 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Blind inverse problems with isolated spikes
Nov 03, 2021
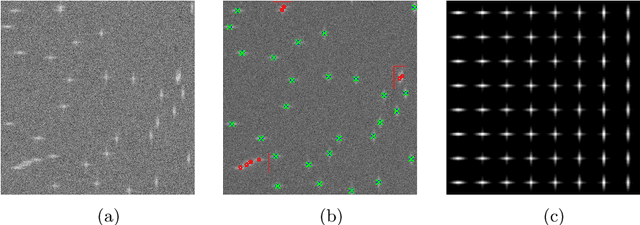
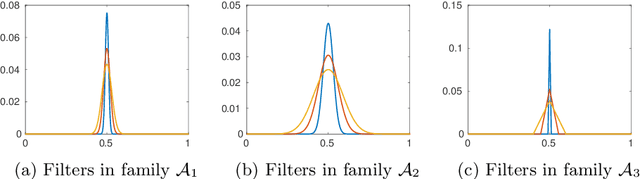
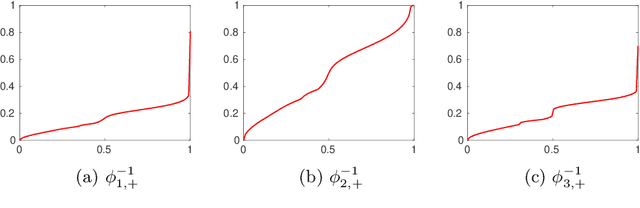
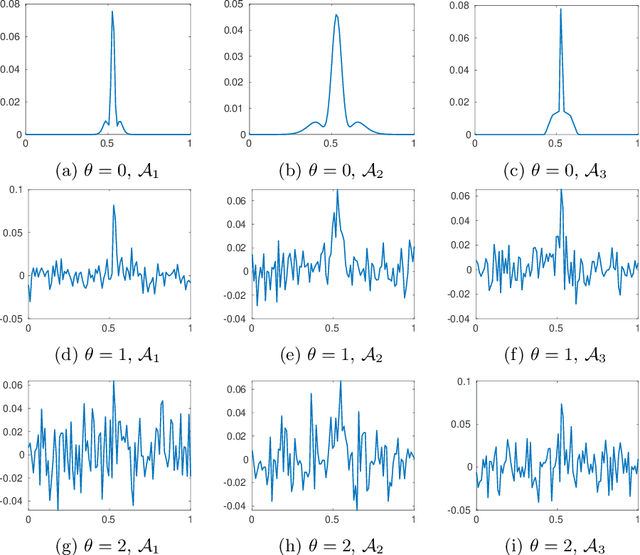
Assume that an unknown integral operator living in some known subspace is observed indirectly, by evaluating its action on a few Dirac masses at unknown locations. Is this information enough to recover the operator and the impulse responses locations stably? We study this question and answer positively under realistic technical assumptions. We illustrate the well-foundedness of this theory on two challenging optical imaging problems: blind super-resolution and deconvolution. This provides a simple, practical and theoretically grounded approach to solve these long resisting problems.
Efficient Context-Aware Network for Abdominal Multi-organ Segmentation
Oct 09, 2021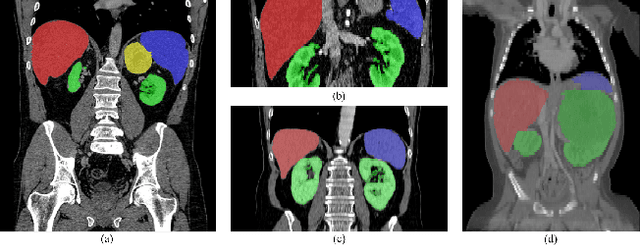
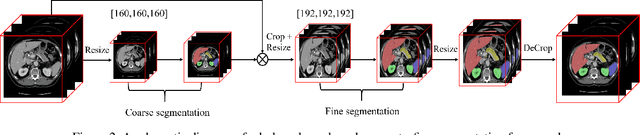
The contextual information, presented in abdominal CT scan, is relative consistent. In order to make full use of the overall 3D context, we develop a whole-volume-based coarse-to-fine framework for efficient and effective abdominal multi-organ segmentation. We propose a new efficientSegNet network, which is composed of encoder, decoder and context block. For the decoder module, anisotropic convolution with a k*k*1 intra-slice convolution and a 1*1*k inter-slice convolution, is designed to reduce the computation burden. For the context block, we propose strip pooling module to capture anisotropic and long-range contextual information, which exists in abdominal scene. Quantitative evaluation on the FLARE2021 validation cases, this method achieves the average dice similarity coefficient (DSC) of 0.895 and average normalized surface distance (NSD) of 0.775. The average running time is 9.8 s per case in inference phase, and maximum used GPU memory is 1017 MB.
Passive Indoor Localization with WiFi Fingerprints
Nov 29, 2021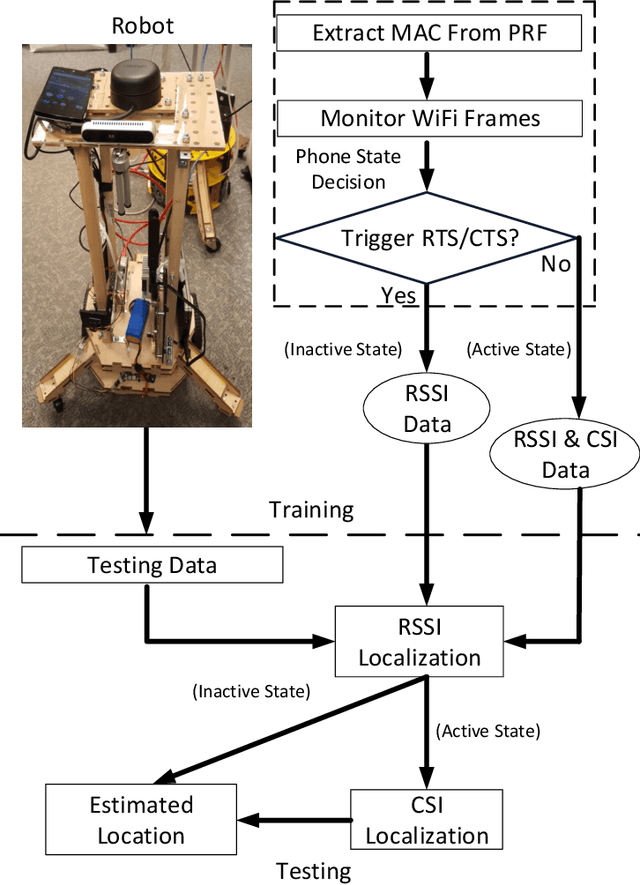
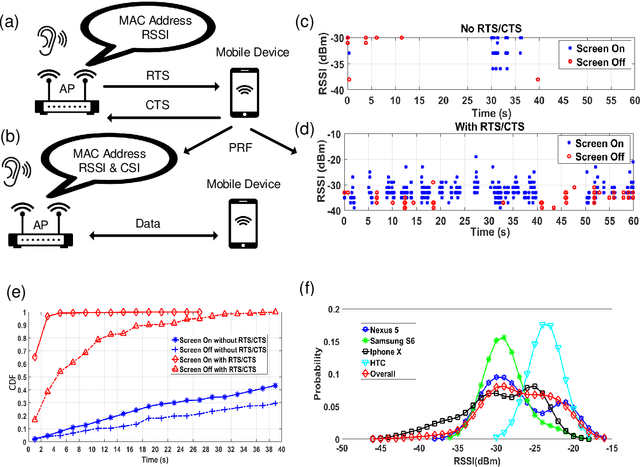
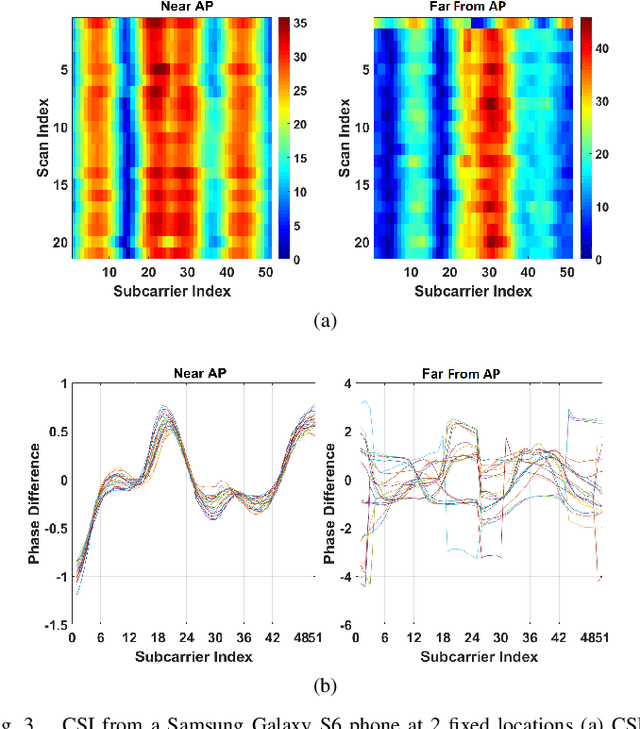
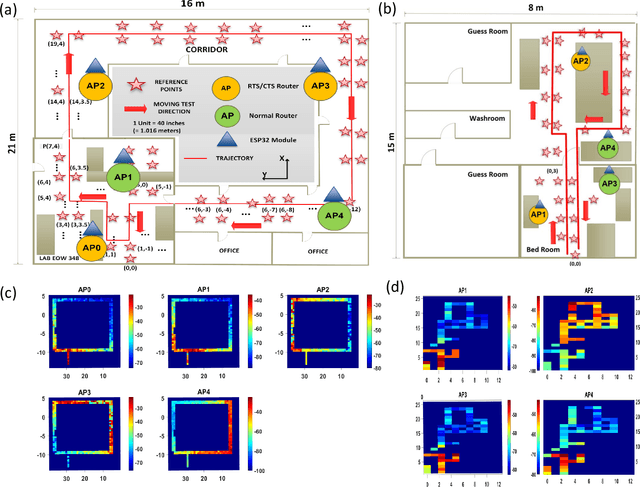
This paper proposes passive WiFi indoor localization. Instead of using WiFi signals received by mobile devices as fingerprints, we use signals received by routers to locate the mobile carrier. Consequently, software installation on the mobile device is not required. To resolve the data insufficiency problem, flow control signals such as request to send (RTS) and clear to send (CTS) are utilized. In our model, received signal strength indicator (RSSI) and channel state information (CSI) are used as fingerprints for several algorithms, including deterministic, probabilistic and neural networks localization algorithms. We further investigated localization algorithms performance through extensive on-site experiments with various models of phones at hundreds of testing locations. We demonstrate that our passive scheme achieves an average localization error of 0.8 m when the phone is actively transmitting data frames and 1.5 m when it is not transmitting data frames.
Bridging between Cognitive Processing Signals and Linguistic Features via a Unified Attentional Network
Dec 16, 2021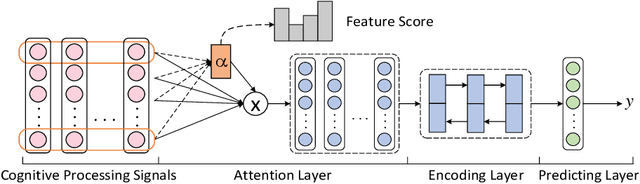

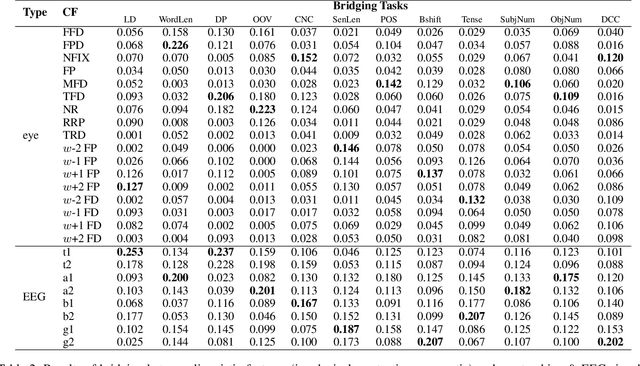

Cognitive processing signals can be used to improve natural language processing (NLP) tasks. However, it is not clear how these signals correlate with linguistic information. Bridging between human language processing and linguistic features has been widely studied in neurolinguistics, usually via single-variable controlled experiments with highly-controlled stimuli. Such methods not only compromises the authenticity of natural reading, but also are time-consuming and expensive. In this paper, we propose a data-driven method to investigate the relationship between cognitive processing signals and linguistic features. Specifically, we present a unified attentional framework that is composed of embedding, attention, encoding and predicting layers to selectively map cognitive processing signals to linguistic features. We define the mapping procedure as a bridging task and develop 12 bridging tasks for lexical, syntactic and semantic features. The proposed framework only requires cognitive processing signals recorded under natural reading as inputs, and can be used to detect a wide range of linguistic features with a single cognitive dataset. Observations from experiment results resonate with previous neuroscience findings. In addition to this, our experiments also reveal a number of interesting findings, such as the correlation between contextual eye-tracking features and tense of sentence.
Extracting Attentive Social Temporal Excitation for Sequential Recommendation
Sep 28, 2021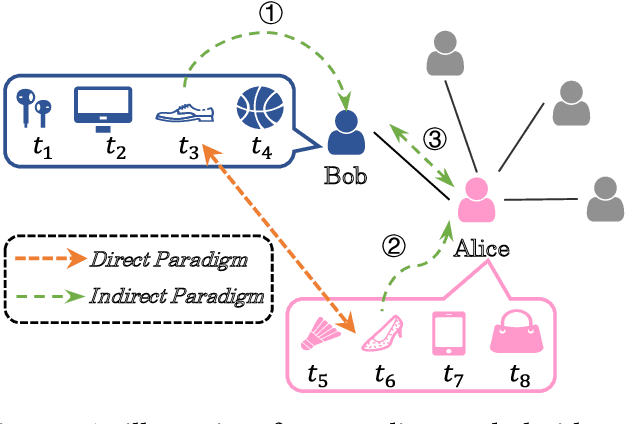
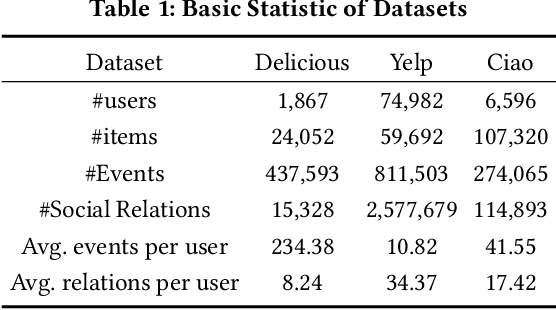
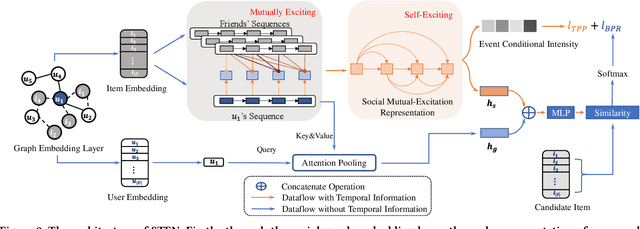
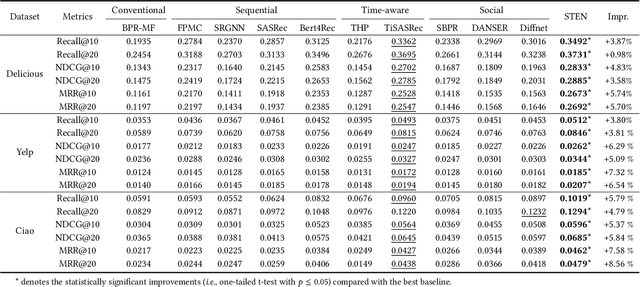
In collaborative filtering, it is an important way to make full use of social information to improve the recommendation quality, which has been proved to be effective because user behavior will be affected by her friends. However, existing works leverage the social relationship to aggregate user features from friends' historical behavior sequences in a user-level indirect paradigm. A significant defect of the indirect paradigm is that it ignores the temporal relationships between behavior events across users. In this paper, we propose a novel time-aware sequential recommendation framework called Social Temporal Excitation Networks (STEN), which introduces temporal point processes to model the fine-grained impact of friends' behaviors on the user s dynamic interests in an event-level direct paradigm. Moreover, we propose to decompose the temporal effect in sequential recommendation into social mutual temporal effect and ego temporal effect. Specifically, we employ a social heterogeneous graph embedding layer to refine user representation via structural information. To enhance temporal information propagation, STEN directly extracts the fine-grained temporal mutual influence of friends' behaviors through the mutually exciting temporal network. Besides, the user s dynamic interests are captured through the self-exciting temporal network. Extensive experiments on three real-world datasets show that STEN outperforms state-of-the-art baseline methods. Moreover, STEN provides event-level recommendation explainability, which is also illustrated experimentally.
A Survey of Knowledge Graph Embedding and Their Applications
Jul 16, 2021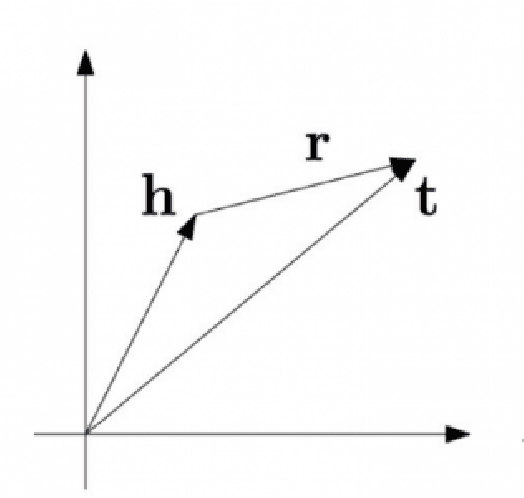
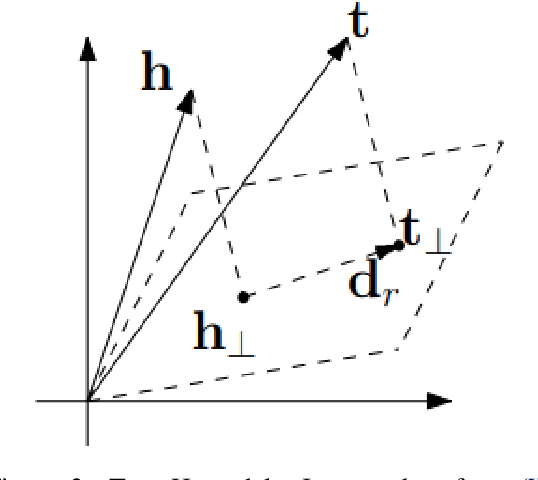
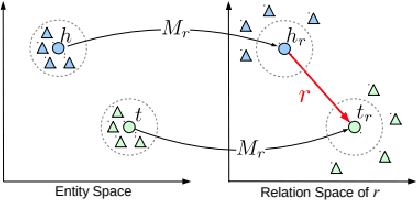
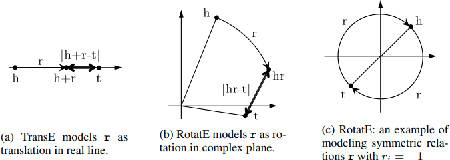
Knowledge Graph embedding provides a versatile technique for representing knowledge. These techniques can be used in a variety of applications such as completion of knowledge graph to predict missing information, recommender systems, question answering, query expansion, etc. The information embedded in Knowledge graph though being structured is challenging to consume in a real-world application. Knowledge graph embedding enables the real-world application to consume information to improve performance. Knowledge graph embedding is an active research area. Most of the embedding methods focus on structure-based information. Recent research has extended the boundary to include text-based information and image-based information in entity embedding. Efforts have been made to enhance the representation with context information. This paper introduces growth in the field of KG embedding from simple translation-based models to enrichment-based models. This paper includes the utility of the Knowledge graph in real-world applications.
BoGraph: Structured Bayesian Optimization From Logs for Systems with High-dimensional Parameter Space
Dec 16, 2021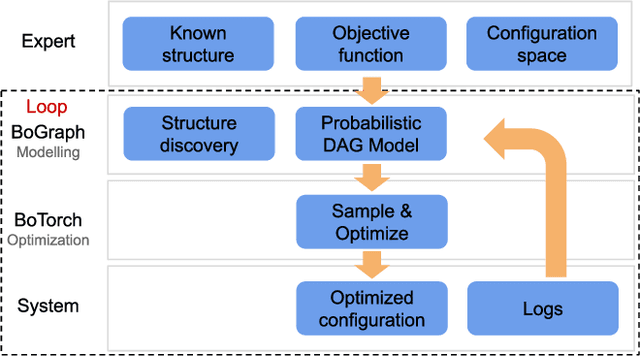

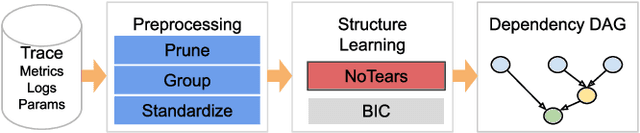
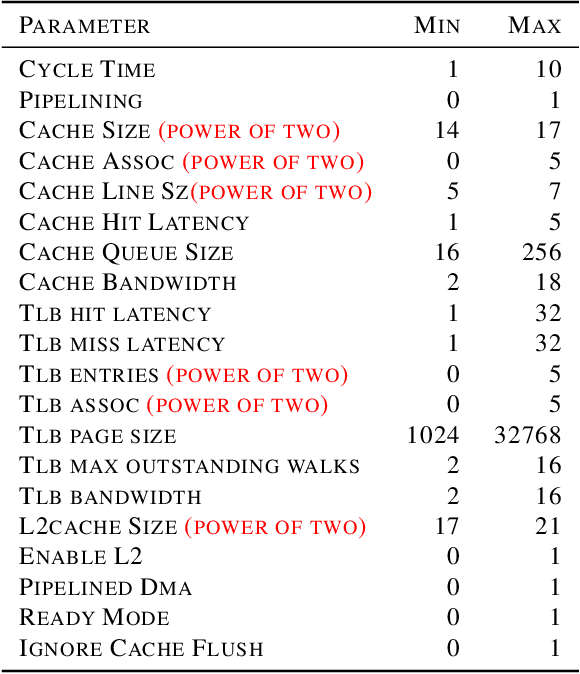
Current auto-tuning frameworks struggle with tuning computer systems configurations due to their large parameter space, complex interdependencies, and high evaluation cost. Utilizing probabilistic models, Structured Bayesian Optimization (SBO) has recently overcome these difficulties. SBO decomposes the parameter space by utilizing contextual information provided by system experts leading to fast convergence. However, the complexity of building probabilistic models has hindered its wider adoption. We propose BoAnon, a SBO framework that learns the system structure from its logs. BoAnon provides an API enabling experts to encode knowledge of the system as performance models or components dependency. BoAnon takes in the learned structure and transforms it into a probabilistic graph model. Then it applies the expert-provided knowledge to the graph to further contextualize the system behavior. BoAnon probabilistic graph allows the optimizer to find efficient configurations faster than other methods. We evaluate BoAnon via a hardware architecture search problem, achieving an improvement in energy-latency objectives ranging from $5-7$ x-factors improvement over the default architecture. With its novel contextual structure learning pipeline, BoAnon makes using SBO accessible for a wide range of other computer systems such as databases and stream processors.
Unsourced Random Massive Access with Beam-Space Tree Decoding
Dec 30, 2021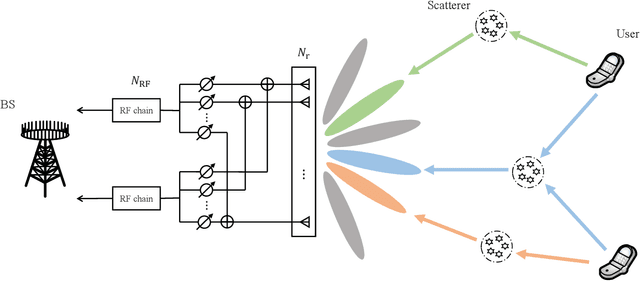
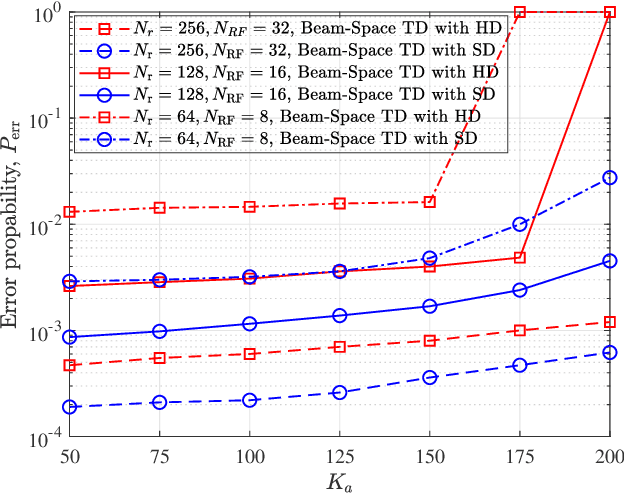
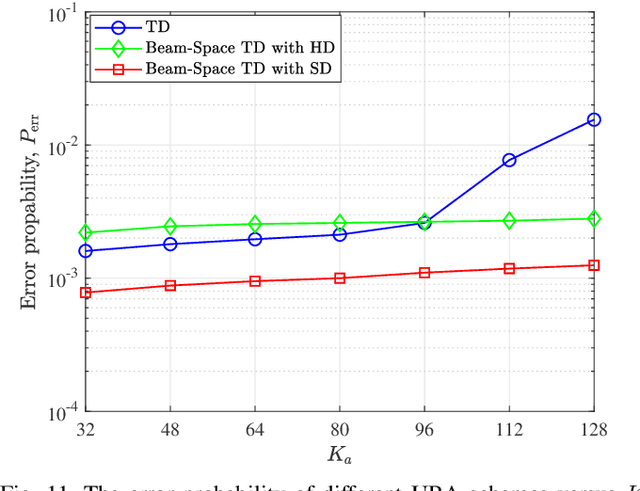
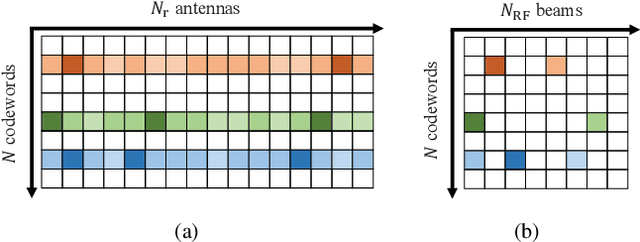
The core requirement of massive Machine-Type Communication (mMTC) is to support reliable and fast access for an enormous number of machine-type devices (MTDs). In many practical applications, the base station (BS) only concerns the list of received messages instead of the source information, introducing the emerging concept of unsourced random access (URA). Although some massive multiple-input multiple-output (MIMO) URA schemes have been proposed recently, the unique propagation properties of millimeter-wave (mmWave) massive MIMO systems are not fully exploited in conventional URA schemes. In grant-free random access, the BS cannot perform receive beamforming independently as the identities of active users are unknown to the BS. Therefore, only the intrinsic beam division property can be exploited to improve the decoding performance. In this paper, a URA scheme based on beam-space tree decoding is proposed for mmWave massive MIMO system. Specifically, two beam-space tree decoders are designed based on hard decision and soft decision, respectively, to utilize the beam division property. They both leverage the beam division property to assist in discriminating the sub-blocks transmitted from different users. Besides, the first decoder can reduce the searching space, enjoying a low complexity. The second decoder exploits the advantage of list decoding to recover the miss-detected packets. Simulation results verify the superiority of the proposed URA schemes compared to the conventional URA schemes in terms of error probability.
Online Learning in Adversarial MDPs: Is the Communicating Case Harder than Ergodic?
Nov 03, 2021
We study online learning in adversarial communicating Markov Decision Processes with full information. We give an algorithm that achieves a regret of $O(\sqrt{T})$ with respect to the best fixed deterministic policy in hindsight when the transitions are deterministic. We also prove a regret lower bound in this setting which is tight up to polynomial factors in the MDP parameters. We also give an inefficient algorithm that achieves $O(\sqrt{T})$ regret in communicating MDPs (with an additional mild restriction on the transition dynamics).
Assessment of Amazon Comprehend Medical: Medication Information Extraction
Feb 02, 2020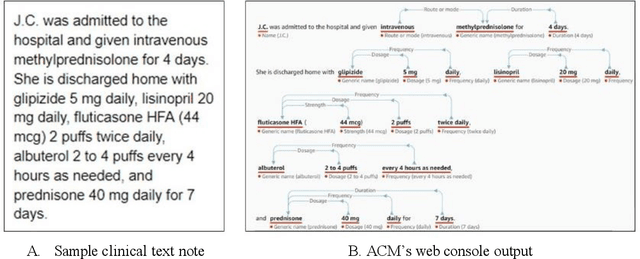
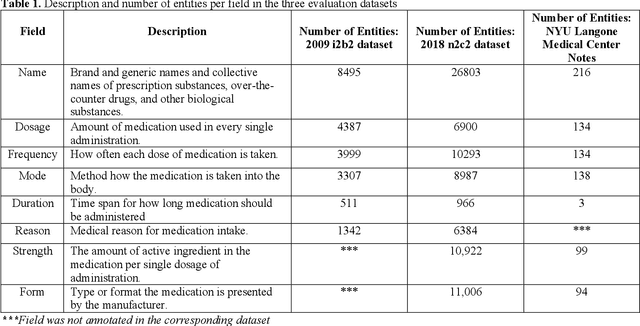

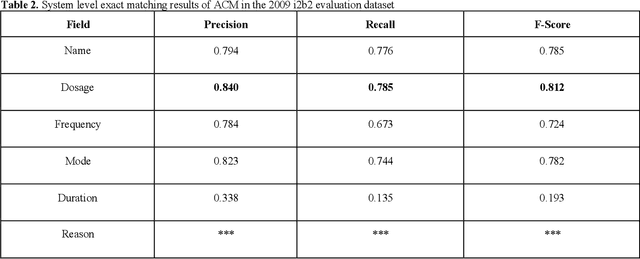
In November 27, 2018, Amazon Web Services (AWS) released Amazon Comprehend Medical (ACM), a deep learning based system that automatically extracts clinical concepts (which include anatomy, medical conditions, protected health information (PH)I, test names, treatment names, and medical procedures, and medications) from clinical text notes. Uptake and trust in any new data product relies on independent validation across benchmark datasets and tools to establish and confirm expected quality of results. This work focuses on the medication extraction task, and particularly, ACM was evaluated using the official test sets from the 2009 i2b2 Medication Extraction Challenge and 2018 n2c2 Track 2: Adverse Drug Events and Medication Extraction in EHRs. Overall, ACM achieved F-scores of 0.768 and 0.828. These scores ranked the lowest when compared to the three best systems in the respective challenges. To further establish the generalizability of its medication extraction performance, a set of random internal clinical text notes from NYU Langone Medical Center were also included in this work. And in this corpus, ACM garnered an F-score of 0.753.