 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Gaze-based Object Detection in the Wild
Mar 29, 2022
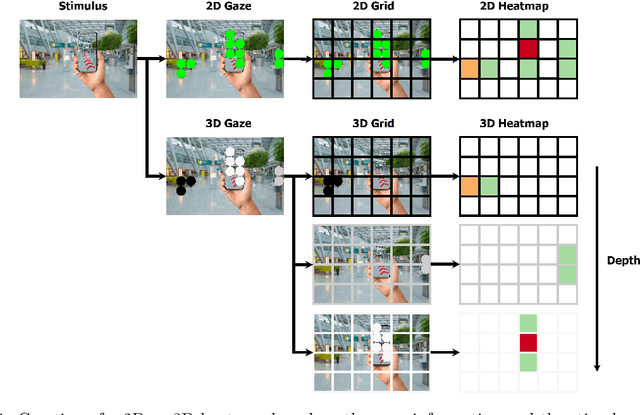
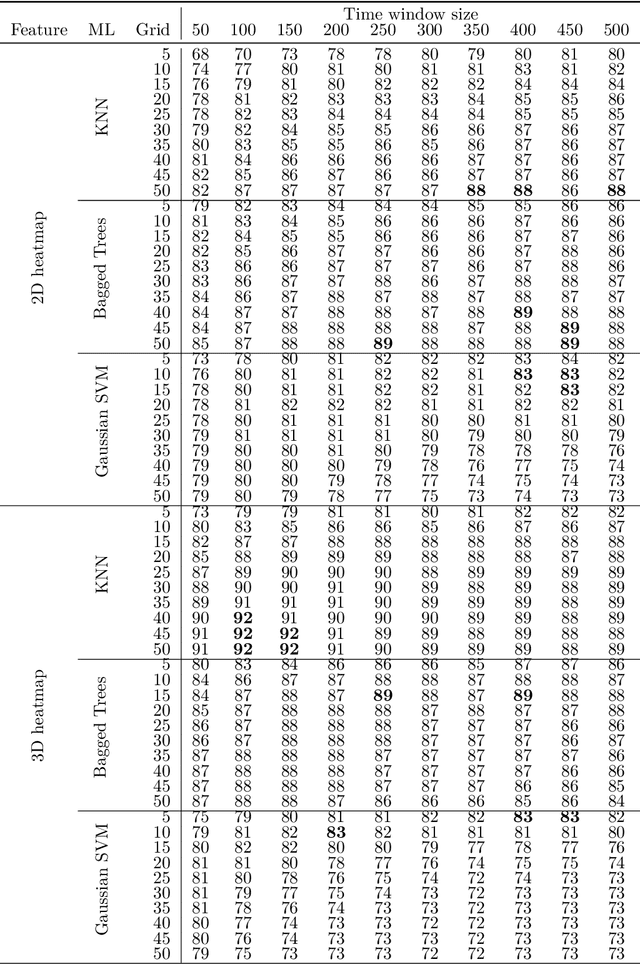
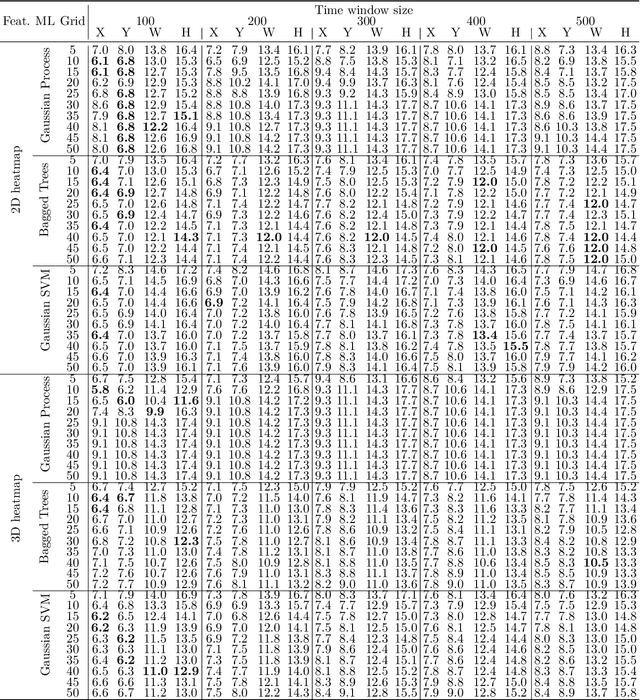
In human-robot collaboration, one challenging task is to teach a robot new yet unknown objects. Thereby, gaze can contain valuable information. We investigate if it is possible to detect objects (object or no object) from gaze data and determine their bounding box parameters. For this purpose, we explore different sizes of temporal windows, which serve as a basis for the computation of heatmaps, i.e., the spatial distribution of the gaze data. Additionally, we analyze different grid sizes of these heatmaps, and various machine learning techniques are applied. To generate the data, we conducted a small study with five subjects who could move freely and thus, turn towards arbitrary objects. This way, we chose a scenario for our data collection that is as realistic as possible. Since the subjects move while facing objects, the heatmaps also contain gaze data trajectories, complicating the detection and parameter regression.
Writer Recognition Using Off-line Handwritten Single Block Characters
Jan 25, 2022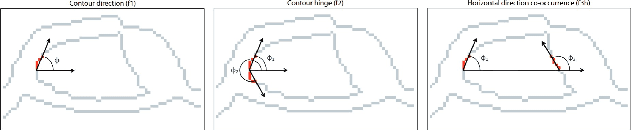

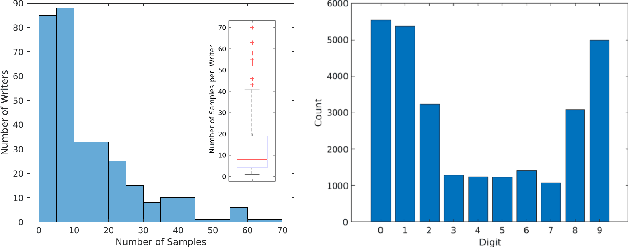
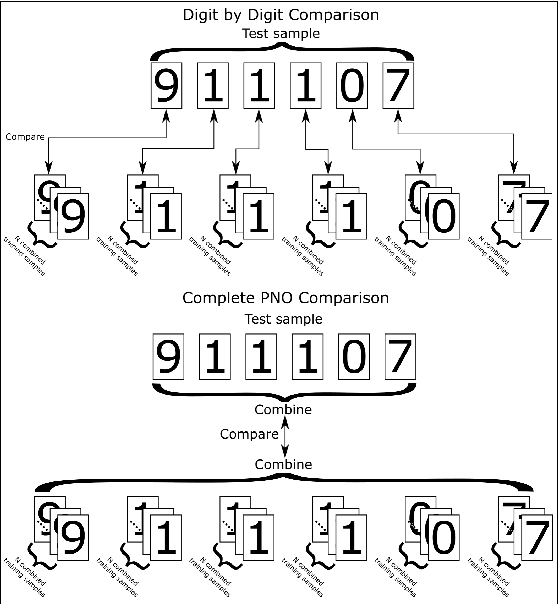
Block characters are often used when filling paper forms for a variety of purposes. We investigate if there is biometric information contained within individual digits of handwritten text. In particular, we use personal identity numbers consisting of the six digits of the date of birth, DoB. We evaluate two recognition approaches, one based on handcrafted features that compute contour directional measurements, and another based on deep features from a ResNet50 model. We use a self-captured database of 317 individuals and 4920 written DoBs in total. Results show the presence of identity-related information in a piece of handwritten information as small as six digits with the DoB. We also analyze the impact of the amount of enrolment samples, varying its number between one and ten. Results with such small amount of data are promising. With ten enrolment samples, the Top-1 accuracy with deep features is around 94%, and reaches nearly 100% by Top-10. The verification accuracy is more modest, with EER>20%with any given feature and enrolment set size, showing that there is still room for improvement.
Learning to Revise References for Faithful Summarization
Apr 13, 2022
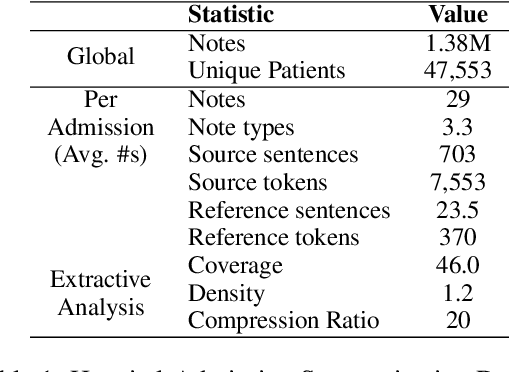

In many real-world scenarios with naturally occurring datasets, reference summaries are noisy and contain information that cannot be inferred from the source text. On large news corpora, removing low quality samples has been shown to reduce model hallucinations. Yet, this method is largely untested for smaller, noisier corpora. To improve reference quality while retaining all data, we propose a new approach: to revise--not remove--unsupported reference content. Without ground-truth supervision, we construct synthetic unsupported alternatives to supported sentences and use contrastive learning to discourage/encourage (un)faithful revisions. At inference, we vary style codes to over-generate revisions of unsupported reference sentences and select a final revision which balances faithfulness and abstraction. We extract a small corpus from a noisy source--the Electronic Health Record (EHR)--for the task of summarizing a hospital admission from multiple notes. Training models on original, filtered, and revised references, we find (1) learning from revised references reduces the hallucination rate substantially more than filtering (18.4\% vs 3.8\%), (2) learning from abstractive (vs extractive) revisions improves coherence, relevance, and faithfulness, (3) beyond redress of noisy data, the revision task has standalone value for the task: as a pre-training objective and as a post-hoc editor.
Adaptivity and Confounding in Multi-Armed Bandit Experiments
Mar 02, 2022
We explore a new model of bandit experiments where a potentially nonstationary sequence of contexts influences arms' performance. Context-unaware algorithms risk confounding while those that perform correct inference face information delays. Our main insight is that an algorithm we call deconfounted Thompson sampling strikes a delicate balance between adaptivity and robustness. Its adaptivity leads to optimal efficiency properties in easy stationary instances, but it displays surprising resilience in hard nonstationary ones which cause other adaptive algorithms to fail.
Normalizing Flow-based Day-Ahead Wind Power Scenario Generation for Profitable and Reliable Delivery Commitments by Wind Farm Operators
Apr 05, 2022
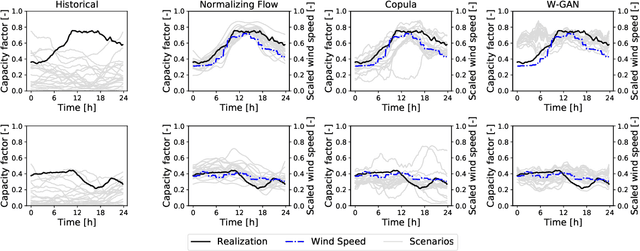
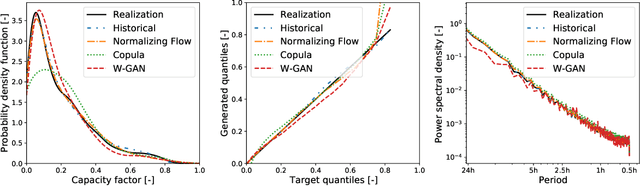
We present a specialized scenario generation method that utilizes forecast information to generate scenarios for the particular usage in day-ahead scheduling problems. In particular, we use normalizing flows to generate wind power generation scenarios by sampling from a conditional distribution that uses day-ahead wind speed forecasts to tailor the scenarios to the specific day. We apply the generated scenarios in a simple stochastic day-ahead bidding problem of a wind electricity producer and run a statistical analysis focusing on whether the scenarios yield profitable and reliable decisions. Compared to conditional scenarios generated from Gaussian copulas and Wasserstein-generative adversarial networks, the normalizing flow scenarios identify the daily trends more accurately and with a lower spread while maintaining a diverse variety. In the stochastic day-ahead bidding problem, the conditional scenarios from all methods lead to significantly more profitable and reliable results compared to an unconditional selection of historical scenarios. The obtained profits using the normalizing flow scenarios are consistently closest to the perfect foresight solution, in particular, for small sets of only five scenarios.
Supporting Schema References in Keyword Queries over Relational Databases
Mar 11, 2022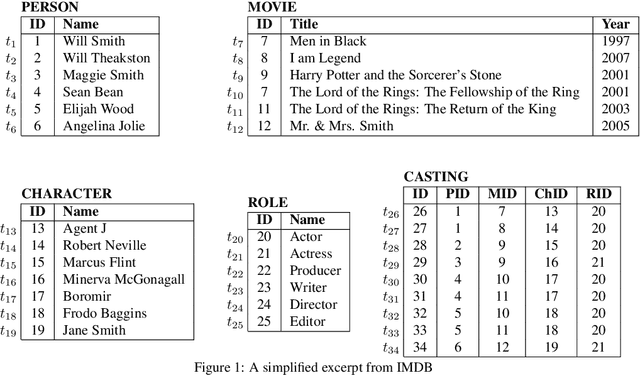


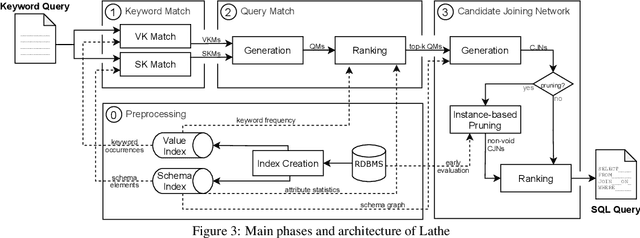
Relational Keyword Search (R-KwS) systems enable naive/informal users to explore and retrieve information from relational databases without knowing schema details or query languages. These systems take the keywords from the input query, locate the elements of the target database that correspond to these keywords, and look for ways to "connect" these elements using information on referential integrity constraints, i.e., key/foreign key pairs. Although several such systems have been proposed in the literature, most of them only support queries whose keywords refer to the contents of the target database and just very few support queries in which keywords refer to elements of the database schema. This paper proposes LATHE, a novel R-KwS designed to support such queries. To this end, in our work, we first generalize the well-known concepts of Query Matches (QMs) and Candidate Joining Networks (CJNs) to handle keywords referring to schema elements and propose new algorithms to generate them. Then, we introduce an approach to automatically select the CJNs that are more likely to represent the user intent when issuing a keyword query. This approach includes two major innovations: a ranking algorithm for selecting better QMs, yielding the generation of fewer but better CJNs, and an eager evaluation strategy for pruning void useless CJNs. We present a comprehensive set of experiments performed with query sets and datasets previously used in experiments with state-of-the-art R-KwS systems and methods. Our results indicate that LATHE can handle a wider variety of keyword queries while remaining highly effective, even for large databases with intricate schemas.
Cross-Domain Sentiment Classification With Contrastive Learning and Mutual Information Maximization
Oct 30, 2020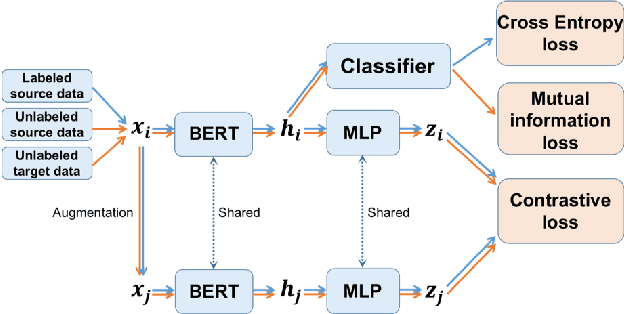
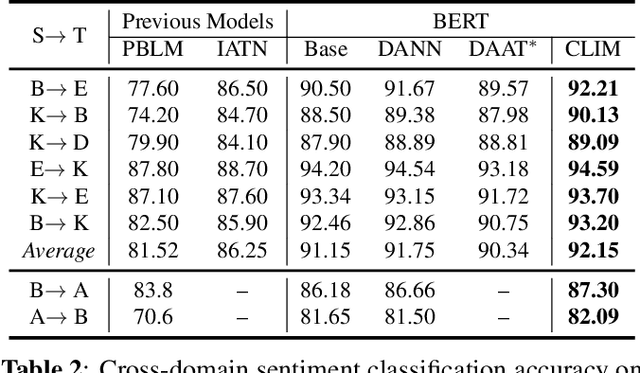

Contrastive learning (CL) has been successful as a powerful representation learning method. In this work we propose CLIM: Contrastive Learning with mutual Information Maximization, to explore the potential of CL on cross-domain sentiment classification. To the best of our knowledge, CLIM is the first to adopt contrastive learning for natural language processing (NLP) tasks across domains. Due to scarcity of labels on the target domain, we introduce mutual information maximization (MIM) apart from CL to exploit the features that best support the final prediction. Furthermore, MIM is able to maintain a relatively balanced distribution of the model's prediction, and enlarges the margin between classes on the target domain. The larger margin increases our model's robustness and enables the same classifier to be optimal across domains. Consequently, we achieve new state-of-the-art results on the Amazon-review dataset as well as the airlines dataset, showing the efficacy of our proposed method CLIM.
Projection: A Mixed-Initiative Research Process
Jan 09, 2022
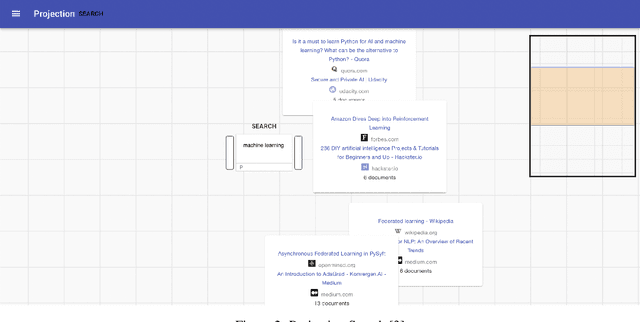
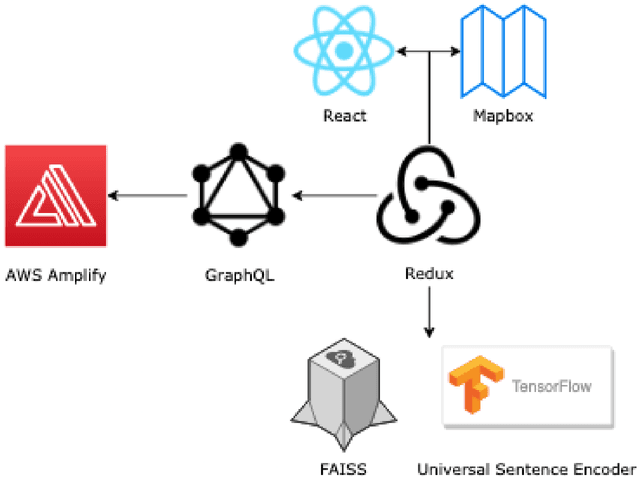
Communication of dense information between humans and machines is relatively low bandwidth. Many modern search and recommender systems operate as machine learning black boxes, giving little insight as to how they represent information or why they take certain actions. We present Projection, a mixed-initiative interface that aims to increase the bandwidth of communication between humans and machines throughout the research process. The interface supports adding context to searches and visualizing information in multiple dimensions with techniques such as hierarchical clustering and spatial projections. Potential customers have shown interest in the application integrating their research outlining and search processes, enabling them to structure their searches in hierarchies, and helping them visualize related spaces of knowledge.
Multi-View Transformer for 3D Visual Grounding
Apr 05, 2022
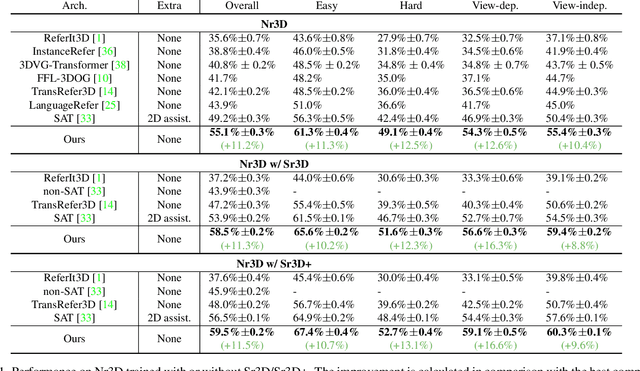
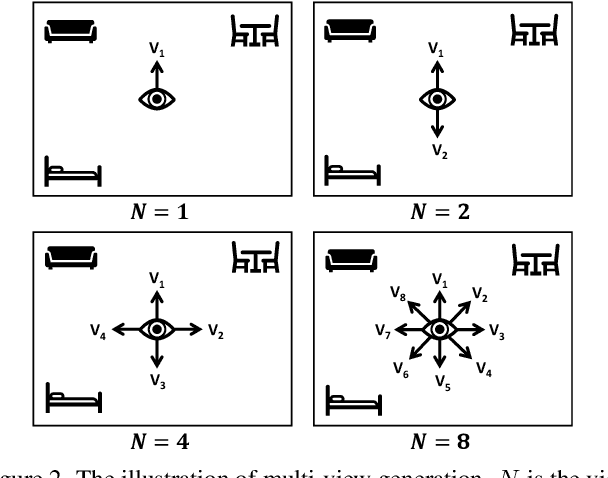
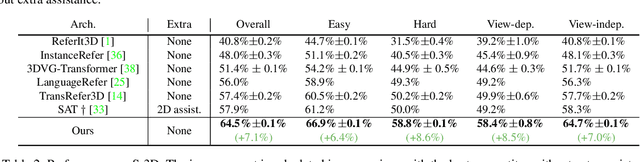
The 3D visual grounding task aims to ground a natural language description to the targeted object in a 3D scene, which is usually represented in 3D point clouds. Previous works studied visual grounding under specific views. The vision-language correspondence learned by this way can easily fail once the view changes. In this paper, we propose a Multi-View Transformer (MVT) for 3D visual grounding. We project the 3D scene to a multi-view space, in which the position information of the 3D scene under different views are modeled simultaneously and aggregated together. The multi-view space enables the network to learn a more robust multi-modal representation for 3D visual grounding and eliminates the dependence on specific views. Extensive experiments show that our approach significantly outperforms all state-of-the-art methods. Specifically, on Nr3D and Sr3D datasets, our method outperforms the best competitor by 11.2% and 7.1% and even surpasses recent work with extra 2D assistance by 5.9% and 6.6%. Our code is available at https://github.com/sega-hsj/MVT-3DVG.
AILTTS: Adversarial Learning of Intermediate Acoustic Feature for End-to-End Lightweight Text-to-Speech
Apr 05, 2022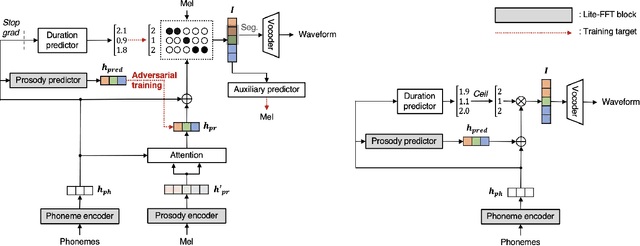
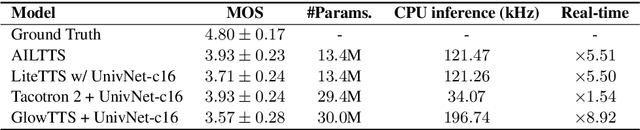
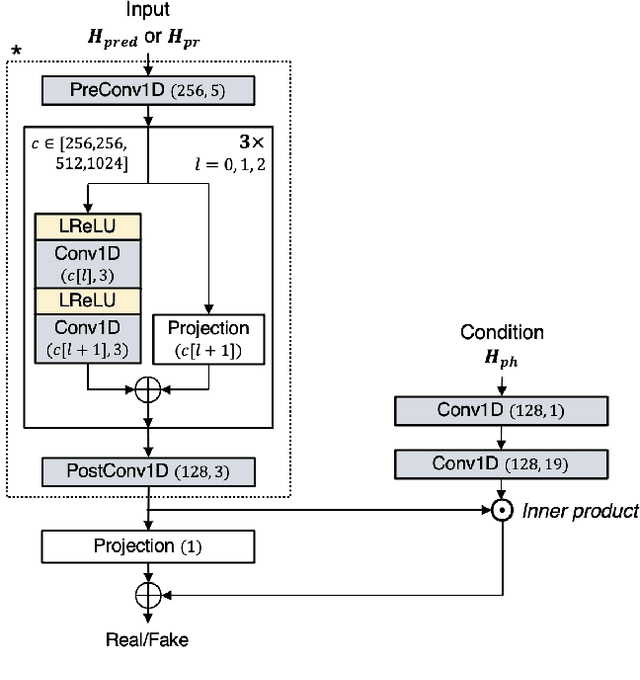

The quality of end-to-end neural text-to-speech (TTS) systems highly depends on the reliable estimation of intermediate acoustic features from text inputs. To reduce the complexity of the speech generation process, several non-autoregressive TTS systems directly find a mapping relationship between text and waveforms. However, the generation quality of these system is unsatisfactory due to the difficulty in modeling the dynamic nature of prosodic information. In this paper, we propose an effective prosody predictor that successfully replicates the characteristics of prosodic features extracted from mel-spectrograms. Specifically, we introduce a generative model-based conditional discriminator to enable the estimated embeddings have highly informative prosodic features, which significantly enhances the expressiveness of generated speech. Since the estimated embeddings obtained by the proposed method are highly correlated with acoustic features, the time-alignment of input texts and intermediate features is greatly simplified, which results in faster convergence. Our proposed model outperforms several publicly available models based on various objective and subjective evaluation metrics, even using a relatively small number of parameters.