 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Causal Order Identification to Address Confounding: Binary Variables
Aug 13, 2021
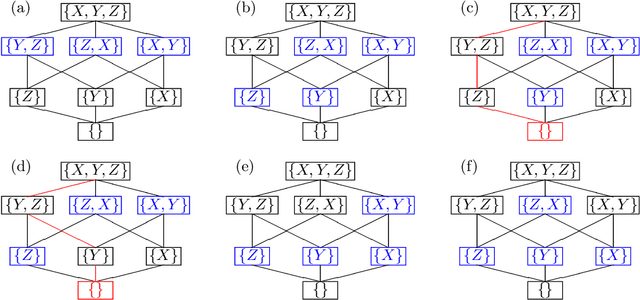

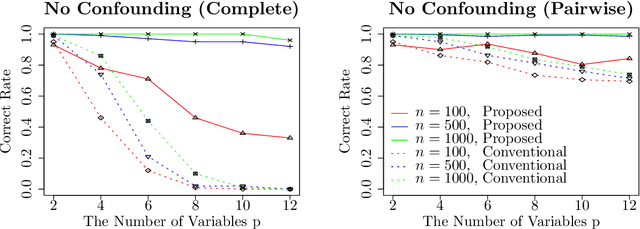
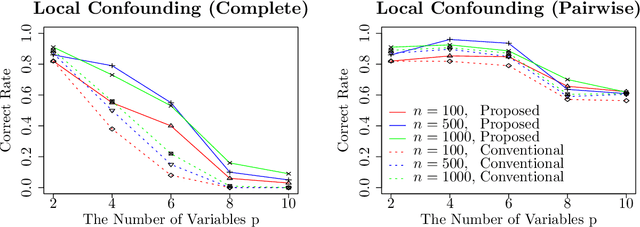
This paper considers an extension of the linear non-Gaussian acyclic model (LiNGAM) that determines the causal order among variables from a dataset when the variables are expressed by a set of linear equations, including noise. In particular, we assume that the variables are binary. The existing LiNGAM assumes that no confounding is present, which is restrictive in practice. Based on the concept of independent component analysis (ICA), this paper proposes an extended framework in which the mutual information among the noises is minimized. Another significant contribution is to reduce the realization of the shortest path problem. The distance between each pair of nodes expresses an associated mutual information value, and the path with the minimum sum (KL divergence) is sought. Although $p!$ mutual information values should be compared, this paper dramatically reduces the computation when no confounding is present. The proposed algorithm finds the globally optimal solution, while the existing locally greedily seek the order based on hypothesis testing. We use the best estimator in the sense of Bayes/MDL that correctly detects independence for mutual information estimation. Experiments using artificial and actual data show that the proposed version of LiNGAM achieves significantly better performance, particularly when confounding is present.
Multi-agent Natural Actor-critic Reinforcement Learning Algorithms
Sep 03, 2021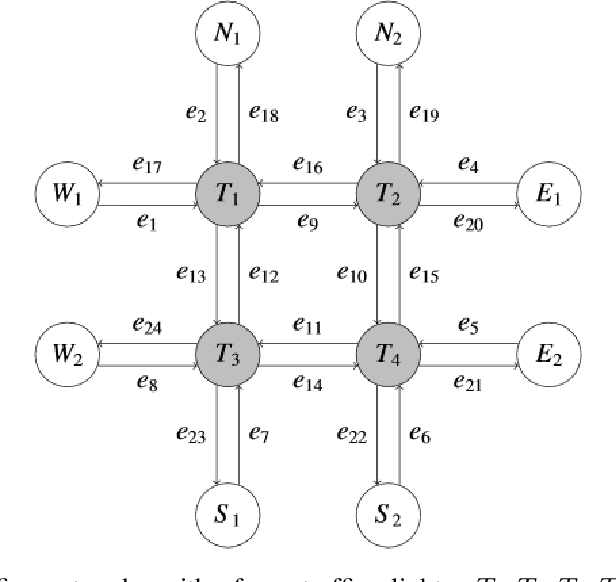
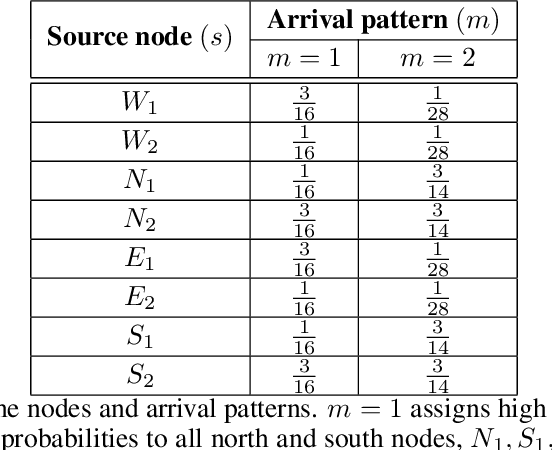
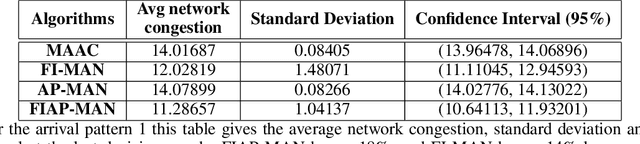
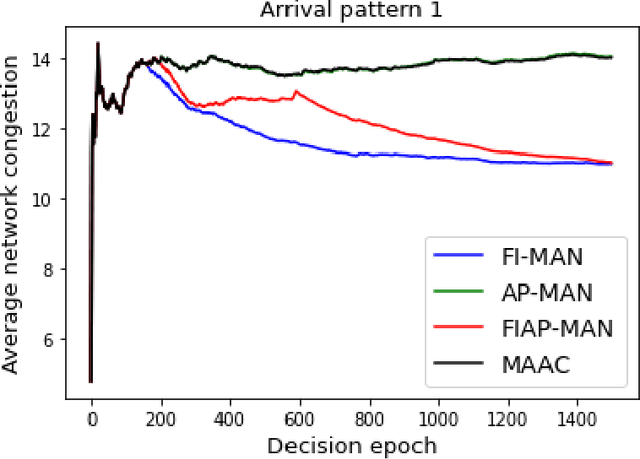
Both single-agent and multi-agent actor-critic algorithms are an important class of Reinforcement Learning algorithms. In this work, we propose three fully decentralized multi-agent natural actor-critic (MAN) algorithms. The agents' objective is to collectively learn a joint policy that maximizes the sum of averaged long-term returns of these agents. In the absence of a central controller, agents communicate the information to their neighbors via a time-varying communication network while preserving privacy. We prove the convergence of all the 3 MAN algorithms to a globally asymptotically stable point of the ODE corresponding to the actor update; these use linear function approximations. We use the Fisher information matrix to obtain the natural gradients. The Fisher information matrix captures the curvature of the Kullback-Leibler (KL) divergence between polices at successive iterates. We also show that the gradient of this KL divergence between policies of successive iterates is proportional to the objective function's gradient. Our MAN algorithms indeed use this \emph{representation} of the objective function's gradient. Under certain conditions on the Fisher information matrix, we prove that at each iterate, the optimal value via MAN algorithms can be better than that of the multi-agent actor-critic (MAAC) algorithm using the standard gradients. To validate the usefulness of our proposed algorithms, we implement all the 3 MAN algorithms on a bi-lane traffic network to reduce the average network congestion. We observe an almost 25% reduction in the average congestion in 2 MAN algorithms; the average congestion in another MAN algorithm is on par with the MAAC algorithm. We also consider a generic 15 agent MARL; the performance of the MAN algorithms is again as good as the MAAC algorithm. We attribute the better performance of the MAN algorithms to their use of the above representation.
Detecting and Tracking Small and Dense Moving Objects in Satellite Videos: A Benchmark
Nov 25, 2021
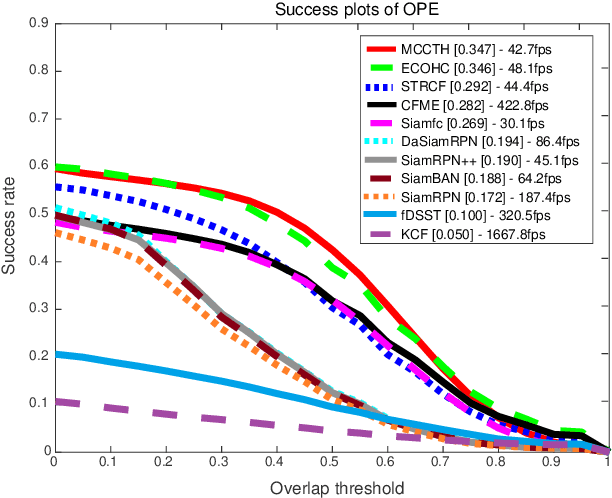

Satellite video cameras can provide continuous observation for a large-scale area, which is important for many remote sensing applications. However, achieving moving object detection and tracking in satellite videos remains challenging due to the insufficient appearance information of objects and lack of high-quality datasets. In this paper, we first build a large-scale satellite video dataset with rich annotations for the task of moving object detection and tracking. This dataset is collected by the Jilin-1 satellite constellation and composed of 47 high-quality videos with 1,646,038 instances of interest for object detection and 3,711 trajectories for object tracking. We then introduce a motion modeling baseline to improve the detection rate and reduce false alarms based on accumulative multi-frame differencing and robust matrix completion. Finally, we establish the first public benchmark for moving object detection and tracking in satellite videos, and extensively evaluate the performance of several representative approaches on our dataset. Comprehensive experimental analyses and insightful conclusions are also provided. The dataset is available at https://github.com/QingyongHu/VISO.
HeMI: Multi-view Embedding in Heterogeneous Graphs
Sep 14, 2021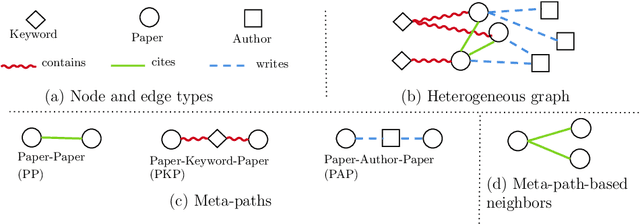
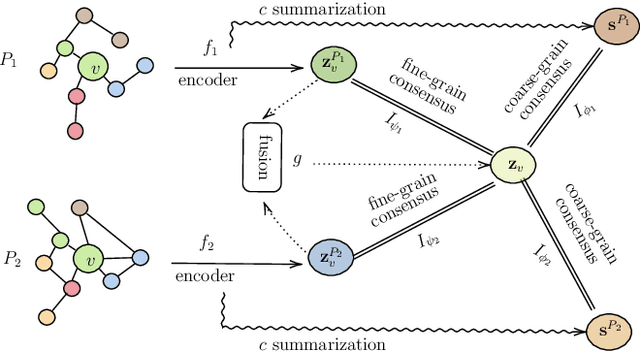
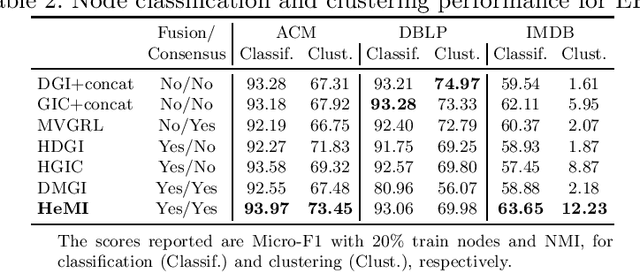
Many real-world graphs involve different types of nodes and relations between nodes, being heterogeneous by nature. The representation learning of heterogeneous graphs (HGs) embeds the rich structure and semantics of such graphs into a low-dimensional space and facilitates various data mining tasks, such as node classification, node clustering, and link prediction. In this paper, we propose a self-supervised method that learns HG representations by relying on knowledge exchange and discovery among different HG structural semantics (meta-paths). Specifically, by maximizing the mutual information of meta-path representations, we promote meta-path information fusion and consensus, and ensure that globally shared semantics are encoded. By extensive experiments on node classification, node clustering, and link prediction tasks, we show that the proposed self-supervision both outperforms and improves competing methods by 1% and up to 10% for all tasks.
Enhanced countering adversarial attacks via input denoising and feature restoring
Nov 19, 2021
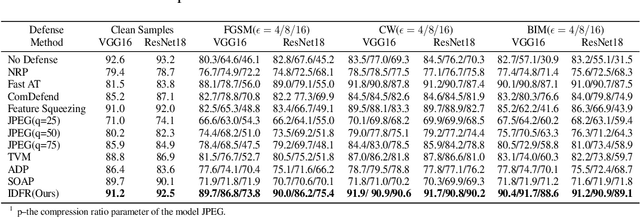
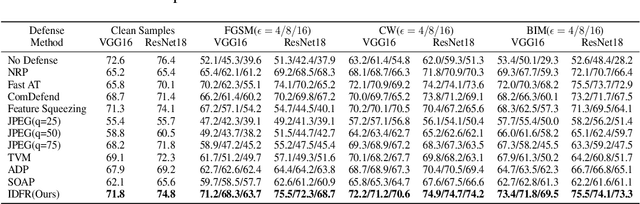
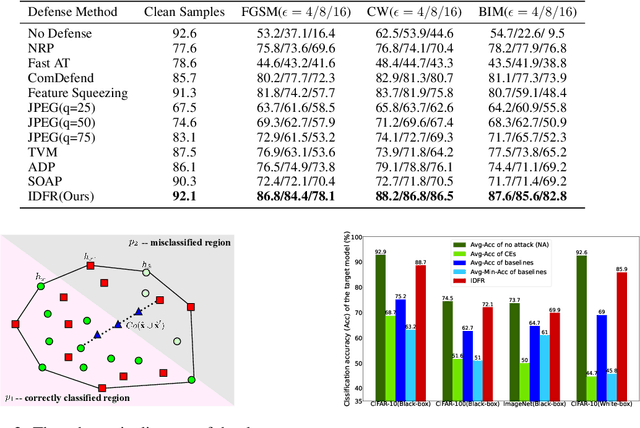
Despite the fact that deep neural networks (DNNs) have achieved prominent performance in various applications, it is well known that DNNs are vulnerable to adversarial examples/samples (AEs) with imperceptible perturbations in clean/original samples. To overcome the weakness of the existing defense methods against adversarial attacks, which damages the information on the original samples, leading to the decrease of the target classifier accuracy, this paper presents an enhanced countering adversarial attack method IDFR (via Input Denoising and Feature Restoring). The proposed IDFR is made up of an enhanced input denoiser (ID) and a hidden lossy feature restorer (FR) based on the convex hull optimization. Extensive experiments conducted on benchmark datasets show that the proposed IDFR outperforms the various state-of-the-art defense methods, and is highly effective for protecting target models against various adversarial black-box or white-box attacks. \footnote{Souce code is released at: \href{https://github.com/ID-FR/IDFR}{https://github.com/ID-FR/IDFR}}
Solving Traffic4Cast Competition with U-Net and Temporal Domain Adaptation
Nov 05, 2021
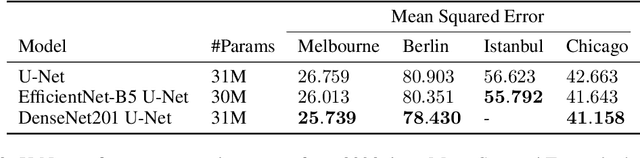


In this technical report, we present our solution to the Traffic4Cast 2021 Core Challenge, in which participants were asked to develop algorithms for predicting a traffic state 60 minutes ahead, based on the information from the previous hour, in 4 different cities. In contrast to the previously held competitions, this year's challenge focuses on the temporal domain shift in traffic due to the COVID-19 pandemic. Following the past success of U-Net, we utilize it for predicting future traffic maps. Additionally, we explore the usage of pre-trained encoders such as DenseNet and EfficientNet and employ multiple domain adaptation techniques to fight the domain shift. Our solution has ranked third in the final competition. The code is available at https://github.com/jbr-ai-labs/traffic4cast-2021.
A Deep Neural Information Fusion Architecture for Textual Network Embeddings
Aug 29, 2019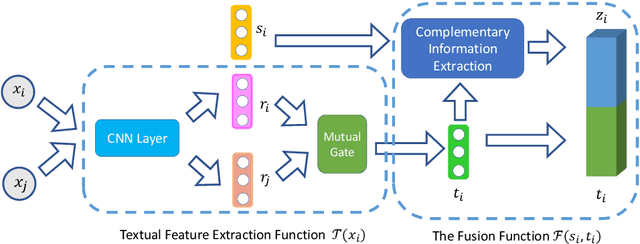
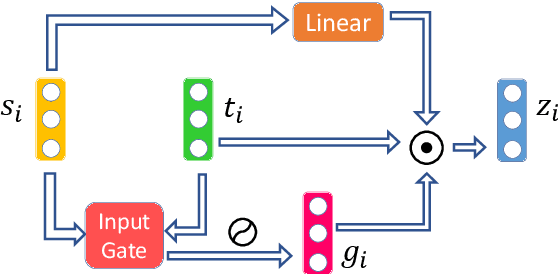
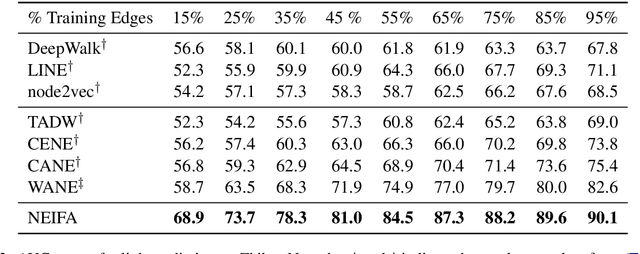
Textual network embeddings aim to learn a low-dimensional representation for every node in the network so that both the structural and textual information from the networks can be well preserved in the representations. Traditionally, the structural and textual embeddings were learned by models that rarely take the mutual influences between them into account. In this paper, a deep neural architecture is proposed to effectively fuse the two kinds of informations into one representation. The novelties of the proposed architecture are manifested in the aspects of a newly defined objective function, the complementary information fusion method for structural and textual features, and the mutual gate mechanism for textual feature extraction. Experimental results show that the proposed model outperforms the comparing methods on all three datasets.
Blameworthiness in Games with Imperfect Information
Nov 16, 2018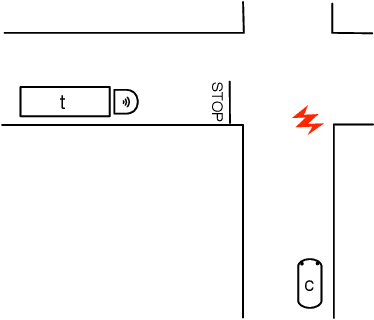
Blameworthiness of an agent or a coalition of agents is often defined in terms of the principle of alternative possibilities: for the coalition to be responsible for an outcome, the outcome must take place and the coalition should have had a strategy to prevent it. In this paper we argue that in the settings with imperfect information, not only should the coalition have had a strategy, but it also should have known that it had a strategy, and it should have known what the strategy was. The main technical result of the paper is a sound and complete bimodal logic that describes the interplay between knowledge and blameworthiness in strategic games with imperfect information.
Dynamic Allocation of Visual Attention for Vision-based Autonomous Navigation under Data Rate Constraints
Sep 27, 2021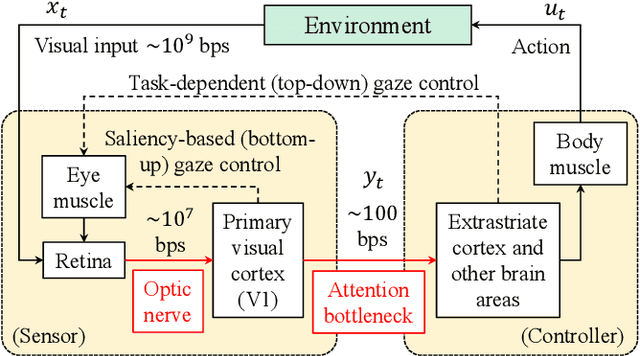

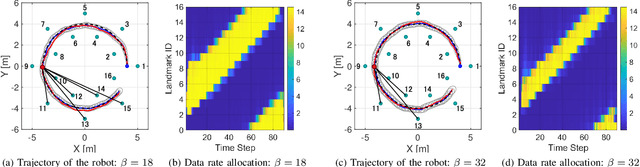
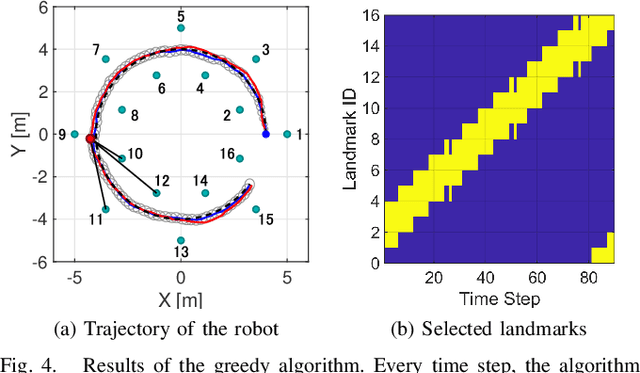
This paper considers the problem of task-dependent (top-down) attention allocation for vision-based autonomous navigation using known landmarks. Unlike the existing paradigm in which landmark selection is formulated as a combinatorial optimization problem, we model it as a resource allocation problem where the decision-maker (DM) is granted extra freedom to control the degree of attention to each landmark. The total resource available to DM is expressed in terms of the capacity limit of the in-take information flow, which is quantified by the directed information from the state of the environment to the DM's observation. We consider a receding horizon implementation of such a controlled sensing scheme in the Linear-Quadratic-Gaussian (LQG) regime. The convex-concave procedure is applied in each time step, whose time complexity is shown to be linear in the horizon length if the alternating direction method of multipliers (ADMM) is used. Numerical studies show that the proposed formulation is sparsity-promoting in the sense that it tends to allocate zero data rate to uninformative landmarks.
A Hybrid Spatial-temporal Deep Learning Architecture for Lane Detection
Oct 14, 2021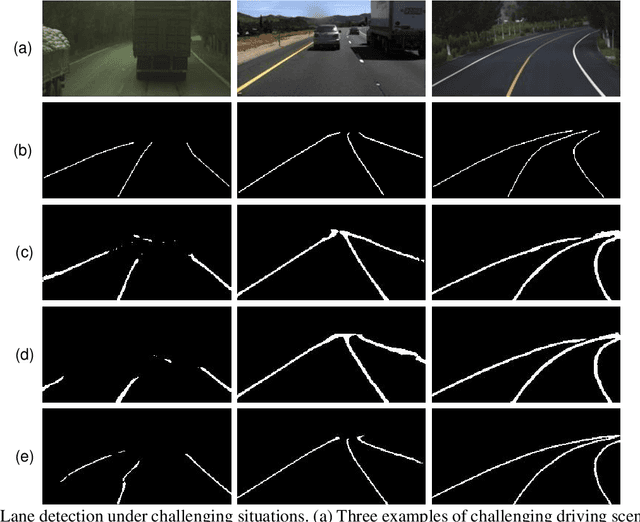
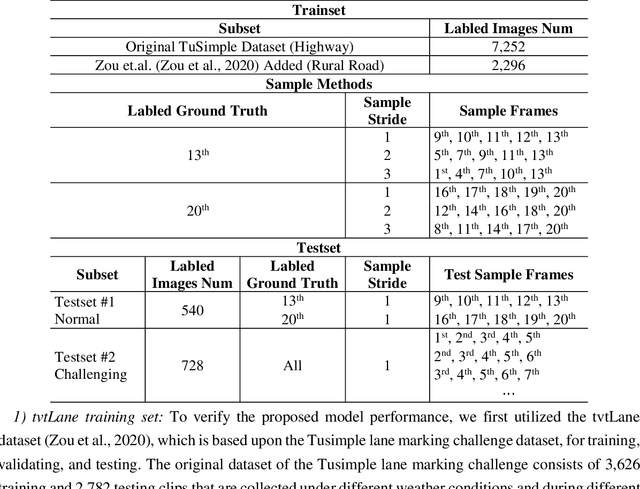
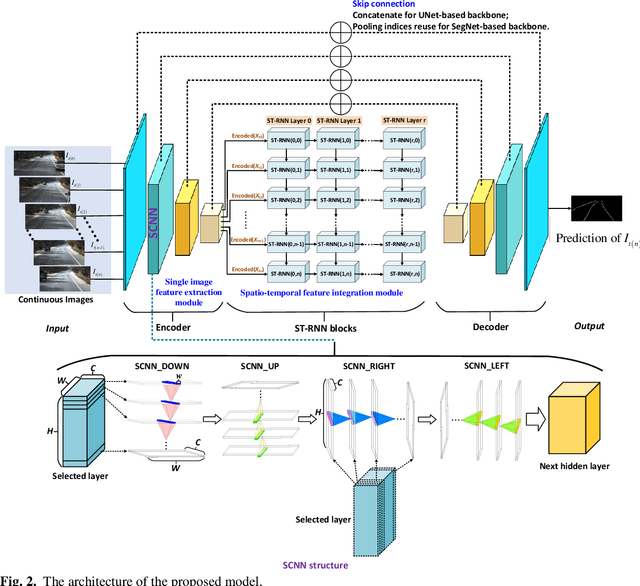
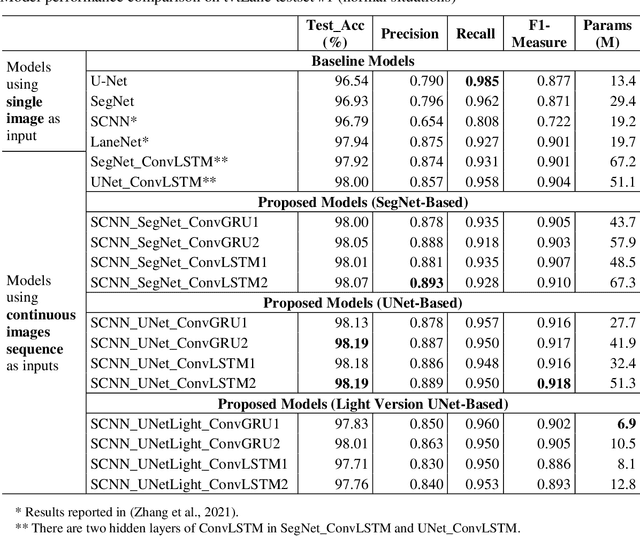
Reliable and accurate lane detection is of vital importance for the safe performance of Lane Keeping Assistance and Lane Departure Warning systems. However, under certain challenging peculiar circumstances, it is difficult to get satisfactory performance in accurately detecting the lanes from one single image which is often the case in current literature. Since lane markings are continuous lines, the lanes that are difficult to be accurately detected in the single current image can potentially be better deduced if information from previous frames is incorporated. This study proposes a novel hybrid spatial-temporal sequence-to-one deep learning architecture making full use of the spatial-temporal information in multiple continuous image frames to detect lane markings in the very last current frame. Specifically, the hybrid model integrates the single image feature extraction module with the spatial convolutional neural network (SCNN) embedded for excavating spatial features and relationships in one single image, the spatial-temporal feature integration module with spatial-temporal recurrent neural network (ST-RNN), which can capture the spatial-temporal correlations and time dependencies among image sequences, and the encoder-decoder structure, which makes this image segmentation problem work in an end-to-end supervised learning format. Extensive experiments reveal that the proposed model can effectively handle challenging driving scenes and outperforms available state-of-the-art methods with a large margin.