 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Predicting Efficiency/Effectiveness Trade-offs for Dense vs. Sparse Retrieval Strategy Selection
Sep 22, 2021
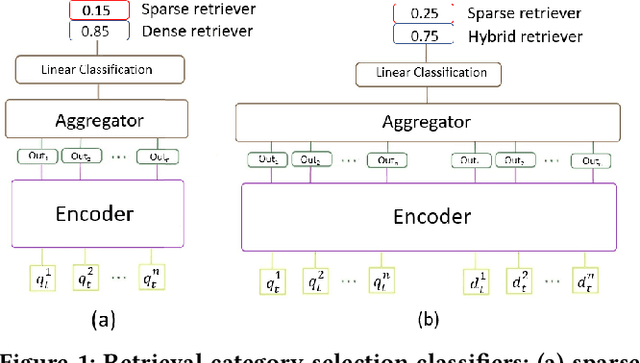
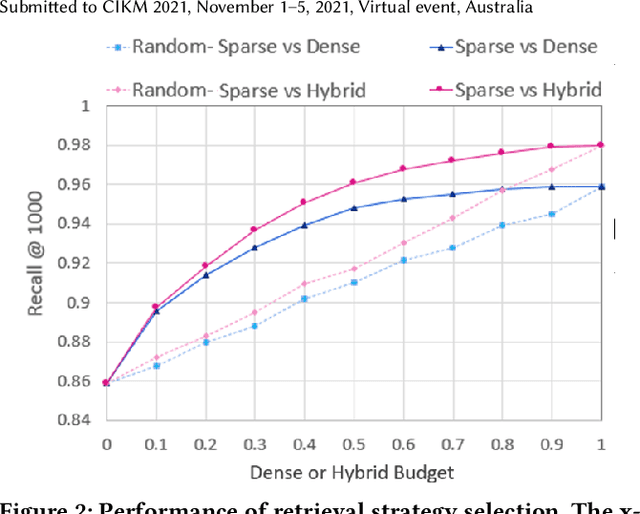
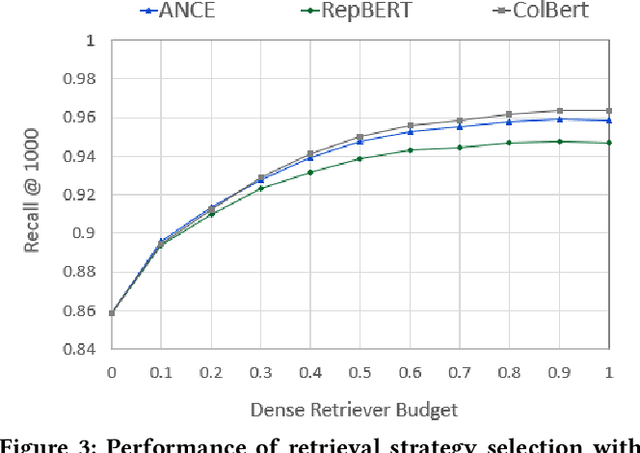
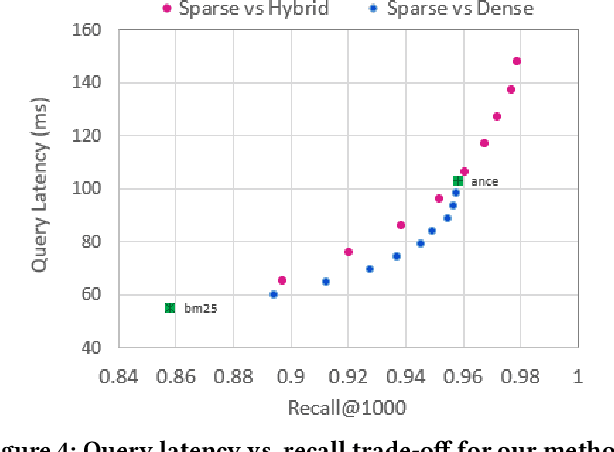
Over the last few years, contextualized pre-trained transformer models such as BERT have provided substantial improvements on information retrieval tasks. Recent approaches based on pre-trained transformer models such as BERT, fine-tune dense low-dimensional contextualized representations of queries and documents in embedding space. While these dense retrievers enjoy substantial retrieval effectiveness improvements compared to sparse retrievers, they are computationally intensive, requiring substantial GPU resources, and dense retrievers are known to be more expensive from both time and resource perspectives. In addition, sparse retrievers have been shown to retrieve complementary information with respect to dense retrievers, leading to proposals for hybrid retrievers. These hybrid retrievers leverage low-cost, exact-matching based sparse retrievers along with dense retrievers to bridge the semantic gaps between query and documents. In this work, we address this trade-off between the cost and utility of sparse vs dense retrievers by proposing a classifier to select a suitable retrieval strategy (i.e., sparse vs. dense vs. hybrid) for individual queries. Leveraging sparse retrievers for queries which can be answered with sparse retrievers decreases the number of calls to GPUs. Consequently, while utility is maintained, query latency decreases. Although we use less computational resources and spend less time, we still achieve improved performance. Our classifier can select between sparse and dense retrieval strategies based on the query alone. We conduct experiments on the MS MARCO passage dataset demonstrating an improved range of efficiency/effectiveness trade-offs between purely sparse, purely dense or hybrid retrieval strategies, allowing an appropriate strategy to be selected based on a target latency and resource budget.
UltraGCN: Ultra Simplification of Graph Convolutional Networks for Recommendation
Oct 28, 2021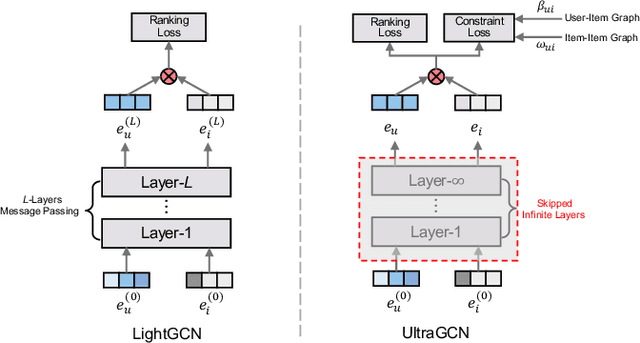
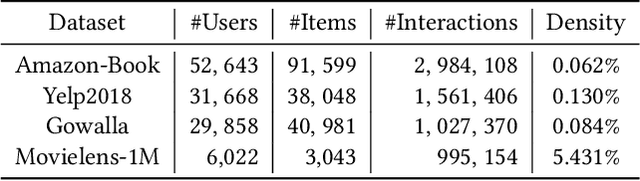
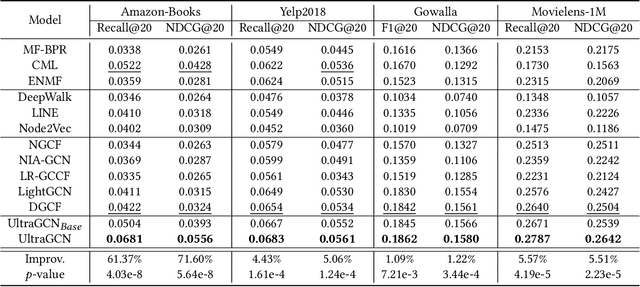
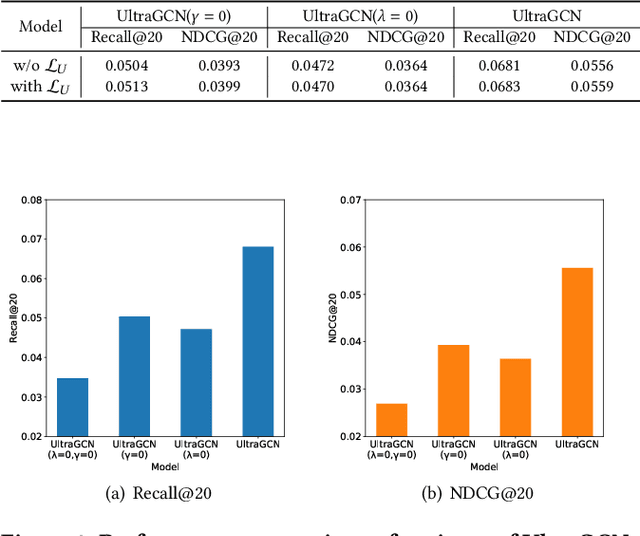
With the recent success of graph convolutional networks (GCNs), they have been widely applied for recommendation, and achieved impressive performance gains. The core of GCNs lies in its message passing mechanism to aggregate neighborhood information. However, we observed that message passing largely slows down the convergence of GCNs during training, especially for large-scale recommender systems, which hinders their wide adoption. LightGCN makes an early attempt to simplify GCNs for collaborative filtering by omitting feature transformations and nonlinear activations. In this paper, we take one step further to propose an ultra-simplified formulation of GCNs (dubbed UltraGCN), which skips infinite layers of message passing for efficient recommendation. Instead of explicit message passing, UltraGCN resorts to directly approximate the limit of infinite-layer graph convolutions via a constraint loss. Meanwhile, UltraGCN allows for more appropriate edge weight assignments and flexible adjustment of the relative importances among different types of relationships. This finally yields a simple yet effective UltraGCN model, which is easy to implement and efficient to train. Experimental results on four benchmark datasets show that UltraGCN not only outperforms the state-of-the-art GCN models but also achieves more than 10x speedup over LightGCN.
A Quantitative Comparison of Epistemic Uncertainty Maps Applied to Multi-Class Segmentation
Sep 22, 2021

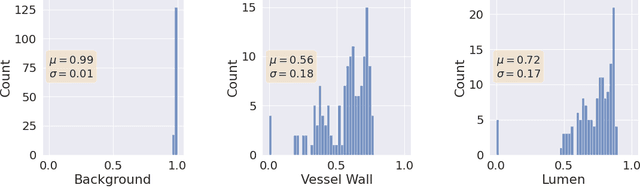
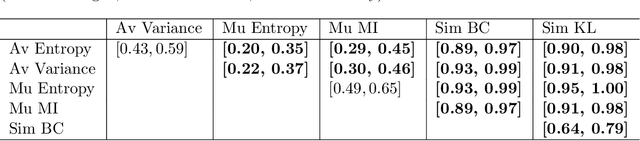
Uncertainty assessment has gained rapid interest in medical image analysis. A popular technique to compute epistemic uncertainty is the Monte-Carlo (MC) dropout technique. From a network with MC dropout and a single input, multiple outputs can be sampled. Various methods can be used to obtain epistemic uncertainty maps from those multiple outputs. In the case of multi-class segmentation, the number of methods is even larger as epistemic uncertainty can be computed voxelwise per class or voxelwise per image. This paper highlights a systematic approach to define and quantitatively compare those methods in two different contexts: class-specific epistemic uncertainty maps (one value per image, voxel and class) and combined epistemic uncertainty maps (one value per image and voxel). We applied this quantitative analysis to a multi-class segmentation of the carotid artery lumen and vessel wall, on a multi-center, multi-scanner, multi-sequence dataset of (MR) images. We validated our analysis over 144 sets of hyperparameters of a model. Our main analysis considers the relationship between the order of the voxels sorted according to their epistemic uncertainty values and the misclassification of the prediction. Under this consideration, the comparison of combined uncertainty maps reveals that the multi-class entropy and the multi-class mutual information statistically out-perform the other combined uncertainty maps under study. In a class-specific scenario, the one-versus-all entropy statistically out-performs the class-wise entropy, the class-wise variance and the one versus all mutual information. The class-wise entropy statistically out-performs the other class-specific uncertainty maps in terms of calibration. We made a python package available to reproduce our analysis on different data and tasks.
Tight and Robust Private Mean Estimation with Few Users
Oct 22, 2021


In this work, we study high-dimensional mean estimation under user-level differential privacy, and attempt to design an $(\epsilon,\delta)$-differentially private mechanism using as few users as possible. In particular, we provide a nearly optimal trade-off between the number of users and the number of samples per user required for private mean estimation, even when the number of users is as low as $O(\frac{1}{\epsilon}\log\frac{1}{\delta})$. Interestingly our bound $O(\frac{1}{\epsilon}\log\frac{1}{\delta})$ on the number of users is independent of the dimension, unlike the previous work that depends polynomially on the dimension, solving a problem left open by Amin et al.~(ICML'2019). Our mechanism enjoys robustness up to the point that even if the information of $49\%$ of the users are corrupted, our final estimation is still approximately accurate. Finally, our results also apply to a broader range of problems such as learning discrete distributions, stochastic convex optimization, empirical risk minimization, and a variant of stochastic gradient descent via a reduction to differentially private mean estimation.
TADRN: Triple-Attentive Dual-Recurrent Network for Ad-hoc Array Multichannel Speech Enhancement
Oct 22, 2021


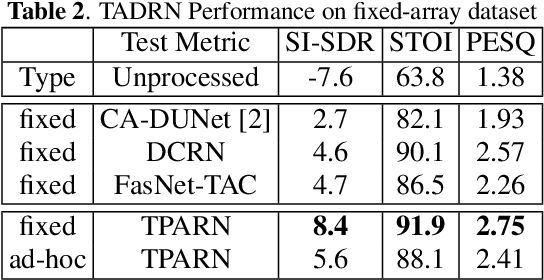
Deep neural networks (DNNs) have been successfully used for multichannel speech enhancement in fixed array geometries. However, challenges remain for ad-hoc arrays with unknown microphone placements. We propose a deep neural network based approach for ad-hoc array processing: Triple-Attentive Dual-Recurrent Network (TADRN). TADRN uses self-attention across channels for learning spatial information and a dual-path attentive recurrent network (ARN) for temporal modeling. Temporal modeling is done independently for all channels by dividing a signal into smaller chunks and using an intra-chunk ARN for local modeling and an inter-chunk ARN for global modeling. Consequently, TADRN uses triple-path attention: inter-channel, intra-chunk, and inter-chunk, and dual-path recurrence: intra-chunk and inter-chunk. Experimental results show excellent performance of TADRN. We demonstrate that TADRN improves speech enhancement by leveraging additional randomly placed microphones, even at locations far from the target source. Additionally, large improvements in objective scores are observed when poorly placed microphones in the scene are complemented with more effective microphone positions, such as those closer to a target source.
Introspective Robot Perception using Smoothed Predictions from Bayesian Neural Networks
Sep 27, 2021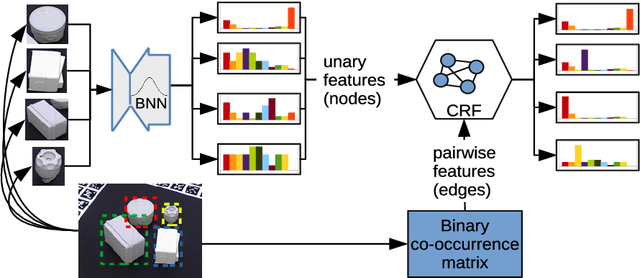
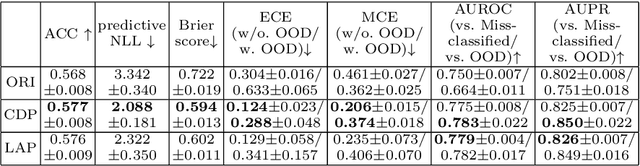
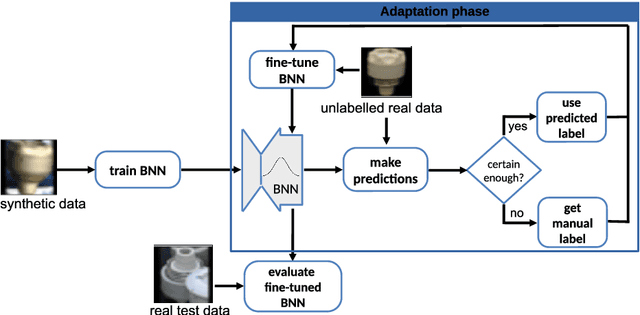
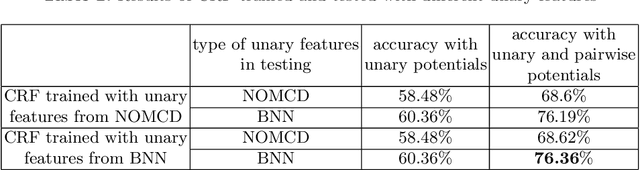
This work focuses on improving uncertainty estimation in the field of object classification from RGB images and demonstrates its benefits in two robotic applications. We employ a (BNN), and evaluate two practical inference techniques to obtain better uncertainty estimates, namely Concrete Dropout (CDP) and Kronecker-factored Laplace Approximation (LAP). We show a performance increase using more reliable uncertainty estimates as unary potentials within a Conditional Random Field (CRF), which is able to incorporate contextual information as well. Furthermore, the obtained uncertainties are exploited to achieve domain adaptation in a semi-supervised manner, which requires less manual efforts in annotating data. We evaluate our approach on two public benchmark datasets that are relevant for robot perception tasks.
Arbitrary Virtual Try-On Network: Characteristics Preservation and Trade-off between Body and Clothing
Nov 24, 2021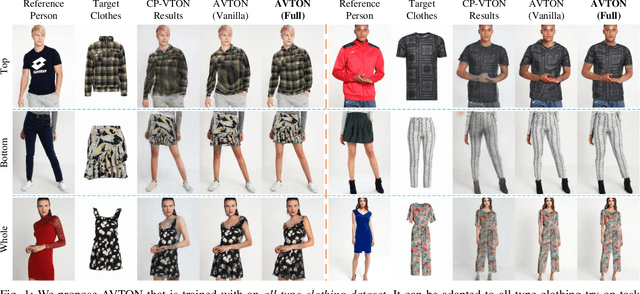
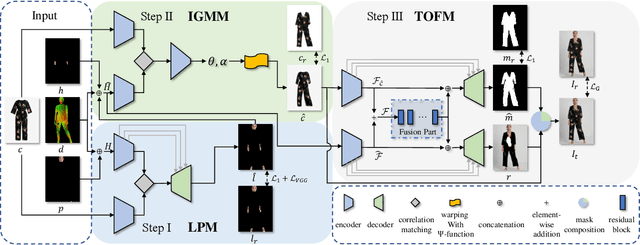


Deep learning based virtual try-on system has achieved some encouraging progress recently, but there still remain several big challenges that need to be solved, such as trying on arbitrary clothes of all types, trying on the clothes from one category to another and generating image-realistic results with few artifacts. To handle this issue, we in this paper first collect a new dataset with all types of clothes, \ie tops, bottoms, and whole clothes, each one has multiple categories with rich information of clothing characteristics such as patterns, logos, and other details. Based on this dataset, we then propose the Arbitrary Virtual Try-On Network (AVTON) that is utilized for all-type clothes, which can synthesize realistic try-on images by preserving and trading off characteristics of the target clothes and the reference person. Our approach includes three modules: 1) Limbs Prediction Module, which is utilized for predicting the human body parts by preserving the characteristics of the reference person. This is especially good for handling cross-category try-on task (\eg long sleeves \(\leftrightarrow\) short sleeves or long pants \(\leftrightarrow\) skirts, \etc), where the exposed arms or legs with the skin colors and details can be reasonably predicted; 2) Improved Geometric Matching Module, which is designed to warp clothes according to the geometry of the target person. We improve the TPS based warping method with a compactly supported radial function (Wendland's \(\Psi\)-function); 3) Trade-Off Fusion Module, which is to trade off the characteristics of the warped clothes and the reference person. This module is to make the generated try-on images look more natural and realistic based on a fine-tune symmetry of the network structure. Extensive simulations are conducted and our approach can achieve better performance compared with the state-of-the-art virtual try-on methods.
De-rendering Stylized Texts
Oct 05, 2021
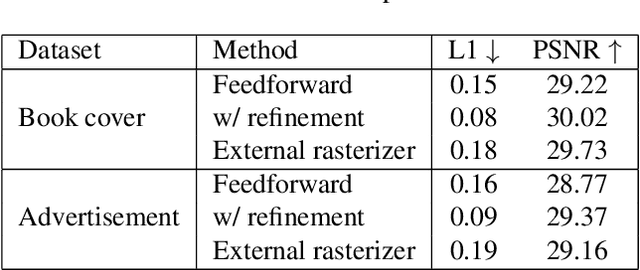
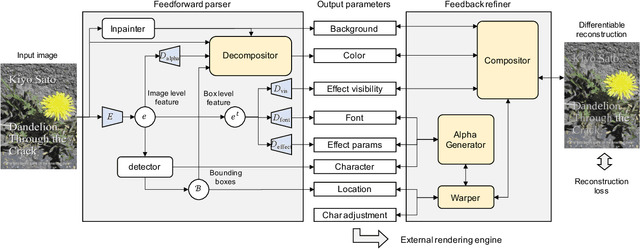
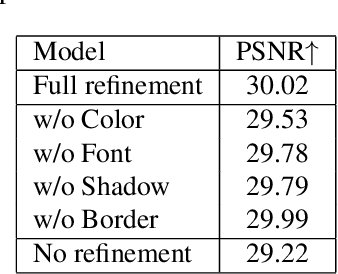
Editing raster text is a promising but challenging task. We propose to apply text vectorization for the task of raster text editing in display media, such as posters, web pages, or advertisements. In our approach, instead of applying image transformation or generation in the raster domain, we learn a text vectorization model to parse all the rendering parameters including text, location, size, font, style, effects, and hidden background, then utilize those parameters for reconstruction and any editing task. Our text vectorization takes advantage of differentiable text rendering to accurately reproduce the input raster text in a resolution-free parametric format. We show in the experiments that our approach can successfully parse text, styling, and background information in the unified model, and produces artifact-free text editing compared to a raster baseline.
Semantic Communications for Speech Recognition
Jul 22, 2021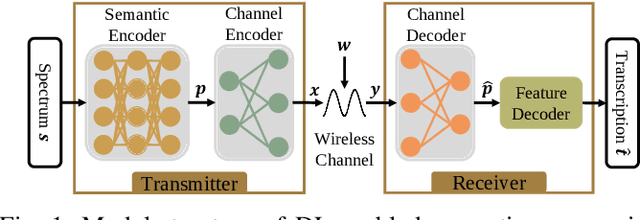
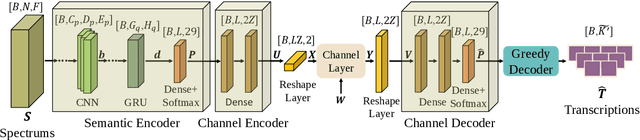
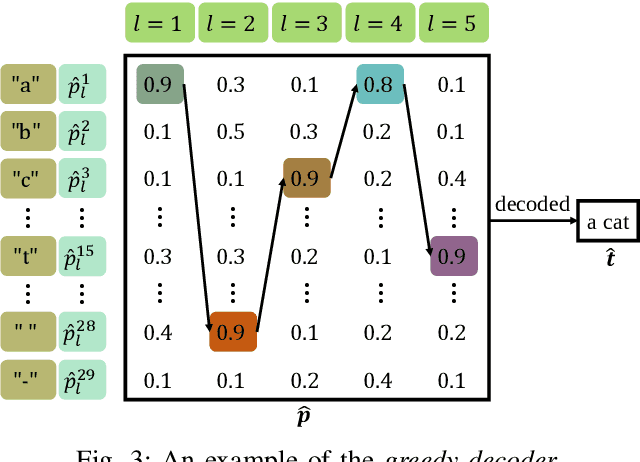
The traditional communications transmit all the source date represented by bits, regardless of the content of source and the semantic information required by the receiver. However, in some applications, the receiver only needs part of the source data that represents critical semantic information, which prompts to transmit the application-related information, especially when bandwidth resources are limited. In this paper, we consider a semantic communication system for speech recognition by designing the transceiver as an end-to-end (E2E) system. Particularly, a deep learning (DL)-enabled semantic communication system, named DeepSC-SR, is developed to learn and extract text-related semantic features at the transmitter, which motivates the system to transmit much less than the source speech data without performance degradation. Moreover, in order to facilitate the proposed DeepSC-SR for dynamic channel environments, we investigate a robust model to cope with various channel environments without requiring retraining. The simulation results demonstrate that our proposed DeepSC-SR outperforms the traditional communication systems in terms of the speech recognition metrics, such as character-error-rate and word-error-rate, and is more robust to channel variations, especially in the low signal-to-noise (SNR) regime.
Multi-Modal Pre-Training for Automated Speech Recognition
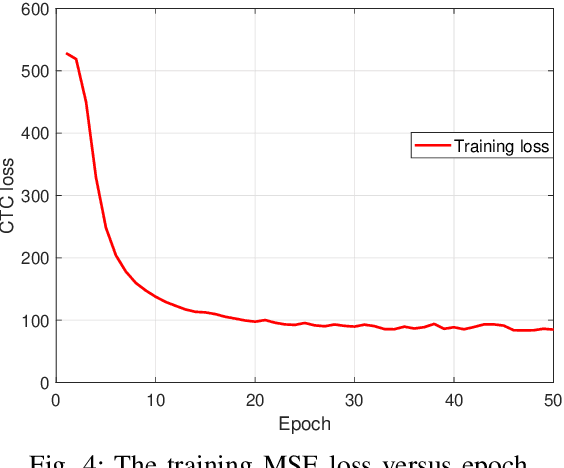
Oct 12, 2021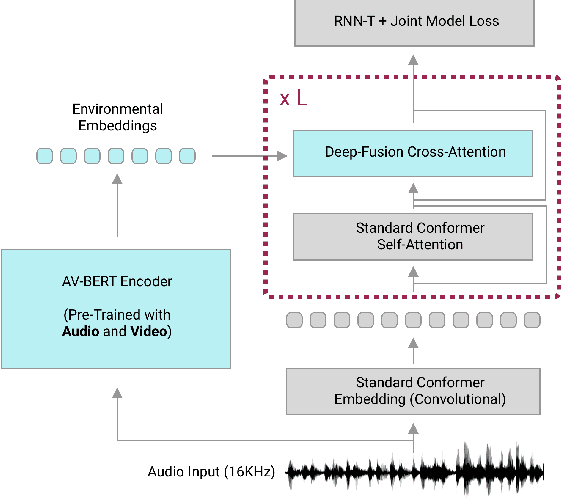
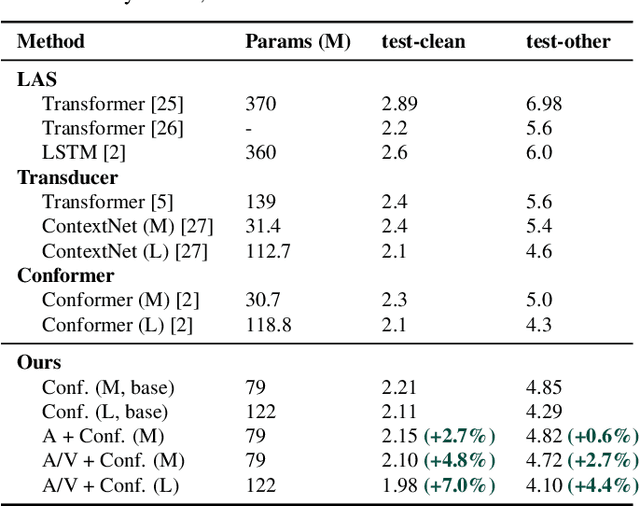
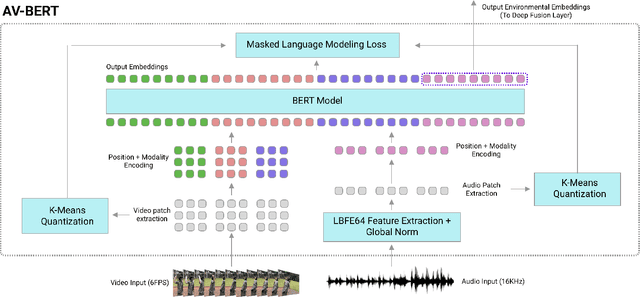
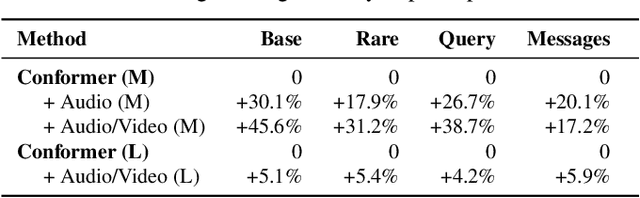
Traditionally, research in automated speech recognition has focused on local-first encoding of audio representations to predict the spoken phonemes in an utterance. Unfortunately, approaches relying on such hyper-local information tend to be vulnerable to both local-level corruption (such as audio-frame drops, or loud noises) and global-level noise (such as environmental noise, or background noise) that has not been seen during training. In this work, we introduce a novel approach which leverages a self-supervised learning technique based on masked language modeling to compute a global, multi-modal encoding of the environment in which the utterance occurs. We then use a new deep-fusion framework to integrate this global context into a traditional ASR method, and demonstrate that the resulting method can outperform baseline methods by up to 7% on Librispeech; gains on internal datasets range from 6% (on larger models) to 45% (on smaller models).