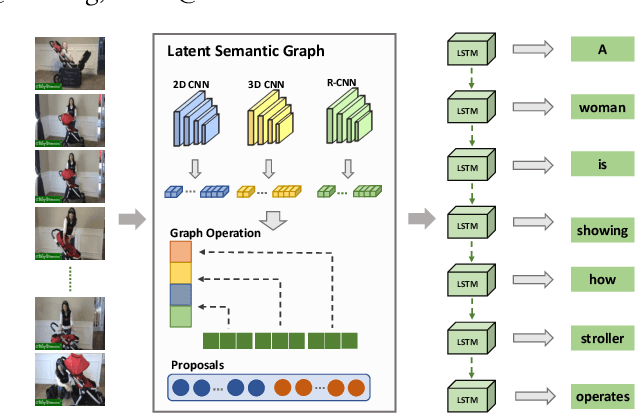
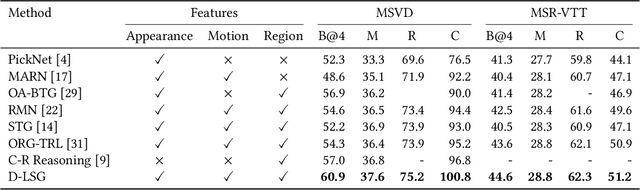
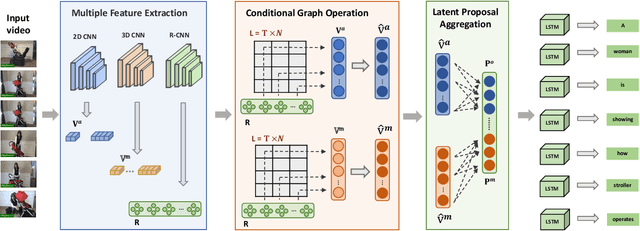
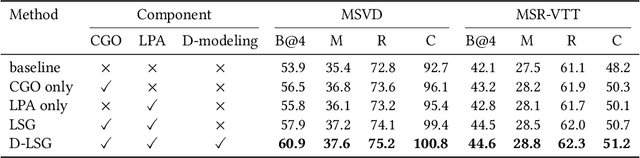
Video captioning aims to automatically generate natural language sentences that can describe the visual contents of a given video. Existing generative models like encoder-decoder frameworks cannot explicitly explore the object-level interactions and frame-level information from complex spatio-temporal data to generate semantic-rich captions. Our main contribution is to identify three key problems in a joint framework for future video summarization tasks. 1) Enhanced Object Proposal: we propose a novel Conditional Graph that can fuse spatio-temporal information into latent object proposal. 2) Visual Knowledge: Latent Proposal Aggregation is proposed to dynamically extract visual words with higher semantic levels. 3) Sentence Validation: A novel Discriminative Language Validator is proposed to verify generated captions so that key semantic concepts can be effectively preserved. Our experiments on two public datasets (MVSD and MSR-VTT) manifest significant improvements over state-of-the-art approaches on all metrics, especially for BLEU-4 and CIDEr. Our code is available at https://github.com/baiyang4/D-LSG-Video-Caption.
Multimotion Visual Odometry (MVO)
Oct 28, 2021

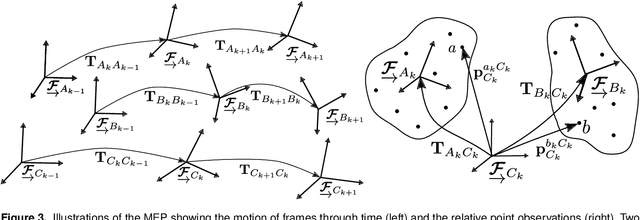
Visual motion estimation is a well-studied challenge in autonomous navigation. Recent work has focused on addressing multimotion estimation in highly dynamic environments. These environments not only comprise multiple, complex motions but also tend to exhibit significant occlusion. Estimating third-party motions simultaneously with the sensor egomotion is difficult because an object's observed motion consists of both its true motion and the sensor motion. Most previous works in multimotion estimation simplify this problem by relying on appearance-based object detection or application-specific motion constraints. These approaches are effective in specific applications and environments but do not generalize well to the full multimotion estimation problem (MEP). This paper presents Multimotion Visual Odometry (MVO), a multimotion estimation pipeline that estimates the full SE(3) trajectory of every motion in the scene, including the sensor egomotion, without relying on appearance-based information. MVO extends the traditional visual odometry (VO) pipeline with multimotion segmentation and tracking techniques. It uses physically founded motion priors to extrapolate motions through temporary occlusions and identify the reappearance of motions through motion closure. Evaluations on real-world data from the Oxford Multimotion Dataset (OMD) and the KITTI Vision Benchmark Suite demonstrate that MVO achieves good estimation accuracy compared to similar approaches and is applicable to a variety of multimotion estimation challenges.
Accurate shape and phase averaging of time series through Dynamic Time Warping
Sep 02, 2021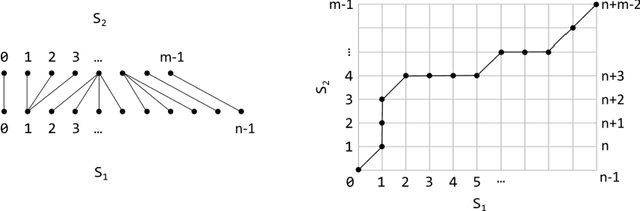

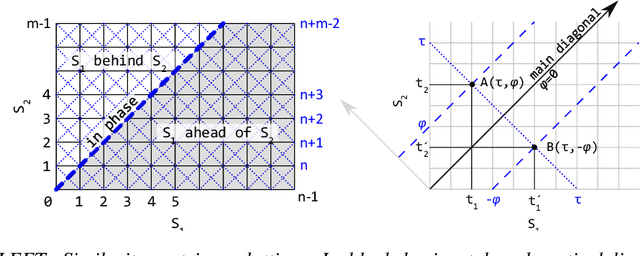

We propose a novel time series averaging method based on Dynamic Time Warping (DTW). In contrast to previous methods, our algorithm preserves durational information and the distinctive durational features of the sequences due to a simple conversion of the output of DTW into a time sequence and an innovative iterative averaging process. We show that it accurately estimates the ground truth mean sequences and mean temporal location of landmarks in synthetic and real-world datasets and outperforms state-of-the-art methods.
Click-Based Student Performance Prediction: A Clustering Guided Meta-Learning Approach
Oct 28, 2021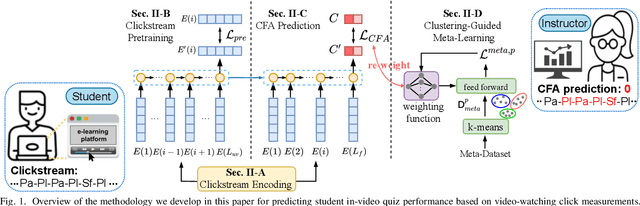
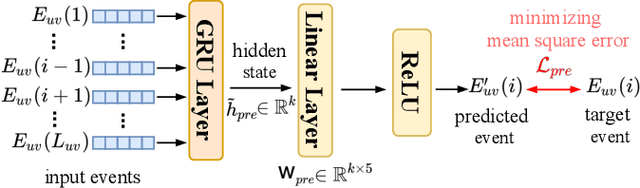
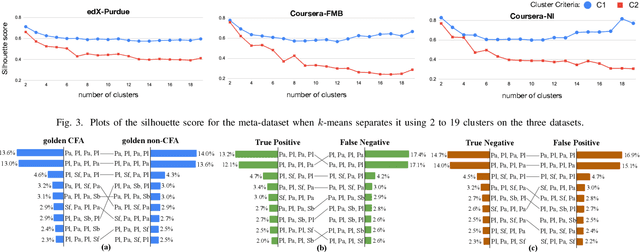
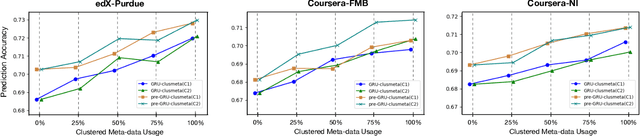
We study the problem of predicting student knowledge acquisition in online courses from clickstream behavior. Motivated by the proliferation of eLearning lecture delivery, we specifically focus on student in-video activity in lectures videos, which consist of content and in-video quizzes. Our methodology for predicting in-video quiz performance is based on three key ideas we develop. First, we model students' clicking behavior via time-series learning architectures operating on raw event data, rather than defining hand-crafted features as in existing approaches that may lose important information embedded within the click sequences. Second, we develop a self-supervised clickstream pre-training to learn informative representations of clickstream events that can initialize the prediction model effectively. Third, we propose a clustering guided meta-learning-based training that optimizes the prediction model to exploit clusters of frequent patterns in student clickstream sequences. Through experiments on three real-world datasets, we demonstrate that our method obtains substantial improvements over two baseline models in predicting students' in-video quiz performance. Further, we validate the importance of the pre-training and meta-learning components of our framework through ablation studies. Finally, we show how our methodology reveals insights on video-watching behavior associated with knowledge acquisition for useful learning analytics.
A Critical Study on the Recent Deep Learning Based Semi-Supervised Video Anomaly Detection Methods
Nov 02, 2021
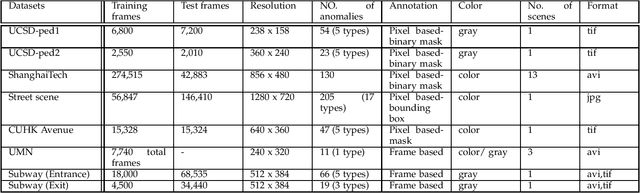
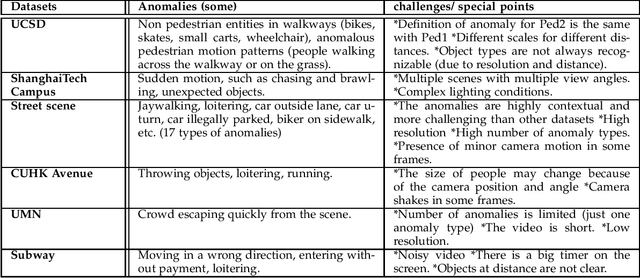
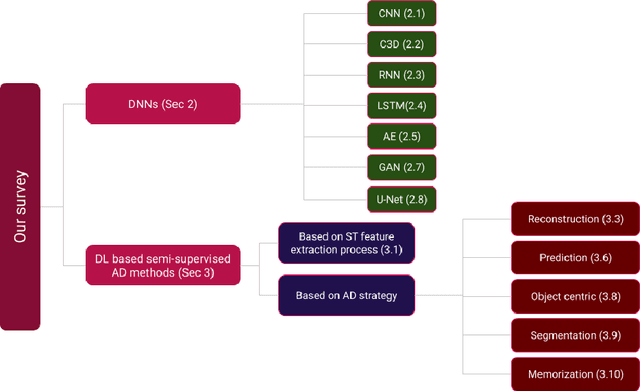
Video anomaly detection is one of the hot research topics in computer vision nowadays, as abnormal events contain a high amount of information. Anomalies are one of the main detection targets in surveillance systems, usually needing real-time actions. Regarding the availability of labeled data for training (i.e., there is not enough labeled data for abnormalities), semi-supervised anomaly detection approaches have gained interest recently. This paper introduces the researchers of the field to a new perspective and reviews the recent deep-learning based semi-supervised video anomaly detection approaches, based on a common strategy they use for anomaly detection. Our goal is to help researchers develop more effective video anomaly detection methods. As the selection of a right Deep Neural Network plays an important role for several parts of this task, a quick comparative review on DNNs is prepared first. Unlike previous surveys, DNNs are reviewed from a spatiotemporal feature extraction viewpoint, customized for video anomaly detection. This part of the review can help researchers in this field select suitable networks for different parts of their methods. Moreover, some of the state-of-the-art anomaly detection methods, based on their detection strategy, are critically surveyed. The review provides a novel and deep look at existing methods and results in stating the shortcomings of these approaches, which can be a hint for future works.
Homography augumented momentum constrastive learning for SAR image retrieval
Sep 21, 2021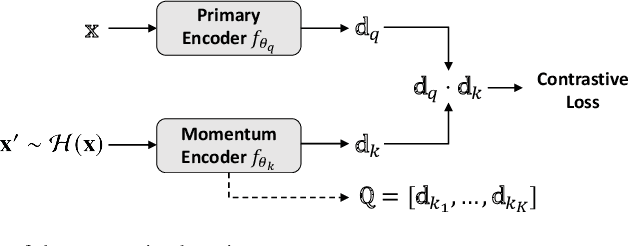
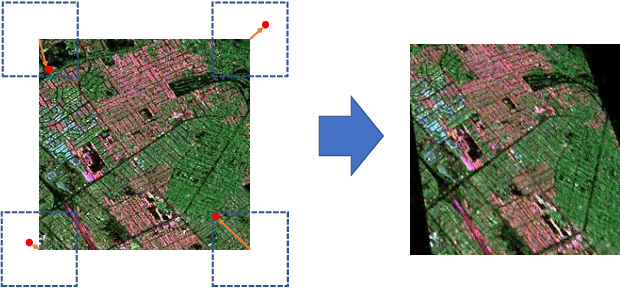
Deep learning-based image retrieval has been emphasized in computer vision. Representation embedding extracted by deep neural networks (DNNs) not only aims at containing semantic information of the image, but also can manage large-scale image retrieval tasks. In this work, we propose a deep learning-based image retrieval approach using homography transformation augmented contrastive learning to perform large-scale synthetic aperture radar (SAR) image search tasks. Moreover, we propose a training method for the DNNs induced by contrastive learning that does not require any labeling procedure. This may enable tractability of large-scale datasets with relative ease. Finally, we verify the performance of the proposed method by conducting experiments on the polarimetric SAR image datasets.