 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Marginal Contrastive Correspondence for Guided Image Generation
Apr 01, 2022
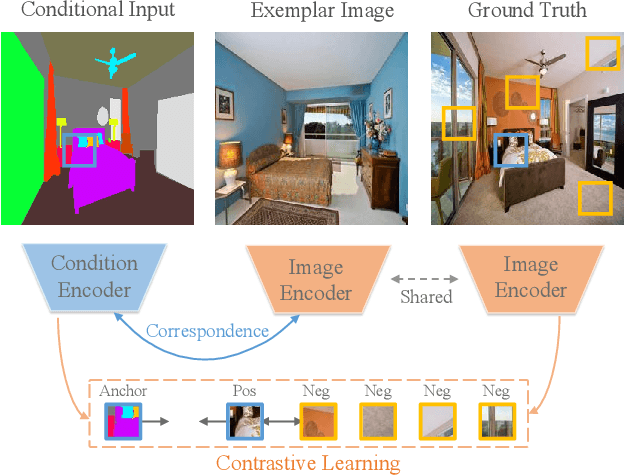
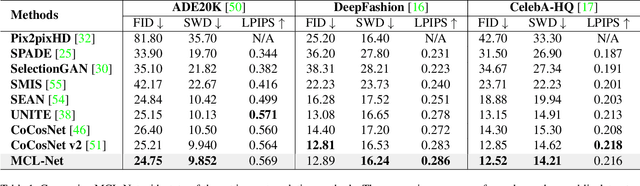
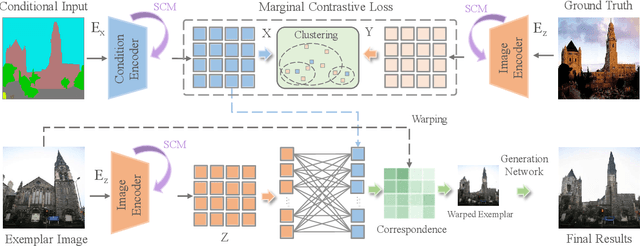
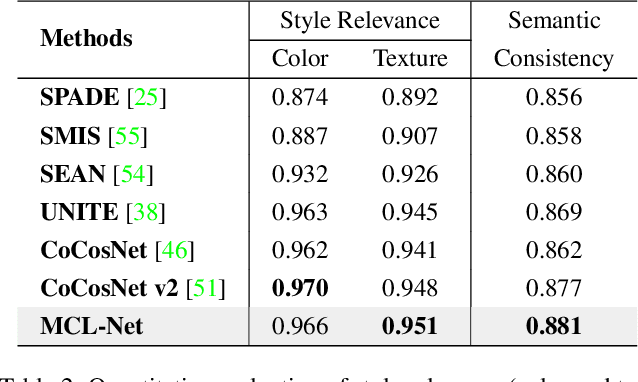
Exemplar-based image translation establishes dense correspondences between a conditional input and an exemplar (from two different domains) for leveraging detailed exemplar styles to achieve realistic image translation. Existing work builds the cross-domain correspondences implicitly by minimizing feature-wise distances across the two domains. Without explicit exploitation of domain-invariant features, this approach may not reduce the domain gap effectively which often leads to sub-optimal correspondences and image translation. We design a Marginal Contrastive Learning Network (MCL-Net) that explores contrastive learning to learn domain-invariant features for realistic exemplar-based image translation. Specifically, we design an innovative marginal contrastive loss that guides to establish dense correspondences explicitly. Nevertheless, building correspondence with domain-invariant semantics alone may impair the texture patterns and lead to degraded texture generation. We thus design a Self-Correlation Map (SCM) that incorporates scene structures as auxiliary information which improves the built correspondences substantially. Quantitative and qualitative experiments on multifarious image translation tasks show that the proposed method outperforms the state-of-the-art consistently.
StrongSORT: Make DeepSORT Great Again
Feb 28, 2022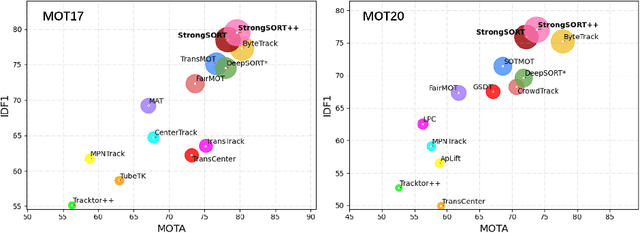

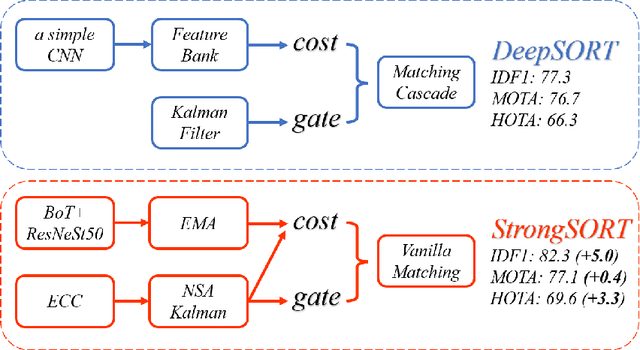
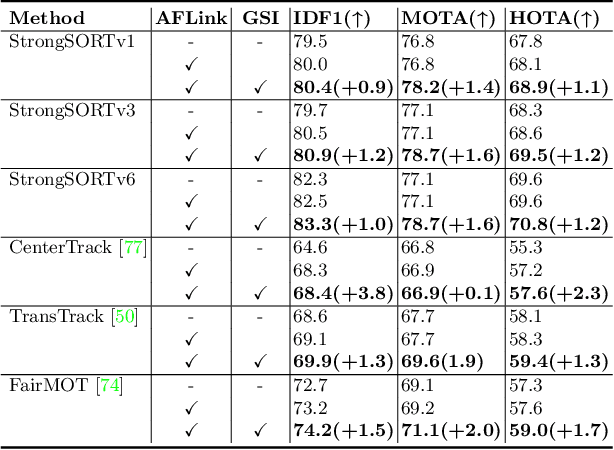
Existing Multi-Object Tracking (MOT) methods can be roughly classified as tracking-by-detection and joint-detection-association paradigms. Although the latter has elicited more attention and demonstrates comparable performance relative to the former, we claim that the tracking-by-detection paradigm is still the optimal solution in terms of tracking accuracy. In this paper, we revisit the classic tracker DeepSORT and upgrade it from various aspects, i.e., detection, embedding and association. The resulting tracker, called StrongSORT, sets new HOTA and IDF1 records on MOT17 and MOT20. We also present two lightweight and plug-and-play algorithms to further refine the tracking results. Firstly, an appearance-free link model (AFLink) is proposed to associate short tracklets into complete trajectories. To the best of our knowledge, this is the first global link model without appearance information. Secondly, we propose Gaussian-smoothed interpolation (GSI) to compensate for missing detections. Instead of ignoring motion information like linear interpolation, GSI is based on the Gaussian process regression algorithm and can achieve more accurate localizations. Moreover, AFLink and GSI can be plugged into various trackers with a negligible extra computational cost (591.9 and 140.9 Hz, respectively, on MOT17). By integrating StrongSORT with the two algorithms, the final tracker StrongSORT++ ranks first on MOT17 and MOT20 in terms of HOTA and IDF1 metrics and surpasses the second-place one by 1.3 - 2.2. Code will be released soon.
Improving Voice Trigger Detection with Metric Learning
Apr 05, 2022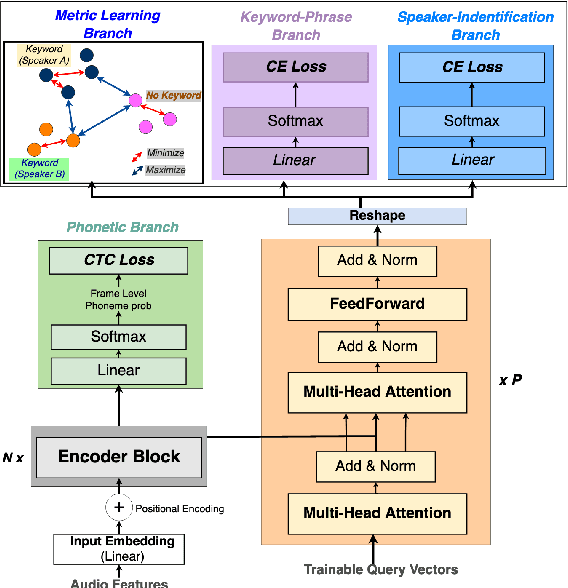
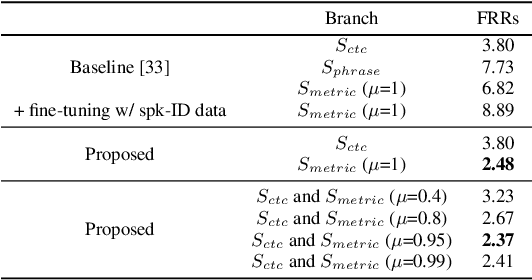
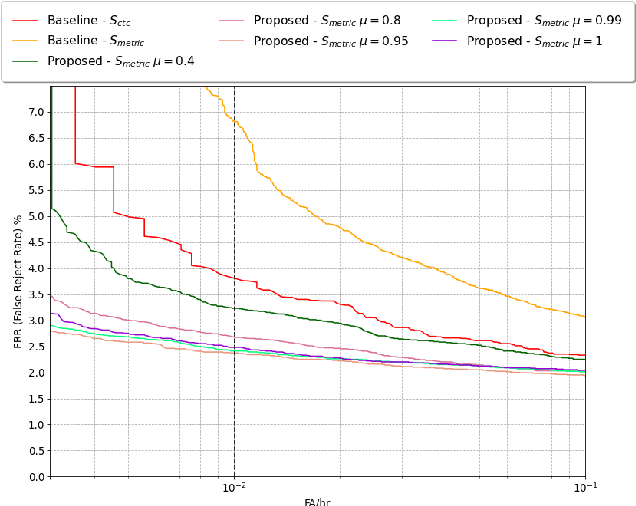
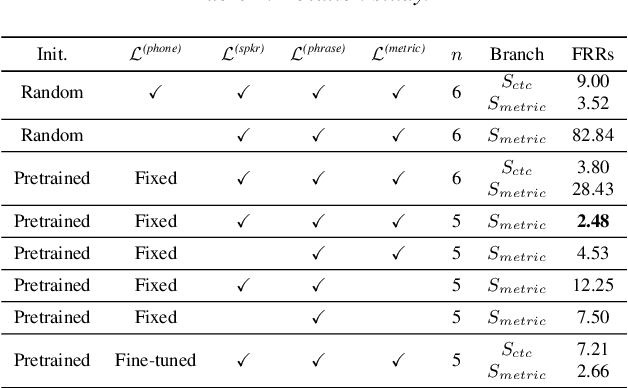
Voice trigger detection is an important task, which enables activating a voice assistant when a target user speaks a keyword phrase. A detector is typically trained on speech data independent of speaker information and used for the voice trigger detection task. However, such a speaker independent voice trigger detector typically suffers from performance degradation on speech from underrepresented groups, such as accented speakers. In this work, we propose a novel voice trigger detector that can use a small number of utterances from a target speaker to improve detection accuracy. Our proposed model employs an encoder-decoder architecture. While the encoder performs speaker independent voice trigger detection, similar to the conventional detector, the decoder predicts a personalized embedding for each utterance. A personalized voice trigger score is then obtained as a similarity score between the embeddings of enrollment utterances and a test utterance. The personalized embedding allows adapting to target speaker's speech when computing the voice trigger score, hence improving voice trigger detection accuracy. Experimental results show that the proposed approach achieves a 38% relative reduction in a false rejection rate (FRR) compared to a baseline speaker independent voice trigger model.
Leveraging Tacit Information Embedded in CNN Layers for Visual Tracking
Oct 02, 2020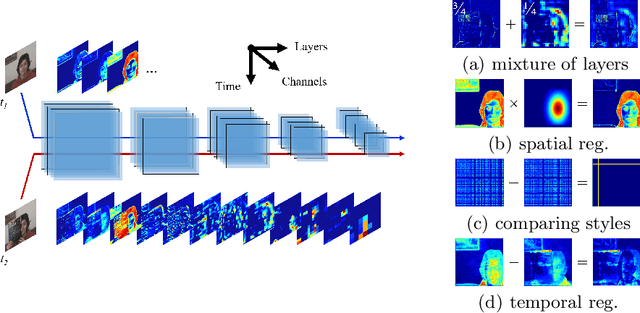
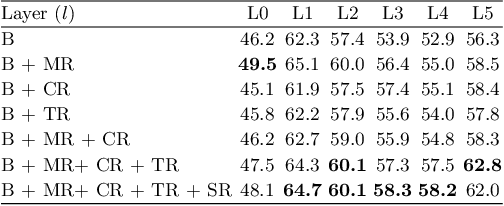
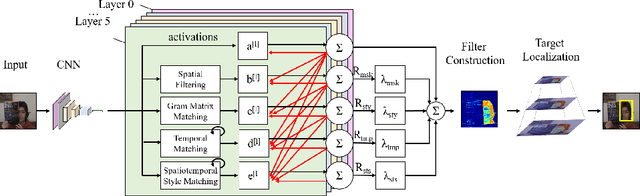

Different layers in CNNs provide not only different levels of abstraction for describing the objects in the input but also encode various implicit information about them. The activation patterns of different features contain valuable information about the stream of incoming images: spatial relations, temporal patterns, and co-occurrence of spatial and spatiotemporal (ST) features. The studies in visual tracking literature, so far, utilized only one of the CNN layers, a pre-fixed combination of them, or an ensemble of trackers built upon individual layers. In this study, we employ an adaptive combination of several CNN layers in a single DCF tracker to address variations of the target appearances and propose the use of style statistics on both spatial and temporal properties of the target, directly extracted from CNN layers for visual tracking. Experiments demonstrate that using the additional implicit data of CNNs significantly improves the performance of the tracker. Results demonstrate the effectiveness of using style similarity and activation consistency regularization in improving its localization and scale accuracy.
CLEVR-X: A Visual Reasoning Dataset for Natural Language Explanations
Apr 05, 2022
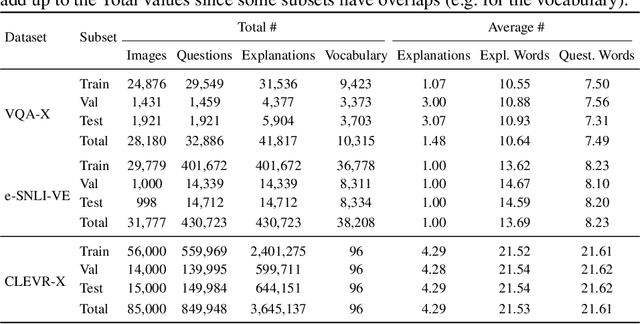
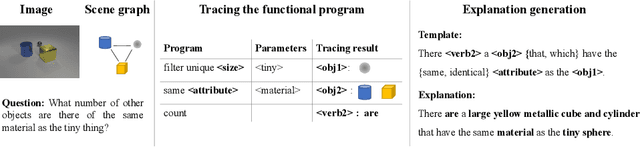

Providing explanations in the context of Visual Question Answering (VQA) presents a fundamental problem in machine learning. To obtain detailed insights into the process of generating natural language explanations for VQA, we introduce the large-scale CLEVR-X dataset that extends the CLEVR dataset with natural language explanations. For each image-question pair in the CLEVR dataset, CLEVR-X contains multiple structured textual explanations which are derived from the original scene graphs. By construction, the CLEVR-X explanations are correct and describe the reasoning and visual information that is necessary to answer a given question. We conducted a user study to confirm that the ground-truth explanations in our proposed dataset are indeed complete and relevant. We present baseline results for generating natural language explanations in the context of VQA using two state-of-the-art frameworks on the CLEVR-X dataset. Furthermore, we provide a detailed analysis of the explanation generation quality for different question and answer types. Additionally, we study the influence of using different numbers of ground-truth explanations on the convergence of natural language generation (NLG) metrics. The CLEVR-X dataset is publicly available at \url{https://explainableml.github.io/CLEVR-X/}.
First is Better Than Last for Training Data Influence
Feb 24, 2022
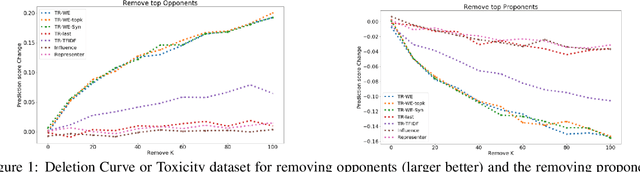

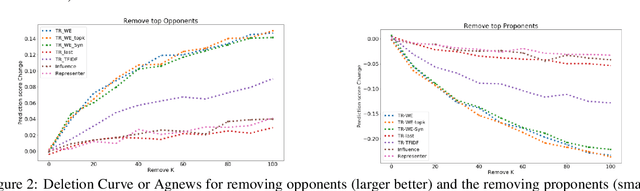
The ability to identify influential training examples enables us to debug training data and explain model behavior. Existing techniques are based on the flow of influence through the model parameters. For large models in NLP applications, it is often computationally infeasible to study this flow through all model parameters, therefore techniques usually pick the last layer of weights. Our first observation is that for classification problems, the last layer is reductive and does not encode sufficient input level information. Deleting influential examples, according to this measure, typically does not change the model's behavior much. We propose a technique called TracIn-WE that modifies a method called TracIn to operate on the word embedding layer instead of the last layer. This could potentially have the opposite concern, that the word embedding layer does not encode sufficient high level information. However, we find that gradients (unlike embeddings) do not suffer from this, possibly because they chain through higher layers. We show that TracIn-WE significantly outperforms other data influence methods applied on the last layer by 4-10 times on the case deletion evaluation on three language classification tasks. In addition, TracIn-WE can produce scores not just at the training data level, but at the word training data level, a further aid in debugging.
Transient Information Adaptation of Artificial Intelligence: Towards Sustainable Data Processes in Complex Projects
Apr 18, 2021Large scale projects increasingly operate in complicated settings whilst drawing on an array of complex data-points, which require precise analysis for accurate control and interventions to mitigate possible project failure. Coupled with a growing tendency to rely on new information systems and processes in change projects, 90% of megaprojects globally fail to achieve their planned objectives. Renewed interest in the concept of Artificial Intelligence (AI) against a backdrop of disruptive technological innovations, seeks to enhance project managers cognitive capacity through the project lifecycle and enhance project excellence. However, despite growing interest there remains limited empirical insights on project managers ability to leverage AI for cognitive load enhancement in complex settings. As such this research adopts an exploratory sequential linear mixed methods approach to address unresolved empirical issues on transient adaptations of AI in complex projects, and the impact on cognitive load enhancement. Initial thematic findings from semi-structured interviews with domain experts, suggest that in order to leverage AI technologies and processes for sustainable cognitive load enhancement with complex data over time, project managers require improved knowledge and access to relevant technologies that mediate data processes in complex projects, but equally reflect application across different project phases. These initial findings support further hypothesis testing through a larger quantitative study incorporating structural equation modelling to examine the relationship between artificial intelligence and project managers cognitive load with project data in complex contexts.
Climate Change & Computer Audition: A Call to Action and Overview on Audio Intelligence to Help Save the Planet
Mar 10, 2022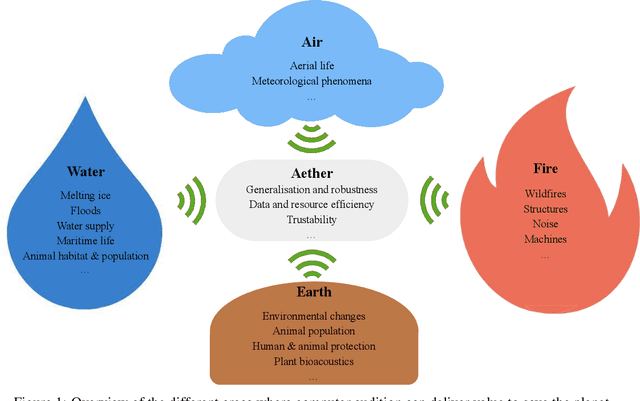
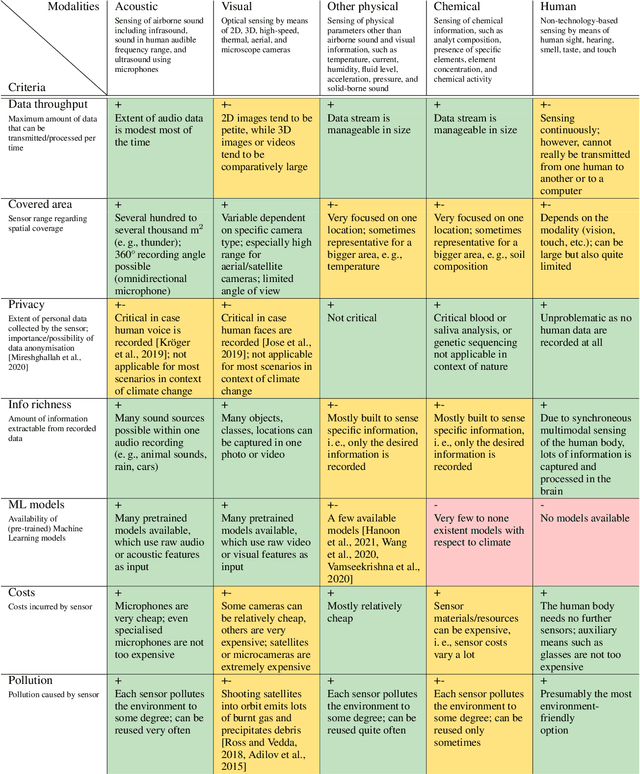
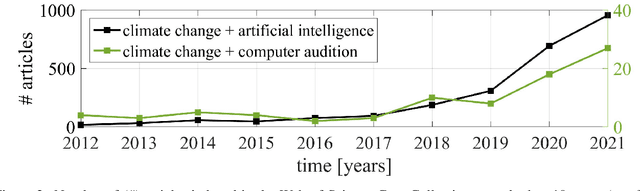
Among the seventeen Sustainable Development Goals (SDGs) proposed within the 2030 Agenda and adopted by all the United Nations member states, the 13$^{th}$ SDG is a call for action to combat climate change for a better world. In this work, we provide an overview of areas in which audio intelligence -- a powerful but in this context so far hardly considered technology -- can contribute to overcome climate-related challenges. We categorise potential computer audition applications according to the five elements of earth, water, air, fire, and aether, proposed by the ancient Greeks in their five element theory; this categorisation serves as a framework to discuss computer audition in relation to different ecological aspects. Earth and water are concerned with the early detection of environmental changes and, thus, with the protection of humans and animals, as well as the monitoring of land and aquatic organisms. Aerial audio is used to monitor and obtain information about bird and insect populations. Furthermore, acoustic measures can deliver relevant information for the monitoring and forecasting of weather and other meteorological phenomena. The fourth considered element is fire. Due to the burning of fossil fuels, the resulting increase in CO$_2$ emissions and the associated rise in temperature, fire is used as a symbol for man-made climate change and in this context includes the monitoring of noise pollution, machines, as well as the early detection of wildfires. In all these areas, computer audition can help counteract climate change. Aether then corresponds to the technology itself that makes this possible. This work explores these areas and discusses potential applications, while positioning computer audition in relation to methodological alternatives.
Efficient Cluster-Based k-Nearest-Neighbor Machine Translation
Apr 13, 2022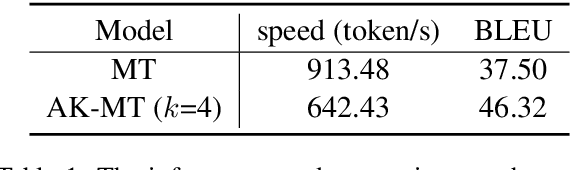
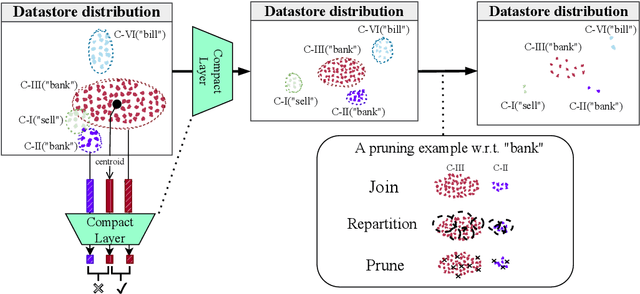

k-Nearest-Neighbor Machine Translation (kNN-MT) has been recently proposed as a non-parametric solution for domain adaptation in neural machine translation (NMT). It aims to alleviate the performance degradation of advanced MT systems in translating out-of-domain sentences by coordinating with an additional token-level feature-based retrieval module constructed from in-domain data. Previous studies have already demonstrated that non-parametric NMT is even superior to models fine-tuned on out-of-domain data. In spite of this success, kNN retrieval is at the expense of high latency, in particular for large datastores. To make it practical, in this paper, we explore a more efficient kNN-MT and propose to use clustering to improve the retrieval efficiency. Concretely, we first propose a cluster-based Compact Network for feature reduction in a contrastive learning manner to compress context features into 90+% lower dimensional vectors. We then suggest a cluster-based pruning solution to filter out 10%-40% redundant nodes in large datastores while retaining translation quality. Our proposed methods achieve better or comparable performance while reducing up to 57% inference latency against the advanced non-parametric MT model on several machine translation benchmarks. Experimental results indicate that the proposed methods maintain the most useful information of the original datastore and the Compact Network shows good generalization on unseen domains.
Exploiting Data Sparsity in Secure Cross-Platform Social Recommendation
Feb 15, 2022


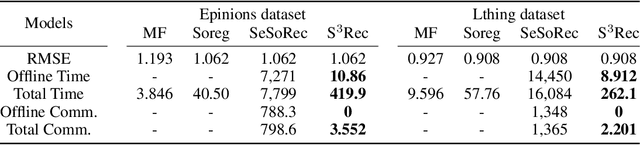
Social recommendation has shown promising improvements over traditional systems since it leverages social correlation data as an additional input. Most existing work assumes that all data are available to the recommendation platform. However, in practice, user-item interaction data (e.g.,rating) and user-user social data are usually generated by different platforms, and both of which contain sensitive information. Therefore, "How to perform secure and efficient social recommendation across different platforms, where the data are highly-sparse in nature" remains an important challenge. In this work, we bring secure computation techniques into social recommendation, and propose S3Rec, a sparsity-aware secure cross-platform social recommendation framework. As a result, our model can not only improve the recommendation performance of the rating platform by incorporating the sparse social data on the social platform, but also protect data privacy of both platforms. Moreover, to further improve model training efficiency, we propose two secure sparse matrix multiplication protocols based on homomorphic encryption and private information retrieval. Our experiments on two benchmark datasets demonstrate the effectiveness of S3Rec.