 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Understanding of Kernels in CNN Models by Suppressing Irrelevant Visual Features in Images
Aug 25, 2021

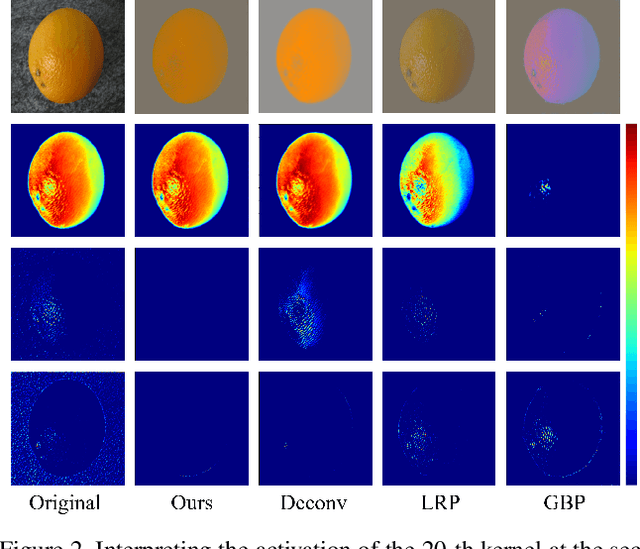


Deep learning models have shown their superior performance in various vision tasks. However, the lack of precisely interpreting kernels in convolutional neural networks (CNNs) is becoming one main obstacle to wide applications of deep learning models in real scenarios. Although existing interpretation methods may find certain visual patterns which are associated with the activation of a specific kernel, those visual patterns may not be specific or comprehensive enough for interpretation of a specific activation of kernel of interest. In this paper, a simple yet effective optimization method is proposed to interpret the activation of any kernel of interest in CNN models. The basic idea is to simultaneously preserve the activation of the specific kernel and suppress the activation of all other kernels at the same layer. In this way, only visual information relevant to the activation of the specific kernel is remained in the input. Consistent visual information from multiple modified inputs would help users understand what kind of features are specifically associated with specific kernel. Comprehensive evaluation shows that the proposed method can help better interpret activation of specific kernels than widely used methods, even when two kernels have very similar activation regions from the same input image.
A Precision Diagnostic Framework of Renal Cell Carcinoma on Whole-Slide Images using Deep Learning
Oct 26, 2021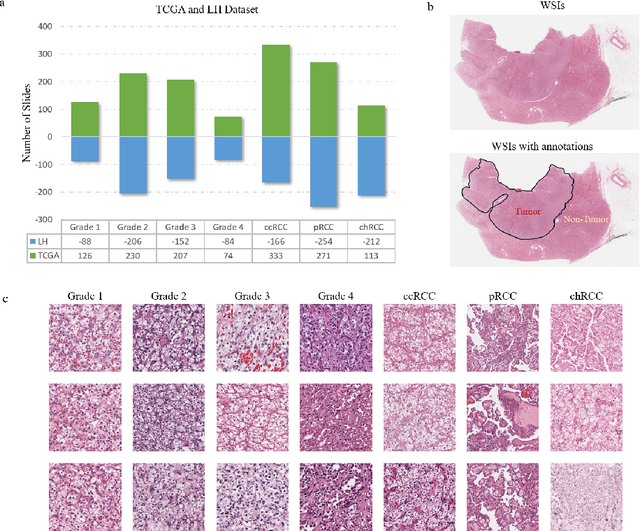
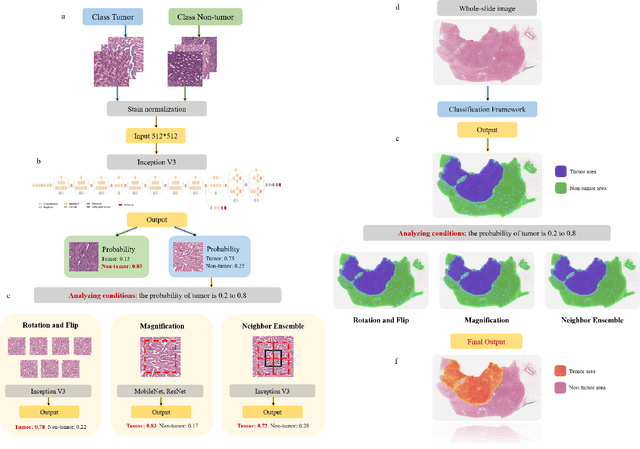
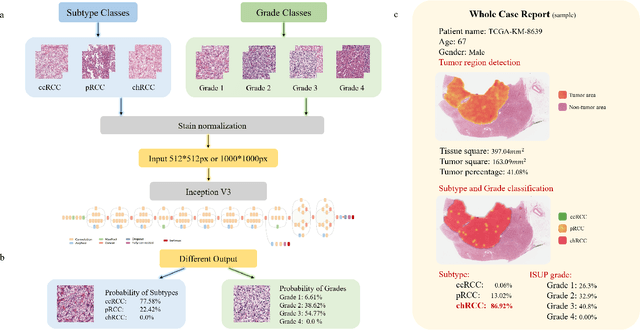
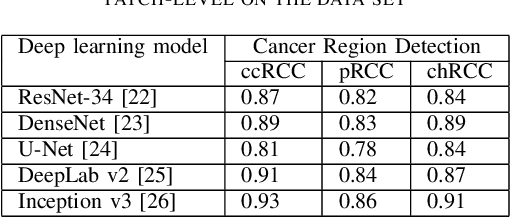
Diagnostic pathology, which is the basis and gold standard of cancer diagnosis, provides essential information on the prognosis of the disease and vital evidence for clinical treatment. Tumor region detection, subtype and grade classification are the fundamental diagnostic indicators for renal cell carcinoma (RCC) in whole-slide images (WSIs). However, pathological diagnosis is subjective, differences in observation and diagnosis between pathologists is common in hospitals with inadequate diagnostic capacity. The main challenge for developing deep learning based RCC diagnostic system is the lack of large-scale datasets with precise annotations. In this work, we proposed a deep learning-based framework for analyzing histopathological images of patients with renal cell carcinoma, which has the potential to achieve pathologist-level accuracy in diagnosis. A deep convolutional neural network (InceptionV3) was trained on the high-quality annotated dataset of The Cancer Genome Atlas (TCGA) whole-slide histopathological image for accurate tumor area detection, classification of RCC subtypes, and ISUP grades classification of clear cell carcinoma subtypes. These results suggest that our framework can help pathologists in the detection of cancer region and classification of subtypes and grades, which could be applied to any cancer type, providing auxiliary diagnosis and promoting clinical consensus.
Similarity-Aware Fusion Network for 3D Semantic Segmentation
Jul 06, 2021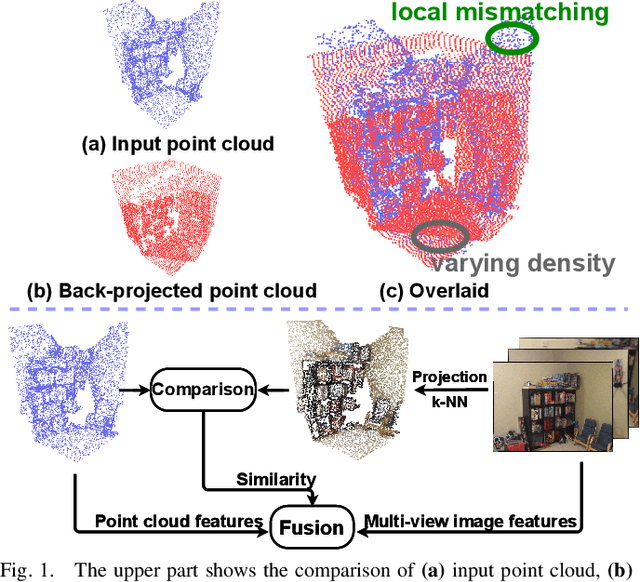
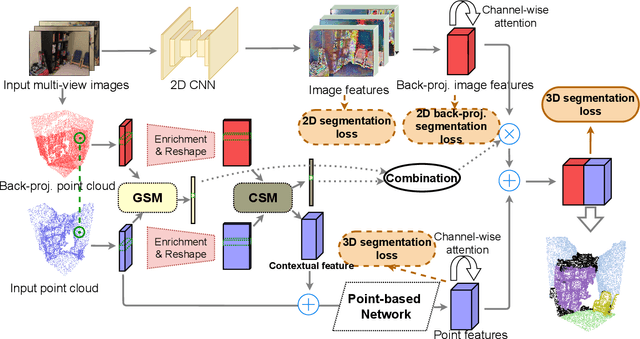
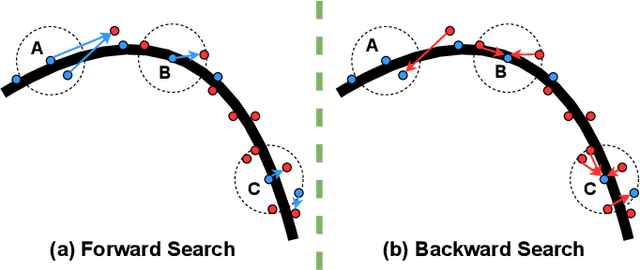
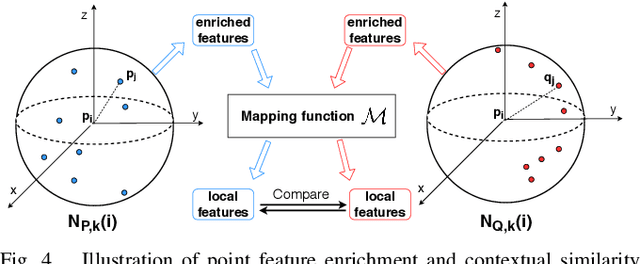
In this paper, we propose a similarity-aware fusion network (SAFNet) to adaptively fuse 2D images and 3D point clouds for 3D semantic segmentation. Existing fusion-based methods achieve remarkable performances by integrating information from multiple modalities. However, they heavily rely on the correspondence between 2D pixels and 3D points by projection and can only perform the information fusion in a fixed manner, and thus their performances cannot be easily migrated to a more realistic scenario where the collected data often lack strict pair-wise features for prediction. To address this, we employ a late fusion strategy where we first learn the geometric and contextual similarities between the input and back-projected (from 2D pixels) point clouds and utilize them to guide the fusion of two modalities to further exploit complementary information. Specifically, we employ a geometric similarity module (GSM) to directly compare the spatial coordinate distributions of pair-wise 3D neighborhoods, and a contextual similarity module (CSM) to aggregate and compare spatial contextual information of corresponding central points. The two proposed modules can effectively measure how much image features can help predictions, enabling the network to adaptively adjust the contributions of two modalities to the final prediction of each point. Experimental results on the ScanNetV2 benchmark demonstrate that SAFNet significantly outperforms existing state-of-the-art fusion-based approaches across various data integrity.
Adaptive Hierarchical Dual Consistency for Semi-Supervised Left Atrium Segmentation on Cross-Domain Data
Sep 20, 2021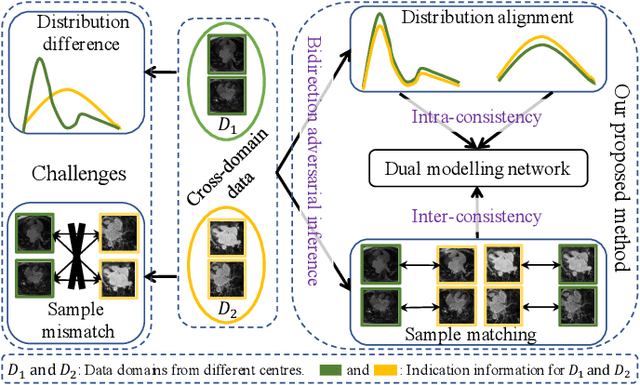
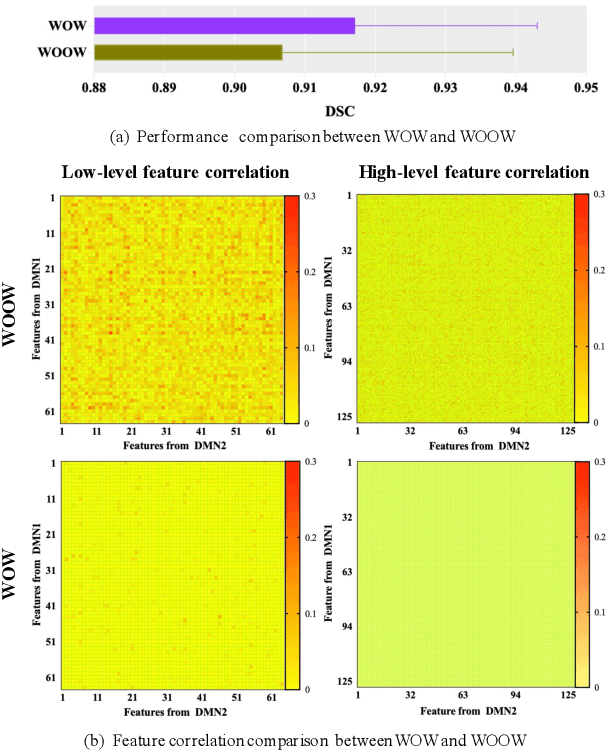
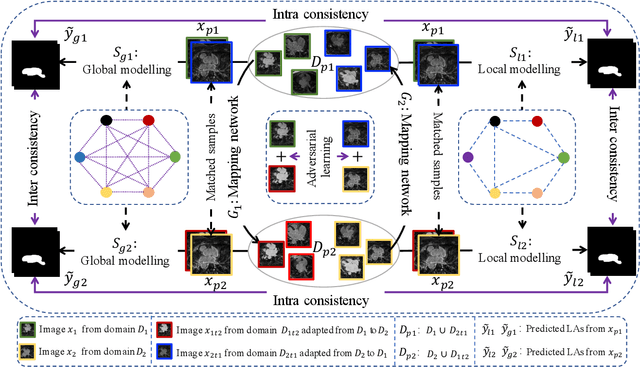
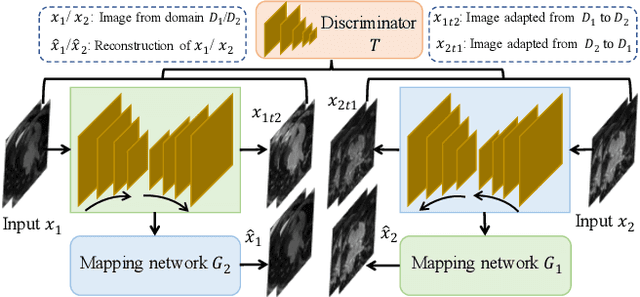
Semi-supervised learning provides great significance in left atrium (LA) segmentation model learning with insufficient labelled data. Generalising semi-supervised learning to cross-domain data is of high importance to further improve model robustness. However, the widely existing distribution difference and sample mismatch between different data domains hinder the generalisation of semi-supervised learning. In this study, we alleviate these problems by proposing an Adaptive Hierarchical Dual Consistency (AHDC) for the semi-supervised LA segmentation on cross-domain data. The AHDC mainly consists of a Bidirectional Adversarial Inference module (BAI) and a Hierarchical Dual Consistency learning module (HDC). The BAI overcomes the difference of distributions and the sample mismatch between two different domains. It mainly learns two mapping networks adversarially to obtain two matched domains through mutual adaptation. The HDC investigates a hierarchical dual learning paradigm for cross-domain semi-supervised segmentation based on the obtained matched domains. It mainly builds two dual-modelling networks for mining the complementary information in both intra-domain and inter-domain. For the intra-domain learning, a consistency constraint is applied to the dual-modelling targets to exploit the complementary modelling information. For the inter-domain learning, a consistency constraint is applied to the LAs modelled by two dual-modelling networks to exploit the complementary knowledge among different data domains. We demonstrated the performance of our proposed AHDC on four 3D late gadolinium enhancement cardiac MR (LGE-CMR) datasets from different centres and a 3D CT dataset. Compared to other state-of-the-art methods, our proposed AHDC achieved higher segmentation accuracy, which indicated its capability in the cross-domain semi-supervised LA segmentation.
Why Settle for Just One? Extending EL++ Ontology Embeddings with Many-to-Many Relationships
Oct 20, 2021
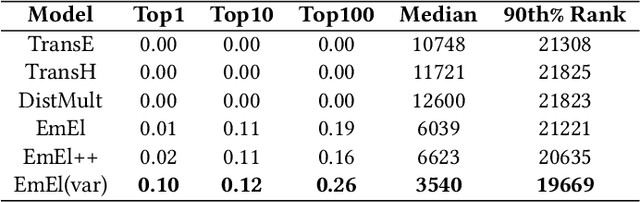
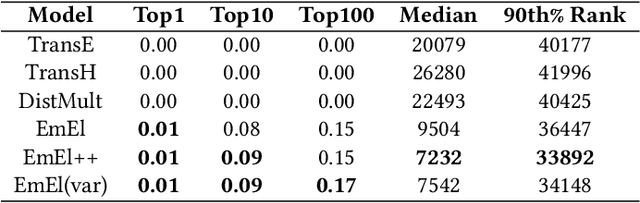
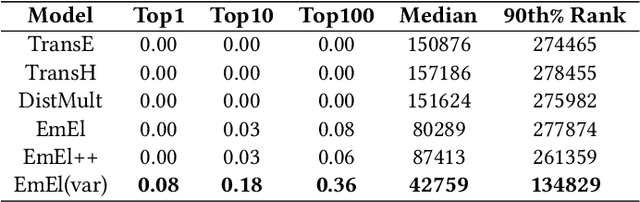
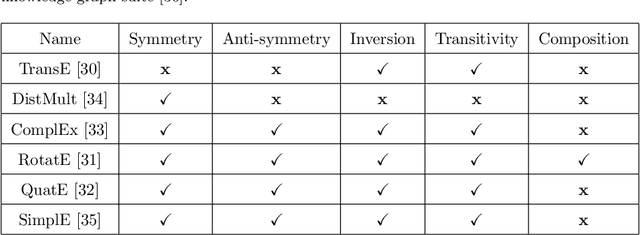
Knowledge Graph (KG) embeddings provide a low-dimensional representation of entities and relations of a Knowledge Graph and are used successfully for various applications such as question answering and search, reasoning, inference, and missing link prediction. However, most of the existing KG embeddings only consider the network structure of the graph and ignore the semantics and the characteristics of the underlying ontology that provides crucial information about relationships between entities in the KG. Recent efforts in this direction involve learning embeddings for a Description Logic (logical underpinning for ontologies) named EL++. However, such methods consider all the relations defined in the ontology to be one-to-one which severely limits their performance and applications. We provide a simple and effective solution to overcome this shortcoming that allows such methods to consider many-to-many relationships while learning embedding representations. Experiments conducted using three different EL++ ontologies show substantial performance improvement over five baselines. Our proposed solution also paves the way for learning embedding representations for even more expressive description logics such as SROIQ.
Direct source and early reflections localization using deep deconvolution network under reverbrate environment
Oct 10, 2021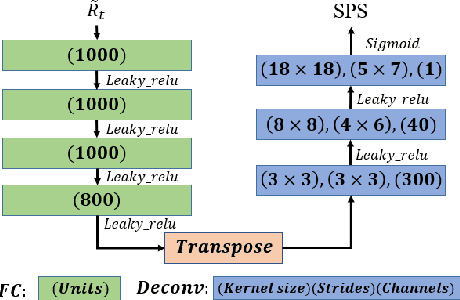
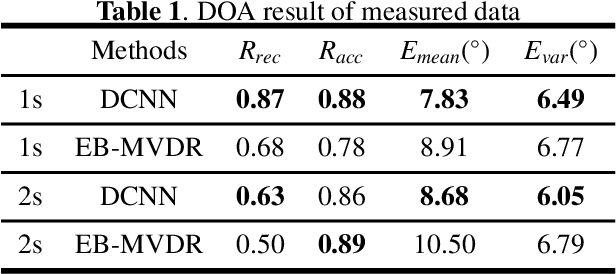
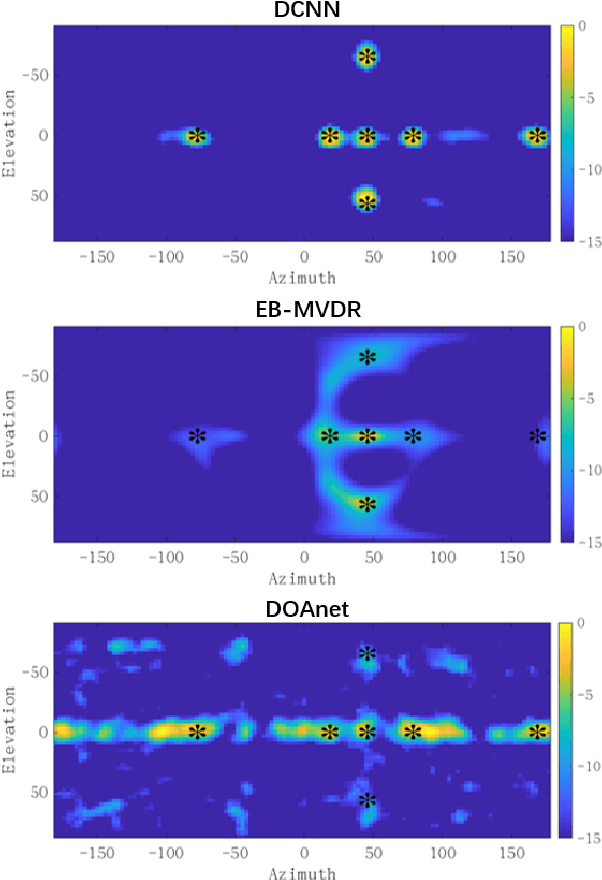
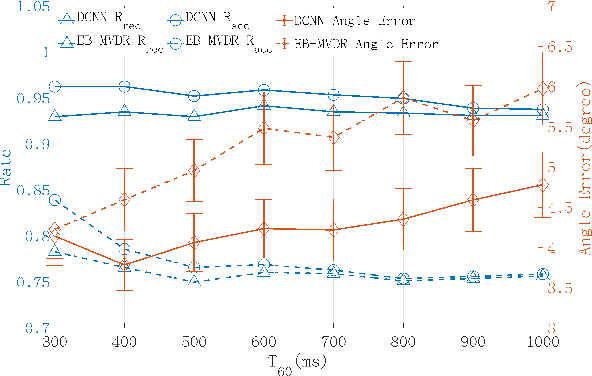
This paper proposes a deconvolution-based network (DCNN) model for DOA estimation of direct source and early reflections under reverberate scenarios. Considering that the first-order reflections of the sound source also contain spatial directivity like the direct source, we treat both of them as the sources in the learning process. We use the covariance matrix of high order Ambisonics (HOA) signals in time domain as the input feature of the network, which is concise while contains precise spatial information under reverberate scenarios. Besides, we use the deconvolution-based network for the spatial pseudo-spectrum (SPS) reconstruction in the 2D polar space, based on which the spatial relationship between elevation and azimuth can be depicted. We have carried out a series of experiments based on simulated and measured data under different reverberate scenarios, which prove the robustness and accuracy of the proposed DCNN model.
A Survey on Multi-modal Summarization
Sep 11, 2021
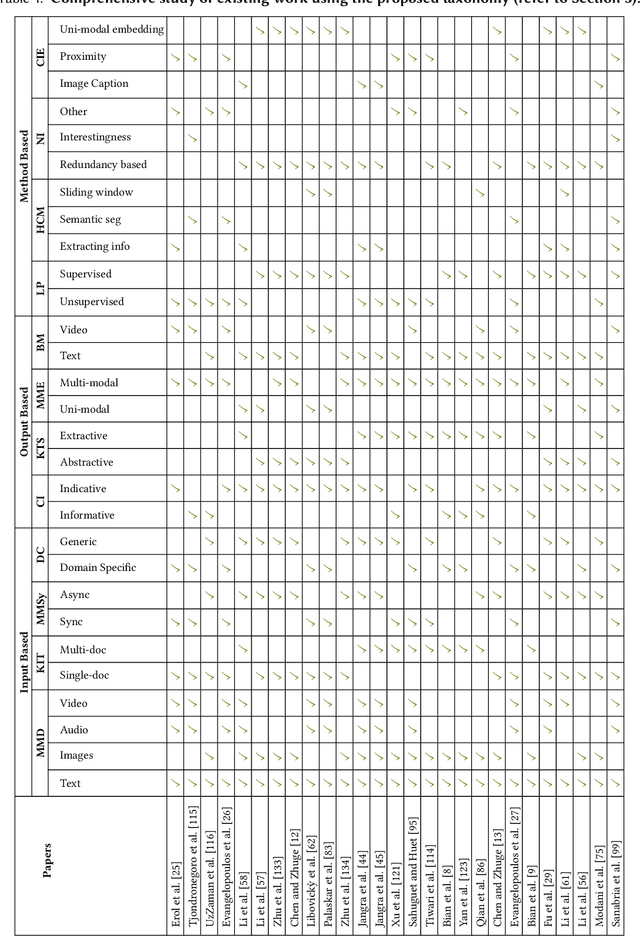
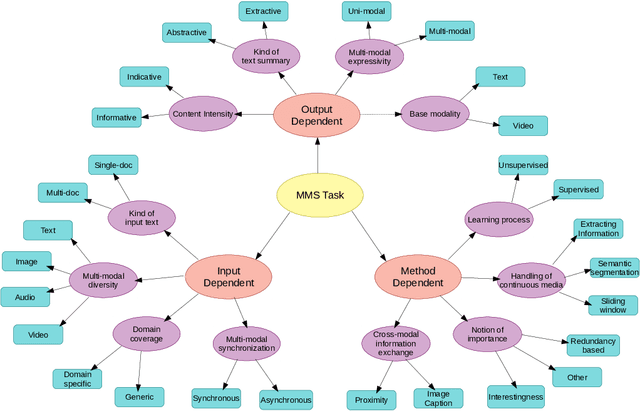

The new era of technology has brought us to the point where it is convenient for people to share their opinions over an abundance of platforms. These platforms have a provision for the users to express themselves in multiple forms of representations, including text, images, videos, and audio. This, however, makes it difficult for users to obtain all the key information about a topic, making the task of automatic multi-modal summarization (MMS) essential. In this paper, we present a comprehensive survey of the existing research in the area of MMS.
Coherent False Seizure Prediction in Epilepsy, Coincidence or Providence?
Oct 26, 2021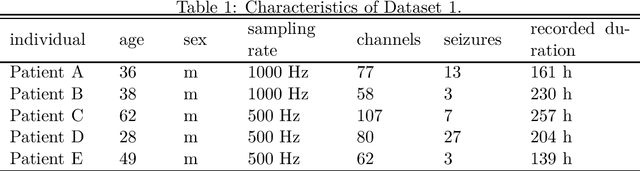
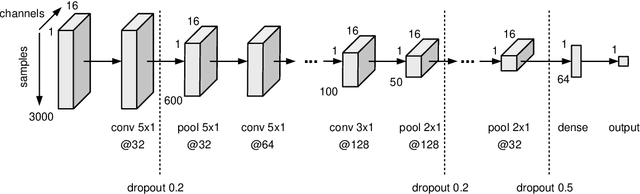
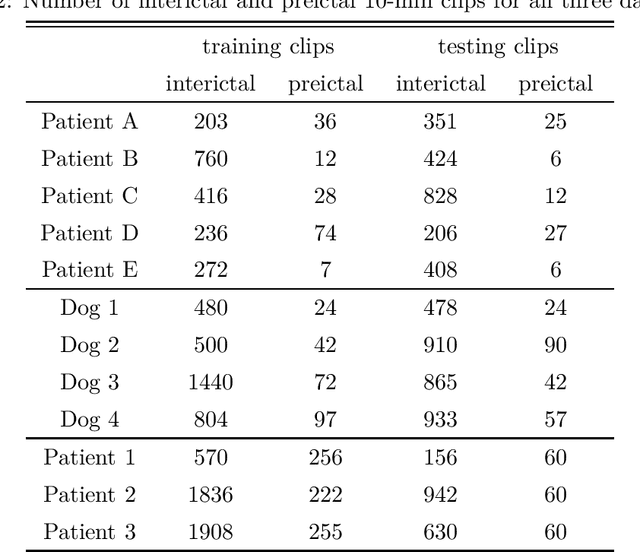
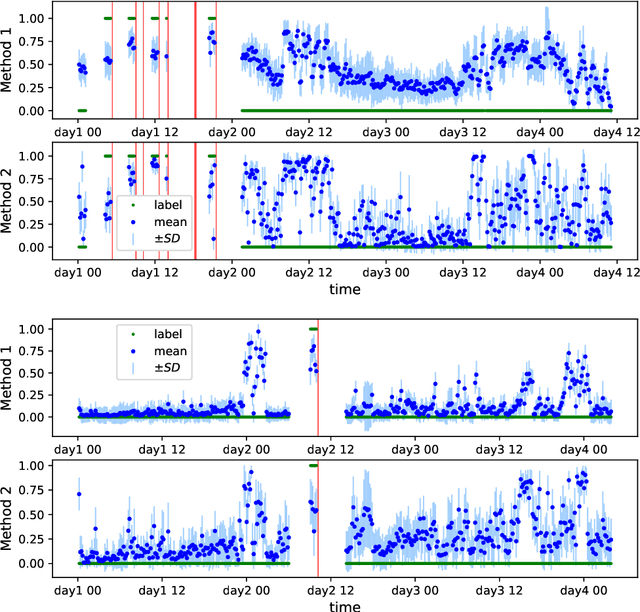
Seizure forecasting using machine learning is possible, but the performance is far from ideal, as indicated by many false predictions and low specificity. Here, we examine false and missing alarms of two algorithms on long-term datasets to show that the limitations are less related to classifiers or features, but rather to intrinsic changes in the data. We evaluated two algorithms on three datasets by computing the correlation of false predictions and estimating the information transfer between both classification methods. For 9 out of 12 individuals both methods showed a performance better than chance. For all individuals we observed a positive correlation in predictions. For individuals with strong correlation in false predictions we were able to boost the performance of one method by excluding test samples based on the results of the second method. Substantially different algorithms exhibit a highly consistent performance and a strong coherency in false and missing alarms. Hence, changing the underlying hypothesis of a preictal state of fixed time length prior to each seizure to a proictal state is more helpful than further optimizing classifiers. The outcome is significant for the evaluation of seizure prediction algorithms on continuous data.
Knowledge Graph informed Fake News Classification via Heterogeneous Representation Ensembles
Oct 20, 2021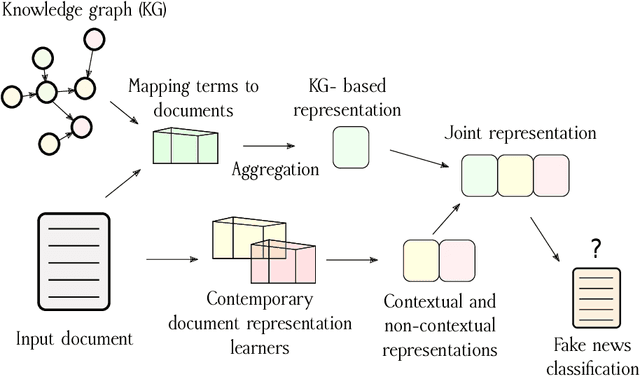

Increasing amounts of freely available data both in textual and relational form offers exploration of richer document representations, potentially improving the model performance and robustness. An emerging problem in the modern era is fake news detection -- many easily available pieces of information are not necessarily factually correct, and can lead to wrong conclusions or are used for manipulation. In this work we explore how different document representations, ranging from simple symbolic bag-of-words, to contextual, neural language model-based ones can be used for efficient fake news identification. One of the key contributions is a set of novel document representation learning methods based solely on knowledge graphs, i.e. extensive collections of (grounded) subject-predicate-object triplets. We demonstrate that knowledge graph-based representations already achieve competitive performance to conventionally accepted representation learners. Furthermore, when combined with existing, contextual representations, knowledge graph-based document representations can achieve state-of-the-art performance. To our knowledge this is the first larger-scale evaluation of how knowledge graph-based representations can be systematically incorporated into the process of fake news classification.
Learning to maximize global influence from local observations
Sep 24, 2021We study a family online influence maximization problems where in a sequence of rounds $t=1,\ldots,T$, a decision maker selects one from a large number of agents with the goal of maximizing influence. Upon choosing an agent, the decision maker shares a piece of information with the agent, which information then spreads in an unobserved network over which the agents communicate. The goal of the decision maker is to select the sequence of agents in a way that the total number of influenced nodes in the network. In this work, we consider a scenario where the networks are generated independently for each $t$ according to some fixed but unknown distribution, so that the set of influenced nodes corresponds to the connected component of the random graph containing the vertex corresponding to the selected agent. Furthermore, we assume that the decision maker only has access to limited feedback: instead of making the unrealistic assumption that the entire network is observable, we suppose that the available feedback is generated based on a small neighborhood of the selected vertex. Our results show that such partial local observations can be sufficient for maximizing global influence. We model the underlying random graph as a sparse inhomogeneous Erd\H{o}s--R\'enyi graph, and study three specific families of random graph models in detail: stochastic block models, Chung--Lu models and Kronecker random graphs. We show that in these cases one may learn to maximize influence by merely observing the degree of the selected vertex in the generated random graph. We propose sequential learning algorithms that aim at maximizing influence, and provide their theoretical analysis in both the subcritical and supercritical regimes of all considered models.