 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Illumination and Temperature-Aware Multispectral Networks for Edge-Computing-Enabled Pedestrian Detection
Dec 09, 2021
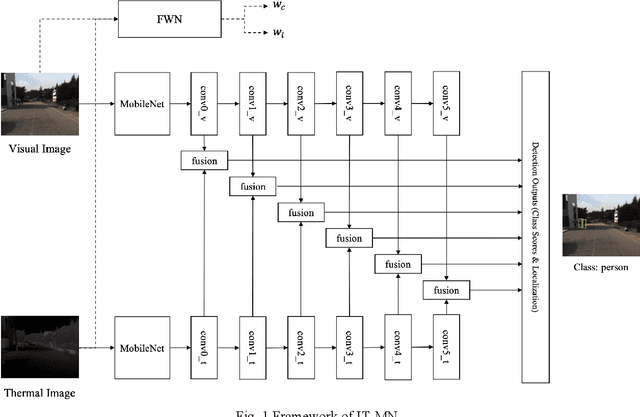
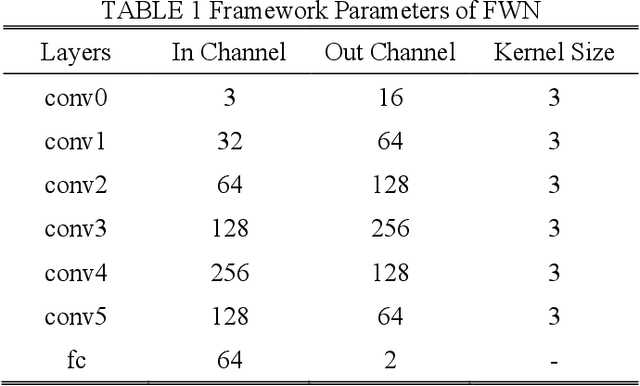
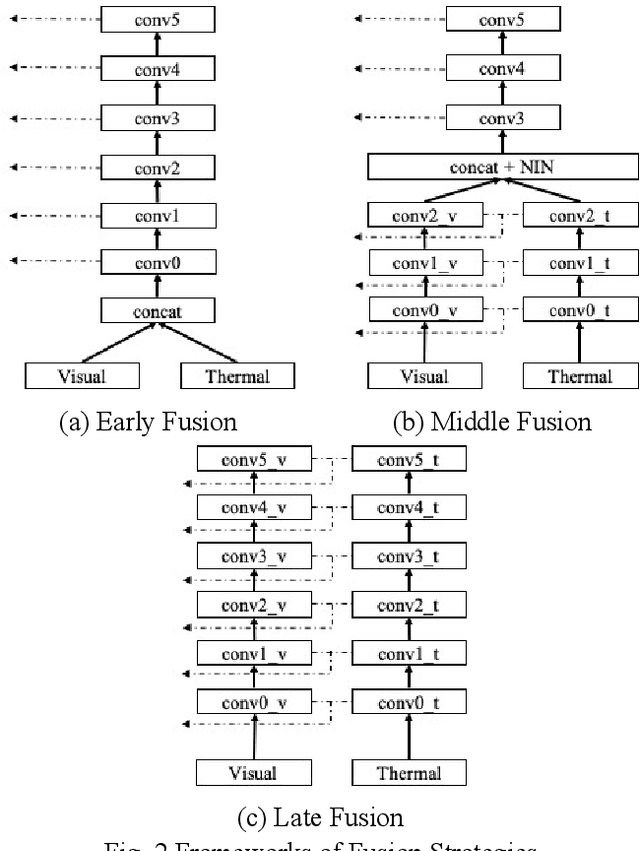
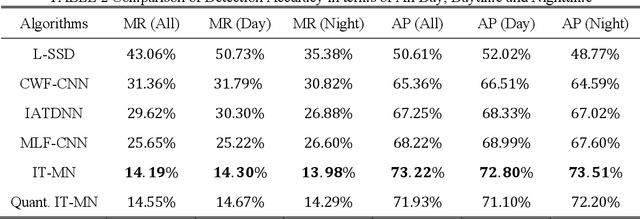
Accurate and efficient pedestrian detection is crucial for the intelligent transportation system regarding pedestrian safety and mobility, e.g., Advanced Driver Assistance Systems, and smart pedestrian crosswalk systems. Among all pedestrian detection methods, vision-based detection method is demonstrated to be the most effective in previous studies. However, the existing vision-based pedestrian detection algorithms still have two limitations that restrict their implementations, those being real-time performance as well as the resistance to the impacts of environmental factors, e.g., low illumination conditions. To address these issues, this study proposes a lightweight Illumination and Temperature-aware Multispectral Network (IT-MN) for accurate and efficient pedestrian detection. The proposed IT-MN is an efficient one-stage detector. For accommodating the impacts of environmental factors and enhancing the sensing accuracy, thermal image data is fused by the proposed IT-MN with visual images to enrich useful information when visual image quality is limited. In addition, an innovative and effective late fusion strategy is also developed to optimize the image fusion performance. To make the proposed model implementable for edge computing, the model quantization is applied to reduce the model size by 75% while shortening the inference time significantly. The proposed algorithm is evaluated by comparing with the selected state-of-the-art algorithms using a public dataset collected by in-vehicle cameras. The results show that the proposed algorithm achieves a low miss rate and inference time at 14.19% and 0.03 seconds per image pair on GPU. Besides, the quantized IT-MN achieves an inference time of 0.21 seconds per image pair on the edge device, which also demonstrates the potentiality of deploying the proposed model on edge devices as a highly efficient pedestrian detection algorithm.
Emulation of physical processes with Emukit
Oct 25, 2021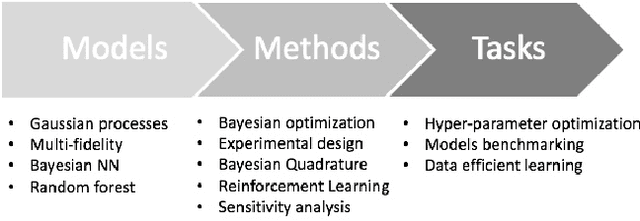
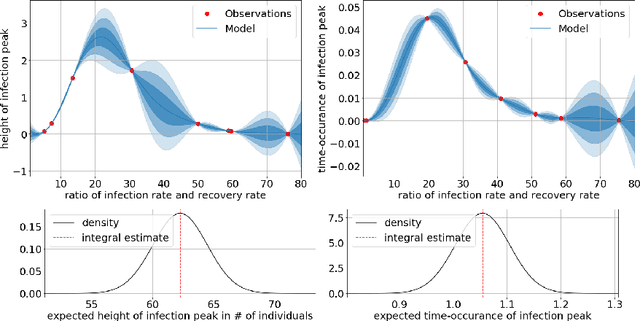
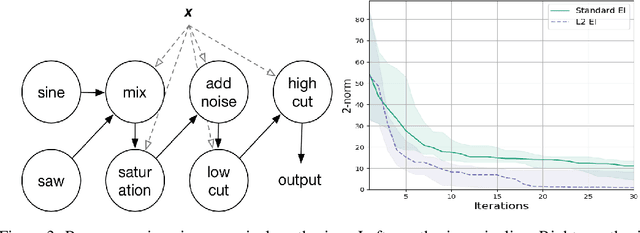
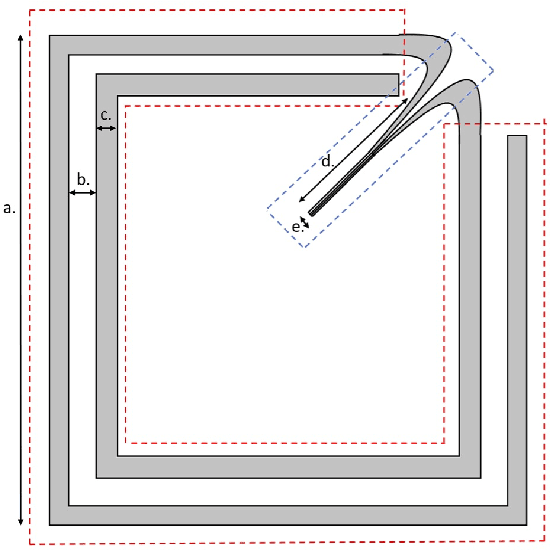
Decision making in uncertain scenarios is an ubiquitous challenge in real world systems. Tools to deal with this challenge include simulations to gather information and statistical emulation to quantify uncertainty. The machine learning community has developed a number of methods to facilitate decision making, but so far they are scattered in multiple different toolkits, and generally rely on a fixed backend. In this paper, we present Emukit, a highly adaptable Python toolkit for enriching decision making under uncertainty. Emukit allows users to: (i) use state of the art methods including Bayesian optimization, multi-fidelity emulation, experimental design, Bayesian quadrature and sensitivity analysis; (ii) easily prototype new decision making methods for new problems. Emukit is agnostic to the underlying modeling framework and enables users to use their own custom models. We show how Emukit can be used on three exemplary case studies.
Automated volumetric and statistical shape assessment of cam-type morphology of the femoral head-neck region from 3D magnetic resonance images
Dec 06, 2021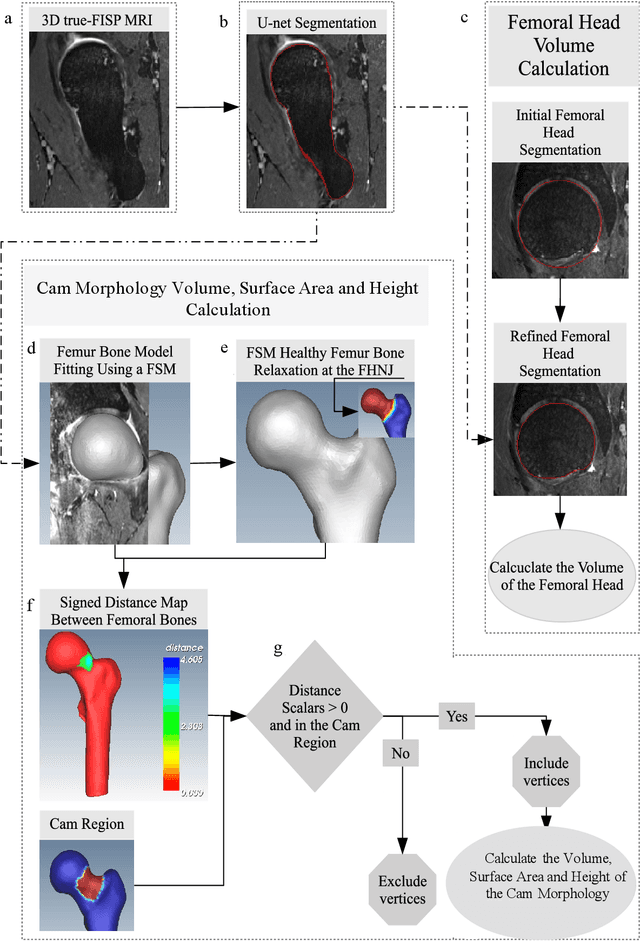
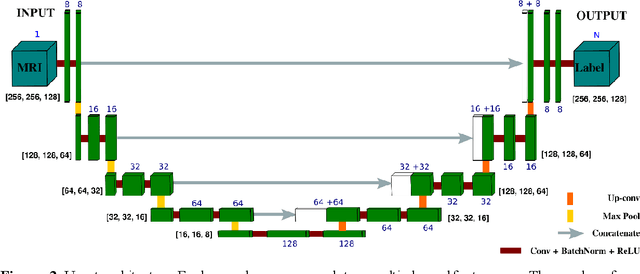

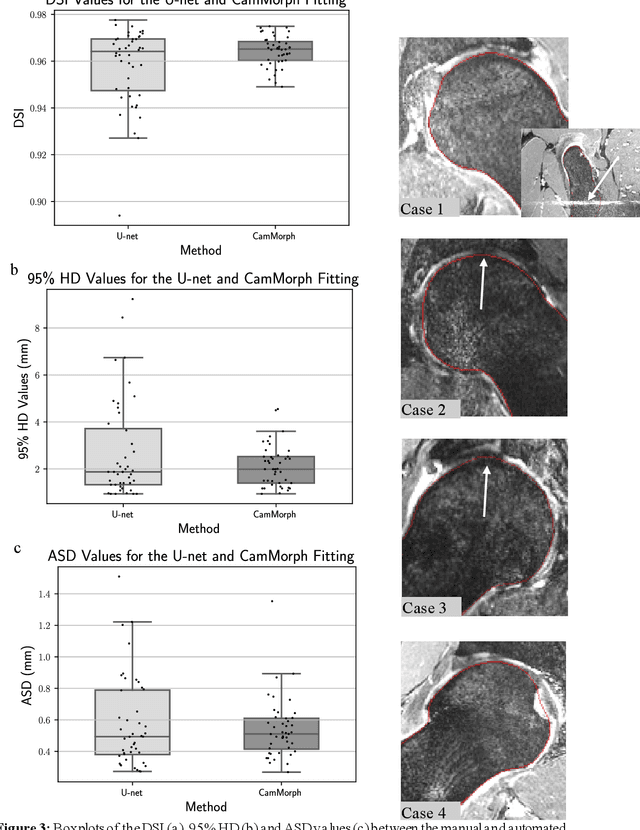
Femoroacetabular impingement (FAI) cam morphology is routinely assessed using two-dimensional alpha angles which do not provide specific data on cam size characteristics. The purpose of this study is to implement a novel, automated three-dimensional (3D) pipeline, CamMorph, for segmentation and measurement of cam volume, surface area and height from magnetic resonance (MR) images in patients with FAI. The CamMorph pipeline involves two processes: i) proximal femur segmentation using an approach integrating 3D U-net with focused shape modelling (FSM); ii) use of patient-specific anatomical information from 3D FSM to simulate healthy femoral bone models and pathological region constraints to identify cam bone mass. Agreement between manual and automated segmentation of the proximal femur was evaluated with the Dice similarity index (DSI) and surface distance measures. Independent t-tests or Mann-Whitney U rank tests were used to compare the femoral head volume, cam volume, surface area and height data between female and male patients with FAI. There was a mean DSI value of 0.964 between manual and automated segmentation of proximal femur volume. Compared to female FAI patients, male patients had a significantly larger mean femoral head volume (66.12cm3 v 46.02cm3, p<0.001). Compared to female FAI patients, male patients had a significantly larger mean cam volume (1136.87mm3 v 337.86mm3, p<0.001), surface area (657.36mm2 v 306.93mm2 , p<0.001), maximum-height (3.89mm v 2.23mm, p<0.001) and average-height (1.94mm v 1.00mm, p<0.001). Automated analyses of 3D MR images from patients with FAI using the CamMorph pipeline showed that, in comparison with female patients, male patients had significantly greater cam volume, surface area and height.
Multitask Adaptation by Retrospective Exploration with Learned World Models
Oct 25, 2021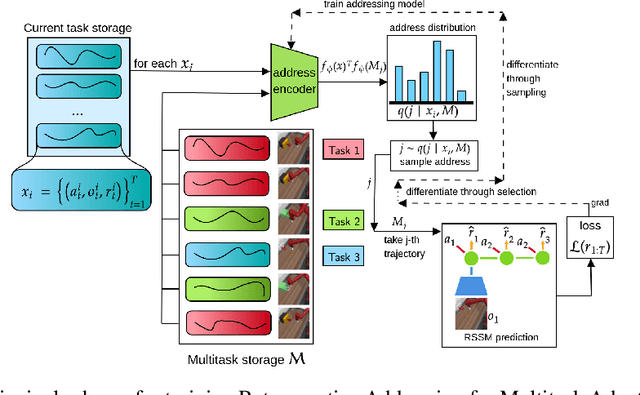
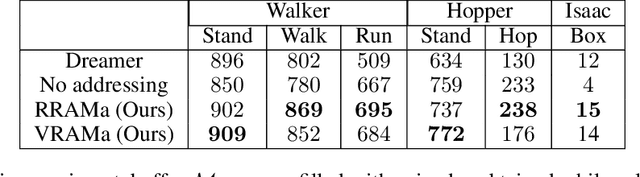


Model-based reinforcement learning (MBRL) allows solving complex tasks in a sample-efficient manner. However, no information is reused between the tasks. In this work, we propose a meta-learned addressing model called RAMa that provides training samples for the MBRL agent taken from continuously growing task-agnostic storage. The model is trained to maximize the expected agent's performance by selecting promising trajectories solving prior tasks from the storage. We show that such retrospective exploration can accelerate the learning process of the MBRL agent by better informing learned dynamics and prompting agent with exploratory trajectories. We test the performance of our approach on several domains from the DeepMind control suite, from Metaworld multitask benchmark, and from our bespoke environment implemented with a robotic NVIDIA Isaac simulator to test the ability of the model to act in a photorealistic, ray-traced environment.
Minimax Optimal Quantile and Semi-Adversarial Regret via Root-Logarithmic Regularizers
Nov 07, 2021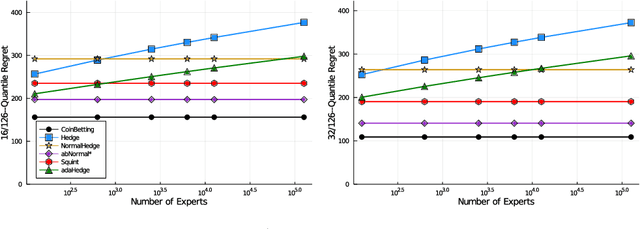
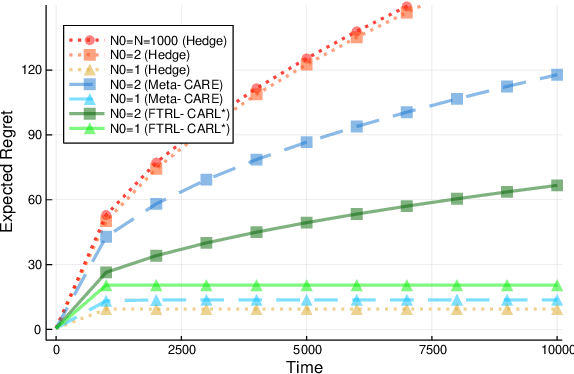
Quantile (and, more generally, KL) regret bounds, such as those achieved by NormalHedge (Chaudhuri, Freund, and Hsu 2009) and its variants, relax the goal of competing against the best individual expert to only competing against a majority of experts on adversarial data. More recently, the semi-adversarial paradigm (Bilodeau, Negrea, and Roy 2020) provides an alternative relaxation of adversarial online learning by considering data that may be neither fully adversarial nor stochastic (i.i.d.). We achieve the minimax optimal regret in both paradigms using FTRL with separate, novel, root-logarithmic regularizers, both of which can be interpreted as yielding variants of NormalHedge. We extend existing KL regret upper bounds, which hold uniformly over target distributions, to possibly uncountable expert classes with arbitrary priors; provide the first full-information lower bounds for quantile regret on finite expert classes (which are tight); and provide an adaptively minimax optimal algorithm for the semi-adversarial paradigm that adapts to the true, unknown constraint faster, leading to uniformly improved regret bounds over existing methods.
* 30 pages, 2 figures. Jeffrey Negrea and Blair Bilodeau are equal-contribution authors. Updated citations
Meta Learning with Relational Information for Short Sequences
Sep 04, 2019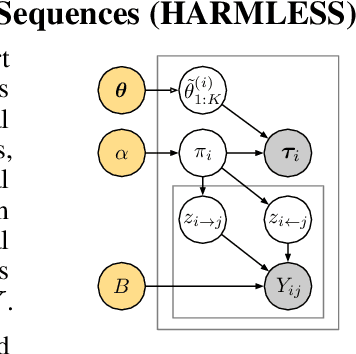
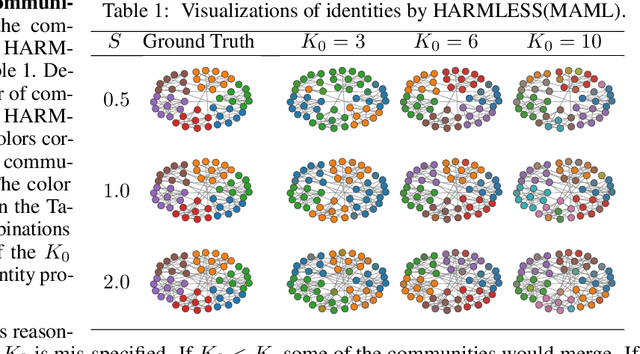
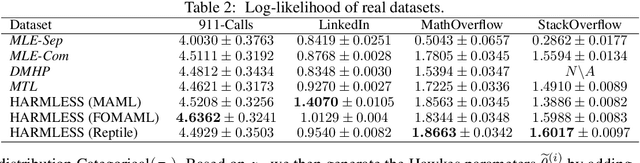
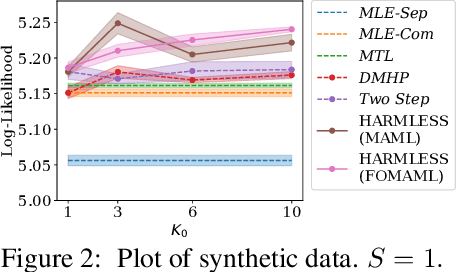
This paper proposes a new meta-learning method -- named HARMLESS (HAwkes Relational Meta LEarning method for Short Sequences) for learning heterogeneous point process models from short event sequence data along with a relational network. Specifically, we propose a hierarchical Bayesian mixture Hawkes process model, which naturally incorporates the relational information among sequences into point process modeling. Compared with existing methods, our model can capture the underlying mixed-community patterns of the relational network, which simultaneously encourages knowledge sharing among sequences and facilitates adaptive learning for each individual sequence. We further propose an efficient stochastic variational meta expectation maximization algorithm that can scale to large problems. Numerical experiments on both synthetic and real data show that HARMLESS outperforms existing methods in terms of predicting the future events.
Context-Aware Online Client Selection for Hierarchical Federated Learning
Dec 02, 2021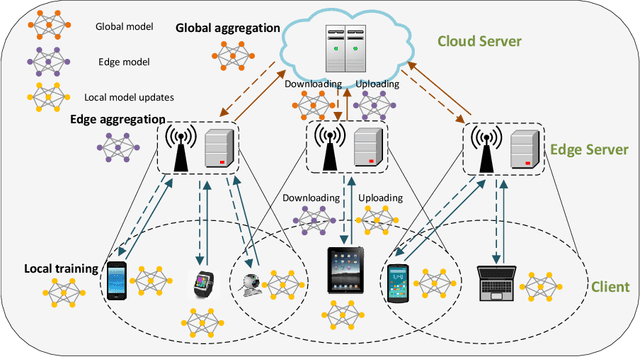
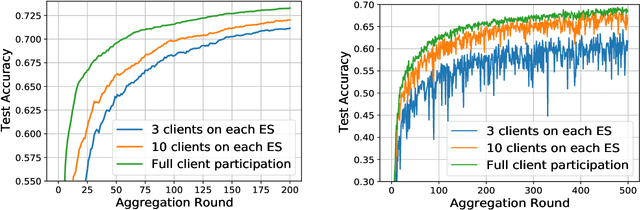
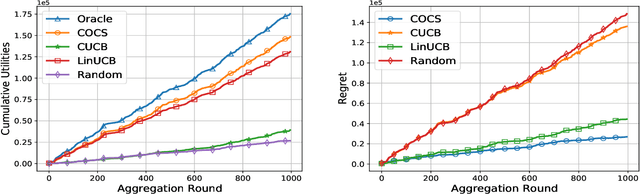
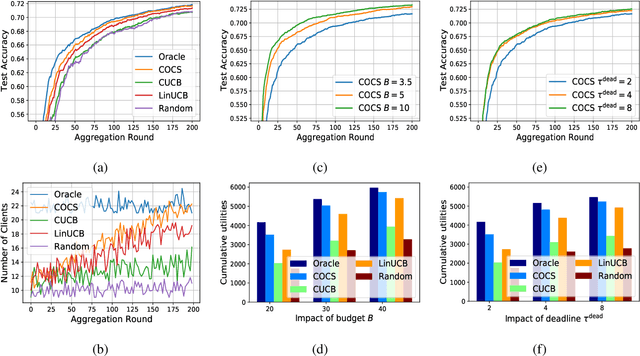
Federated Learning (FL) has been considered as an appealing framework to tackle data privacy issues of mobile devices compared to conventional Machine Learning (ML). Using Edge Servers (ESs) as intermediaries to perform model aggregation in proximity can reduce the transmission overhead, and it enables great potentials in low-latency FL, where the hierarchical architecture of FL (HFL) has been attracted more attention. Designing a proper client selection policy can significantly improve training performance, and it has been extensively used in FL studies. However, to the best of our knowledge, there are no studies focusing on HFL. In addition, client selection for HFL faces more challenges than conventional FL, e.g., the time-varying connection of client-ES pairs and the limited budget of the Network Operator (NO). In this paper, we investigate a client selection problem for HFL, where the NO learns the number of successful participating clients to improve the training performance (i.e., select as many clients in each round) as well as under the limited budget on each ES. An online policy, called Context-aware Online Client Selection (COCS), is developed based on Contextual Combinatorial Multi-Armed Bandit (CC-MAB). COCS observes the side-information (context) of local computing and transmission of client-ES pairs and makes client selection decisions to maximize NO's utility given a limited budget. Theoretically, COCS achieves a sublinear regret compared to an Oracle policy on both strongly convex and non-convex HFL. Simulation results also support the efficiency of the proposed COCS policy on real-world datasets.
Mutual-Information Regularization in Markov Decision Processes and Actor-Critic Learning
Sep 11, 2019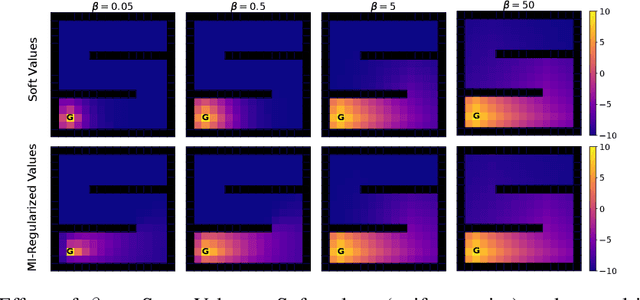
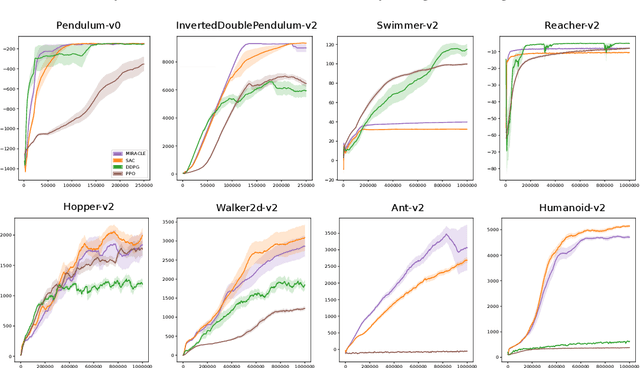
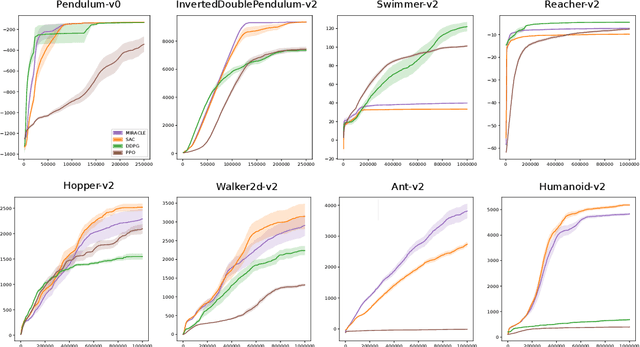
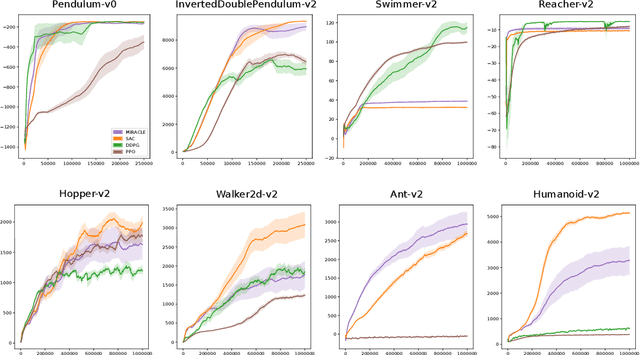
Cumulative entropy regularization introduces a regulatory signal to the reinforcement learning (RL) problem that encourages policies with high-entropy actions, which is equivalent to enforcing small deviations from a uniform reference marginal policy. This has been shown to improve exploration and robustness, and it tackles the value overestimation problem. It also leads to a significant performance increase in tabular and high-dimensional settings, as demonstrated via algorithms such as soft Q-learning (SQL) and soft actor-critic (SAC). Cumulative entropy regularization has been extended to optimize over the reference marginal policy instead of keeping it fixed, yielding a regularization that minimizes the mutual information between states and actions. While this has been initially proposed for Markov Decision Processes (MDPs) in tabular settings, it was recently shown that a similar principle leads to significant improvements over vanilla SQL in RL for high-dimensional domains with discrete actions and function approximators. Here, we follow the motivation of mutual-information regularization from an inference perspective and theoretically analyze the corresponding Bellman operator. Inspired by this Bellman operator, we devise a novel mutual-information regularized actor-critic learning (MIRACLE) algorithm for continuous action spaces that optimizes over the reference marginal policy. We empirically validate MIRACLE in the Mujoco robotics simulator, where we demonstrate that it can compete with contemporary RL methods. Most notably, it can improve over the model-free state-of-the-art SAC algorithm which implicitly assumes a fixed reference policy.
MetaMIML: Meta Multi-Instance Multi-Label Learning
Nov 07, 2021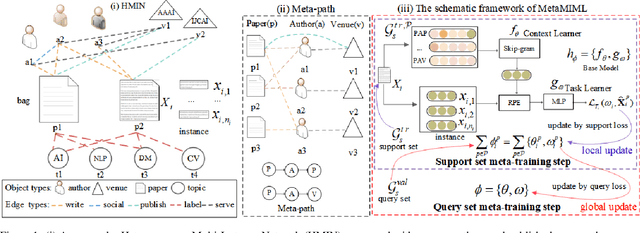
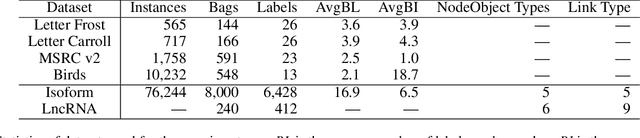
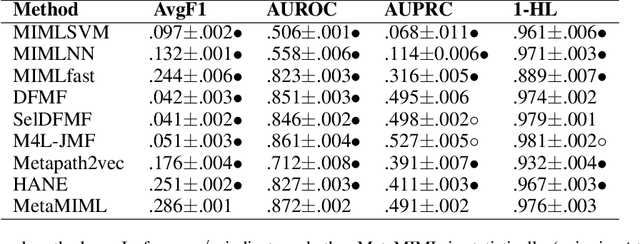
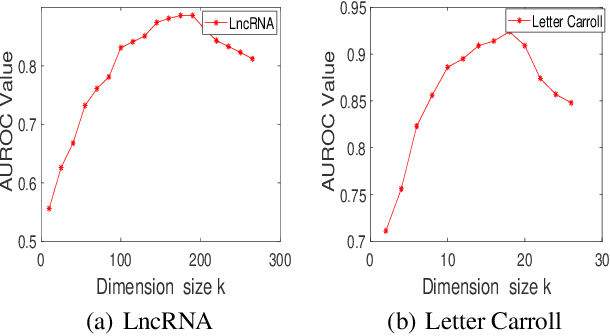
Multi-Instance Multi-Label learning (MIML) models complex objects (bags), each of which is associated with a set of interrelated labels and composed with a set of instances. Current MIML solutions still focus on a single-type of objects and assumes an IID distribution of training data. But these objects are linked with objects of other types, %(i.e., pictures in Facebook link with various users), which also encode the semantics of target objects. In addition, they generally need abundant labeled data for training. To effectively mine interdependent MIML objects of different types, we propose a network embedding and meta learning based approach (MetaMIML). MetaMIML introduces the context learner with network embedding to capture semantic information of objects of different types, and the task learner to extract the meta knowledge for fast adapting to new tasks. In this way, MetaMIML can naturally deal with MIML objects at data level improving, but also exploit the power of meta-learning at the model enhancing. Experiments on benchmark datasets demonstrate that MetaMIML achieves a significantly better performance than state-of-the-art algorithms.
Robbing the Fed: Directly Obtaining Private Data in Federated Learning with Modified Models
Oct 25, 2021
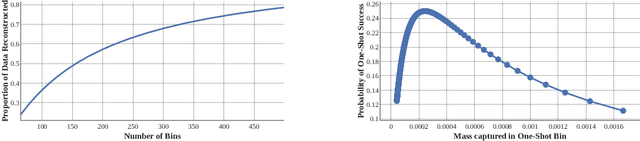


Federated learning has quickly gained popularity with its promises of increased user privacy and efficiency. Previous works have shown that federated gradient updates contain information that can be used to approximately recover user data in some situations. These previous attacks on user privacy have been limited in scope and do not scale to gradient updates aggregated over even a handful of data points, leaving some to conclude that data privacy is still intact for realistic training regimes. In this work, we introduce a new threat model based on minimal but malicious modifications of the shared model architecture which enable the server to directly obtain a verbatim copy of user data from gradient updates without solving difficult inverse problems. Even user data aggregated over large batches -- where previous methods fail to extract meaningful content -- can be reconstructed by these minimally modified models.