 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecepticons: Corrupted Transformers Breach Privacy in Federated Learning for Language Models
Jan 29, 2022



A central tenet of Federated learning (FL), which trains models without centralizing user data, is privacy. However, previous work has shown that the gradient updates used in FL can leak user information. While the most industrial uses of FL are for text applications (e.g. keystroke prediction), nearly all attacks on FL privacy have focused on simple image classifiers. We propose a novel attack that reveals private user text by deploying malicious parameter vectors, and which succeeds even with mini-batches, multiple users, and long sequences. Unlike previous attacks on FL, the attack exploits characteristics of both the Transformer architecture and the token embedding, separately extracting tokens and positional embeddings to retrieve high-fidelity text. This work suggests that FL on text, which has historically been resistant to privacy attacks, is far more vulnerable than previously thought.
Robbing the Fed: Directly Obtaining Private Data in Federated Learning with Modified Models
Oct 25, 2021
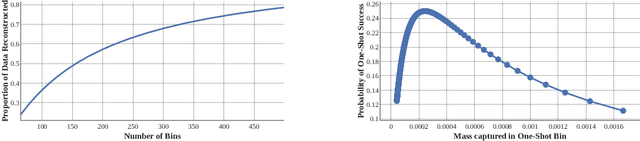


Federated learning has quickly gained popularity with its promises of increased user privacy and efficiency. Previous works have shown that federated gradient updates contain information that can be used to approximately recover user data in some situations. These previous attacks on user privacy have been limited in scope and do not scale to gradient updates aggregated over even a handful of data points, leaving some to conclude that data privacy is still intact for realistic training regimes. In this work, we introduce a new threat model based on minimal but malicious modifications of the shared model architecture which enable the server to directly obtain a verbatim copy of user data from gradient updates without solving difficult inverse problems. Even user data aggregated over large batches -- where previous methods fail to extract meaningful content -- can be reconstructed by these minimally modified models.
Adversarial Examples Make Strong Poisons
Jun 21, 2021

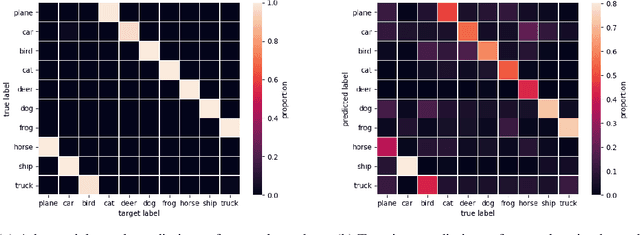

The adversarial machine learning literature is largely partitioned into evasion attacks on testing data and poisoning attacks on training data. In this work, we show that adversarial examples, originally intended for attacking pre-trained models, are even more effective for data poisoning than recent methods designed specifically for poisoning. Our findings indicate that adversarial examples, when assigned the original label of their natural base image, cannot be used to train a classifier for natural images. Furthermore, when adversarial examples are assigned their adversarial class label, they are useful for training. This suggests that adversarial examples contain useful semantic content, just with the ``wrong'' labels (according to a network, but not a human). Our method, adversarial poisoning, is substantially more effective than existing poisoning methods for secure dataset release, and we release a poisoned version of ImageNet, ImageNet-P, to encourage research into the strength of this form of data obfuscation.
Preventing Unauthorized Use of Proprietary Data: Poisoning for Secure Dataset Release
Mar 05, 2021



Large organizations such as social media companies continually release data, for example user images. At the same time, these organizations leverage their massive corpora of released data to train proprietary models that give them an edge over their competitors. These two behaviors can be in conflict as an organization wants to prevent competitors from using their own data to replicate the performance of their proprietary models. We solve this problem by developing a data poisoning method by which publicly released data can be minimally modified to prevent others from train-ing models on it. Moreover, our method can be used in an online fashion so that companies can protect their data in real time as they release it.We demonstrate the success of our approach onImageNet classification and on facial recognition.