 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Information Directed Sampling for Linear Partial Monitoring
Feb 25, 2020
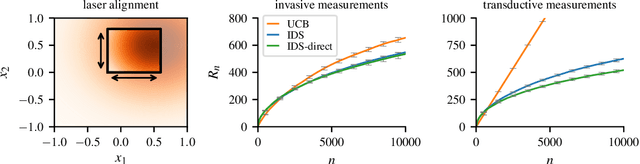
Partial monitoring is a rich framework for sequential decision making under uncertainty that generalizes many well known bandit models, including linear, combinatorial and dueling bandits. We introduce information directed sampling (IDS) for stochastic partial monitoring with a linear reward and observation structure. IDS achieves adaptive worst-case regret rates that depend on precise observability conditions of the game. Moreover, we prove lower bounds that classify the minimax regret of all finite games into four possible regimes. IDS achieves the optimal rate in all cases up to logarithmic factors, without tuning any hyper-parameters. We further extend our results to the contextual and the kernelized setting, which significantly increases the range of possible applications.
Using Deep Learning to Bootstrap Abstractions for Hierarchical Robot Planning
Feb 02, 2022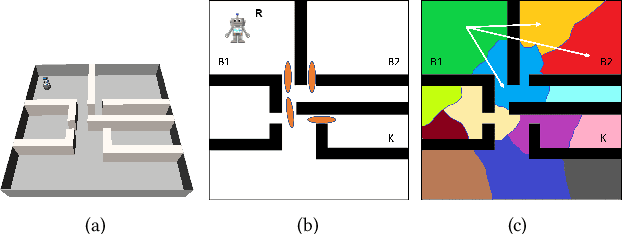
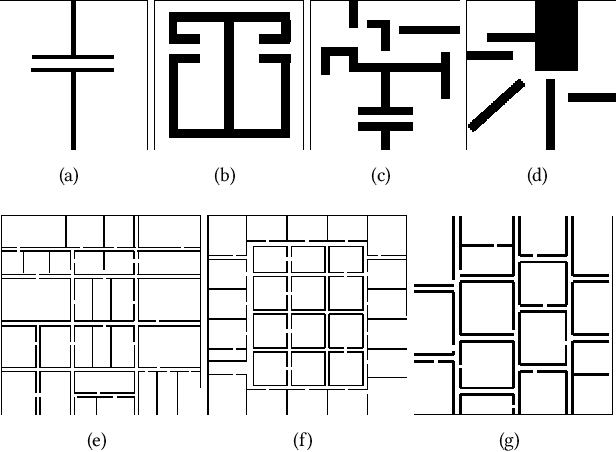
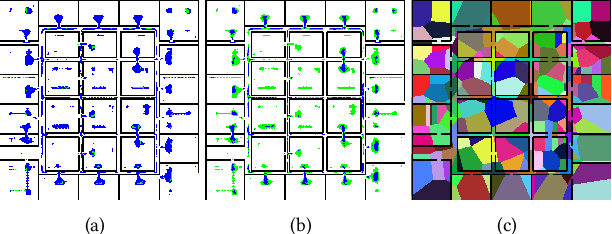
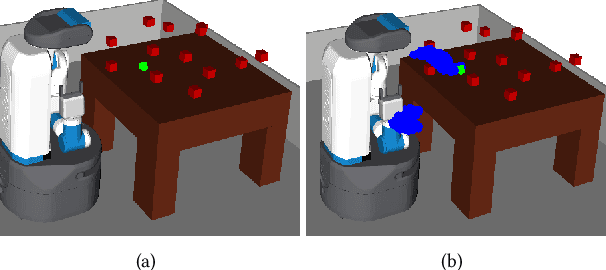
This paper addresses the problem of learning abstractions that boost robot planning performance while providing strong guarantees of reliability. Although state-of-the-art hierarchical robot planning algorithms allow robots to efficiently compute long-horizon motion plans for achieving user desired tasks, these methods typically rely upon environment-dependent state and action abstractions that need to be hand-designed by experts. We present a new approach for bootstrapping the entire hierarchical planning process. It shows how abstract states and actions for new environments can be computed automatically using the critical regions predicted by a deep neural-network with an auto-generated robot specific architecture. It uses the learned abstractions in a novel multi-source bi-directional hierarchical robot planning algorithm that is sound and probabilistically complete. An extensive empirical evaluation on twenty different settings using holonomic and non-holonomic robots shows that (a) the learned abstractions provide the information necessary for efficient multi-source hierarchical planning; and that (b) this approach of learning abstraction and planning outperforms state-of-the-art baselines by nearly a factor of ten in terms of planning time on test environments not seen during training.
A Pre-trained Audio-Visual Transformer for Emotion Recognition
Jan 23, 2022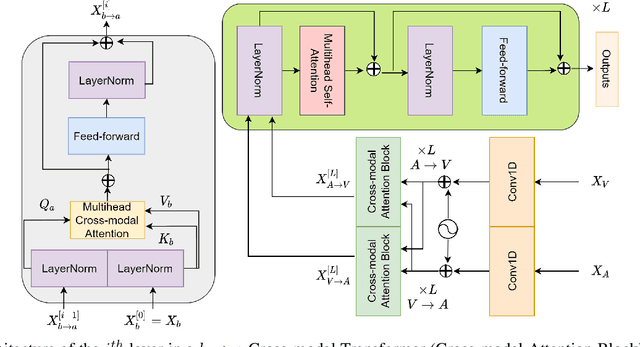
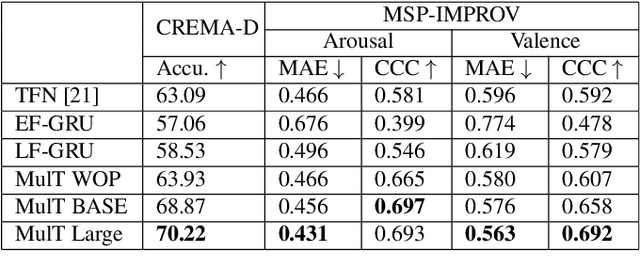
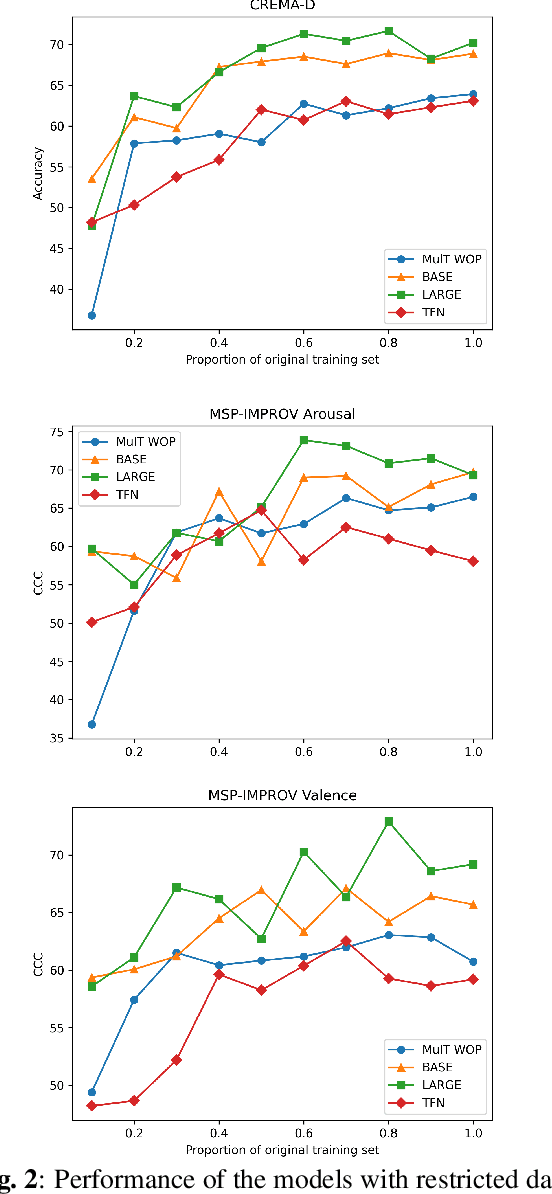
In this paper, we introduce a pretrained audio-visual Transformer trained on more than 500k utterances from nearly 4000 celebrities from the VoxCeleb2 dataset for human behavior understanding. The model aims to capture and extract useful information from the interactions between human facial and auditory behaviors, with application in emotion recognition. We evaluate the model performance on two datasets, namely CREMAD-D (emotion classification) and MSP-IMPROV (continuous emotion regression). Experimental results show that fine-tuning the pre-trained model helps improving emotion classification accuracy by 5-7% and Concordance Correlation Coefficients (CCC) in continuous emotion recognition by 0.03-0.09 compared to the same model trained from scratch. We also demonstrate the robustness of finetuning the pre-trained model in a low-resource setting. With only 10% of the original training set provided, fine-tuning the pre-trained model can lead to at least 10% better emotion recognition accuracy and a CCC score improvement by at least 0.1 for continuous emotion recognition.
WiFi-based Multi-task Sensing
Nov 26, 2021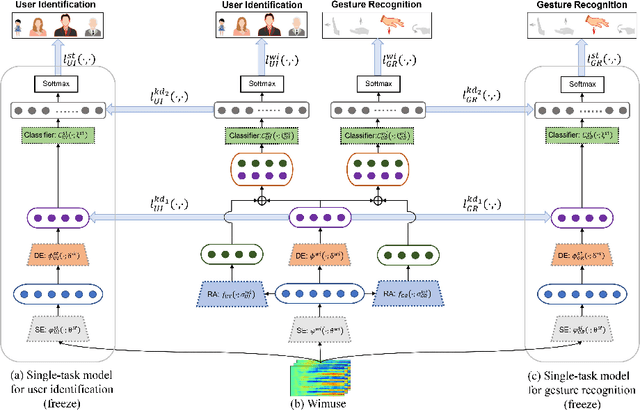
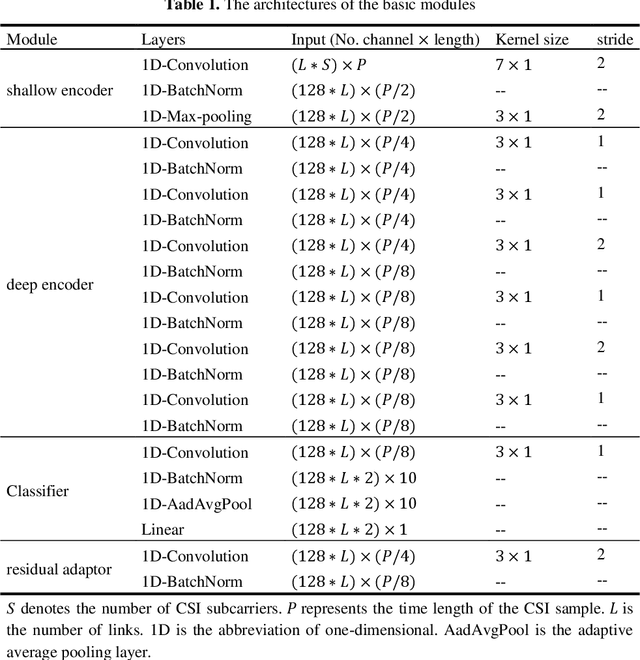
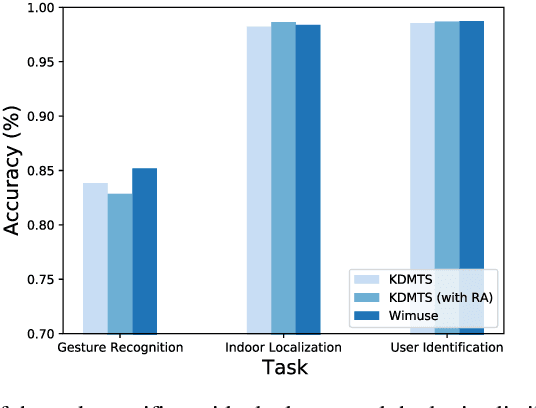
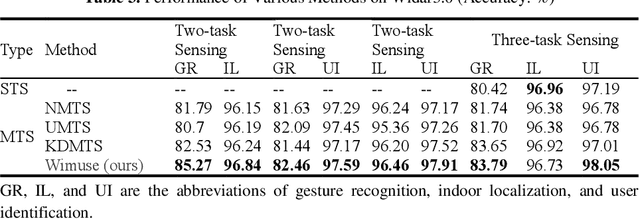
WiFi-based sensing has aroused immense attention over recent years. The rationale is that the signal fluctuations caused by humans carry the information of human behavior which can be extracted from the channel state information of WiFi. Still, the prior studies mainly focus on single-task sensing (STS), e.g., gesture recognition, indoor localization, user identification. Since the fluctuations caused by gestures are highly coupling with body features and the user's location, we propose a WiFi-based multi-task sensing model (Wimuse) to perform gesture recognition, indoor localization, and user identification tasks simultaneously. However, these tasks have different difficulty levels (i.e., imbalance issue) and need task-specific information (i.e., discrepancy issue). To address these issues, the knowledge distillation technique and task-specific residual adaptor are adopted in Wimuse. We first train the STS model for each task. Then, for solving the imbalance issue, the extracted common feature in Wimuse is encouraged to get close to the counterpart features of the STS models. Further, for each task, a task-specific residual adaptor is applied to extract the task-specific compensation feature which is fused with the common feature to address the discrepancy issue. We conduct comprehensive experiments on three public datasets and evaluation suggests that Wimuse achieves state-of-the-art performance with the average accuracy of 85.20%, 98.39%, and 98.725% on the joint task of gesture recognition, indoor localization, and user identification, respectively.
Hybrid Contrastive Learning with Cluster Ensemble for Unsupervised Person Re-identification
Jan 28, 2022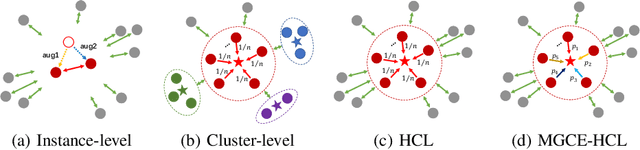
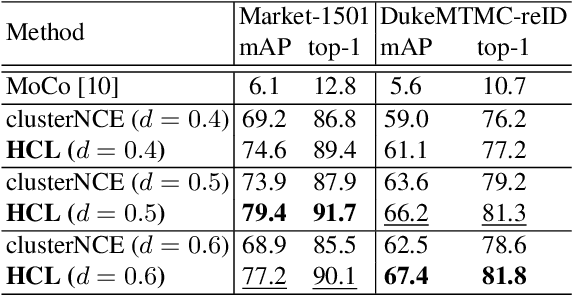
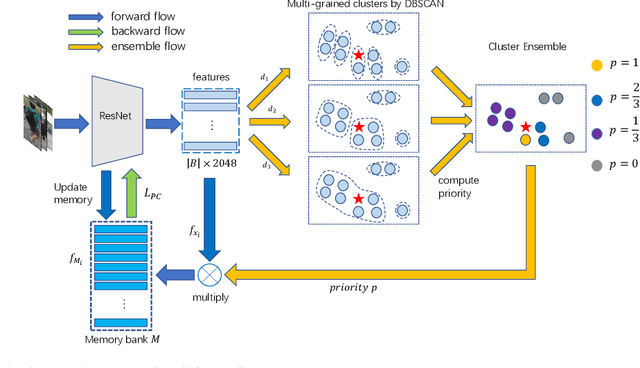
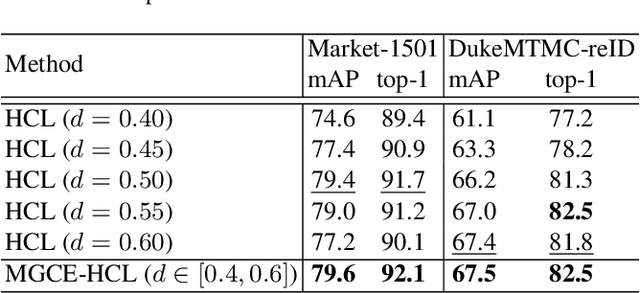
Unsupervised person re-identification (ReID) aims to match a query image of a pedestrian to the images in gallery set without supervision labels. The most popular approaches to tackle unsupervised person ReID are usually performing a clustering algorithm to yield pseudo labels at first and then exploit the pseudo labels to train a deep neural network. However, the pseudo labels are noisy and sensitive to the hyper-parameter(s) in clustering algorithm. In this paper, we propose a Hybrid Contrastive Learning (HCL) approach for unsupervised person ReID, which is based on a hybrid between instance-level and cluster-level contrastive loss functions. Moreover, we present a Multi-Granularity Clustering Ensemble based Hybrid Contrastive Learning (MGCE-HCL) approach, which adopts a multi-granularity clustering ensemble strategy to mine priority information among the pseudo positive sample pairs and defines a priority-weighted hybrid contrastive loss for better tolerating the noises in the pseudo positive samples. We conduct extensive experiments on two benchmark datasets Market-1501 and DukeMTMC-reID. Experimental results validate the effectiveness of our proposals.
Deep Networks for Image and Video Super-Resolution
Jan 28, 2022



Efficiency of gradient propagation in intermediate layers of convolutional neural networks is of key importance for super-resolution task. To this end, we propose a deep architecture for single image super-resolution (SISR), which is built using efficient convolutional units we refer to as mixed-dense connection blocks (MDCB). The design of MDCB combines the strengths of both residual and dense connection strategies, while overcoming their limitations. To enable super-resolution for multiple factors, we propose a scale-recurrent framework which reutilizes the filters learnt for lower scale factors recursively for higher factors. This leads to improved performance and promotes parametric efficiency for higher factors. We train two versions of our network to enhance complementary image qualities using different loss configurations. We further employ our network for video super-resolution task, where our network learns to aggregate information from multiple frames and maintain spatio-temporal consistency. The proposed networks lead to qualitative and quantitative improvements over state-of-the-art techniques on image and video super-resolution benchmarks.
A Novel Covert Communication Method using Ambient Backscatter Communications
Jan 17, 2022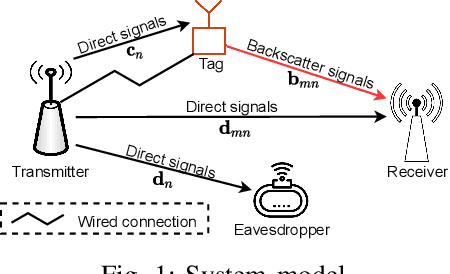
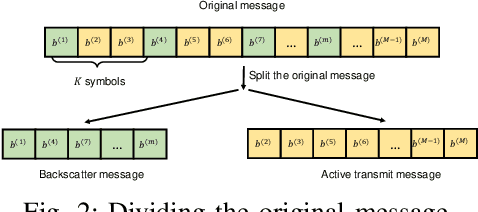
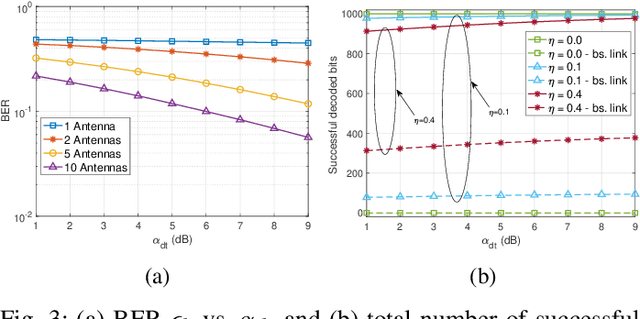
This paper introduces a novel solution to enable covert communication in wireless systems by using ambient backscatter communication technology. In the considered system, the original message at the transmitter is first divided into two parts: (i) active transmit message and (ii) backscatter message. Then, the active transmit message is transmitted by using the conventional wireless transmission method while the backscatter message is transmitted by backscattering the active transmit signals via an ambient backscatter tag. As the backscatter tag does not generate any active signals, it is intractable for the adversary to detect the backscatter message. Therefore, secret information, e.g., secret key for decryption, can be carried by the backscattered message, making the adversary unable to decode the original message. Simulation results demonstrate that our proposed solution can help to significantly enhance security protection for communication systems.
SCROLLS: Standardized CompaRison Over Long Language Sequences
Jan 10, 2022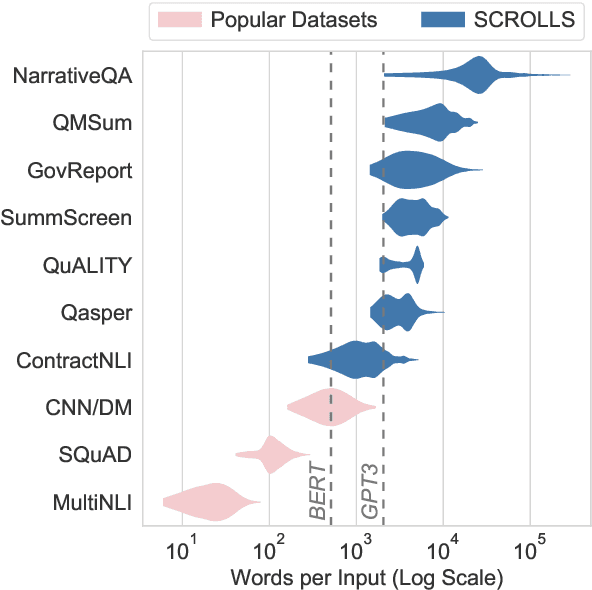
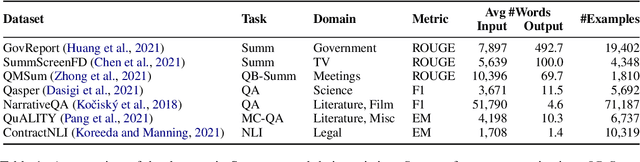

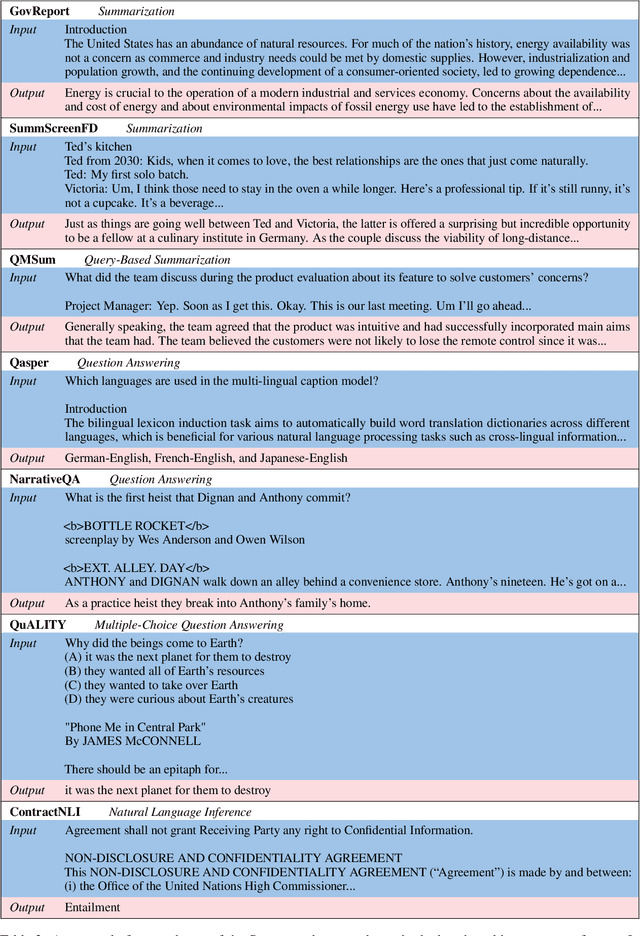
NLP benchmarks have largely focused on short texts, such as sentences and paragraphs, even though long texts comprise a considerable amount of natural language in the wild. We introduce SCROLLS, a suite of tasks that require reasoning over long texts. We examine existing long-text datasets, and handpick ones where the text is naturally long, while prioritizing tasks that involve synthesizing information across the input. SCROLLS contains summarization, question answering, and natural language inference tasks, covering multiple domains, including literature, science, business, and entertainment. Initial baselines, including Longformer Encoder-Decoder, indicate that there is ample room for improvement on SCROLLS. We make all datasets available in a unified text-to-text format and host a live leaderboard to facilitate research on model architecture and pretraining methods.
A pragmatic account of the weak evidence effect
Dec 07, 2021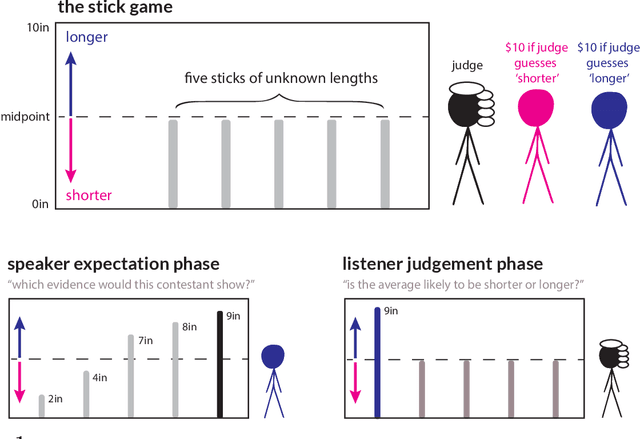
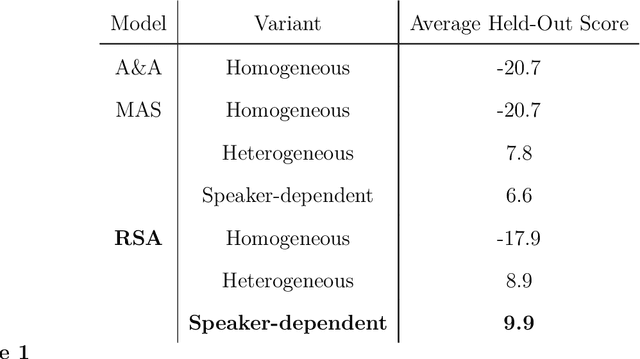
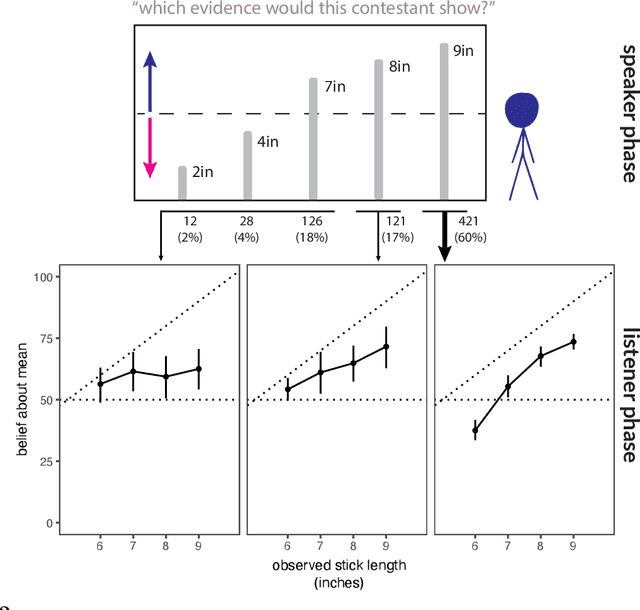
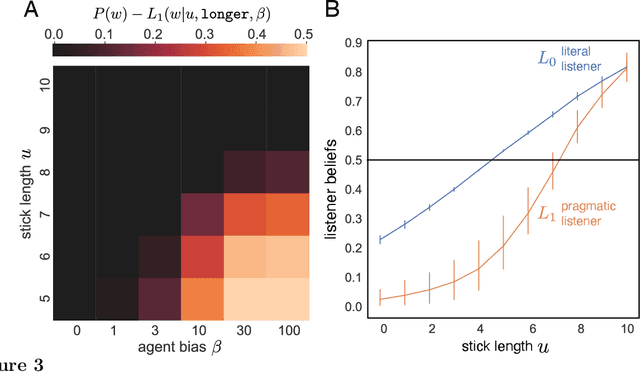
Language is not only used to inform. We often seek to persuade by arguing in favor of a particular view. Persuasion raises a number of challenges for classical accounts of belief updating, as information cannot be taken at face value. How should listeners account for a speaker's "hidden agenda" when incorporating new information? Here, we extend recent probabilistic models of recursive social reasoning to allow for persuasive goals and show that our model provides a new pragmatic explanation for why weakly favorable arguments may backfire, a phenomenon known as the weak evidence effect. Critically, our model predicts a relationship between belief updating and speaker expectations: weak evidence should only backfire when speakers are expected to act under persuasive goals, implying the absence of stronger evidence. We introduce a simple experimental paradigm called the Stick Contest to measure the extent to which the weak evidence effect depends on speaker expectations, and show that a pragmatic listener model accounts for the empirical data better than alternative models. Our findings suggest potential avenues for rational models of social reasoning to further illuminate decision-making phenomena.
Distributed Adaptive Learning Under Communication Constraints
Dec 03, 2021
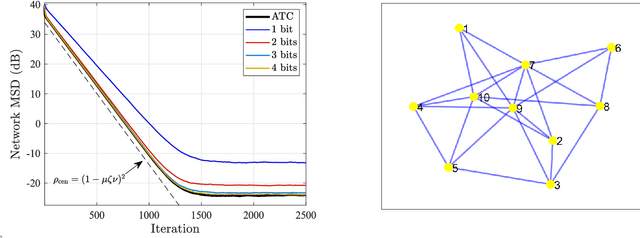
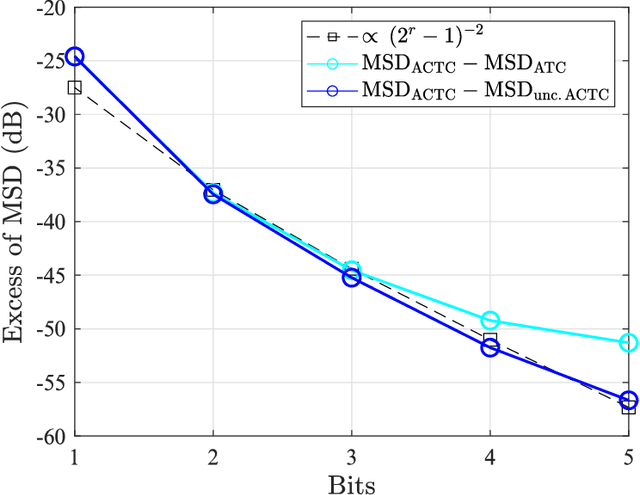
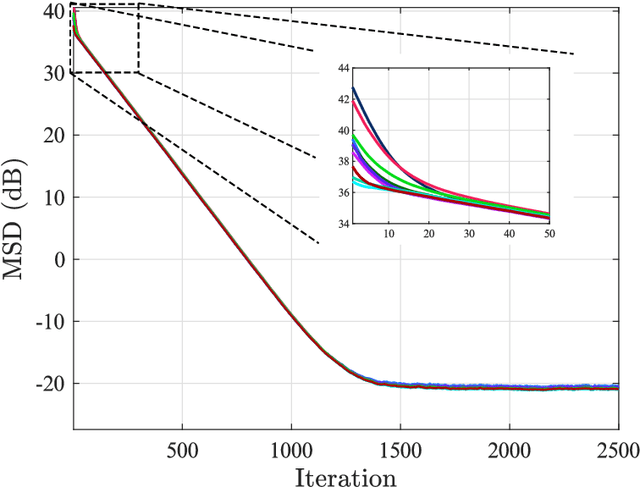
This work examines adaptive distributed learning strategies designed to operate under communication constraints. We consider a network of agents that must solve an online optimization problem from continual observation of streaming data. The agents implement a distributed cooperative strategy where each agent is allowed to perform local exchange of information with its neighbors. In order to cope with communication constraints, the exchanged information must be unavoidably compressed. We propose a diffusion strategy nicknamed as ACTC (Adapt-Compress-Then-Combine), which relies on the following steps: i) an adaptation step where each agent performs an individual stochastic-gradient update with constant step-size; ii) a compression step that leverages a recently introduced class of stochastic compression operators; and iii) a combination step where each agent combines the compressed updates received from its neighbors. The distinguishing elements of this work are as follows. First, we focus on adaptive strategies, where constant (as opposed to diminishing) step-sizes are critical to respond in real time to nonstationary variations. Second, we consider the general class of directed graphs and left-stochastic combination policies, which allow us to enhance the interplay between topology and learning. Third, in contrast with related works that assume strong convexity for all individual agents' cost functions, we require strong convexity only at a network level, a condition satisfied even if a single agent has a strongly-convex cost and the remaining agents have non-convex costs. Fourth, we focus on a diffusion (as opposed to consensus) strategy. Under the demanding setting of compressed information, we establish that the ACTC iterates fluctuate around the desired optimizer, achieving remarkable savings in terms of bits exchanged between neighboring agents.