 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot audio captioning with audio-language model guidance and audio context keywords
Nov 14, 2023Zero-shot audio captioning aims at automatically generating descriptive textual captions for audio content without prior training for this task. Different from speech recognition which translates audio content that contains spoken language into text, audio captioning is commonly concerned with ambient sounds, or sounds produced by a human performing an action. Inspired by zero-shot image captioning methods, we propose ZerAuCap, a novel framework for summarising such general audio signals in a text caption without requiring task-specific training. In particular, our framework exploits a pre-trained large language model (LLM) for generating the text which is guided by a pre-trained audio-language model to produce captions that describe the audio content. Additionally, we use audio context keywords that prompt the language model to generate text that is broadly relevant to sounds. Our proposed framework achieves state-of-the-art results in zero-shot audio captioning on the AudioCaps and Clotho datasets. Our code is available at https://github.com/ExplainableML/ZerAuCap.
Zero-shot Translation of Attention Patterns in VQA Models to Natural Language
Nov 08, 2023



Converting a model's internals to text can yield human-understandable insights about the model. Inspired by the recent success of training-free approaches for image captioning, we propose ZS-A2T, a zero-shot framework that translates the transformer attention of a given model into natural language without requiring any training. We consider this in the context of Visual Question Answering (VQA). ZS-A2T builds on a pre-trained large language model (LLM), which receives a task prompt, question, and predicted answer, as inputs. The LLM is guided to select tokens which describe the regions in the input image that the VQA model attended to. Crucially, we determine this similarity by exploiting the text-image matching capabilities of the underlying VQA model. Our framework does not require any training and allows the drop-in replacement of different guiding sources (e.g. attribution instead of attention maps), or language models. We evaluate this novel task on textual explanation datasets for VQA, giving state-of-the-art performances for the zero-shot setting on GQA-REX and VQA-X. Our code is available at: https://github.com/ExplainableML/ZS-A2T.
In-Context Impersonation Reveals Large Language Models' Strengths and Biases
May 24, 2023



In everyday conversations, humans can take on different roles and adapt their vocabulary to their chosen roles. We explore whether LLMs can take on, that is impersonate, different roles when they generate text in-context. We ask LLMs to assume different personas before solving vision and language tasks. We do this by prefixing the prompt with a persona that is associated either with a social identity or domain expertise. In a multi-armed bandit task, we find that LLMs pretending to be children of different ages recover human-like developmental stages of exploration. In a language-based reasoning task, we find that LLMs impersonating domain experts perform better than LLMs impersonating non-domain experts. Finally, we test whether LLMs' impersonations are complementary to visual information when describing different categories. We find that impersonation can improve performance: an LLM prompted to be a bird expert describes birds better than one prompted to be a car expert. However, impersonation can also uncover LLMs' biases: an LLM prompted to be a man describes cars better than one prompted to be a woman. These findings demonstrate that LLMs are capable of taking on diverse roles and that this in-context impersonation can be used to uncover their hidden strengths and biases.
Diverse Video Captioning by Adaptive Spatio-temporal Attention
Aug 19, 2022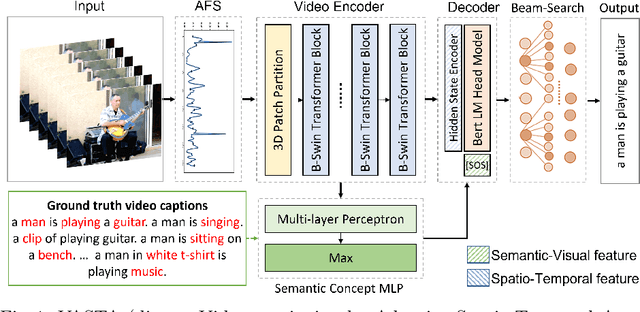
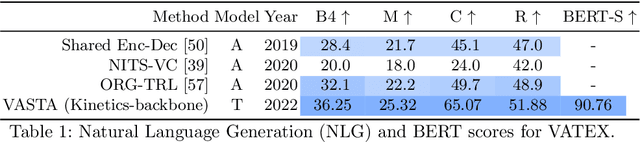
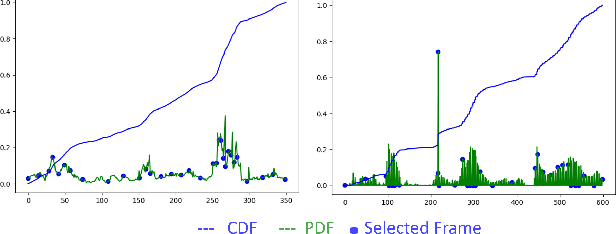
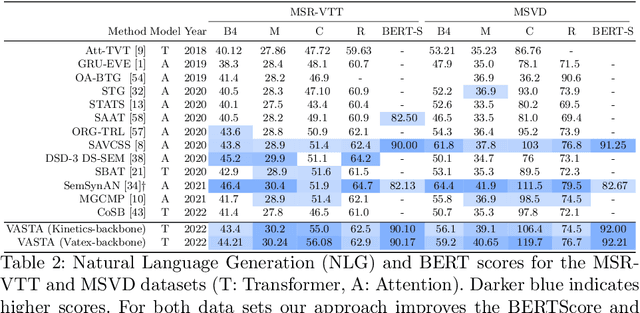
To generate proper captions for videos, the inference needs to identify relevant concepts and pay attention to the spatial relationships between them as well as to the temporal development in the clip. Our end-to-end encoder-decoder video captioning framework incorporates two transformer-based architectures, an adapted transformer for a single joint spatio-temporal video analysis as well as a self-attention-based decoder for advanced text generation. Furthermore, we introduce an adaptive frame selection scheme to reduce the number of required incoming frames while maintaining the relevant content when training both transformers. Additionally, we estimate semantic concepts relevant for video captioning by aggregating all ground truth captions of each sample. Our approach achieves state-of-the-art results on the MSVD, as well as on the large-scale MSR-VTT and the VATEX benchmark datasets considering multiple Natural Language Generation (NLG) metrics. Additional evaluations on diversity scores highlight the expressiveness and diversity in the structure of our generated captions.
CLEVR-X: A Visual Reasoning Dataset for Natural Language Explanations
Apr 05, 2022
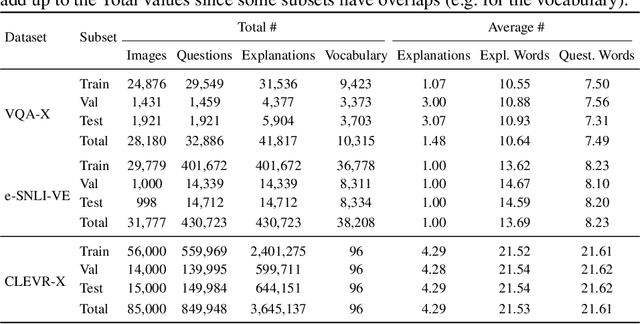
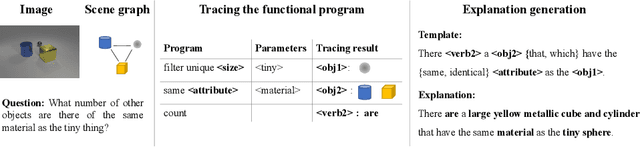

Providing explanations in the context of Visual Question Answering (VQA) presents a fundamental problem in machine learning. To obtain detailed insights into the process of generating natural language explanations for VQA, we introduce the large-scale CLEVR-X dataset that extends the CLEVR dataset with natural language explanations. For each image-question pair in the CLEVR dataset, CLEVR-X contains multiple structured textual explanations which are derived from the original scene graphs. By construction, the CLEVR-X explanations are correct and describe the reasoning and visual information that is necessary to answer a given question. We conducted a user study to confirm that the ground-truth explanations in our proposed dataset are indeed complete and relevant. We present baseline results for generating natural language explanations in the context of VQA using two state-of-the-art frameworks on the CLEVR-X dataset. Furthermore, we provide a detailed analysis of the explanation generation quality for different question and answer types. Additionally, we study the influence of using different numbers of ground-truth explanations on the convergence of natural language generation (NLG) metrics. The CLEVR-X dataset is publicly available at \url{https://explainableml.github.io/CLEVR-X/}.
e-ViL: A Dataset and Benchmark for Natural Language Explanations in Vision-Language Tasks
May 08, 2021


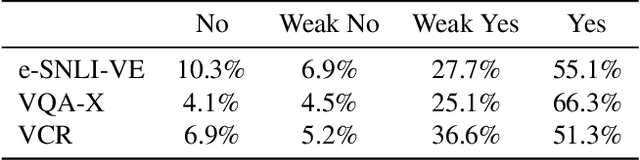
Recently, an increasing number of works have introduced models capable of generating natural language explanations (NLEs) for their predictions on vision-language (VL) tasks. Such models are appealing because they can provide human-friendly and comprehensive explanations. However, there is still a lack of unified evaluation approaches for the explanations generated by these models. Moreover, there are currently only few datasets of NLEs for VL tasks. In this work, we introduce e-ViL, a benchmark for explainable vision-language tasks that establishes a unified evaluation framework and provides the first comprehensive comparison of existing approaches that generate NLEs for VL tasks. e-ViL spans four models and three datasets. Both automatic metrics and human evaluation are used to assess model-generated explanations. We also introduce e-SNLI-VE, the largest existing VL dataset with NLEs (over 430k instances). Finally, we propose a new model that combines UNITER, which learns joint embeddings of images and text, and GPT-2, a pre-trained language model that is well-suited for text generation. It surpasses the previous state-of-the-art by a large margin across all datasets.
Relational Generalized Few-Shot Learning
Jul 22, 2019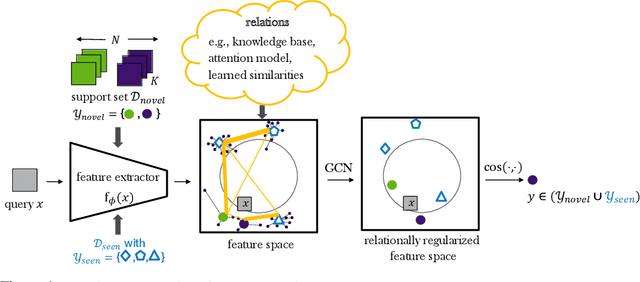
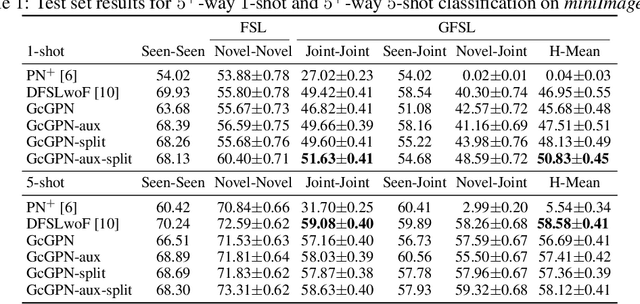
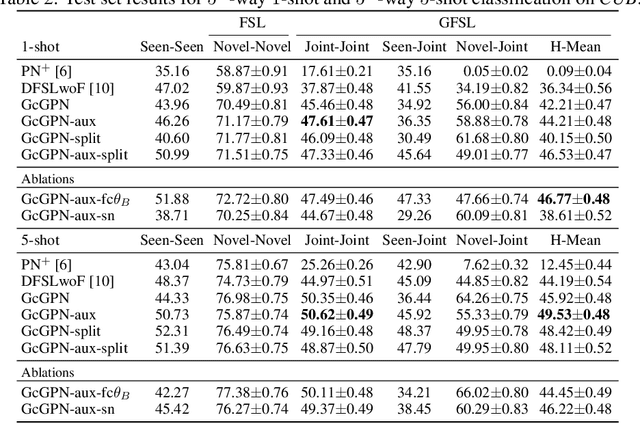
Transferring learned models to novel tasks is a challenging problem, particularly if only very few labeled examples are available. Although this few-shot learning setup has received a lot of attention recently, most proposed methods focus on discriminating novel classes only. Instead, we consider the extended setup of generalized few-shot learning (GFSL), where the model is required to perform classification on the joint label space consisting of both previously seen and novel classes. We propose a graph-based framework that explicitly models relationships between all seen and novel classes in the joint label space. Our model Graph-convolutional Global Prototypical Networks (GcGPN) incorporates these inter-class relations using graph-convolution in order to embed novel class representations into the existing space of previously seen classes in a globally consistent manner. Our approach ensures both fast adaptation and global discrimination, which is the major challenge in GFSL. We demonstrate the benefits of our model on two challenging benchmark datasets.