 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Improved Input Reprogramming for GAN Conditioning
Feb 07, 2022


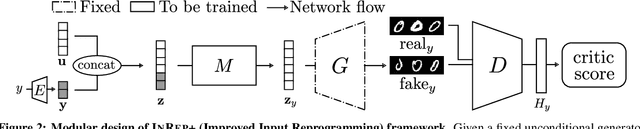
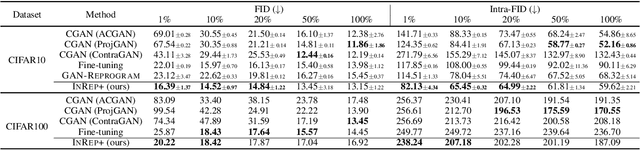
We study the GAN conditioning problem, whose goal is to convert a pretrained unconditional GAN into a conditional GAN using labeled data. We first identify and analyze three approaches to this problem -- conditional GAN training from scratch, fine-tuning, and input reprogramming. Our analysis reveals that when the amount of labeled data is small, input reprogramming performs the best. Motivated by real-world scenarios with scarce labeled data, we focus on the input reprogramming approach and carefully analyze the existing algorithm. After identifying a few critical issues of the previous input reprogramming approach, we propose a new algorithm called InRep+. Our algorithm InRep+ addresses the existing issues with the novel uses of invertible neural networks and Positive-Unlabeled (PU) learning. Via extensive experiments, we show that InRep+ outperforms all existing methods, particularly when label information is scarce, noisy, and/or imbalanced. For instance, for the task of conditioning a CIFAR10 GAN with 1% labeled data, InRep+ achieves an average Intra-FID of 76.24, whereas the second-best method achieves 114.51.
The Effect of Model Size on Worst-Group Generalization
Dec 08, 2021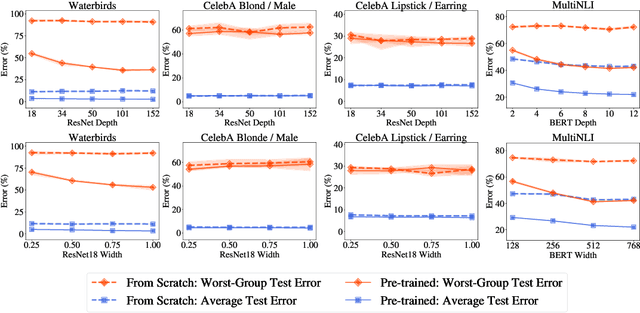
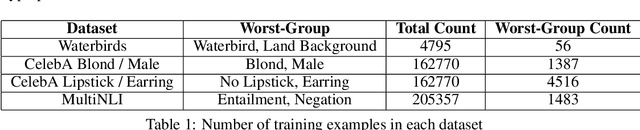
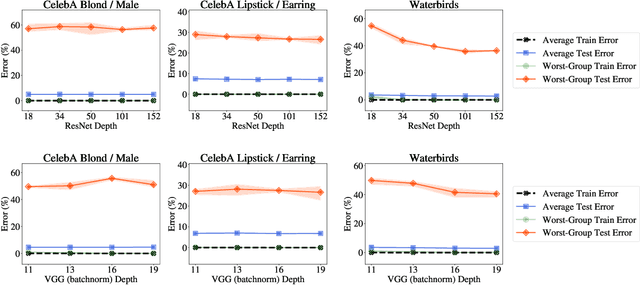
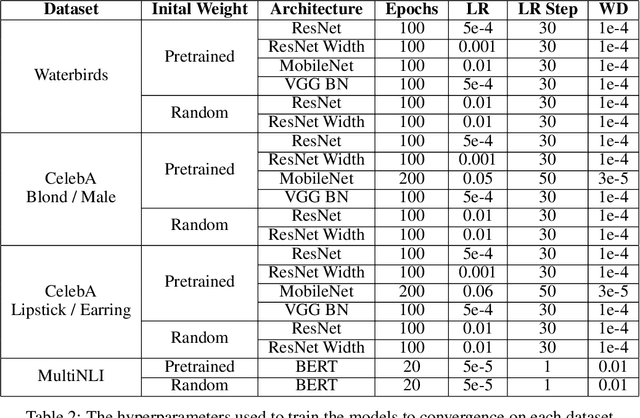
Overparameterization is shown to result in poor test accuracy on rare subgroups under a variety of settings where subgroup information is known. To gain a more complete picture, we consider the case where subgroup information is unknown. We investigate the effect of model size on worst-group generalization under empirical risk minimization (ERM) across a wide range of settings, varying: 1) architectures (ResNet, VGG, or BERT), 2) domains (vision or natural language processing), 3) model size (width or depth), and 4) initialization (with pre-trained or random weights). Our systematic evaluation reveals that increasing model size does not hurt, and may help, worst-group test performance under ERM across all setups. In particular, increasing pre-trained model size consistently improves performance on Waterbirds and MultiNLI. We advise practitioners to use larger pre-trained models when subgroup labels are unknown.
Information-Theoretic Generalization Bounds for Meta-Learning and Applications
May 14, 2020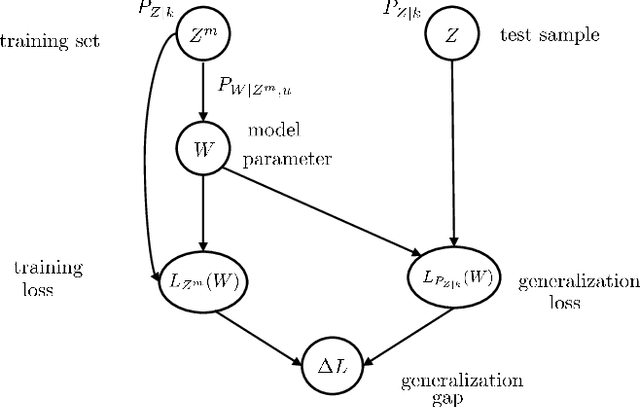
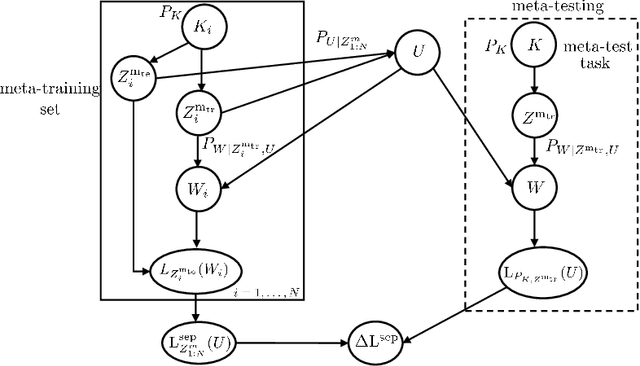
Meta-learning, or "learning to learn", refers to techniques that infer an inductive bias from data corresponding to multiple related tasks with the goal of improving the sample efficiency for new, previously unobserved, tasks. A key performance measure for meta-learning is the meta-generalization gap, that is, the difference between the average loss measured on the meta-training data and on a new, randomly selected task. This paper presents novel information-theoretic upper bounds on the meta-generalization gap. Two broad classes of meta-learning algorithms are considered that uses either separate within-task training and test sets, like MAML, or joint within-task training and test sets, like Reptile. Extending the existing work for conventional learning, an upper bound on the meta-generalization gap is derived for the former class that depends on the mutual information (MI) between the output of the meta-learning algorithm and its input meta-training data. For the latter, the derived bound includes an additional MI between the output of the per-task learning procedure and corresponding data set to capture within-task uncertainty. Tighter bounds are then developed, under given technical conditions, for the two classes via novel Individual Task MI (ITMI) bounds. Applications of the derived bounds are finally discussed, including a broad class of noisy iterative algorithms for meta-learning.
Towards Further Understanding of Sparse Filtering via Information Bottleneck
Oct 20, 2019
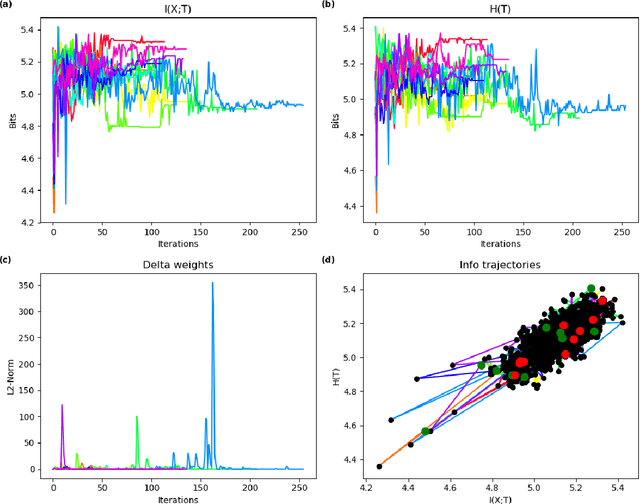
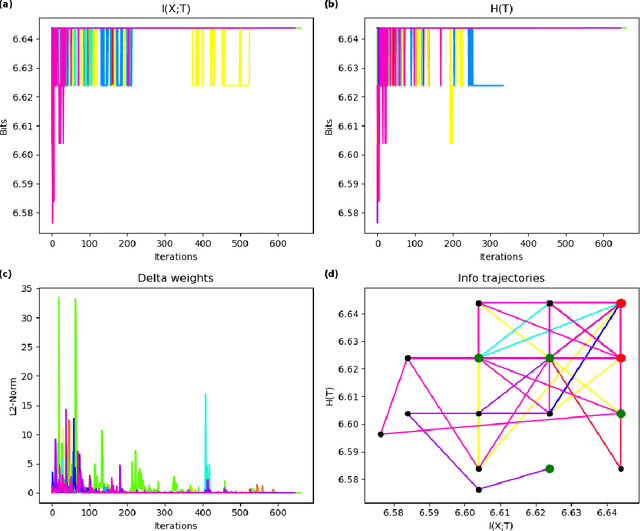
In this paper we examine a formalization of feature distribution learning (FDL) in information-theoretic terms relying on the analytical approach and on the tools already used in the study of the information bottleneck (IB). It has been conjectured that the behavior of FDL algorithms could be expressed as an optimization problem over two information-theoretic quantities: the mutual information of the data with the learned representations and the entropy of the learned distribution. In particular, such a formulation was offered in order to explain the success of the most prominent FDL algorithm, sparse filtering (SF). This conjecture was, however, left unproven. In this work, we aim at providing preliminary empirical support to this conjecture by performing experiments reminiscent of the work done on deep neural networks in the context of the IB research. Specifically, we borrow the idea of using information planes to analyze the behavior of the SF algorithm and gain insights on its dynamics. A confirmation of the conjecture about the dynamics of FDL may provide solid ground to develop information-theoretic tools to assess the quality of the learning process in FDL, and it may be extended to other unsupervised learning algorithms.
CSFlow: Learning Optical Flow via Cross Strip Correlation for Autonomous Driving
Feb 02, 2022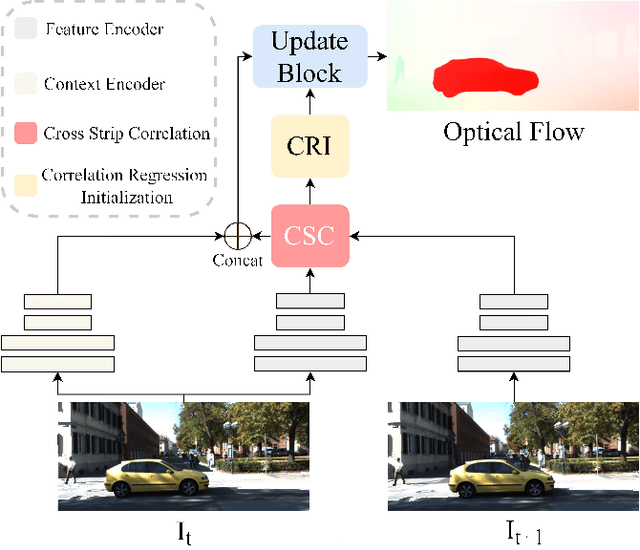
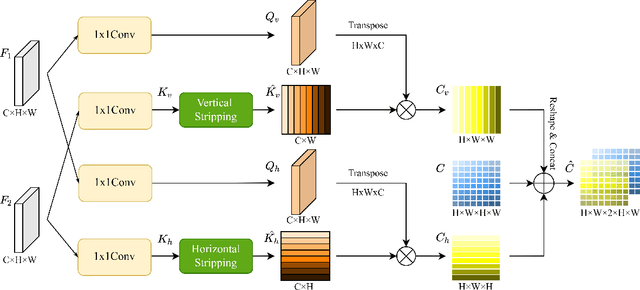
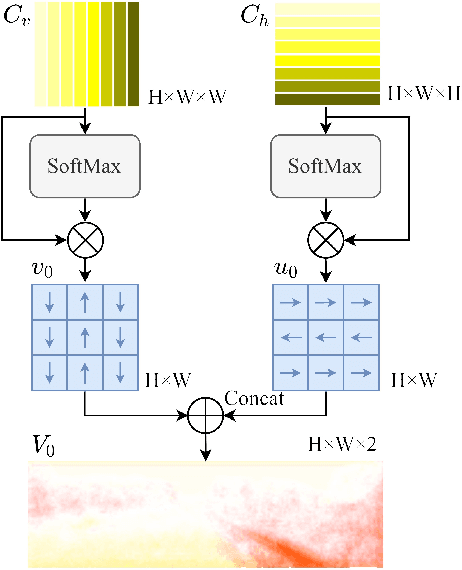
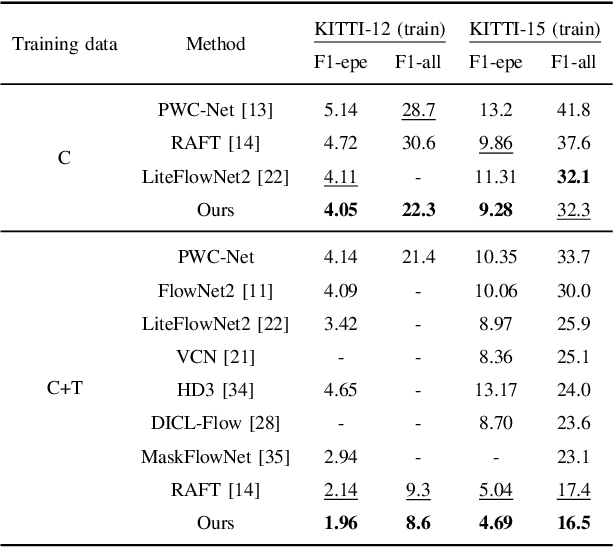
Optical flow estimation is an essential task in self-driving systems, which helps autonomous vehicles perceive temporal continuity information of surrounding scenes. The calculation of all-pair correlation plays an important role in many existing state-of-the-art optical flow estimation methods. However, the reliance on local knowledge often limits the model's accuracy under complex street scenes. In this paper, we propose a new deep network architecture for optical flow estimation in autonomous driving--CSFlow, which consists of two novel modules: Cross Strip Correlation module (CSC) and Correlation Regression Initialization module (CRI). CSC utilizes a striping operation across the target image and the attended image to encode global context into correlation volumes, while maintaining high efficiency. CRI is used to maximally exploit the global context for optical flow initialization. Our method has achieved state-of-the-art accuracy on the public autonomous driving dataset KITTI-2015. Code is publicly available at https://github.com/MasterHow/CSFlow.
A Survey on Temporal Reasoning for Temporal Information Extraction from Text (Extended Abstract)
May 15, 2020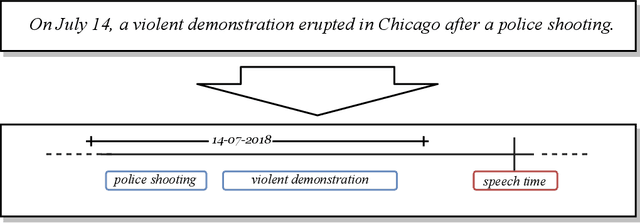

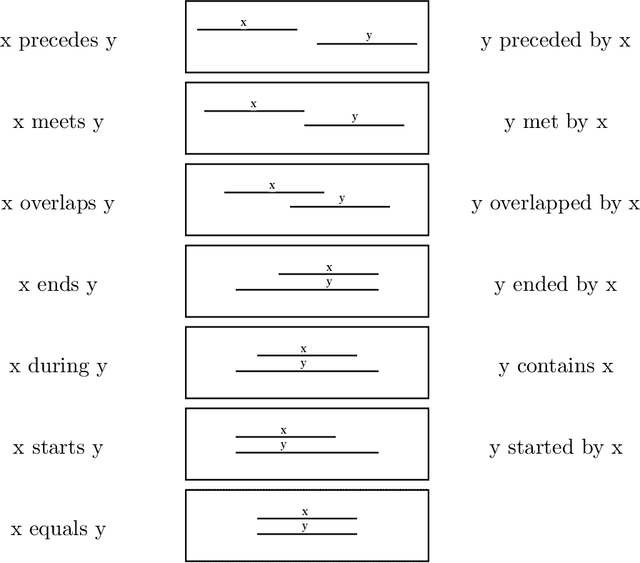
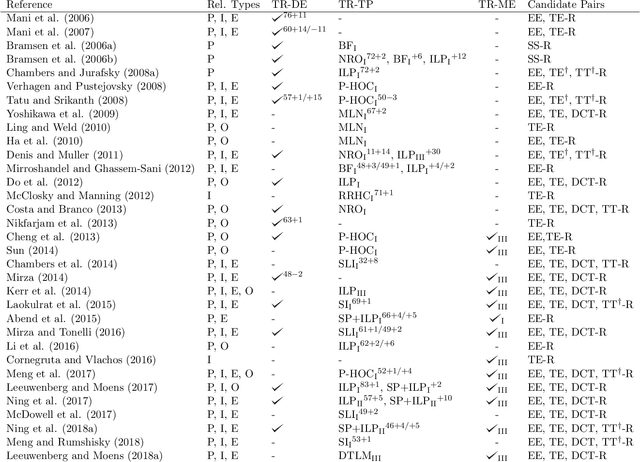
Time is deeply woven into how people perceive, and communicate about the world. Almost unconsciously, we provide our language utterances with temporal cues, like verb tenses, and we can hardly produce sentences without such cues. Extracting temporal cues from text, and constructing a global temporal view about the order of described events is a major challenge of automatic natural language understanding. Temporal reasoning, the process of combining different temporal cues into a coherent temporal view, plays a central role in temporal information extraction. This article presents a comprehensive survey of the research from the past decades on temporal reasoning for automatic temporal information extraction from text, providing a case study on the integration of symbolic reasoning with machine learning-based information extraction systems.
Document-Level Event Extraction via Human-Like Reading Process
Feb 07, 2022
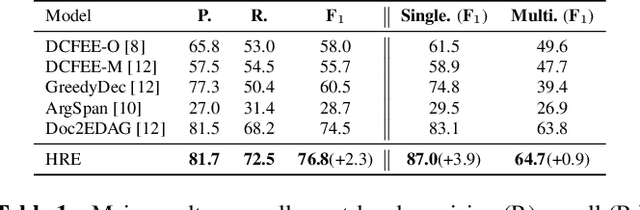
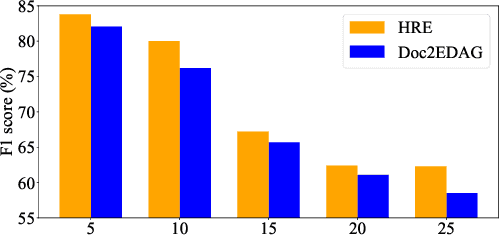
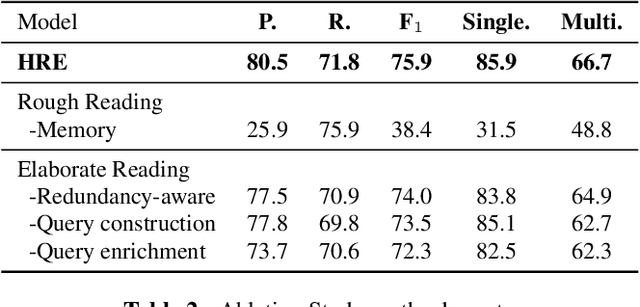
Document-level Event Extraction (DEE) is particularly tricky due to the two challenges it poses: scattering-arguments and multi-events. The first challenge means that arguments of one event record could reside in different sentences in the document, while the second one reflects one document may simultaneously contain multiple such event records. Motivated by humans' reading cognitive to extract information of interests, in this paper, we propose a method called HRE (Human Reading inspired Extractor for Document Events), where DEE is decomposed into these two iterative stages, rough reading and elaborate reading. Specifically, the first stage browses the document to detect the occurrence of events, and the second stage serves to extract specific event arguments. For each concrete event role, elaborate reading hierarchically works from sentences to characters to locate arguments across sentences, thus the scattering-arguments problem is tackled. Meanwhile, rough reading is explored in a multi-round manner to discover undetected events, thus the multi-events problem is handled. Experiment results show the superiority of HRE over prior competitive methods.
Sparse Interventions in Language Models with Differentiable Masking
Dec 13, 2021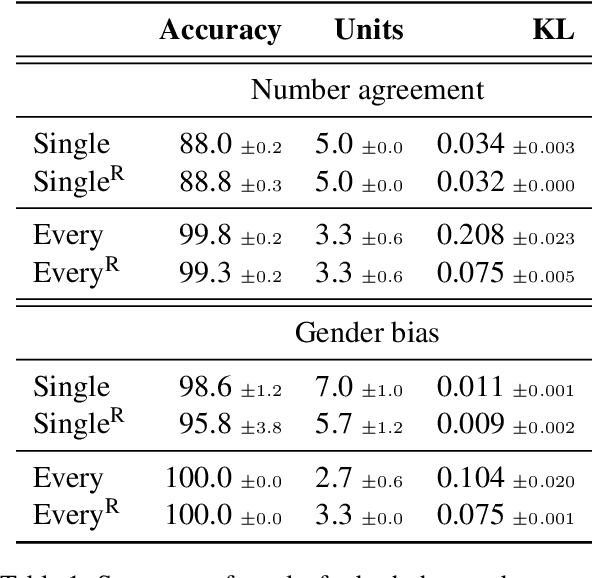
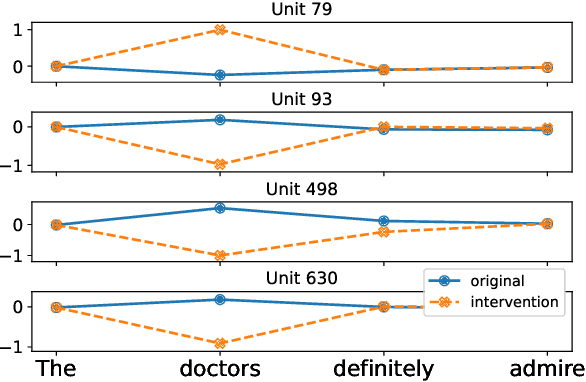
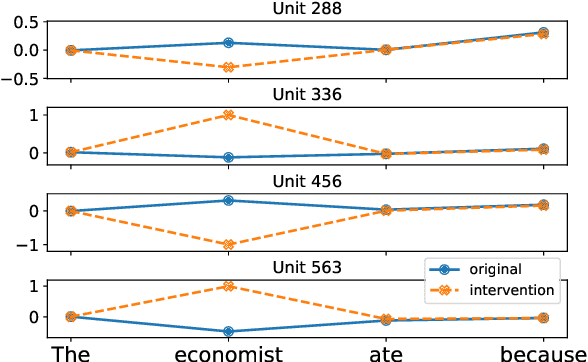
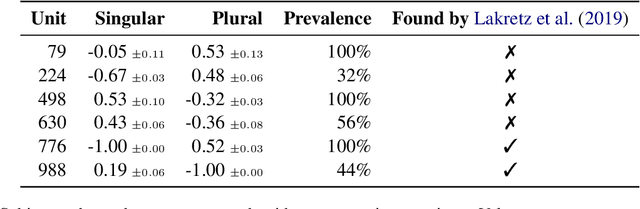
There has been a lot of interest in understanding what information is captured by hidden representations of language models (LMs). Typically, interpretation methods i) do not guarantee that the model actually uses the encoded information, and ii) do not discover small subsets of neurons responsible for a considered phenomenon. Inspired by causal mediation analysis, we propose a method that discovers within a neural LM a small subset of neurons responsible for a particular linguistic phenomenon, i.e., subsets causing a change in the corresponding token emission probabilities. We use a differentiable relaxation to approximately search through the combinatorial space. An $L_0$ regularization term ensures that the search converges to discrete and sparse solutions. We apply our method to analyze subject-verb number agreement and gender bias detection in LSTMs. We observe that it is fast and finds better solutions than the alternative (REINFORCE). Our experiments confirm that each of these phenomenons is mediated through a small subset of neurons that do not play any other discernible role.
Real-time Model Predictive Control and System Identification Using Differentiable Physics Simulation
Feb 20, 2022
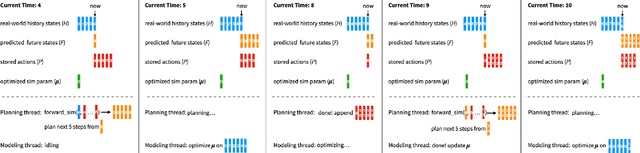
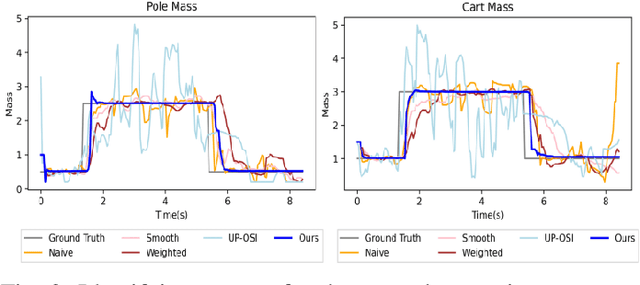
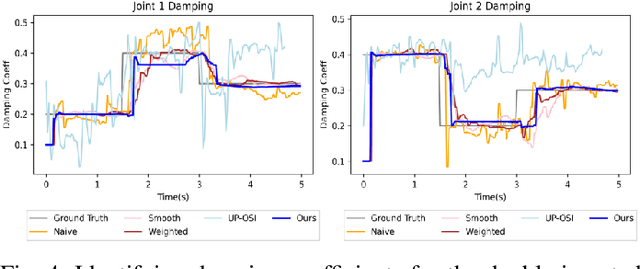
Developing robot controllers in a simulated environment is advantageous but transferring the controllers to the target environment presents challenges, often referred to as the "sim-to-real gap". We present a method for continuous improvement of modeling and control after deploying the robot to a dynamically-changing target environment. We develop a differentiable physics simulation framework that performs online system identification and optimal control simultaneously, using the incoming observations from the target environment in real time. To ensure robust system identification against noisy observations, we devise an algorithm to assess the confidence of our estimated parameters, using numerical analysis of the dynamic equations. To ensure real-time optimal control, we adaptively schedule the optimization window in the future so that the optimized actions can be replenished faster than they are consumed, while staying as up-to-date with new sensor information as possible. The constant re-planning based on a constantly improved model allows the robot to swiftly adapt to the changing environment and utilize real-world data in the most sample-efficient way. Thanks to a fast differentiable physics simulator, the optimization for both system identification and control can be solved efficiently for robots operating in real time. We demonstrate our method on a set of examples in simulation and show that our results are favorable compared to baseline methods.
PetsGAN: Rethinking Priors for Single Image Generation
Mar 03, 2022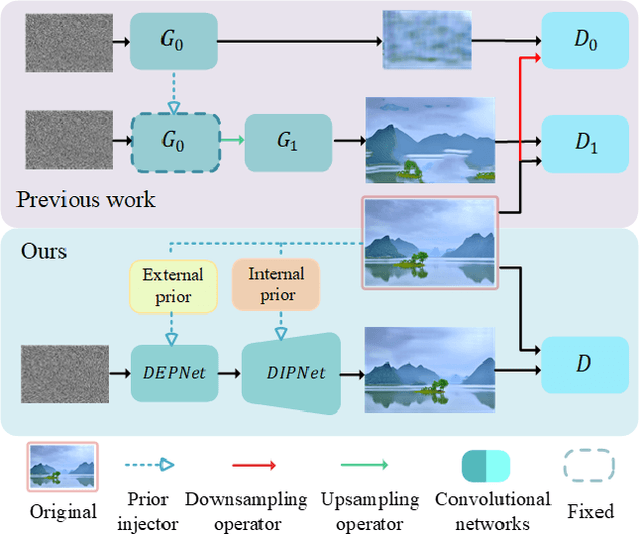
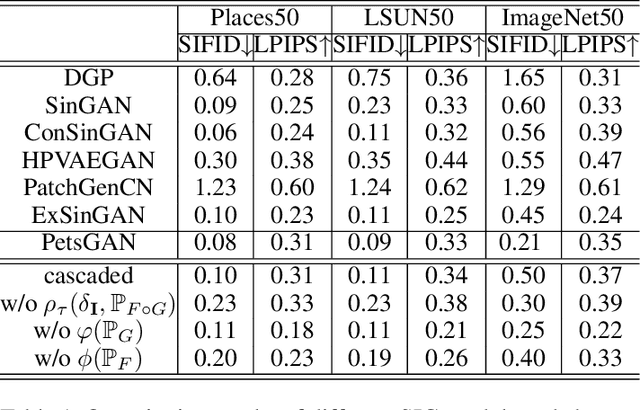

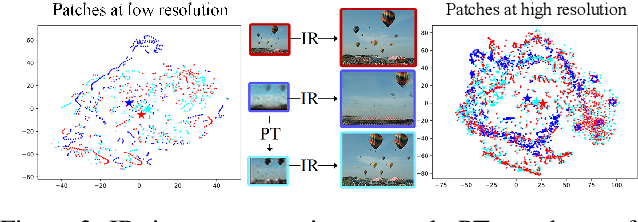
Single image generation (SIG), described as generating diverse samples that have similar visual content with the given single image, is first introduced by SinGAN which builds a pyramid of GANs to progressively learn the internal patch distribution of the single image. It also shows great potentials in a wide range of image manipulation tasks. However, the paradigm of SinGAN has limitations in terms of generation quality and training time. Firstly, due to the lack of high-level information, SinGAN cannot handle the object images well as it does on the scene and texture images. Secondly, the separate progressive training scheme is time-consuming and easy to cause artifact accumulation. To tackle these problems, in this paper, we dig into the SIG problem and improve SinGAN by fully-utilization of internal and external priors. The main contributions of this paper include: 1) We introduce to SIG a regularized latent variable model. To the best of our knowledge, it is the first time to give a clear formulation and optimization goal of SIG, and all the existing methods for SIG can be regarded as special cases of this model. 2) We design a novel Prior-based end-to-end training GAN (PetsGAN) to overcome the problems of SinGAN. Our method gets rid of the time-consuming progressive training scheme and can be trained end-to-end. 3) We construct abundant qualitative and quantitative experiments to show the superiority of our method on both generated image quality, diversity, and the training speed. Moreover, we apply our method to other image manipulation tasks (e.g., style transfer, harmonization), and the results further prove the effectiveness and efficiency of our method.