 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Neural Information Fusion Architecture for Textual Network Embeddings
Paper and Code
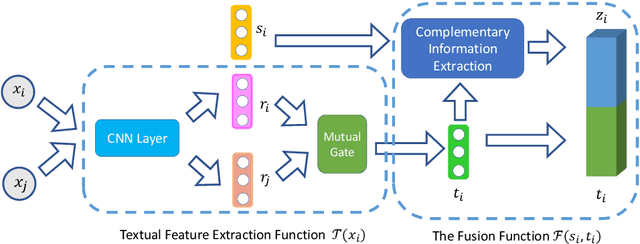
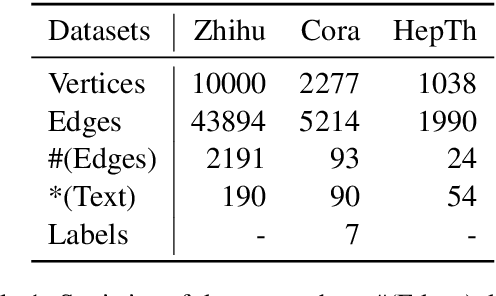
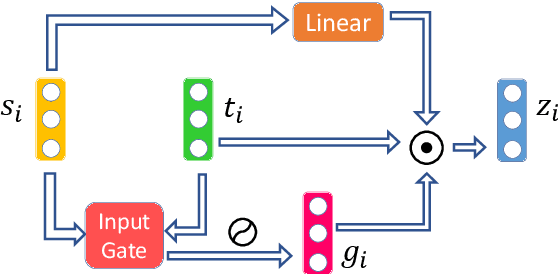
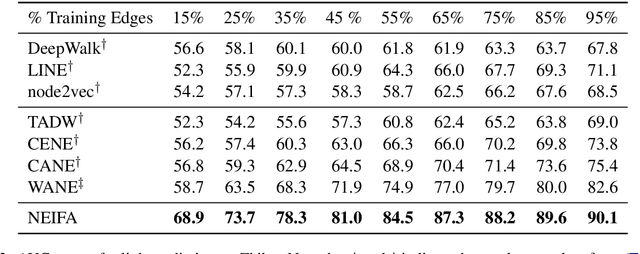
Textual network embeddings aim to learn a low-dimensional representation for every node in the network so that both the structural and textual information from the networks can be well preserved in the representations. Traditionally, the structural and textual embeddings were learned by models that rarely take the mutual influences between them into account. In this paper, a deep neural architecture is proposed to effectively fuse the two kinds of informations into one representation. The novelties of the proposed architecture are manifested in the aspects of a newly defined objective function, the complementary information fusion method for structural and textual features, and the mutual gate mechanism for textual feature extraction. Experimental results show that the proposed model outperforms the comparing methods on all three datasets.