 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Deconfounded Training for Graph Neural Networks
Dec 30, 2021
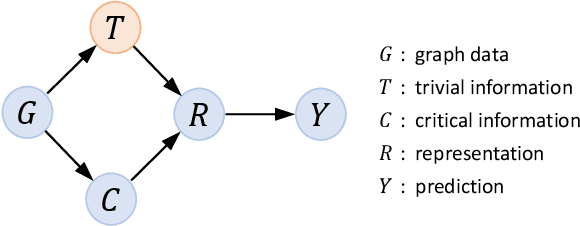
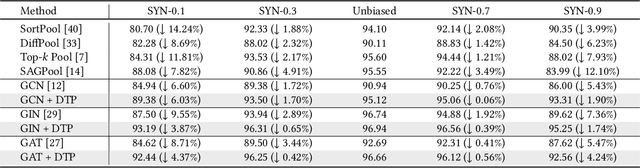
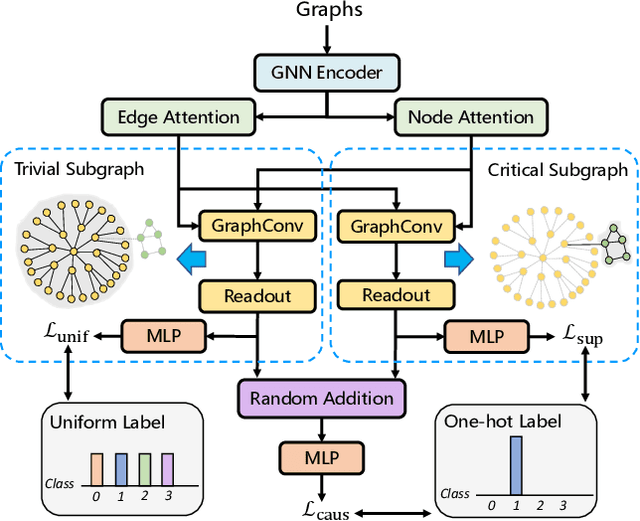
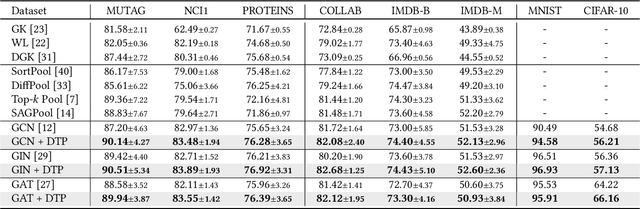
Learning powerful representations is one central theme of graph neural networks (GNNs). It requires refining the critical information from the input graph, instead of the trivial patterns, to enrich the representations. Towards this end, graph attention and pooling methods prevail. They mostly follow the paradigm of "learning to attend". It maximizes the mutual information between the attended subgraph and the ground-truth label. However, this training paradigm is prone to capture the spurious correlations between the trivial subgraph and the label. Such spurious correlations are beneficial to in-distribution (ID) test evaluations, but cause poor generalization in the out-of-distribution (OOD) test data. In this work, we revisit the GNN modeling from the causal perspective. On the top of our causal assumption, the trivial information serves as a confounder between the critical information and the label, which opens a backdoor path between them and makes them spuriously correlated. Hence, we present a new paradigm of deconfounded training (DTP) that better mitigates the confounding effect and latches on the critical information, to enhance the representation and generalization ability. Specifically, we adopt the attention modules to disentangle the critical subgraph and trivial subgraph. Then we make each critical subgraph fairly interact with diverse trivial subgraphs to achieve a stable prediction. It allows GNNs to capture a more reliable subgraph whose relation with the label is robust across different distributions. We conduct extensive experiments on synthetic and real-world datasets to demonstrate the effectiveness.
End-to-End Table Question Answering via Retrieval-Augmented Generation
Mar 30, 2022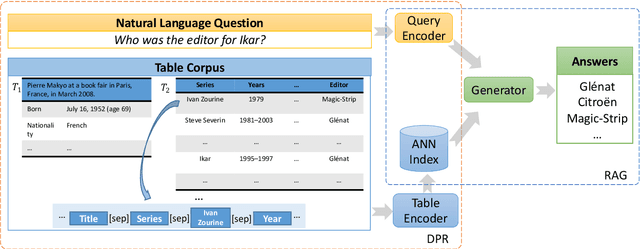
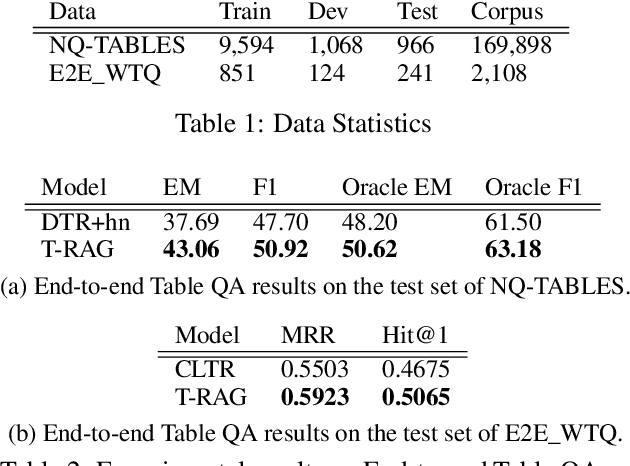
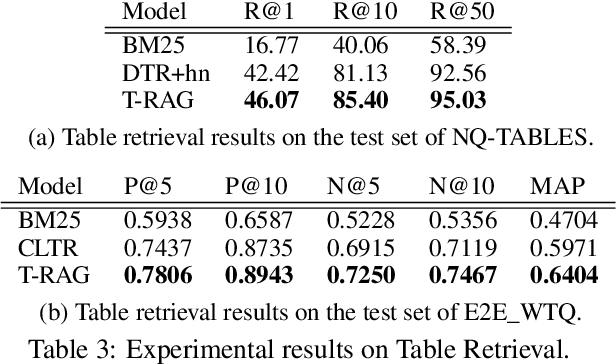
Most existing end-to-end Table Question Answering (Table QA) models consist of a two-stage framework with a retriever to select relevant table candidates from a corpus and a reader to locate the correct answers from table candidates. Even though the accuracy of the reader models is significantly improved with the recent transformer-based approaches, the overall performance of such frameworks still suffers from the poor accuracy of using traditional information retrieval techniques as retrievers. To alleviate this problem, we introduce T-RAG, an end-to-end Table QA model, where a non-parametric dense vector index is fine-tuned jointly with BART, a parametric sequence-to-sequence model to generate answer tokens. Given any natural language question, T-RAG utilizes a unified pipeline to automatically search through a table corpus to directly locate the correct answer from the table cells. We apply T-RAG to recent open-domain Table QA benchmarks and demonstrate that the fine-tuned T-RAG model is able to achieve state-of-the-art performance in both the end-to-end Table QA and the table retrieval tasks.
HyperShot: Few-Shot Learning by Kernel HyperNetworks
Mar 21, 2022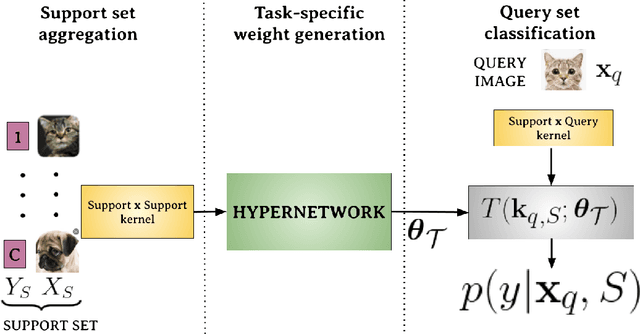
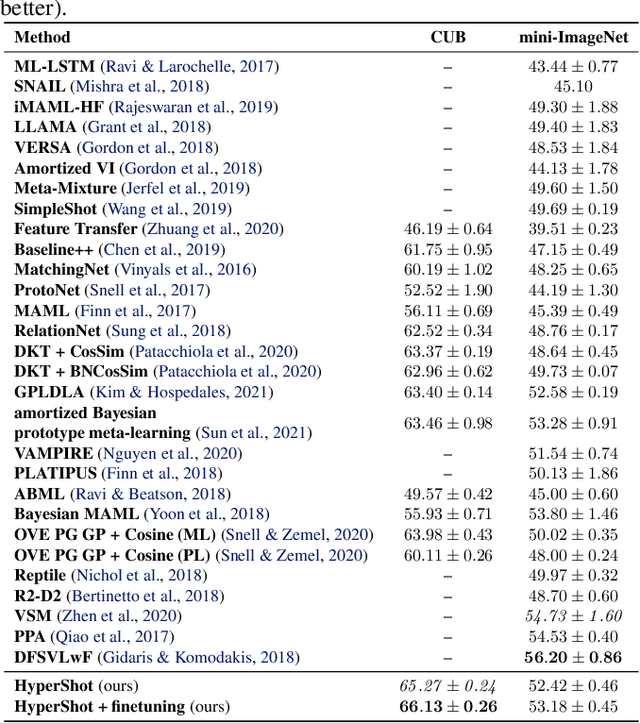
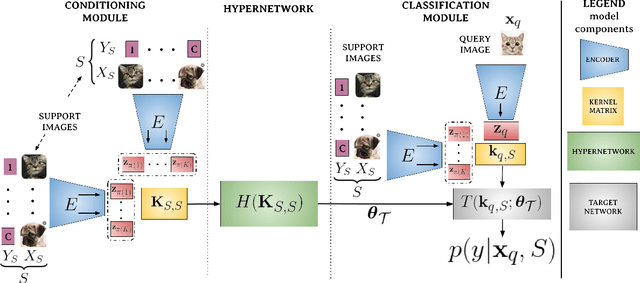
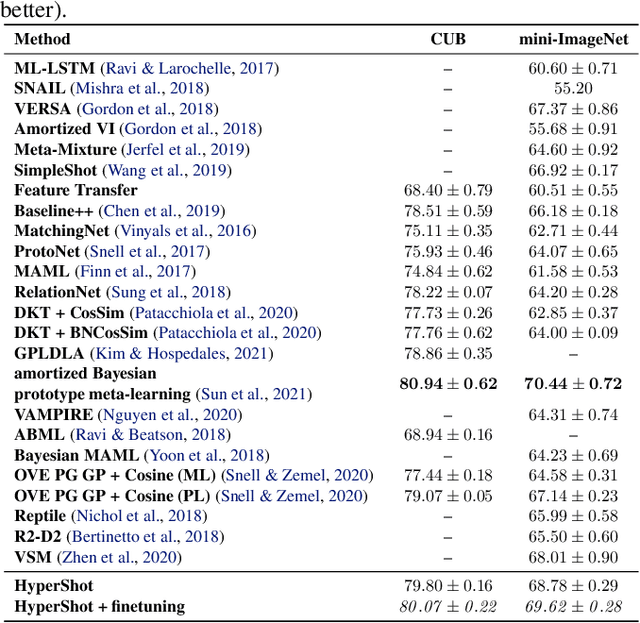
Few-shot models aim at making predictions using a minimal number of labeled examples from a given task. The main challenge in this area is the one-shot setting where only one element represents each class. We propose HyperShot - the fusion of kernels and hypernetwork paradigm. Compared to reference approaches that apply a gradient-based adjustment of the parameters, our model aims to switch the classification module parameters depending on the task's embedding. In practice, we utilize a hypernetwork, which takes the aggregated information from support data and returns the classifier's parameters handcrafted for the considered problem. Moreover, we introduce the kernel-based representation of the support examples delivered to hypernetwork to create the parameters of the classification module. Consequently, we rely on relations between embeddings of the support examples instead of direct feature values provided by the backbone models. Thanks to this approach, our model can adapt to highly different tasks.
Finding the optimal human strategy for Wordle using maximum correct letter probabilities and reinforcement learning
Feb 01, 2022Wordle is an online word puzzle game that gained viral popularity in January 2022. The goal is to guess a hidden five letter word. After each guess, the player gains information about whether the letters they guessed are present in the word, and whether they are in the correct position. Numerous blogs have suggested guessing strategies and starting word lists that improve the chance of winning. Optimized algorithms can win 100% of games within five of the six allowed trials. However, it is infeasible for human players to use these algorithms due to an inability to perfectly recall all known 5-letter words and perform complex calculations that optimize information gain. Here, we present two different methods for choosing starting words along with a framework for discovering the optimal human strategy based on reinforcement learning. Human Wordle players can use the rules we discover to optimize their chance of winning.
Look Backward and Forward: Self-Knowledge Distillation with Bidirectional Decoder for Neural Machine Translation
Mar 11, 2022

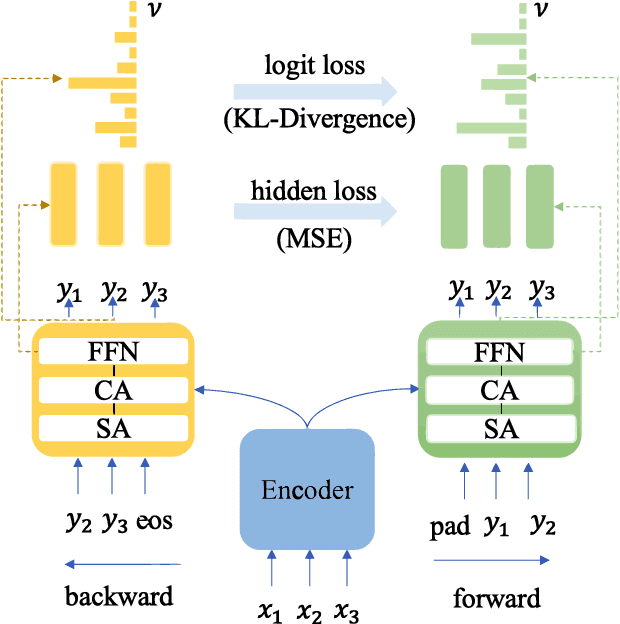
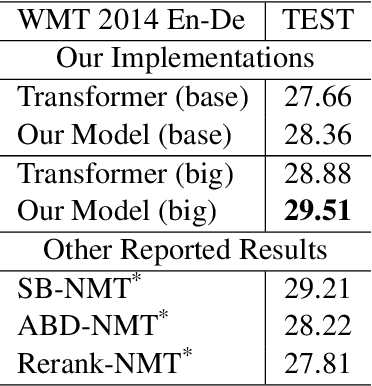
Neural Machine Translation(NMT) models are usually trained via unidirectional decoder which corresponds to optimizing one-step-ahead prediction. However, this kind of unidirectional decoding framework may incline to focus on local structure rather than global coherence. To alleviate this problem, we propose a novel method, Self-Knowledge Distillation with Bidirectional Decoder for Neural Machine Translation(SBD-NMT). We deploy a backward decoder which can act as an effective regularization method to the forward decoder. By leveraging the backward decoder's information about the longer-term future, distilling knowledge learned in the backward decoder can encourage auto-regressive NMT models to plan ahead. Experiments show that our method is significantly better than the strong Transformer baselines on multiple machine translation data sets.
Learning robot motor skills with mixed reality
Mar 21, 2022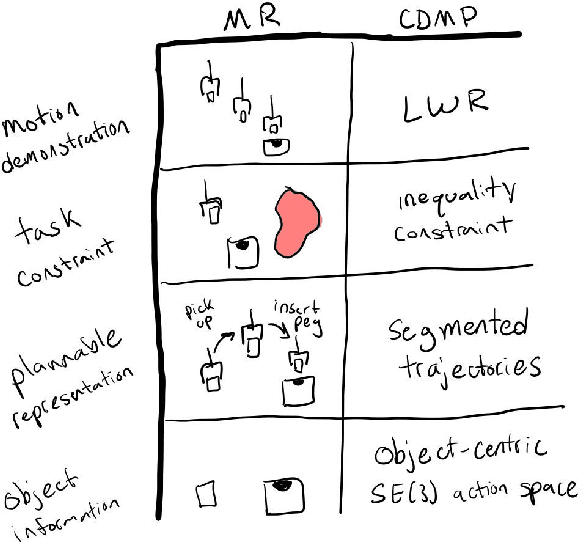

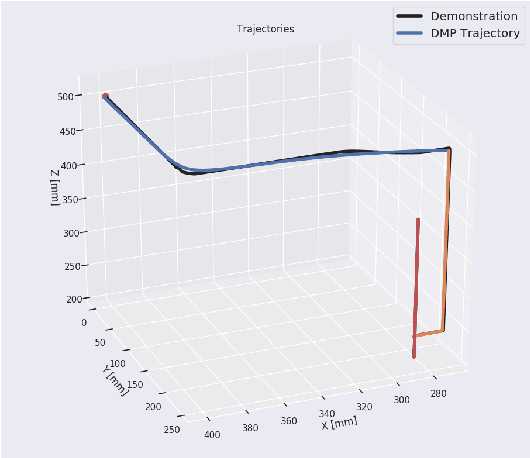
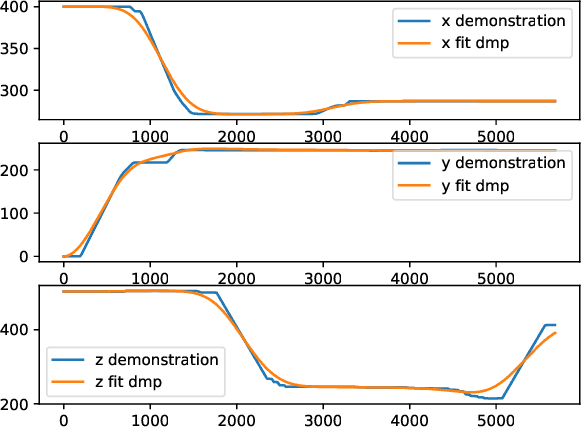
Mixed Reality (MR) has recently shown great success as an intuitive interface for enabling end-users to teach robots. Related works have used MR interfaces to communicate robot intents and beliefs to a co-located human, as well as developed algorithms for taking multi-modal human input and learning complex motor behaviors. Even with these successes, enabling end-users to teach robots complex motor tasks still poses a challenge because end-user communication is highly task dependent and world knowledge is highly varied. We propose a learning framework where end-users teach robots a) motion demonstrations, b) task constraints, c) planning representations, and d) object information, all of which are integrated into a single motor skill learning framework based on Dynamic Movement Primitives (DMPs). We hypothesize that conveying this world knowledge will be intuitive with an MR interface, and that a sample-efficient motor skill learning framework which incorporates varied modalities of world knowledge will enable robots to effectively solve complex tasks.
Joint Sensing, Communication and Localization of a Silent Abnormality Using Molecular Diffusion
Mar 30, 2022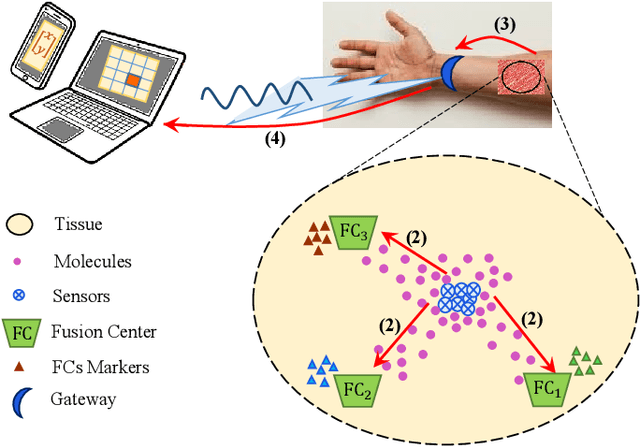
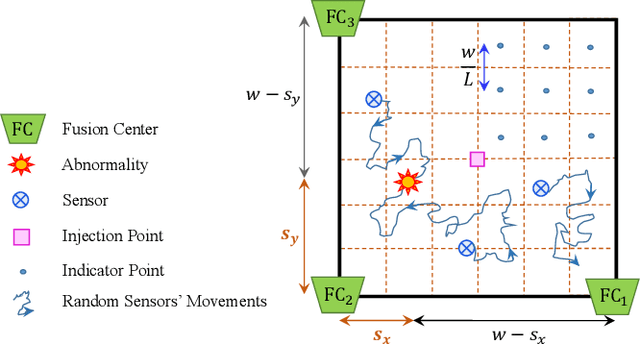
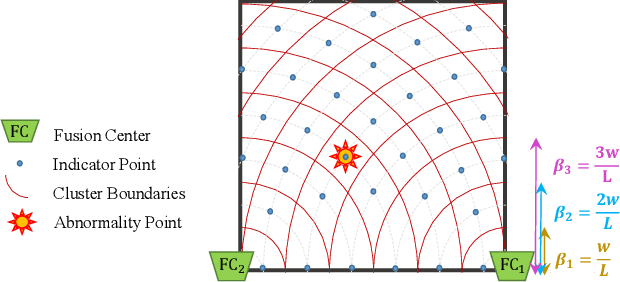
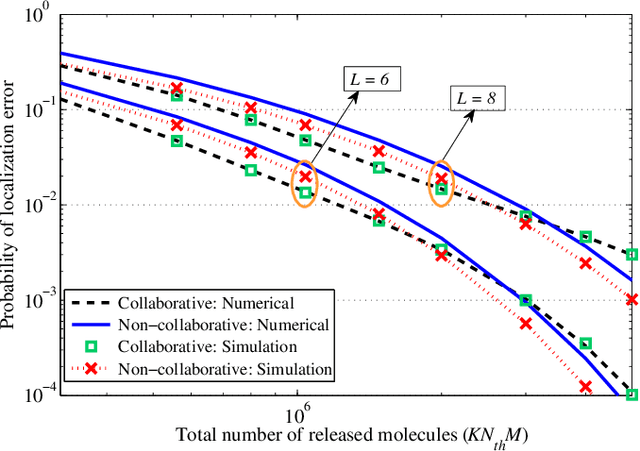
In this paper, we propose a molecular communication system to localize an abnormality in a diffusion based medium. We consider a general setup to perform joint sensing, communication and localization. This setup consists of three types of devices, each for a different task: mobile sensors for navigation and molecule releasing (for communication), fusion centers (FC)s for sampling, amplifying and forwarding the signal, and a gateway for making decision or exchanging the information with an external device. The sensors move randomly in the environment to reach the abnormality. We consider both collaborative and non-collaborative sensors that simultaneously release their molecules to the FCs when the number of activated sensors or the moving time reach a certain threshold, respectively. The FCs amplify the received signal and forward it to the gateway for decision making using either an ideal or a noisy communication channel. A practical application of the proposed model is drug delivery in a tissue of human body, in order to guide the nanomachine bound drug to the exact location. The decision rules and probabilities of error are obtained for two considered sensors types in both ideal and noisy communication channels.
Spatial Information Guided Convolution for Real-Time RGBD Semantic Segmentation
Apr 09, 2020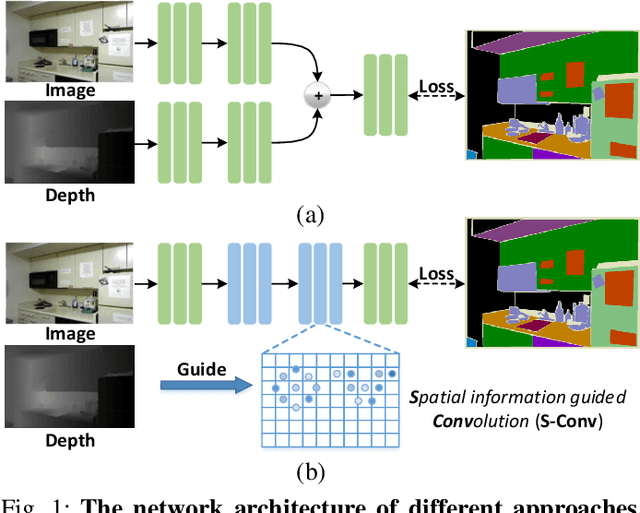
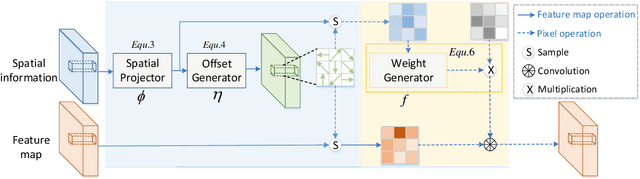
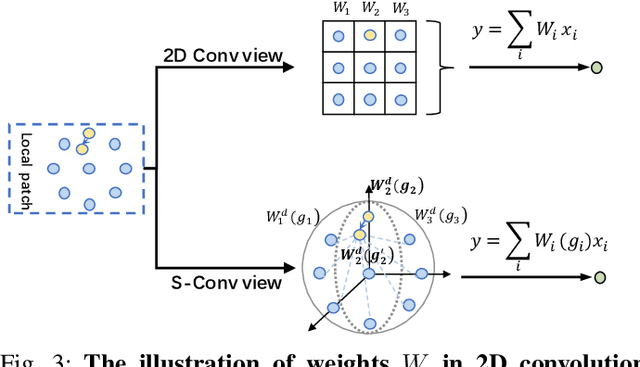
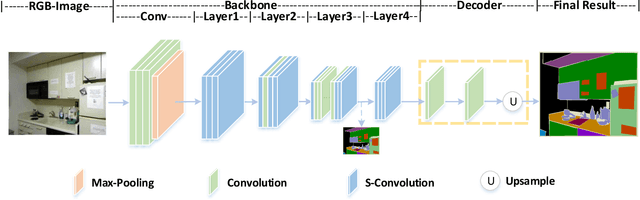
3D spatial information is known to be beneficial to the semantic segmentation task. Most existing methods take 3D spatial data as an additional input, leading to a two-stream segmentation network that processes RGB and 3D spatial information separately. This solution greatly increases the inference time and severely limits its scope for real-time applications. To solve this problem, we propose Spatial information guided Convolution (S-Conv), which allows efficient RGB feature and 3D spatial information integration. S-Conv is competent to infer the sampling offset of the convolution kernel guided by the 3D spatial information, helping the convolutional layer adjust the receptive field and adapt to geometric transformations. S-Conv also incorporates geometric information into the feature learning process by generating spatially adaptive convolutional weights. The capability of perceiving geometry is largely enhanced without much affecting the amount of parameters and computational cost. We further embed S-Conv into a semantic segmentation network, called Spatial information Guided convolutional Network (SGNet), resulting in real-time inference and state-of-the-art performance on NYUDv2 and SUNRGBD datasets.
Transforming Model Prediction for Tracking
Mar 21, 2022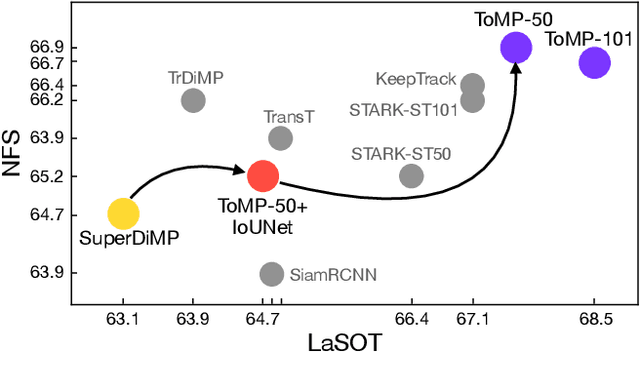
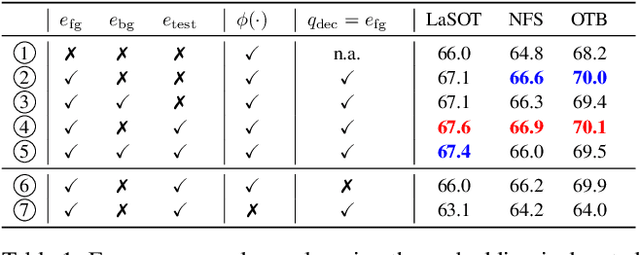
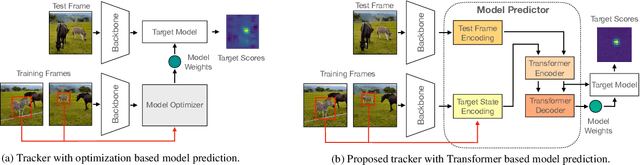
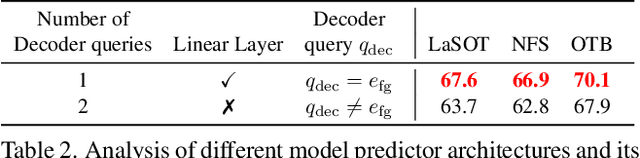
Optimization based tracking methods have been widely successful by integrating a target model prediction module, providing effective global reasoning by minimizing an objective function. While this inductive bias integrates valuable domain knowledge, it limits the expressivity of the tracking network. In this work, we therefore propose a tracker architecture employing a Transformer-based model prediction module. Transformers capture global relations with little inductive bias, allowing it to learn the prediction of more powerful target models. We further extend the model predictor to estimate a second set of weights that are applied for accurate bounding box regression. The resulting tracker relies on training and on test frame information in order to predict all weights transductively. We train the proposed tracker end-to-end and validate its performance by conducting comprehensive experiments on multiple tracking datasets. Our tracker sets a new state of the art on three benchmarks, achieving an AUC of 68.5% on the challenging LaSOT dataset.
Dynamic Non-Regular Sampling Sensor Using Frequency Selective Reconstruction
Apr 07, 2022
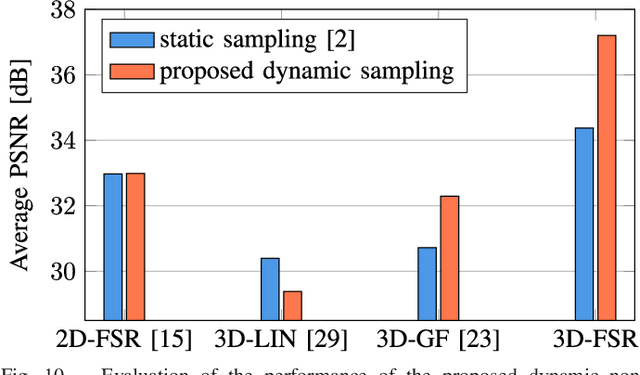


Both a high spatial and a high temporal resolution of images and videos are desirable in many applications such as entertainment systems, monitoring manufacturing processes, or video surveillance. Due to the limited throughput of pixels per second, however, there is always a trade-off between acquiring sequences with a high spatial resolution at a low temporal resolution or vice versa. In this paper, a modified sensor concept is proposed which is able to acquire both a high spatial and a high temporal resolution. This is achieved by dynamically reading out only a subset of pixels in a non-regular order to obtain a high temporal resolution. A full high spatial resolution is then obtained by performing a subsequent three-dimensional reconstruction of the partially acquired frames. The main benefit of the proposed dynamic readout is that for each frame, different sampling points are available which is advantageous since this information can significantly enhance the reconstruction quality of the proposed reconstruction algorithm. Using the proposed dynamic readout strategy, gains in PSNR of up to 8.55 dB are achieved compared to a static readout strategy. Compared to other state-of-the-art techniques like frame rate up-conversion or super-resolution which are also able to reconstruct sequences with both a high spatial and a high temporal resolution, average gains in PSNR of up to 6.58 dB are possible.