 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Structure from Silence: Learning Scene Structure from Ambient Sound
Nov 10, 2021
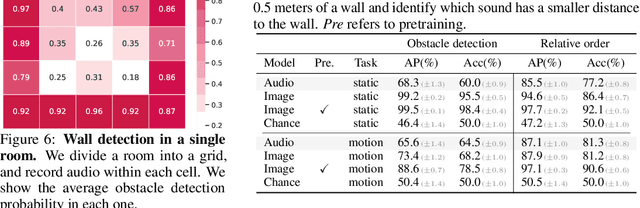

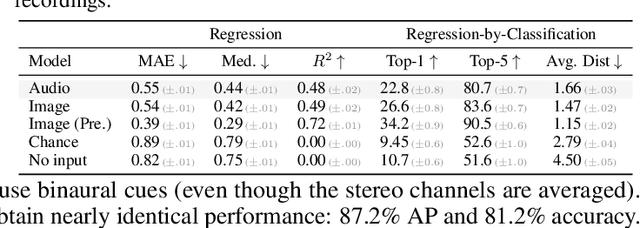
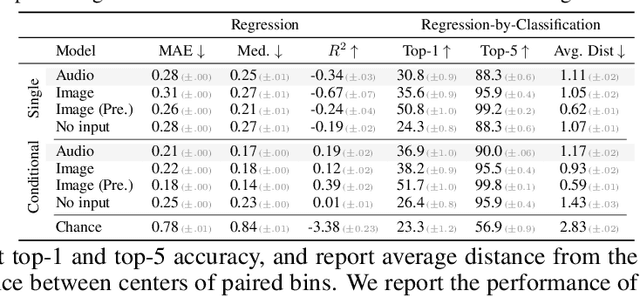
From whirling ceiling fans to ticking clocks, the sounds that we hear subtly vary as we move through a scene. We ask whether these ambient sounds convey information about 3D scene structure and, if so, whether they provide a useful learning signal for multimodal models. To study this, we collect a dataset of paired audio and RGB-D recordings from a variety of quiet indoor scenes. We then train models that estimate the distance to nearby walls, given only audio as input. We also use these recordings to learn multimodal representations through self-supervision, by training a network to associate images with their corresponding sounds. These results suggest that ambient sound conveys a surprising amount of information about scene structure, and that it is a useful signal for learning multimodal features.
Decoupling Makes Weakly Supervised Local Feature Better
Jan 08, 2022
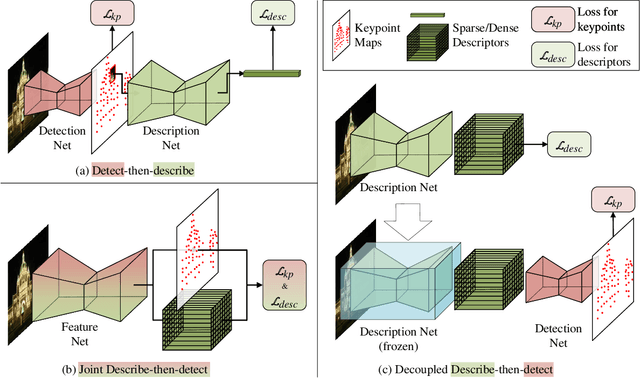

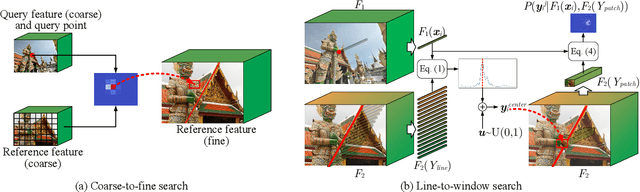
Weakly supervised learning can help local feature methods to overcome the obstacle of acquiring a large-scale dataset with densely labeled correspondences. However, since weak supervision cannot distinguish the losses caused by the detection and description steps, directly conducting weakly supervised learning within a joint describe-then-detect pipeline suffers limited performance. In this paper, we propose a decoupled describe-then-detect pipeline tailored for weakly supervised local feature learning. Within our pipeline, the detection step is decoupled from the description step and postponed until discriminative and robust descriptors are learned. In addition, we introduce a line-to-window search strategy to explicitly use the camera pose information for better descriptor learning. Extensive experiments show that our method, namely PoSFeat (Camera Pose Supervised Feature), outperforms previous fully and weakly supervised methods and achieves state-of-the-art performance on a wide range of downstream tasks.
Game of Privacy: Towards Better Federated Platform Collaboration under Privacy Restriction
Feb 10, 2022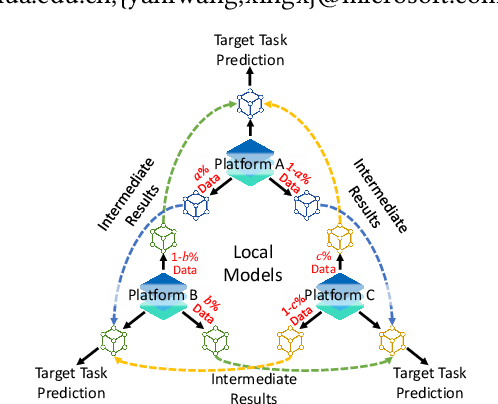
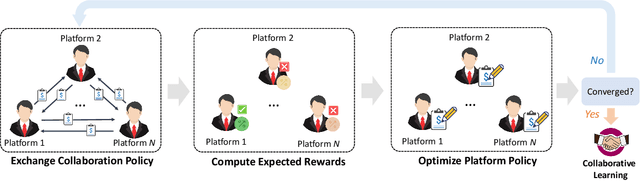
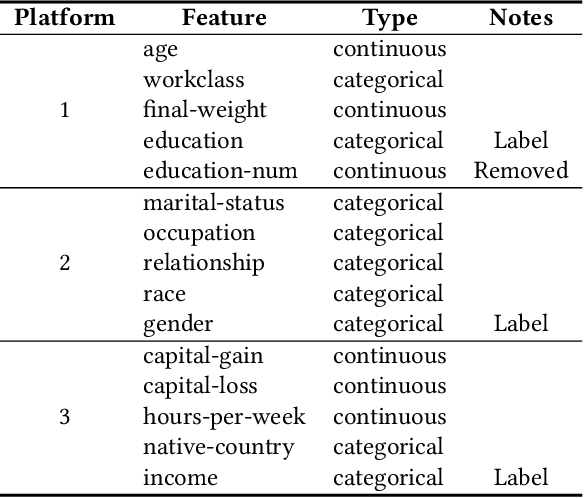
Vertical federated learning (VFL) aims to train models from cross-silo data with different feature spaces stored on different platforms. Existing VFL methods usually assume all data on each platform can be used for model training. However, due to the intrinsic privacy risks of federated learning, the total amount of involved data may be constrained. In addition, existing VFL studies usually assume only one platform has task labels and can benefit from the collaboration, making it difficult to attract other platforms to join in the collaborative learning. In this paper, we study the platform collaboration problem in VFL under privacy constraint. We propose to incent different platforms through a reciprocal collaboration, where all platforms can exploit multi-platform information in the VFL framework to benefit their own tasks. With limited privacy budgets, each platform needs to wisely allocate its data quotas for collaboration with other platforms. Thereby, they naturally form a multi-party game. There are two core problems in this game, i.e., how to appraise other platforms' data value to compute game rewards and how to optimize policies to solve the game. To evaluate the contributions of other platforms' data, each platform offers a small amount of "deposit" data to participate in the VFL. We propose a performance estimation method to predict the expected model performance when involving different amount combinations of inter-platform data. To solve the game, we propose a platform negotiation method that simulates the bargaining among platforms and locally optimizes their policies via gradient descent. Extensive experiments on two real-world datasets show that our approach can effectively facilitate the collaborative exploitation of multi-platform data in VFL under privacy restrictions.
SocialBERT -- Transformers for Online SocialNetwork Language Modelling
Nov 13, 2021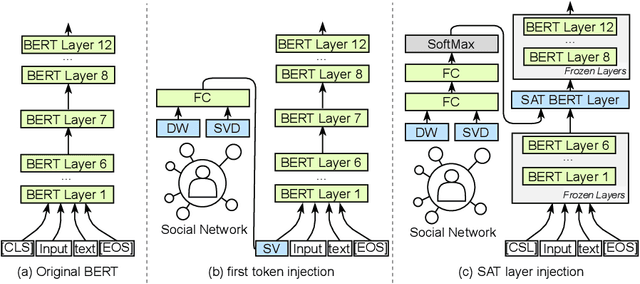

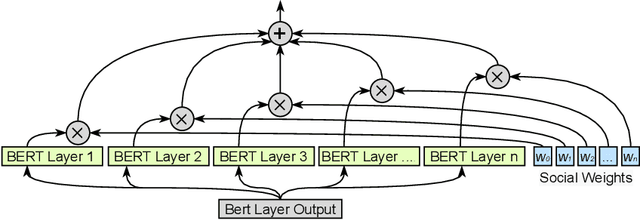

The ubiquity of the contemporary language understanding tasks gives relevance to the development of generalized, yet highly efficient models that utilize all knowledge, provided by the data source. In this work, we present SocialBERT - the first model that uses knowledge about the author's position in the network during text analysis. We investigate possible models for learning social network information and successfully inject it into the baseline BERT model. The evaluation shows that embedding this information maintains a good generalization, with an increase in the quality of the probabilistic model for the given author up to 7.5%. The proposed model has been trained on the majority of groups for the chosen social network, and still able to work with previously unknown groups. The obtained model, as well as the code of our experiments, is available for download and use in applied tasks.
Visualizing the diversity of representations learned by Bayesian neural networks
Jan 26, 2022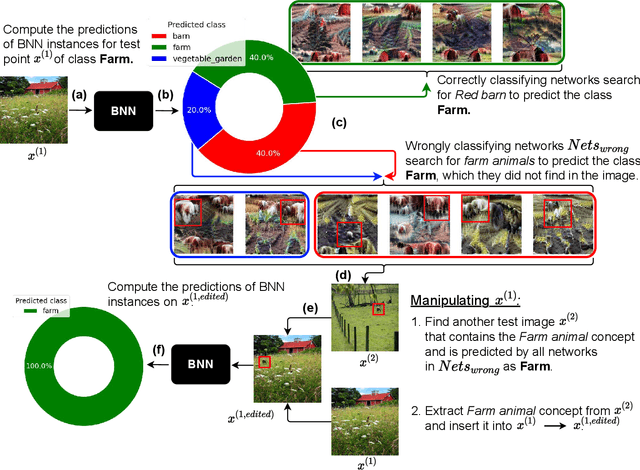
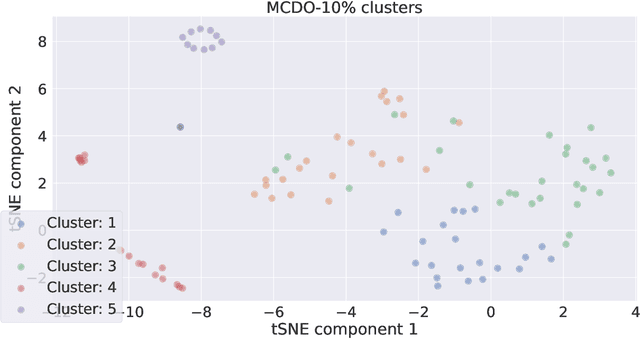


Explainable artificial intelligence (XAI) aims to make learning machines less opaque, and offers researchers and practitioners various tools to reveal the decision-making strategies of neural networks. In this work, we investigate how XAI methods can be used for exploring and visualizing the diversity of feature representations learned by Bayesian neural networks (BNNs). Our goal is to provide a global understanding of BNNs by making their decision-making strategies a) visible and tangible through feature visualizations and b) quantitatively measurable with a distance measure learned by contrastive learning. Our work provides new insights into the posterior distribution in terms of human-understandable feature information with regard to the underlying decision-making strategies. Our main findings are the following: 1) global XAI methods can be applied to explain the diversity of decision-making strategies of BNN instances, 2) Monte Carlo dropout exhibits increased diversity in feature representations compared to the multimodal posterior approximation of MultiSWAG, 3) the diversity of learned feature representations highly correlates with the uncertainty estimates, and 4) the inter-mode diversity of the multimodal posterior decreases as the network width increases, while the intra-mode diversity increases. Our findings are consistent with the recent deep neural networks theory, providing additional intuitions about what the theory implies in terms of humanly understandable concepts.
CRIS: CLIP-Driven Referring Image Segmentation
Nov 30, 2021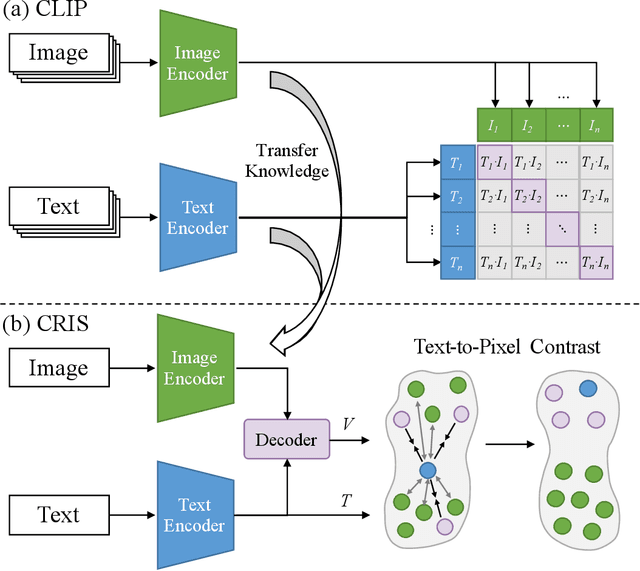
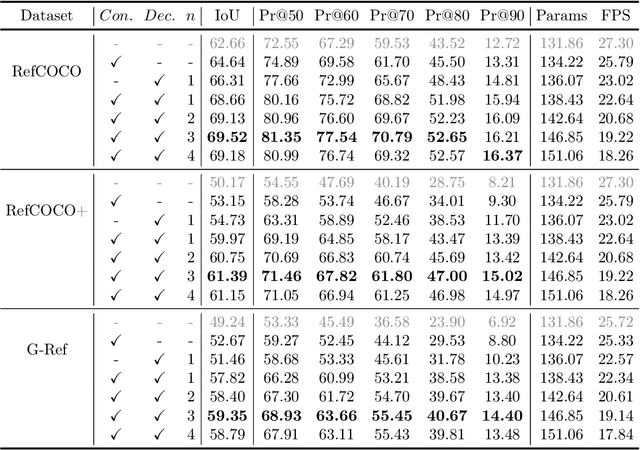

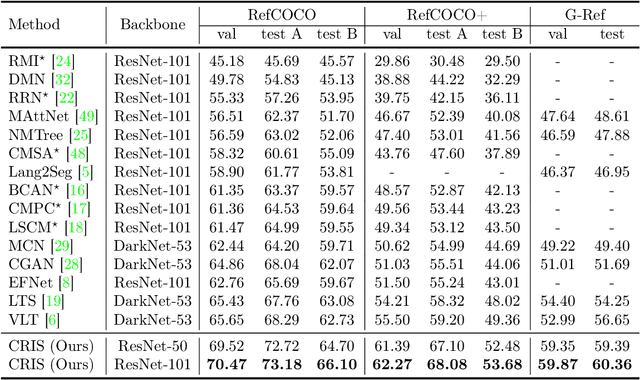
Referring image segmentation aims to segment a referent via a natural linguistic expression.Due to the distinct data properties between text and image, it is challenging for a network to well align text and pixel-level features. Existing approaches use pretrained models to facilitate learning, yet separately transfer the language/vision knowledge from pretrained models, ignoring the multi-modal corresponding information. Inspired by the recent advance in Contrastive Language-Image Pretraining (CLIP), in this paper, we propose an end-to-end CLIP-Driven Referring Image Segmentation framework (CRIS). To transfer the multi-modal knowledge effectively, CRIS resorts to vision-language decoding and contrastive learning for achieving the text-to-pixel alignment. More specifically, we design a vision-language decoder to propagate fine-grained semantic information from textual representations to each pixel-level activation, which promotes consistency between the two modalities. In addition, we present text-to-pixel contrastive learning to explicitly enforce the text feature similar to the related pixel-level features and dissimilar to the irrelevances. The experimental results on three benchmark datasets demonstrate that our proposed framework significantly outperforms the state-of-the-art performance without any post-processing. The code will be released.
A Partial Channel Reciprocity-based Codebook for Wideband FDD Massive MIMO
Jan 26, 2022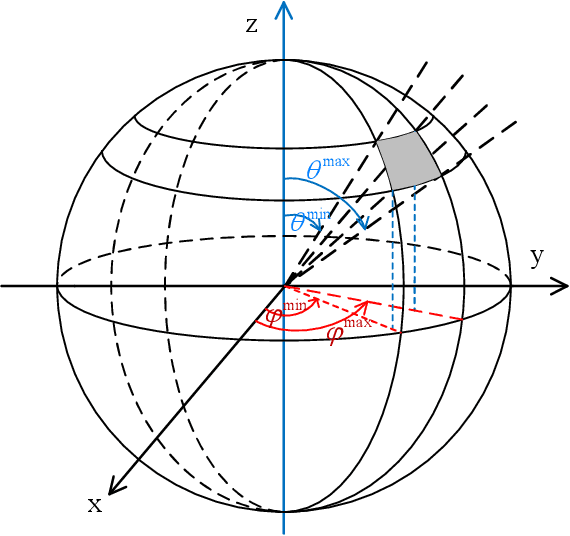
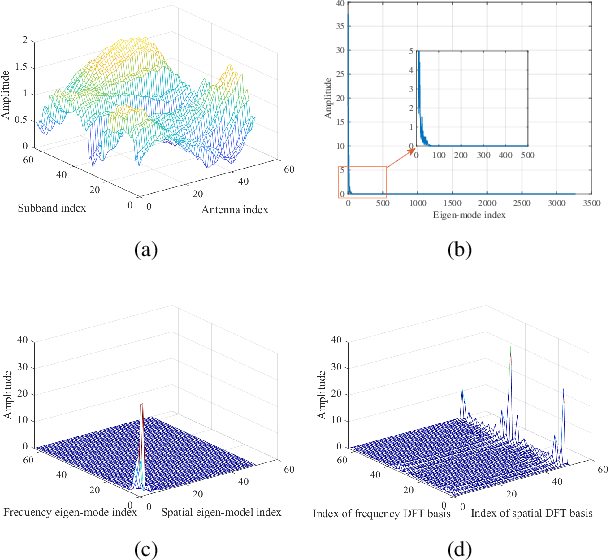
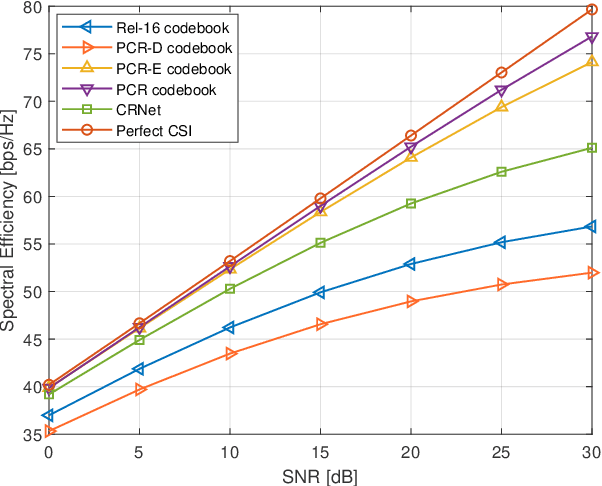
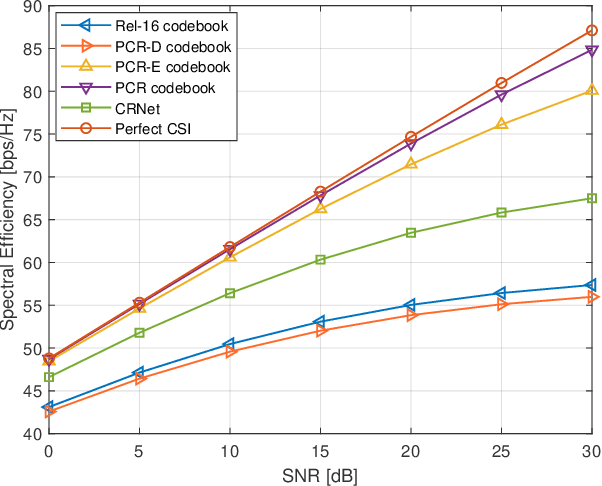
The acquisition of channel state information (CSI) in Frequency Division Duplex (FDD) massive MIMO has been a formidable challenge. In this paper, we address this problem with a novel CSI feedback framework enabled by the partial reciprocity of uplink and downlink channels in the wideband regime. We first derive the closed-form expression of the rank of the wideband massive MIMO channel covariance matrix for a given angle-delay distribution. A low-rankness property is identified, which generalizes the well-known result of the narrow-band uniform linear array setting. Then we propose a partial channel reciprocity (PCR) codebook, inspired by the low-rankness behavior and the fact that the uplink and downlink channels have similar angle-delay distributions. Compared to the latest codebook in 5G, the proposed PCR codebook scheme achieves higher performance, lower complexity at the user side, and requires a smaller amount of feedback. We derive the feedback overhead necessary to achieve asymptotically error-free CSI feedback. Two low-complexity alternatives are also proposed to further reduce the complexity at the base station side. Simulations with the practical 3GPP channel model show the significant gains over the latest 5G codebook, which prove that our proposed methods are practical solutions for 5G and beyond.
Zero-Shot and Few-Shot Classification of Biomedical Articles in Context of the COVID-19 Pandemic
Jan 11, 2022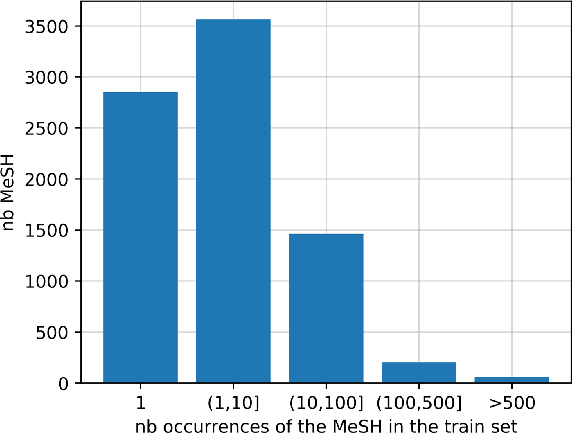
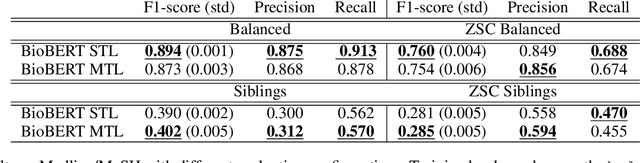
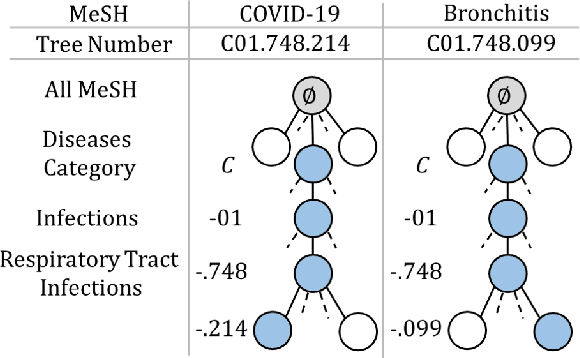
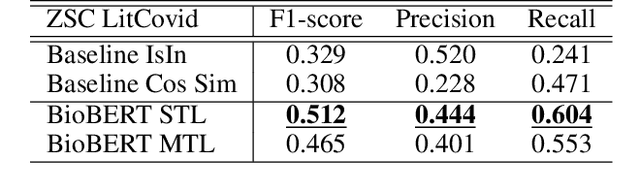
MeSH (Medical Subject Headings) is a large thesaurus created by the National Library of Medicine and used for fine-grained indexing of publications in the biomedical domain. In the context of the COVID-19 pandemic, MeSH descriptors have emerged in relation to articles published on the corresponding topic. Zero-shot classification is an adequate response for timely labeling of the stream of papers with MeSH categories. In this work, we hypothesise that rich semantic information available in MeSH has potential to improve BioBERT representations and make them more suitable for zero-shot/few-shot tasks. We frame the problem as determining if MeSH term definitions, concatenated with paper abstracts are valid instances or not, and leverage multi-task learning to induce the MeSH hierarchy in the representations thanks to a seq2seq task. Results establish a baseline on the MedLine and LitCovid datasets, and probing shows that the resulting representations convey the hierarchical relations present in MeSH.
GreaseLM: Graph REASoning Enhanced Language Models for Question Answering
Jan 21, 2022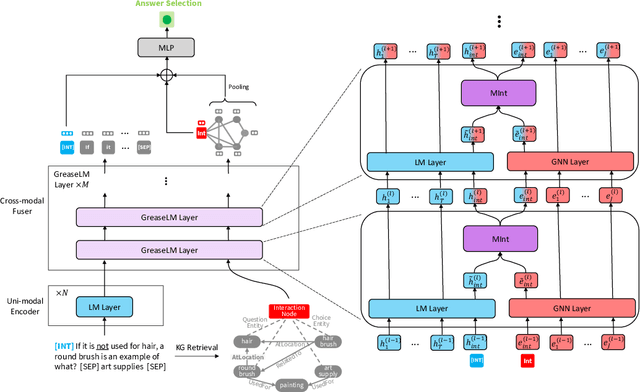

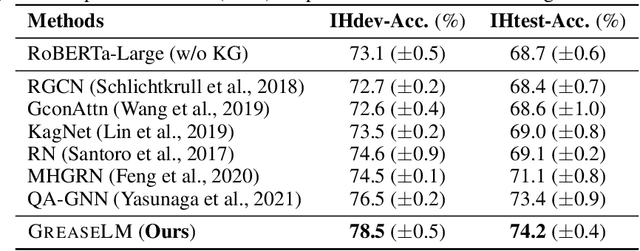
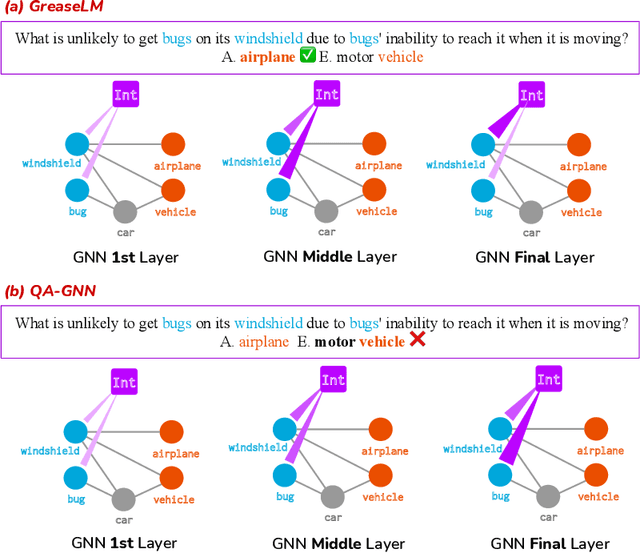
Answering complex questions about textual narratives requires reasoning over both stated context and the world knowledge that underlies it. However, pretrained language models (LM), the foundation of most modern QA systems, do not robustly represent latent relationships between concepts, which is necessary for reasoning. While knowledge graphs (KG) are often used to augment LMs with structured representations of world knowledge, it remains an open question how to effectively fuse and reason over the KG representations and the language context, which provides situational constraints and nuances. In this work, we propose GreaseLM, a new model that fuses encoded representations from pretrained LMs and graph neural networks over multiple layers of modality interaction operations. Information from both modalities propagates to the other, allowing language context representations to be grounded by structured world knowledge, and allowing linguistic nuances (e.g., negation, hedging) in the context to inform the graph representations of knowledge. Our results on three benchmarks in the commonsense reasoning (i.e., CommonsenseQA, OpenbookQA) and medical question answering (i.e., MedQA-USMLE) domains demonstrate that GreaseLM can more reliably answer questions that require reasoning over both situational constraints and structured knowledge, even outperforming models 8x larger.
Bandwidth and Power Allocation for Task-Oriented SemanticCommunication
Jan 26, 2022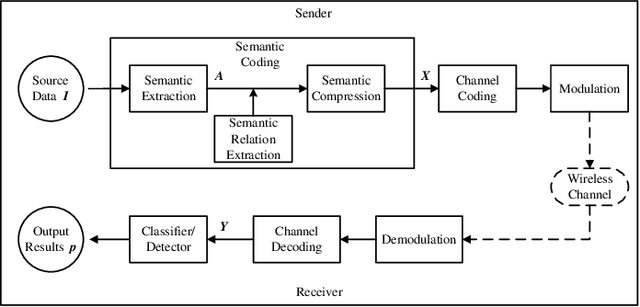
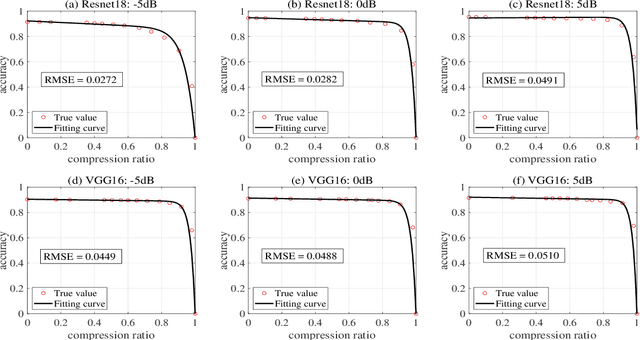
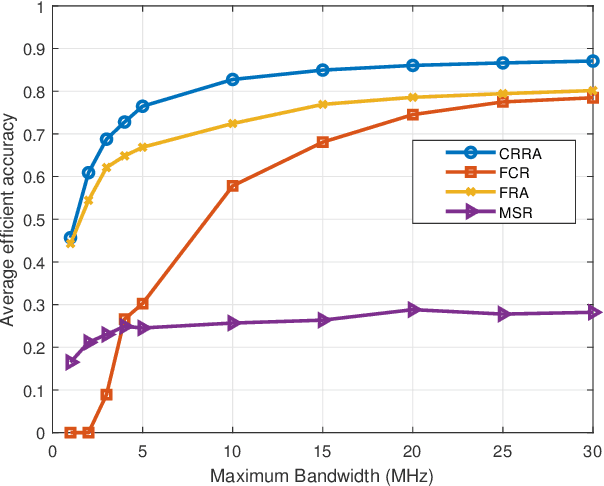
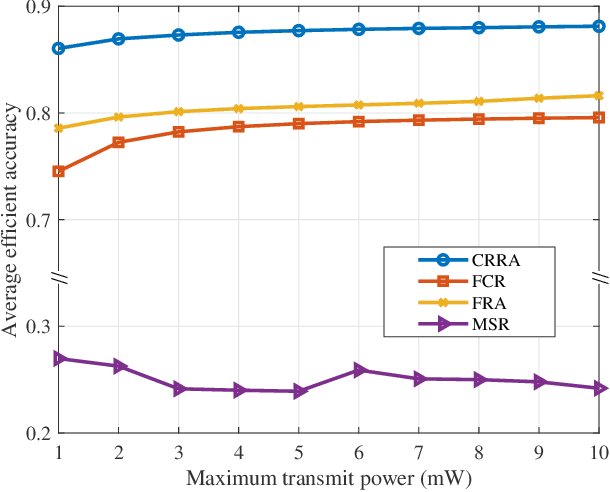
Deep learning enabled semantic communication has been studied to improve communication efficiency while guaranteeing intelligent task performance. Different from conventional communications systems, the resource allocation in semantic communications no longer just pursues the bit transmission rate, but focuses on how to better compress and transmit semantic to complete subsequent intelligent tasks. This paper aims to appropriately allocate the bandwidth and power for artificial intelligence (AI) task-oriented semantic communication and proposes a joint compressiom ratio and resource allocation (CRRA) algorithm. We first analyze the relationship between the AI task's performance and the semantic information. Then, to optimize the AI task's perfomance under resource constraints, a bandwidth and power allocation problem is formulated. The problem is first separated into two subproblems due to the non-convexity. The first subproblem is a compression ratio optimization problem with a given resource allocation scheme, which is solved by a enumeration algorithm. The second subproblem is to find the optimal resource allocation scheme, which is transformed into a convex problem by successive convex approximation method, and solved by a convex optimization method. The optimal semantic compression ratio and resource allocation scheme are obtained by iteratively solving these two subproblems. Simulation results show that the proposed algorithm can efficiently improve the AI task's performance by up to 30\% comprared with baselines.