 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Spectral, Probabilistic, and Deep Metric Learning: Tutorial and Survey
Jan 23, 2022
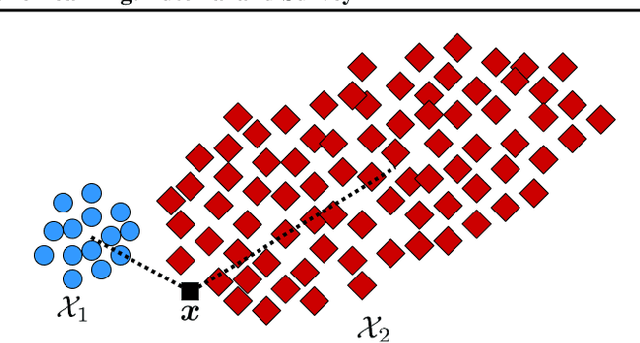
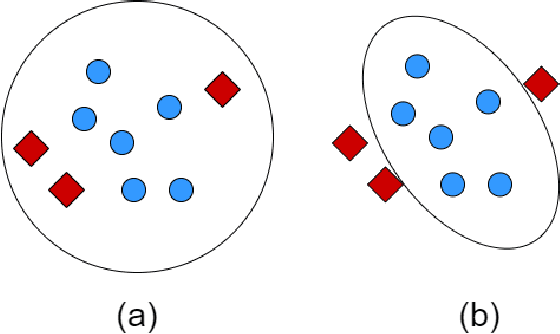
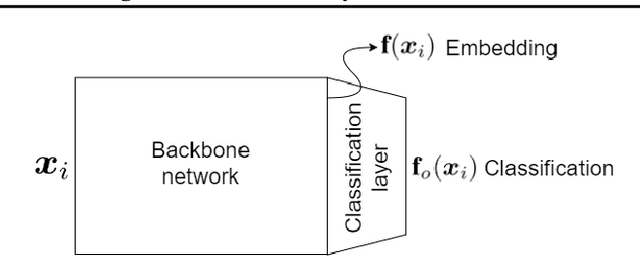
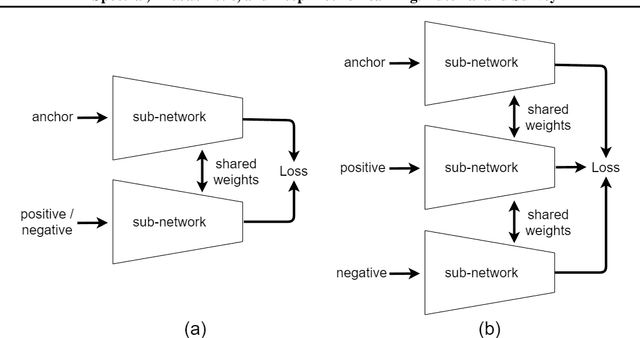
This is a tutorial and survey paper on metric learning. Algorithms are divided into spectral, probabilistic, and deep metric learning. We first start with the definition of distance metric, Mahalanobis distance, and generalized Mahalanobis distance. In spectral methods, we start with methods using scatters of data, including the first spectral metric learning, relevant methods to Fisher discriminant analysis, Relevant Component Analysis (RCA), Discriminant Component Analysis (DCA), and the Fisher-HSIC method. Then, large-margin metric learning, imbalanced metric learning, locally linear metric adaptation, and adversarial metric learning are covered. We also explain several kernel spectral methods for metric learning in the feature space. We also introduce geometric metric learning methods on the Riemannian manifolds. In probabilistic methods, we start with collapsing classes in both input and feature spaces and then explain the neighborhood component analysis methods, Bayesian metric learning, information theoretic methods, and empirical risk minimization in metric learning. In deep learning methods, we first introduce reconstruction autoencoders and supervised loss functions for metric learning. Then, Siamese networks and its various loss functions, triplet mining, and triplet sampling are explained. Deep discriminant analysis methods, based on Fisher discriminant analysis, are also reviewed. Finally, we introduce multi-modal deep metric learning, geometric metric learning by neural networks, and few-shot metric learning.
Cross-Lingual Dialogue Dataset Creation via Outline-Based Generation
Jan 31, 2022Multilingual task-oriented dialogue (ToD) facilitates access to services and information for many (communities of) speakers. Nevertheless, the potential of this technology is not fully realised, as current datasets for multilingual ToD - both for modular and end-to-end modelling - suffer from severe limitations. 1) When created from scratch, they are usually small in scale and fail to cover many possible dialogue flows. 2) Translation-based ToD datasets might lack naturalness and cultural specificity in the target language. In this work, to tackle these limitations we propose a novel outline-based annotation process for multilingual ToD datasets, where domain-specific abstract schemata of dialogue are mapped into natural language outlines. These in turn guide the target language annotators in writing a dialogue by providing instructions about each turn's intents and slots. Through this process we annotate a new large-scale dataset for training and evaluation of multilingual and cross-lingual ToD systems. Our Cross-lingual Outline-based Dialogue dataset (termed COD) enables natural language understanding, dialogue state tracking, and end-to-end dialogue modelling and evaluation in 4 diverse languages: Arabic, Indonesian, Russian, and Kiswahili. Qualitative and quantitative analyses of COD versus an equivalent translation-based dataset demonstrate improvements in data quality, unlocked by the outline-based approach. Finally, we benchmark a series of state-of-the-art systems for cross-lingual ToD, setting reference scores for future work and demonstrating that COD prevents over-inflated performance, typically met with prior translation-based ToD datasets.
A Geometric Perspective towards Neural Calibration via Sensitivity Decomposition
Nov 21, 2021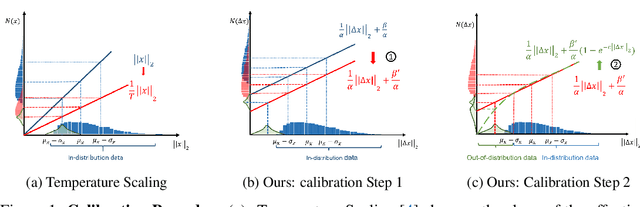
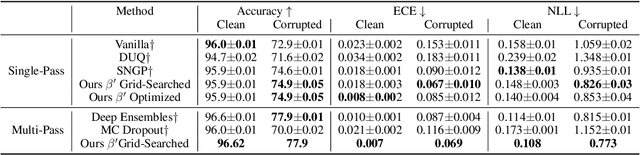
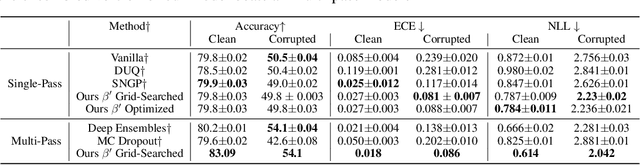
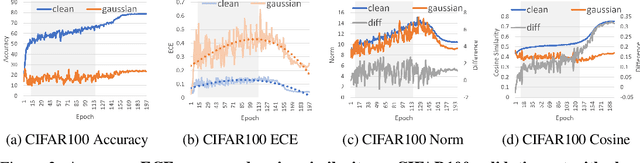
It is well known that vision classification models suffer from poor calibration in the face of data distribution shifts. In this paper, we take a geometric approach to this problem. We propose Geometric Sensitivity Decomposition (GSD) which decomposes the norm of a sample feature embedding and the angular similarity to a target classifier into an instance-dependent and an instance-independent component. The instance-dependent component captures the sensitive information about changes in the input while the instance-independent component represents the insensitive information serving solely to minimize the loss on the training dataset. Inspired by the decomposition, we analytically derive a simple extension to current softmax-linear models, which learns to disentangle the two components during training. On several common vision models, the disentangled model outperforms other calibration methods on standard calibration metrics in the face of out-of-distribution (OOD) data and corruption with significantly less complexity. Specifically, we surpass the current state of the art by 30.8% relative improvement on corrupted CIFAR100 in Expected Calibration Error. Code available at https://github.com/GT-RIPL/Geometric-Sensitivity-Decomposition.git.
MetroLoc: Metro Vehicle Mapping and Localization with LiDAR-Camera-Inertial Integration
Nov 01, 2021
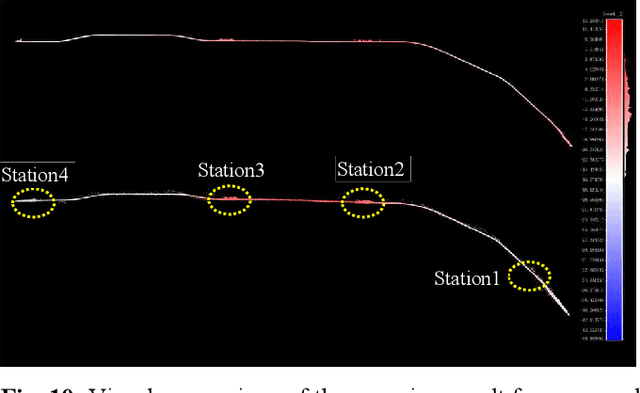
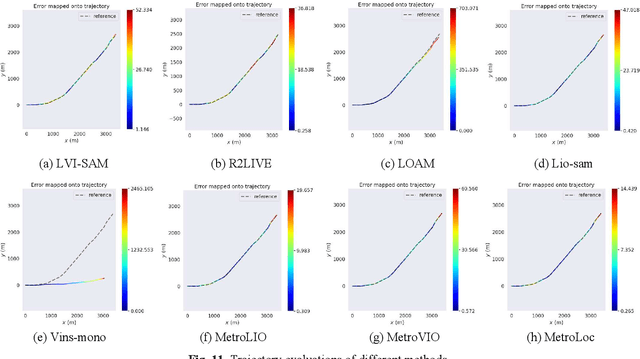

We propose an accurate and robust multi-modal sensor fusion framework, MetroLoc, towards one of the most extreme scenarios, the large-scale metro vehicle localization and mapping. MetroLoc is built atop an IMU-centric state estimator that tightly couples light detection and ranging (LiDAR), visual, and inertial information with the convenience of loosely coupled methods. The proposed framework is composed of three submodules: IMU odometry, LiDAR-inertial odometry (LIO), and Visual-inertial odometry (VIO). The IMU is treated as the primary sensor, which achieves the observations from LIO and VIO to constrain the accelerometer and gyroscope biases. Compared to previous point-only LIO methods, our approach leverages more geometry information by introducing both line and plane features into motion estimation. The VIO also utilizes the environmental structure information by employing both lines and points. Our proposed method has been extensively tested in the long-during metro environments with a maintenance vehicle. Experimental results show the system more accurate and robust than the state-of-the-art approaches with real-time performance. Besides, we develop a series of Virtual Reality (VR) applications towards efficient, economical, and interactive rail vehicle state and trackside infrastructure monitoring, which has already been deployed to an outdoor testing railroad.
Early Detection of Network Attacks Using Deep Learning
Jan 27, 2022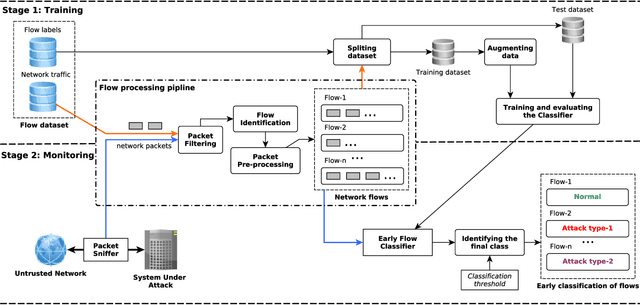
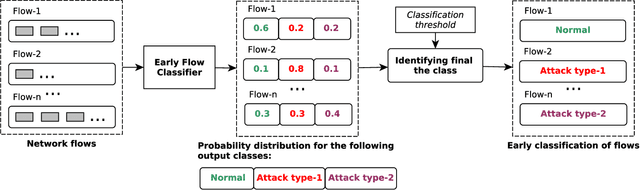


The Internet has become a prime subject to security attacks and intrusions by attackers. These attacks can lead to system malfunction, network breakdown, data corruption or theft. A network intrusion detection system (IDS) is a tool used for identifying unauthorized and malicious behavior by observing the network traffic. State-of-the-art intrusion detection systems are designed to detect an attack by inspecting the complete information about the attack. This means that an IDS would only be able to detect an attack after it has been executed on the system under attack and might have caused damage to the system. In this paper, we propose an end-to-end early intrusion detection system to prevent network attacks before they could cause any more damage to the system under attack while preventing unforeseen downtime and interruption. We employ a deep neural network-based classifier for attack identification. The network is trained in a supervised manner to extract relevant features from raw network traffic data instead of relying on a manual feature selection process used in most related approaches. Further, we introduce a new metric, called earliness, to evaluate how early our proposed approach detects attacks. We have empirically evaluated our approach on the CICIDS2017 dataset. The results show that our approach performed well and attained an overall 0.803 balanced accuracy.
ContraQA: Question Answering under Contradicting Contexts
Oct 15, 2021
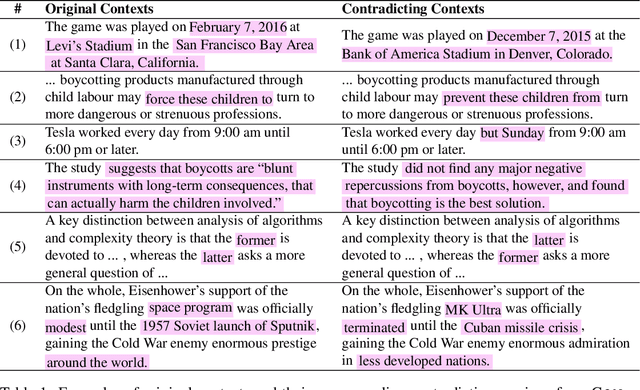

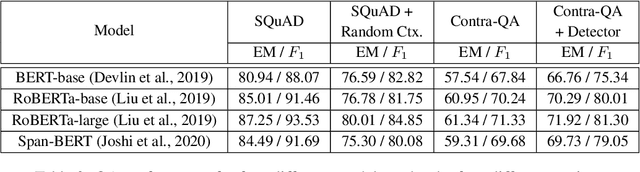
With a rise in false, inaccurate, and misleading information in propaganda, news, and social media, real-world Question Answering (QA) systems face the challenges of synthesizing and reasoning over contradicting information to derive correct answers. This urgency gives rise to the need to make QA systems robust to misinformation, a topic previously unexplored. We study the risk of misinformation to QA models by investigating the behavior of the QA model under contradicting contexts that are mixed with both real and fake information. We create the first large-scale dataset for this problem, namely Contra-QA, which contains over 10K human-written and model-generated contradicting pairs of contexts. Experiments show that QA models are vulnerable under contradicting contexts brought by misinformation. To defend against such a threat, we build a misinformation-aware QA system as a counter-measure that integrates question answering and misinformation detection in a joint fashion.
Application of Graph Convolutions in a Lightweight Model for Skeletal Human Motion Forecasting
Oct 10, 2021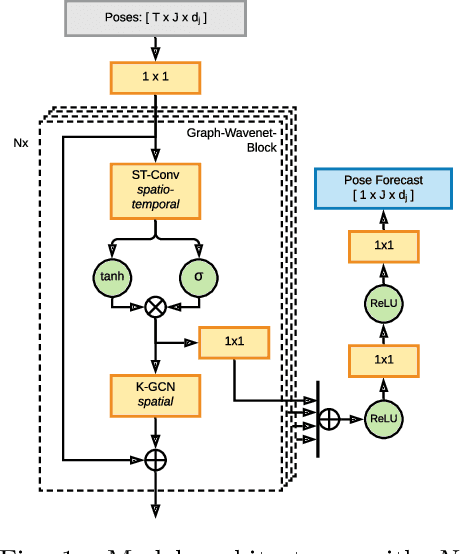
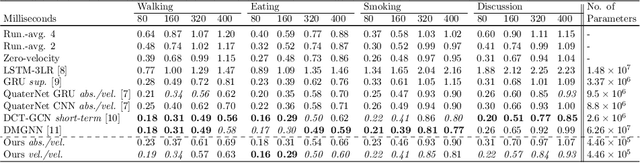
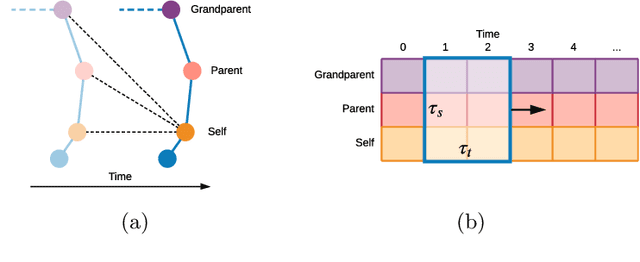
Prediction of movements is essential for successful cooperation with intelligent systems. We propose a model that integrates organized spatial information as given through the moving body's skeletal structure. This inherent structure is exploited in our model through application of Graph Convolutions and we demonstrate how this allows leveraging the structured spatial information into competitive predictions that are based on a lightweight model that requires a comparatively small number of parameters.
Temporal-Spatial Causal Interpretations for Vision-Based Reinforcement Learning
Dec 06, 2021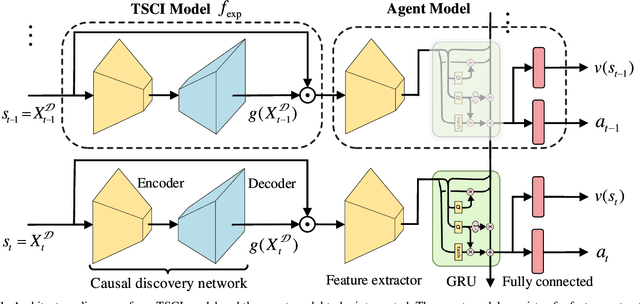

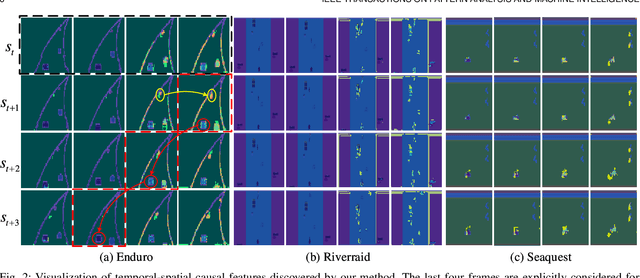
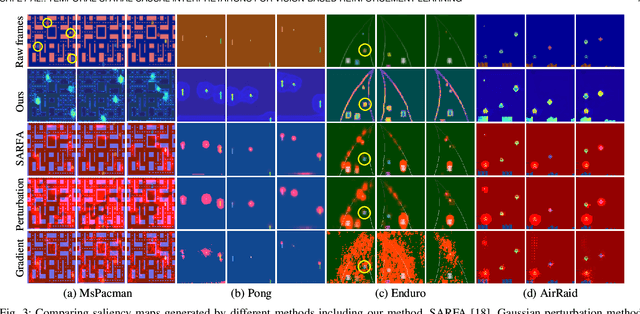
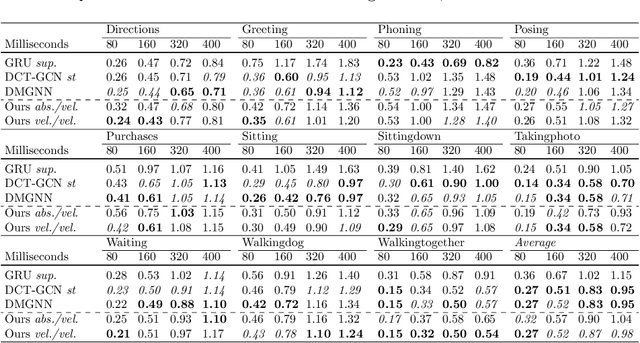
Deep reinforcement learning (RL) agents are becoming increasingly proficient in a range of complex control tasks. However, the agent's behavior is usually difficult to interpret due to the introduction of black-box function, making it difficult to acquire the trust of users. Although there have been some interesting interpretation methods for vision-based RL, most of them cannot uncover temporal causal information, raising questions about their reliability. To address this problem, we present a temporal-spatial causal interpretation (TSCI) model to understand the agent's long-term behavior, which is essential for sequential decision-making. TSCI model builds on the formulation of temporal causality, which reflects the temporal causal relations between sequential observations and decisions of RL agent. Then a separate causal discovery network is employed to identify temporal-spatial causal features, which are constrained to satisfy the temporal causality. TSCI model is applicable to recurrent agents and can be used to discover causal features with high efficiency once trained. The empirical results show that TSCI model can produce high-resolution and sharp attention masks to highlight task-relevant temporal-spatial information that constitutes most evidence about how vision-based RL agents make sequential decisions. In addition, we further demonstrate that our method is able to provide valuable causal interpretations for vision-based RL agents from the temporal perspective.
Leveraging Real Talking Faces via Self-Supervision for Robust Forgery Detection
Jan 18, 2022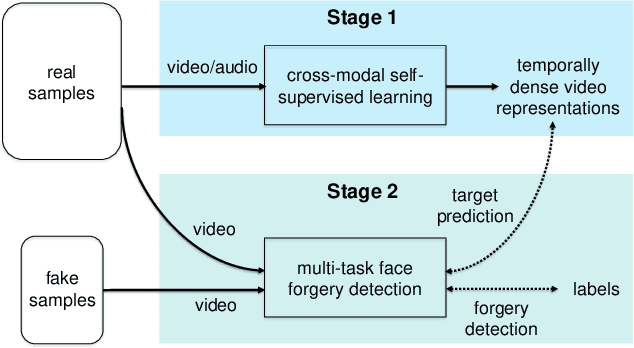
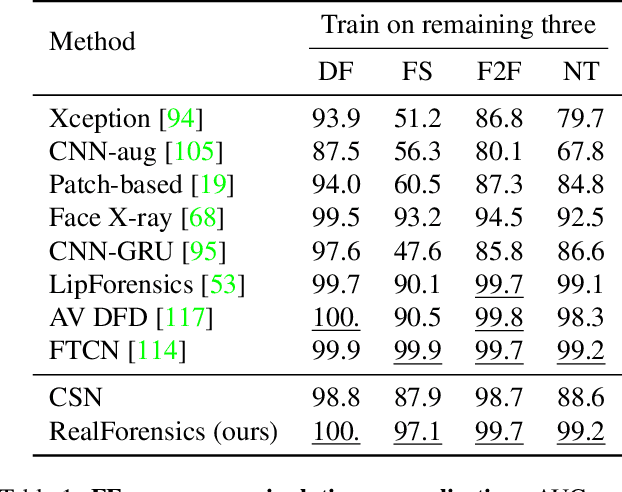

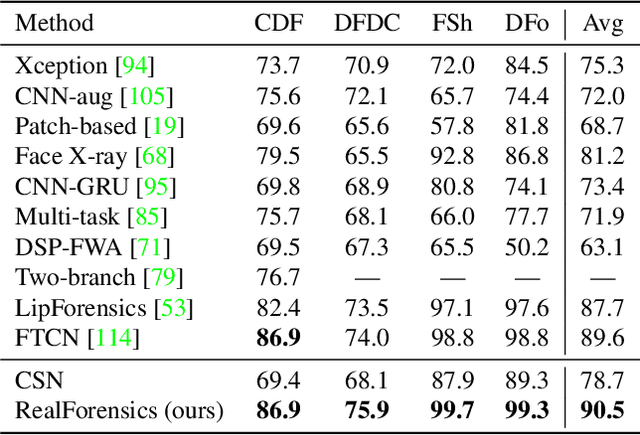
One of the most pressing challenges for the detection of face-manipulated videos is generalising to forgery methods not seen during training while remaining effective under common corruptions such as compression. In this paper, we question whether we can tackle this issue by harnessing videos of real talking faces, which contain rich information on natural facial appearance and behaviour and are readily available in large quantities online. Our method, termed RealForensics, consists of two stages. First, we exploit the natural correspondence between the visual and auditory modalities in real videos to learn, in a self-supervised cross-modal manner, temporally dense video representations that capture factors such as facial movements, expression, and identity. Second, we use these learned representations as targets to be predicted by our forgery detector along with the usual binary forgery classification task; this encourages it to base its real/fake decision on said factors. We show that our method achieves state-of-the-art performance on cross-manipulation generalisation and robustness experiments, and examine the factors that contribute to its performance. Our results suggest that leveraging natural and unlabelled videos is a promising direction for the development of more robust face forgery detectors.
Hashing with Mutual Information
Jun 25, 2018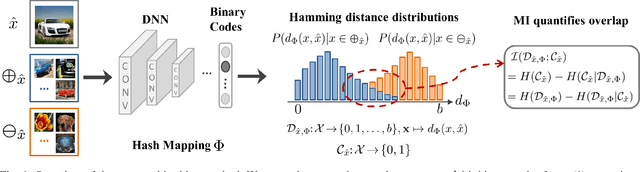
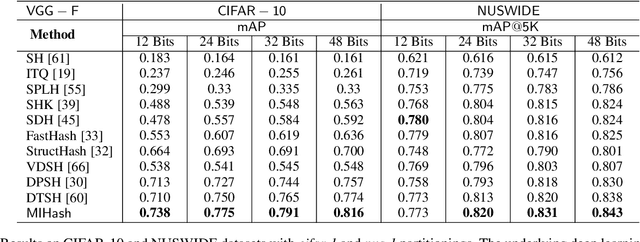
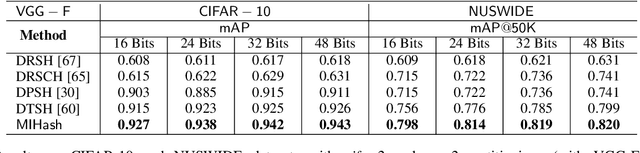
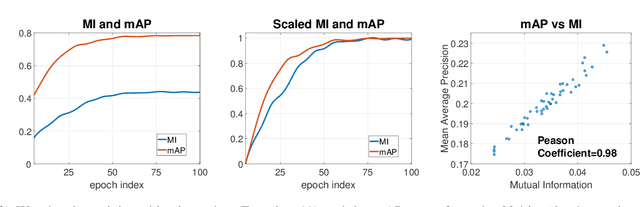
Binary vector embeddings enable fast nearest neighbor retrieval in large databases of high-dimensional objects, and play an important role in many practical applications, such as image and video retrieval. We study the problem of learning binary vector embeddings under a supervised setting, also known as hashing. We propose a novel supervised hashing method based on optimizing an information-theoretic quantity: mutual information. We show that optimizing mutual information can reduce ambiguity in the induced neighborhood structure in the learned Hamming space, which is essential in obtaining high retrieval performance. To this end, we optimize mutual information in deep neural networks with minibatch stochastic gradient descent, with a formulation that maximally and efficiently utilizes available supervision. Experiments on four image retrieval benchmarks, including ImageNet, confirm the effectiveness of our method in learning high-quality binary embeddings for nearest neighbor retrieval.