 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Localization of a Smart Infrastructure Fisheye Camera in a Prior Map for Autonomous Vehicles
Sep 28, 2021
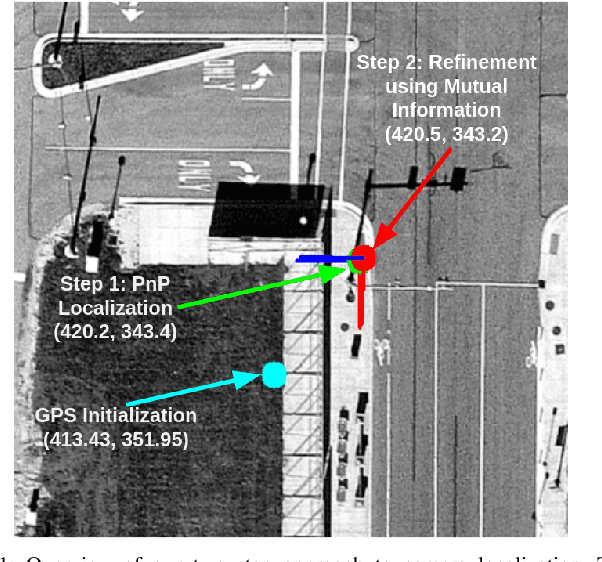


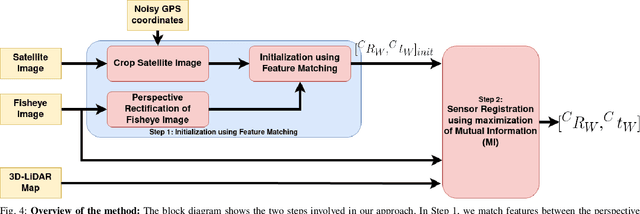
This work presents a technique for localization of a smart infrastructure node, consisting of a fisheye camera, in a prior map. These cameras can detect objects that are outside the line of sight of the autonomous vehicles (AV) and send that information to AVs using V2X technology. However, in order for this information to be of any use to the AV, the detected objects should be provided in the reference frame of the prior map that the AV uses for its own navigation. Therefore, it is important to know the accurate pose of the infrastructure camera with respect to the prior map. Here we propose to solve this localization problem in two steps, \textit{(i)} we perform feature matching between perspective projection of fisheye image and bird's eye view (BEV) satellite imagery from the prior map to estimate an initial camera pose, \textit{(ii)} we refine the initialization by maximizing the Mutual Information (MI) between intensity of pixel values of fisheye image and reflectivity of 3D LiDAR points in the map data. We validate our method on simulated data and also present results with real world data.
Practical Distributed Reception for Wireless Body Area Networks Using Supervised Learning
Dec 14, 2021



Medical applications have driven many areas of engineering to optimize diagnostic capabilities and convenience. In the near future, wireless body area networks (WBANs) are expected to have widespread impact in medicine. To achieve this impact, however, significant advances in research are needed to cope with the changes of the human body's state, which make coherent communications difficult or even impossible. In this paper, we consider a realistic noncoherent WBAN system model where transmissions and receptions are conducted without any channel state information due to the fast-varying channels of the human body. Using distributed reception, we propose several symbol detection approaches where on-off keying (OOK) modulation is exploited, among which a supervised-learning-based approach is developed to overcome the noncoherent system issue. Through simulation results, we compare and verify the performance of the proposed techniques for noncoherent WBANs with OOK transmissions. We show that the well-defined detection techniques with a supervised-learning-based approach enable robust communications for noncoherent WBAN systems.
Spatial-Temporal Transformer for 3D Point Cloud Sequences
Oct 19, 2021Effective learning of spatial-temporal information within a point cloud sequence is highly important for many down-stream tasks such as 4D semantic segmentation and 3D action recognition. In this paper, we propose a novel framework named Point Spatial-Temporal Transformer (PST2) to learn spatial-temporal representations from dynamic 3D point cloud sequences. Our PST2 consists of two major modules: a Spatio-Temporal Self-Attention (STSA) module and a Resolution Embedding (RE) module. Our STSA module is introduced to capture the spatial-temporal context information across adjacent frames, while the RE module is proposed to aggregate features across neighbors to enhance the resolution of feature maps. We test the effectiveness our PST2 with two different tasks on point cloud sequences, i.e., 4D semantic segmentation and 3D action recognition. Extensive experiments on three benchmarks show that our PST2 outperforms existing methods on all datasets. The effectiveness of our STSA and RE modules have also been justified with ablation experiments.
Data-Driven Deep Learning Based Hybrid Beamforming for Aerial Massive MIMO-OFDM Systems with Implicit CSI
Jan 18, 2022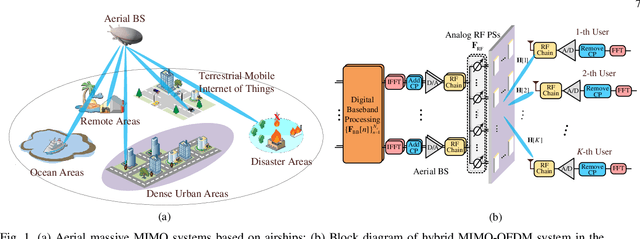
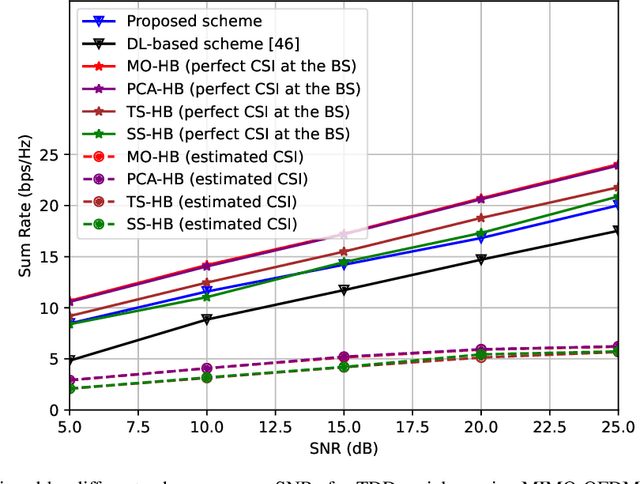
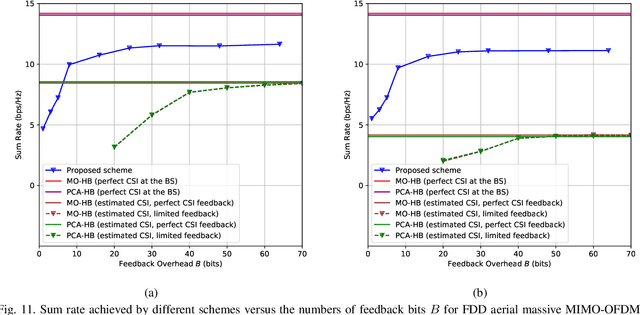
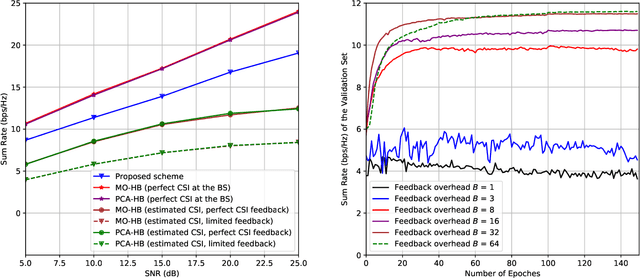
In an aerial hybrid massive multiple-input multiple-output (MIMO) and orthogonal frequency division multiplexing (OFDM) system, how to design a spectral-efficient broadband multi-user hybrid beamforming with a limited pilot and feedback overhead is challenging. To this end, by modeling the key transmission modules as an end-to-end (E2E) neural network, this paper proposes a data-driven deep learning (DL)-based unified hybrid beamforming framework for both the time division duplex (TDD) and frequency division duplex (FDD) systems with implicit channel state information (CSI). For TDD systems, the proposed DL-based approach jointly models the uplink pilot combining and downlink hybrid beamforming modules as an E2E neural network. While for FDD systems, we jointly model the downlink pilot transmission, uplink CSI feedback, and downlink hybrid beamforming modules as an E2E neural network. Different from conventional approaches separately processing different modules, the proposed solution simultaneously optimizes all modules with the sum rate as the optimization object. Therefore, by perceiving the inherent property of air-to-ground massive MIMO-OFDM channel samples, the DL-based E2E neural network can establish the mapping function from the channel to the beamformer, so that the explicit channel reconstruction can be avoided with reduced pilot and feedback overhead. Besides, practical low-resolution phase shifters (PSs) introduce the quantization constraint, leading to the intractable gradient backpropagation when training the neural network. To mitigate the performance loss caused by the phase quantization error, we adopt the transfer learning strategy to further fine-tune the E2E neural network based on a pre-trained network that assumes the ideal infinite-resolution PSs. Numerical results show that our DL-based schemes have considerable advantages over state-of-the-art schemes.
DynSTGAT: Dynamic Spatial-Temporal Graph Attention Network for Traffic Signal Control
Sep 12, 2021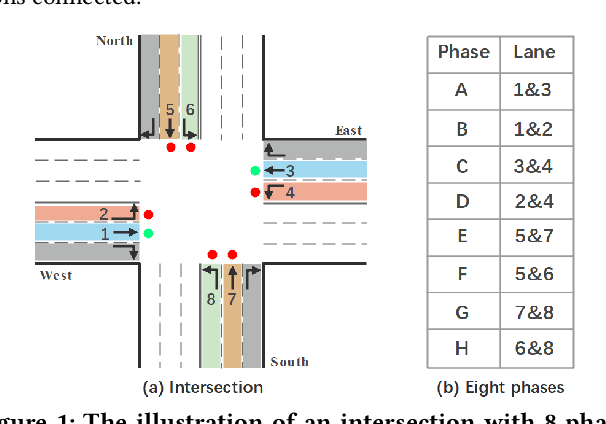
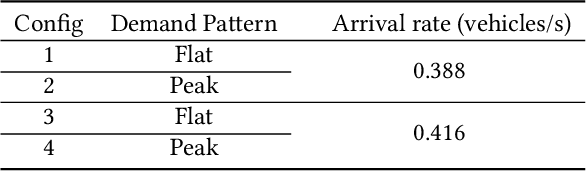
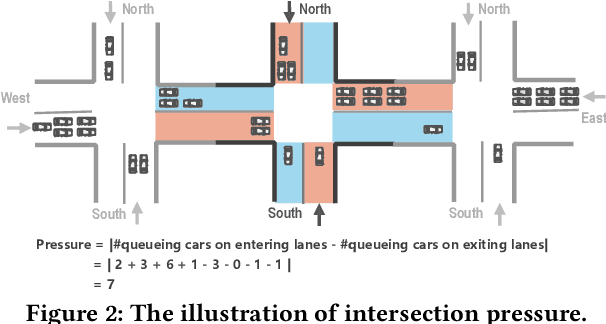

Adaptive traffic signal control plays a significant role in the construction of smart cities. This task is challenging because of many essential factors, such as cooperation among neighboring intersections and dynamic traffic scenarios. First, to facilitate cooperation of traffic signals, existing work adopts graph neural networks to incorporate the temporal and spatial influences of the surrounding intersections into the target intersection, where spatial-temporal information is used separately. However, one drawback of these methods is that the spatial-temporal correlations are not adequately exploited to obtain a better control scheme. Second, in a dynamic traffic environment, the historical state of the intersection is also critical for predicting future signal switching. Previous work mainly solves this problem using the current intersection's state, neglecting the fact that traffic flow is continuously changing both spatially and temporally and does not handle the historical state. In this paper, we propose a novel neural network framework named DynSTGAT, which integrates dynamic historical state into a new spatial-temporal graph attention network to address the above two problems. More specifically, our DynSTGAT model employs a novel multi-head graph attention mechanism, which aims to adequately exploit the joint relations of spatial-temporal information. Then, to efficiently utilize the historical state information of the intersection, we design a sequence model with the temporal convolutional network (TCN) to capture the historical information and further merge it with the spatial information to improve its performance. Extensive experiments conducted in the multi-intersection scenario on synthetic data and real-world data confirm that our method can achieve superior performance in travel time and throughput against the state-of-the-art methods.
Dynamic optimization with side information
Jul 17, 2019
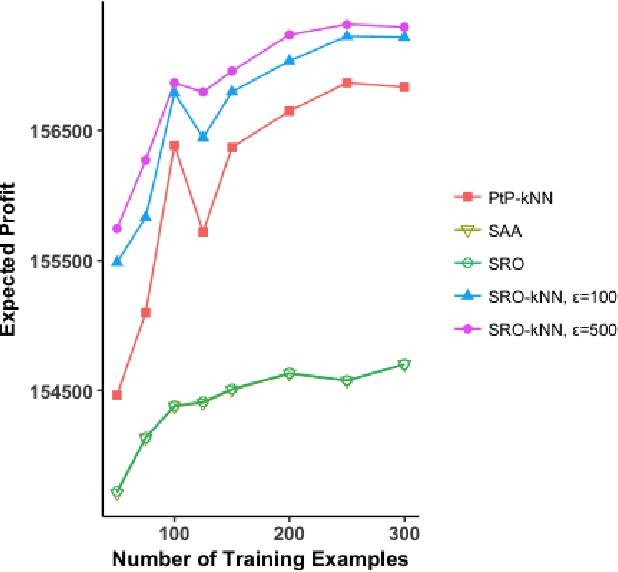
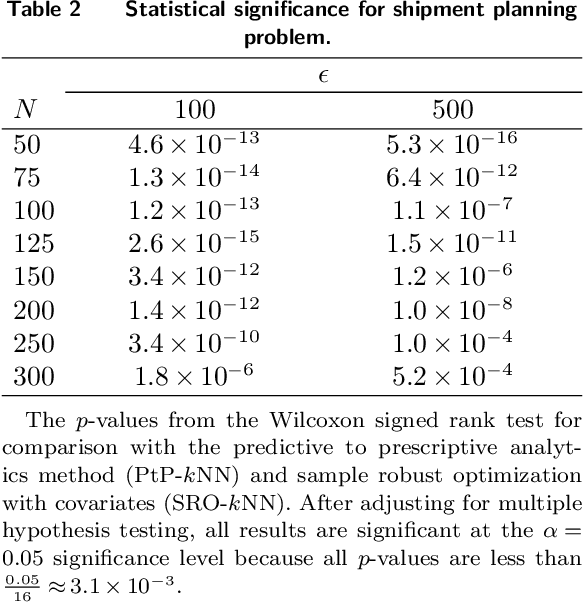
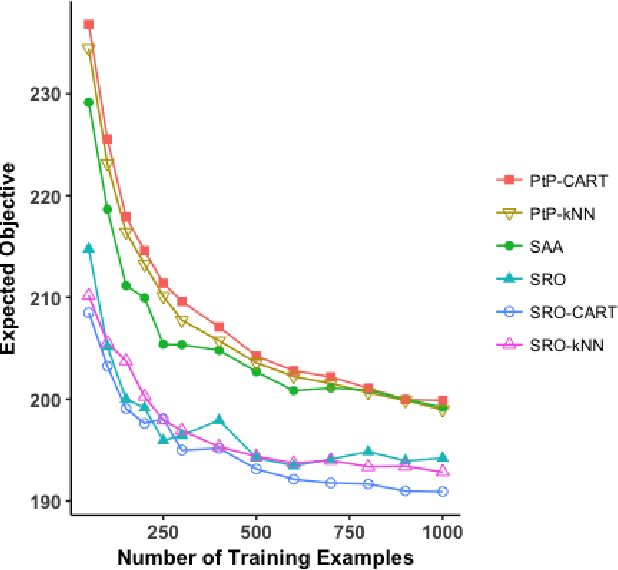
We present a data-driven framework for incorporating side information in dynamic optimization under uncertainty. Specifically, our approach uses predictive machine learning methods (such as k-nearest neighbors, kernel regression, and random forests) to weight the relative importance of various data-driven uncertainty sets in a robust optimization formulation. Through a novel measure concentration result for local machine learning methods, we prove that the proposed framework is asymptotically optimal for stochastic dynamic optimization with covariates. We also describe a general-purpose approximation for the proposed framework, based on overlapping linear decision rules, which is computationally tractable and produces high-quality solutions for dynamic problems with many stages. Across a variety of examples in shipment planning, inventory management, and finance, our method achieves improvements of up to 15% over alternatives and requires less than one minute of computation time on problems with twelve stages.
Are You Smarter Than a Random Expert? The Robust Aggregation of Substitutable Signals
Nov 04, 2021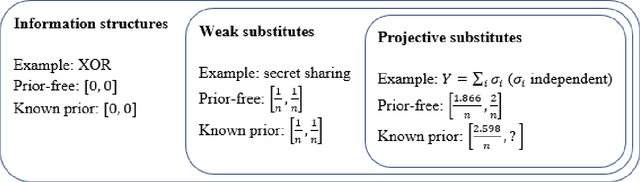
The problem of aggregating expert forecasts is ubiquitous in fields as wide-ranging as machine learning, economics, climate science, and national security. Despite this, our theoretical understanding of this question is fairly shallow. This paper initiates the study of forecast aggregation in a context where experts' knowledge is chosen adversarially from a broad class of information structures. While in full generality it is impossible to achieve a nontrivial performance guarantee, we show that doing so is possible under a condition on the experts' information structure that we call \emph{projective substitutes}. The projective substitutes condition is a notion of informational substitutes: that there are diminishing marginal returns to learning the experts' signals. We show that under the projective substitutes condition, taking the average of the experts' forecasts improves substantially upon the strategy of trusting a random expert. We then consider a more permissive setting, in which the aggregator has access to the prior. We show that by averaging the experts' forecasts and then \emph{extremizing} the average by moving it away from the prior by a constant factor, the aggregator's performance guarantee is substantially better than is possible without knowledge of the prior. Our results give a theoretical grounding to past empirical research on extremization and help give guidance on the appropriate amount to extremize.
Real-Time Volumetric-Semantic Exploration and Mapping: An Uncertainty-Aware Approach
Sep 03, 2021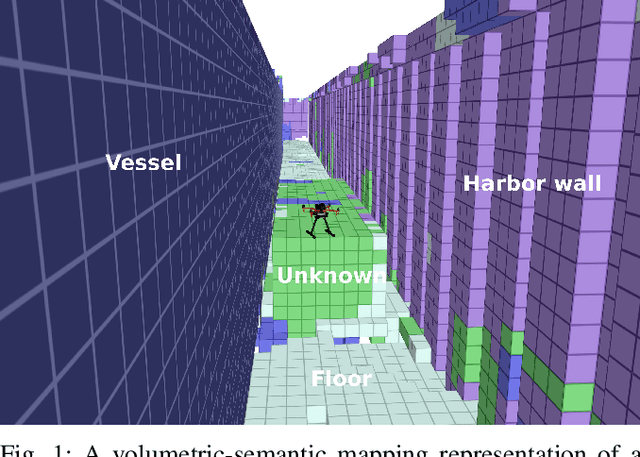
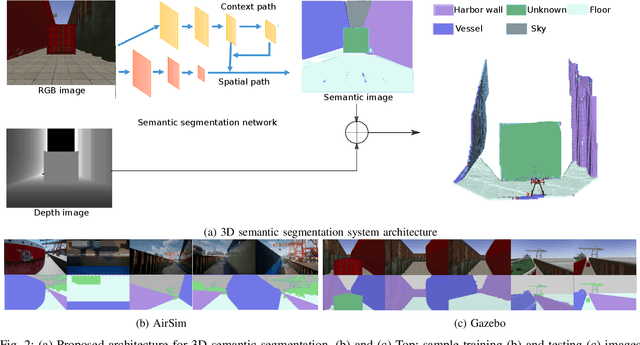
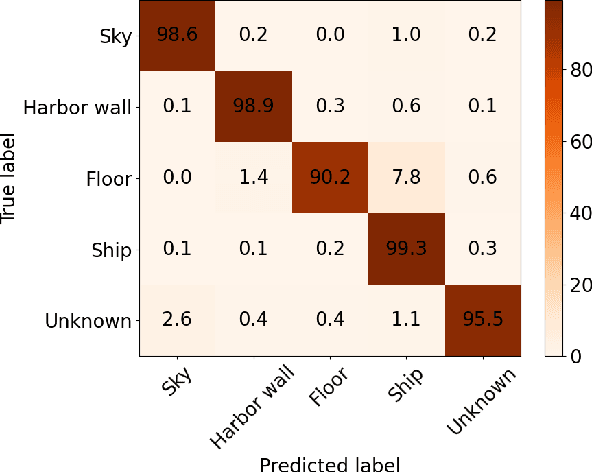

In this work we propose a holistic framework for autonomous aerial inspection tasks, using semantically-aware, yet, computationally efficient planning and mapping algorithms. The system leverages state-of-the-art receding horizon exploration techniques for next-best-view (NBV) planning with geometric and semantic segmentation information provided by state-of-the-art deep convolutional neural networks (DCNNs), with the goal of enriching environment representations. The contributions of this article are threefold, first we propose an efficient sensor observation model, and a reward function that encodes the expected information gains from the observations taken from specific view points. Second, we extend the reward function to incorporate not only geometric but also semantic probabilistic information, provided by a DCNN for semantic segmentation that operates in real-time. The incorporation of semantic information in the environment representation allows biasing exploration towards specific objects, while ignoring task-irrelevant ones during planning. Finally, we employ our approaches in an autonomous drone shipyard inspection task. A set of simulations in realistic scenarios demonstrate the efficacy and efficiency of the proposed framework when compared with the state-of-the-art.
Adaptive Optimization with Examplewise Gradients
Nov 30, 2021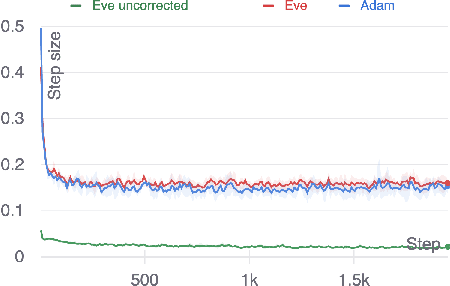

We propose a new, more general approach to the design of stochastic gradient-based optimization methods for machine learning. In this new framework, optimizers assume access to a batch of gradient estimates per iteration, rather than a single estimate. This better reflects the information that is actually available in typical machine learning setups. To demonstrate the usefulness of this generalized approach, we develop Eve, an adaptation of the Adam optimizer which uses examplewise gradients to obtain more accurate second-moment estimates. We provide preliminary experiments, without hyperparameter tuning, which show that the new optimizer slightly outperforms Adam on a small scale benchmark and performs the same or worse on larger scale benchmarks. Further work is needed to refine the algorithm and tune hyperparameters.
Vision Guided Generative Pre-trained Language Models for Multimodal Abstractive Summarization
Sep 08, 2021
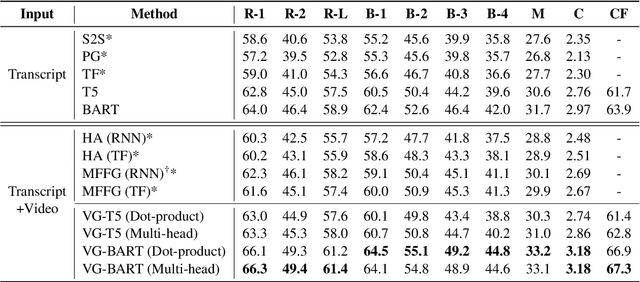
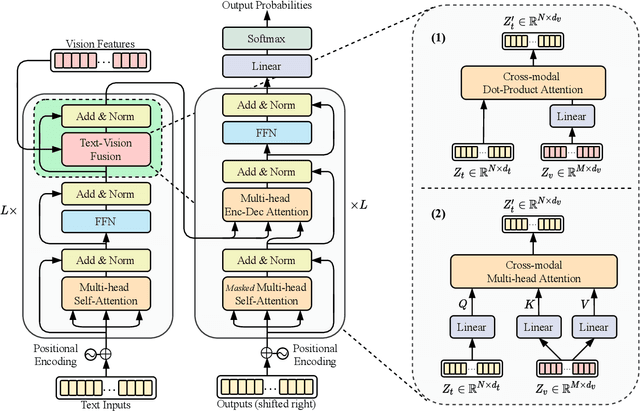

Multimodal abstractive summarization (MAS) models that summarize videos (vision modality) and their corresponding transcripts (text modality) are able to extract the essential information from massive multimodal data on the Internet. Recently, large-scale generative pre-trained language models (GPLMs) have been shown to be effective in text generation tasks. However, existing MAS models cannot leverage GPLMs' powerful generation ability. To fill this research gap, we aim to study two research questions: 1) how to inject visual information into GPLMs without hurting their generation ability; and 2) where is the optimal place in GPLMs to inject the visual information? In this paper, we present a simple yet effective method to construct vision guided (VG) GPLMs for the MAS task using attention-based add-on layers to incorporate visual information while maintaining their original text generation ability. Results show that our best model significantly surpasses the prior state-of-the-art model by 5.7 ROUGE-1, 5.3 ROUGE-2, and 5.1 ROUGE-L scores on the How2 dataset, and our visual guidance method contributes 83.6% of the overall improvement. Furthermore, we conduct thorough ablation studies to analyze the effectiveness of various modality fusion methods and fusion locations.