 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAT-Net: A Cross-Attention Tone Network for Cross-Subject EEG-EMG Fusion Tone Decoding
Nov 14, 2025Brain-computer interface (BCI) speech decoding has emerged as a promising tool for assisting individuals with speech impairments. In this context, the integration of electroencephalography (EEG) and electromyography (EMG) signals offers strong potential for enhancing decoding performance. Mandarin tone classification presents particular challenges, as tonal variations convey distinct meanings even when phonemes remain identical. In this study, we propose a novel cross-subject multimodal BCI decoding framework that fuses EEG and EMG signals to classify four Mandarin tones under both audible and silent speech conditions. Inspired by the cooperative mechanisms of neural and muscular systems in speech production, our neural decoding architecture combines spatial-temporal feature extraction branches with a cross-attention fusion mechanism, enabling informative interaction between modalities. We further incorporate domain-adversarial training to improve cross-subject generalization. We collected 4,800 EEG trials and 4,800 EMG trials from 10 participants using only twenty EEG and five EMG channels, demonstrating the feasibility of minimal-channel decoding. Despite employing lightweight modules, our model outperforms state-of-the-art baselines across all conditions, achieving average classification accuracies of 87.83% for audible speech and 88.08% for silent speech. In cross-subject evaluations, it still maintains strong performance with accuracies of 83.27% and 85.10% for audible and silent speech, respectively. We further conduct ablation studies to validate the effectiveness of each component. Our findings suggest that tone-level decoding with minimal EEG-EMG channels is feasible and potentially generalizable across subjects, contributing to the development of practical BCI applications.
DeepSORT-Driven Visual Tracking Approach for Gesture Recognition in Interactive Systems
May 11, 2025Based on the DeepSORT algorithm, this study explores the application of visual tracking technology in intelligent human-computer interaction, especially in the field of gesture recognition and tracking. With the rapid development of artificial intelligence and deep learning technology, visual-based interaction has gradually replaced traditional input devices and become an important way for intelligent systems to interact with users. The DeepSORT algorithm can achieve accurate target tracking in dynamic environments by combining Kalman filters and deep learning feature extraction methods. It is especially suitable for complex scenes with multi-target tracking and fast movements. This study experimentally verifies the superior performance of DeepSORT in gesture recognition and tracking. It can accurately capture and track the user's gesture trajectory and is superior to traditional tracking methods in terms of real-time and accuracy. In addition, this study also combines gesture recognition experiments to evaluate the recognition ability and feedback response of the DeepSORT algorithm under different gestures (such as sliding, clicking, and zooming). The experimental results show that DeepSORT can not only effectively deal with target occlusion and motion blur but also can stably track in a multi-target environment, achieving a smooth user interaction experience. Finally, this paper looks forward to the future development direction of intelligent human-computer interaction systems based on visual tracking and proposes future research focuses such as algorithm optimization, data fusion, and multimodal interaction in order to promote a more intelligent and personalized interactive experience. Keywords-DeepSORT, visual tracking, gesture recognition, human-computer interaction
Illumination and Temperature-Aware Multispectral Networks for Edge-Computing-Enabled Pedestrian Detection
Dec 09, 2021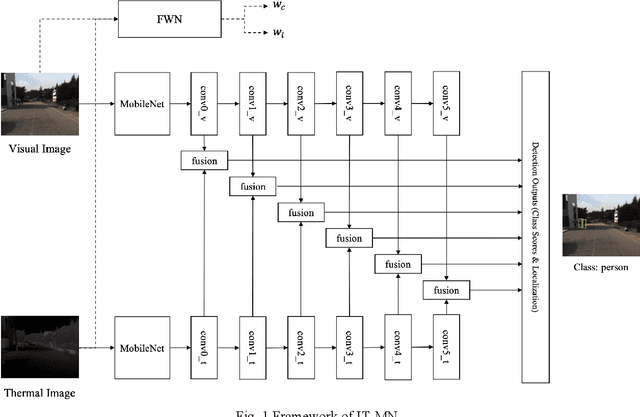
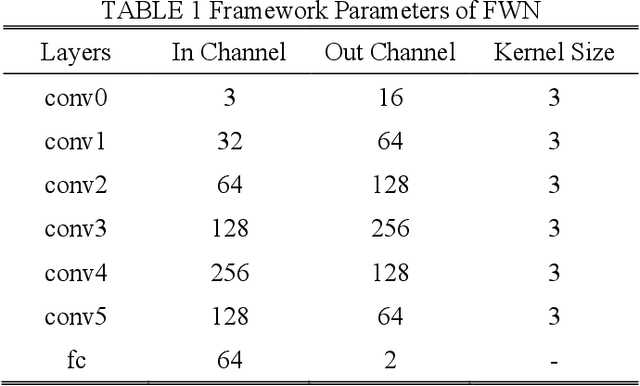
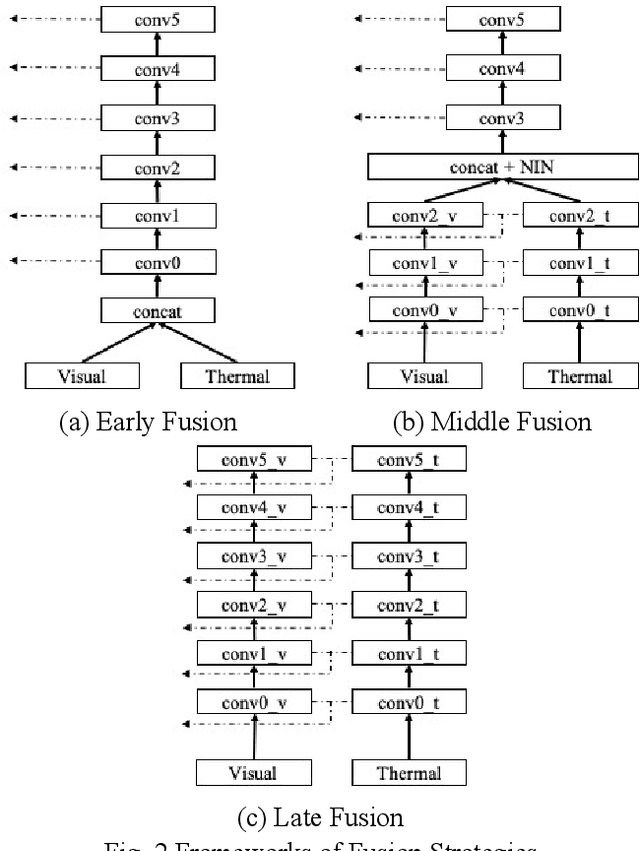
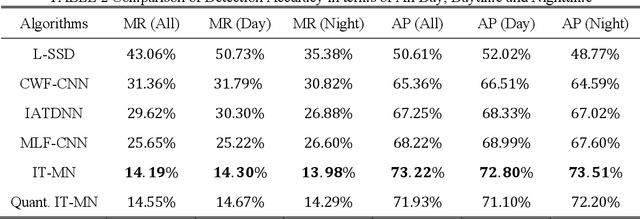
Accurate and efficient pedestrian detection is crucial for the intelligent transportation system regarding pedestrian safety and mobility, e.g., Advanced Driver Assistance Systems, and smart pedestrian crosswalk systems. Among all pedestrian detection methods, vision-based detection method is demonstrated to be the most effective in previous studies. However, the existing vision-based pedestrian detection algorithms still have two limitations that restrict their implementations, those being real-time performance as well as the resistance to the impacts of environmental factors, e.g., low illumination conditions. To address these issues, this study proposes a lightweight Illumination and Temperature-aware Multispectral Network (IT-MN) for accurate and efficient pedestrian detection. The proposed IT-MN is an efficient one-stage detector. For accommodating the impacts of environmental factors and enhancing the sensing accuracy, thermal image data is fused by the proposed IT-MN with visual images to enrich useful information when visual image quality is limited. In addition, an innovative and effective late fusion strategy is also developed to optimize the image fusion performance. To make the proposed model implementable for edge computing, the model quantization is applied to reduce the model size by 75% while shortening the inference time significantly. The proposed algorithm is evaluated by comparing with the selected state-of-the-art algorithms using a public dataset collected by in-vehicle cameras. The results show that the proposed algorithm achieves a low miss rate and inference time at 14.19% and 0.03 seconds per image pair on GPU. Besides, the quantized IT-MN achieves an inference time of 0.21 seconds per image pair on the edge device, which also demonstrates the potentiality of deploying the proposed model on edge devices as a highly efficient pedestrian detection algorithm.