 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Restoring Negative Information in Few-Shot Object Detection
Oct 22, 2020
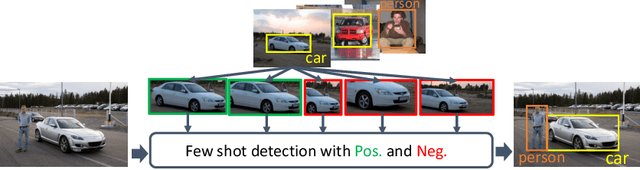
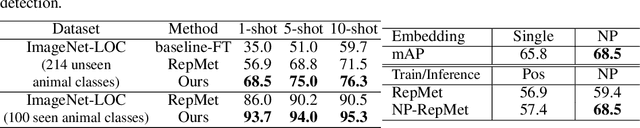
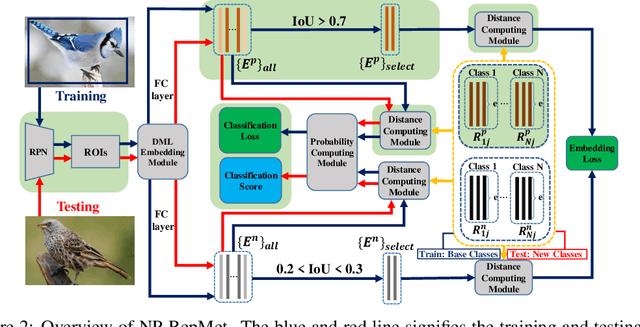

Few-shot learning has recently emerged as a new challenge in the deep learning field: unlike conventional methods that train the deep neural networks (DNNs) with a large number of labeled data, it asks for the generalization of DNNs on new classes with few annotated samples. Recent advances in few-shot learning mainly focus on image classification while in this paper we focus on object detection. The initial explorations in few-shot object detection tend to simulate a classification scenario by using the positive proposals in images with respect to certain object class while discarding the negative proposals of that class. Negatives, especially hard negatives, however, are essential to the embedding space learning in few-shot object detection. In this paper, we restore the negative information in few-shot object detection by introducing a new negative- and positive-representative based metric learning framework and a new inference scheme with negative and positive representatives. We build our work on a recent few-shot pipeline RepMet with several new modules to encode negative information for both training and testing. Extensive experiments on ImageNet-LOC and PASCAL VOC show our method substantially improves the state-of-the-art few-shot object detection solutions. Our code is available at https://github.com/yang-yk/NP-RepMet.
Style-Guided Domain Adaptation for Face Presentation Attack Detection
Mar 28, 2022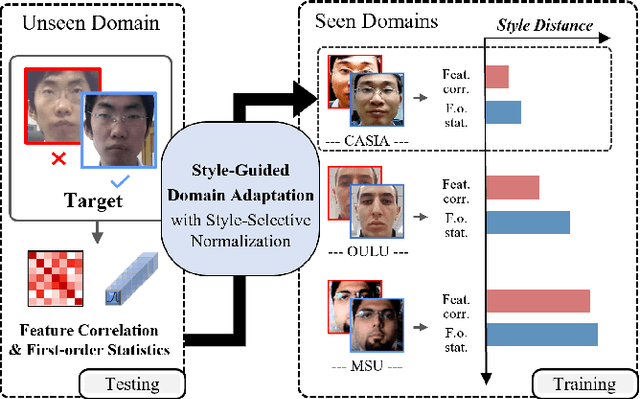
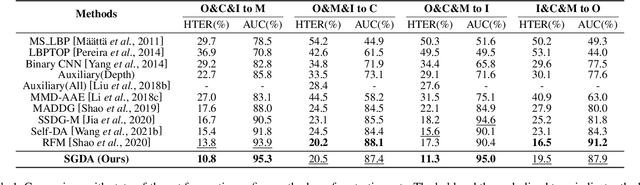
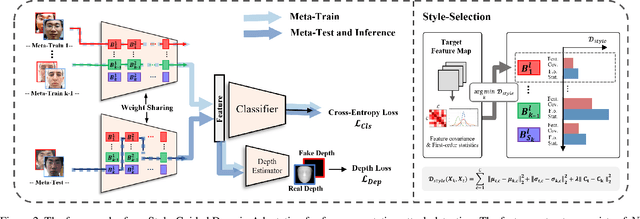

Domain adaptation (DA) or domain generalization (DG) for face presentation attack detection (PAD) has attracted attention recently with its robustness against unseen attack scenarios. Existing DA/DG-based PAD methods, however, have not yet fully explored the domain-specific style information that can provide knowledge regarding attack styles (e.g., materials, background, illumination and resolution). In this paper, we introduce a novel Style-Guided Domain Adaptation (SGDA) framework for inference-time adaptive PAD. Specifically, Style-Selective Normalization (SSN) is proposed to explore the domain-specific style information within the high-order feature statistics. The proposed SSN enables the adaptation of the model to the target domain by reducing the style difference between the target and the source domains. Moreover, we carefully design Style-Aware Meta-Learning (SAML) to boost the adaptation ability, which simulates the inference-time adaptation with style selection process on virtual test domain. In contrast to previous domain adaptation approaches, our method does not require either additional auxiliary models (e.g., domain adaptors) or the unlabeled target domain during training, which makes our method more practical to PAD task. To verify our experiments, we utilize the public datasets: MSU-MFSD, CASIA-FASD, OULU-NPU and Idiap REPLAYATTACK. In most assessments, the result demonstrates a notable gap of performance compared to the conventional DA/DG-based PAD methods.
Infographics Wizard: Flexible Infographics Authoring and Design Exploration
Apr 21, 2022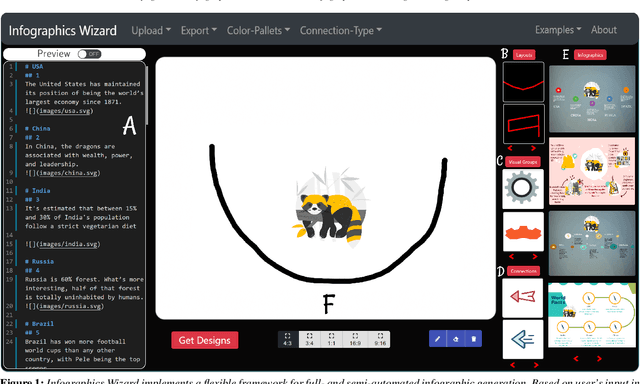
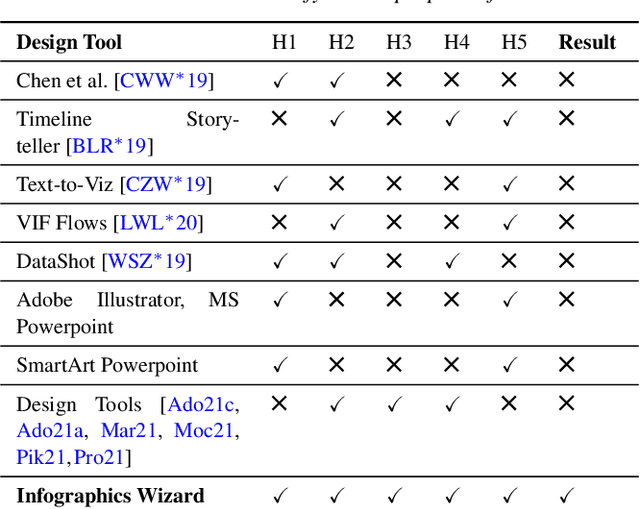
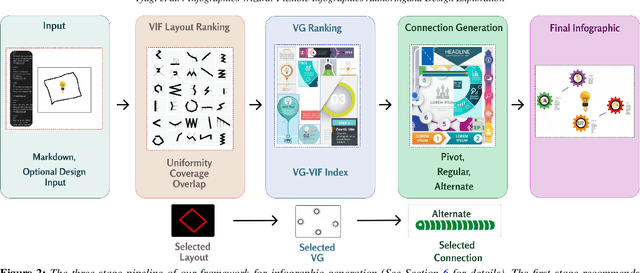
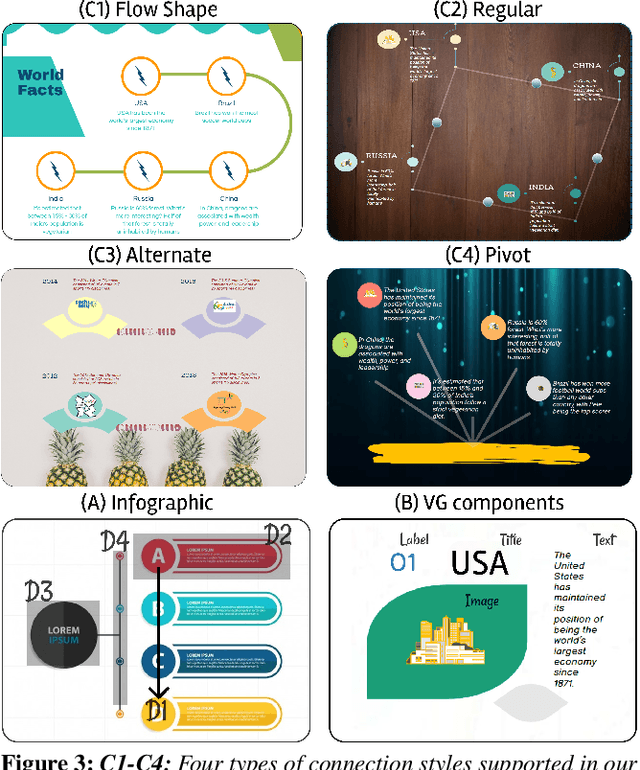
Infographics are an aesthetic visual representation of information following specific design principles of human perception. Designing infographics can be a tedious process for non-experts and time-consuming, even for professional designers. With the help of designers, we propose a semi-automated infographic framework for general structured and flow-based infographic design generation. For novice designers, our framework automatically creates and ranks infographic designs for a user-provided text with no requirement for design input. However, expert designers can still provide custom design inputs to customize the infographics. We will also contribute an individual visual group (VG) designs dataset (in SVG), along with a 1k complete infographic image dataset with segmented VGs in this work. Evaluation results confirm that by using our framework, designers from all expertise levels can generate generic infographic designs faster than existing methods while maintaining the same quality as hand-designed infographics templates.
Adaptive Local Kernels Formulation of Mutual Information with Application to Active Post-Seismic Building Damage Inference
May 24, 2021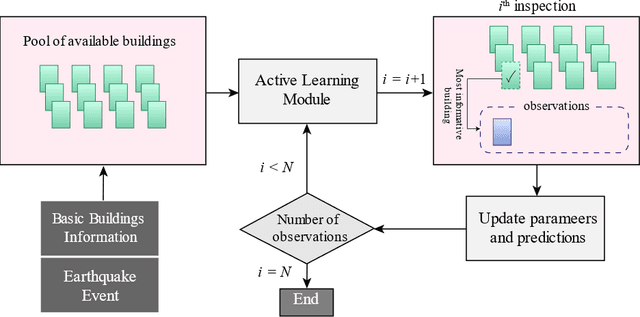

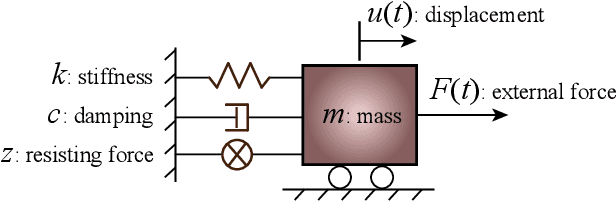
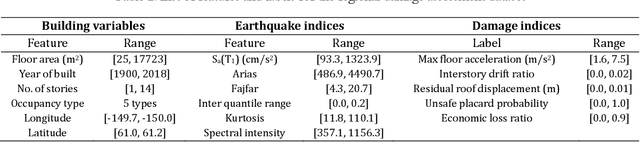
The abundance of training data is not guaranteed in various supervised learning applications. One of these situations is the post-earthquake regional damage assessment of buildings. Querying the damage label of each building requires a thorough inspection by experts, and thus, is an expensive task. A practical approach is to sample the most informative buildings in a sequential learning scheme. Active learning methods recommend the most informative cases that are able to maximally reduce the generalization error. The information theoretic measure of mutual information (MI) is one of the most effective criteria to evaluate the effectiveness of the samples in a pool-based sample selection scenario. However, the computational complexity of the standard MI algorithm prevents the utilization of this method on large datasets. A local kernels strategy was proposed to reduce the computational costs, but the adaptability of the kernels to the observed labels was not considered in the original formulation of this strategy. In this article, an adaptive local kernels methodology is developed that allows for the conformability of the kernels to the observed output data while enhancing the computational complexity of the standard MI algorithm. The proposed algorithm is developed to work on a Gaussian process regression (GPR) framework, where the kernel hyperparameters are updated after each label query using the maximum likelihood estimation. In the sequential learning procedure, the updated hyperparameters can be used in the MI kernel matrices to improve the sample suggestion performance. The advantages are demonstrated on a simulation of the 2018 Anchorage, AK, earthquake. It is shown that while the proposed algorithm enables GPR to reach acceptable performance with fewer training data, the computational demands remain lower than the standard local kernels strategy.
Sampling Is All You Need on Modeling Long-Term User Behaviors for CTR Prediction
May 20, 2022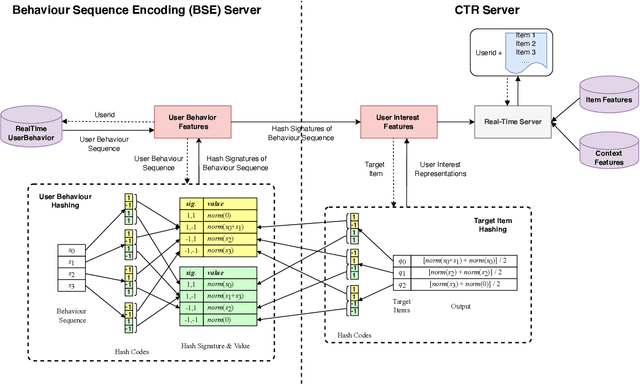

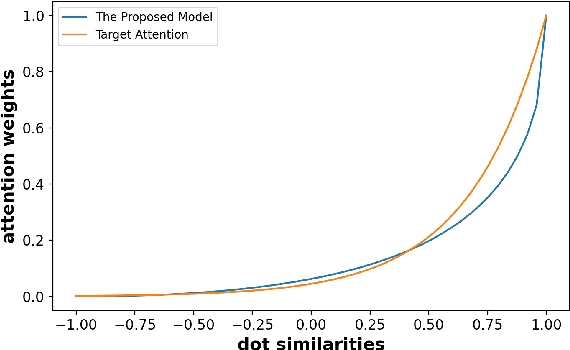
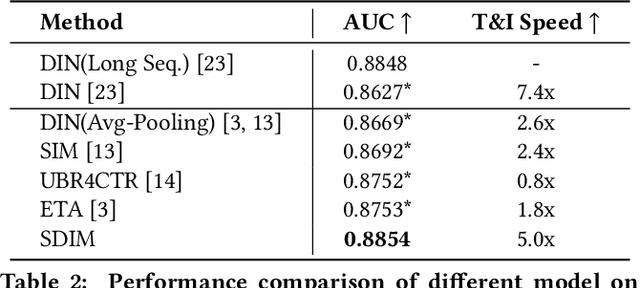
Rich user behavior data has been proven to be of great value for Click-Through Rate (CTR) prediction applications, especially in industrial recommender, search, or advertising systems. However, it's non-trivial for real-world systems to make full use of long-term user behaviors due to the strict requirements of online serving time. Most previous works adopt the retrieval-based strategy, where a small number of user behaviors are retrieved first for subsequent attention. However, the retrieval-based methods are sub-optimal and would cause more or less information losses, and it's difficult to balance the effectiveness and efficiency of the retrieval algorithm. In this paper, we propose \textbf{SDIM} (\textbf{S}ampling-based \textbf{D}eep \textbf{I}nterest \textbf{M}odeling), a simple yet effective sampling-based end-to-end approach for modeling long-term user behaviors. We sample from multiple hash functions to generate hash signatures of the candidate item and each item in the user behavior sequence, and obtain the user interest by directly gathering behavior items associated with the candidate item with the same hash signature. We show theoretically and experimentally that the proposed method performs on par with standard attention-based models on modeling long-term user behaviors, while being sizable times faster. We also introduce the deployment of SDIM in our system. Specifically, we decouple the behavior sequence hashing, which is the most time-consuming part, from the CTR model by designing a separate module named BSE (behavior Sequence Encoding). BSE is latency-free for the CTR server, enabling us to model extremely long user behaviors. Both offline and online experiments are conducted to demonstrate the effectiveness of SDIM. SDIM now has been deployed online in the search system of Meituan APP.
Can Predominant Credible Information Suppress Misinformation in Crises? Empirical Studies of Tweets Related to Prevention Measures during COVID-19
Feb 01, 2021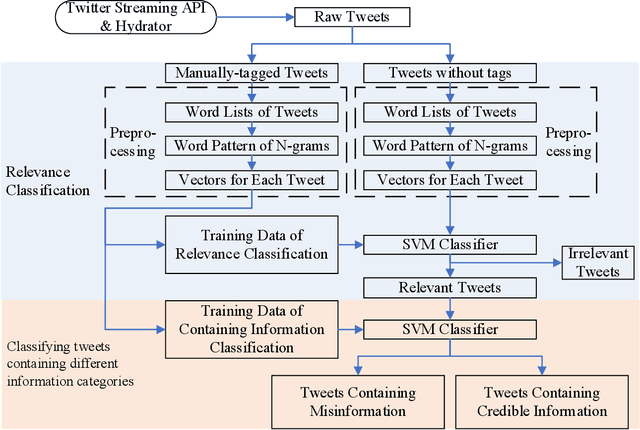
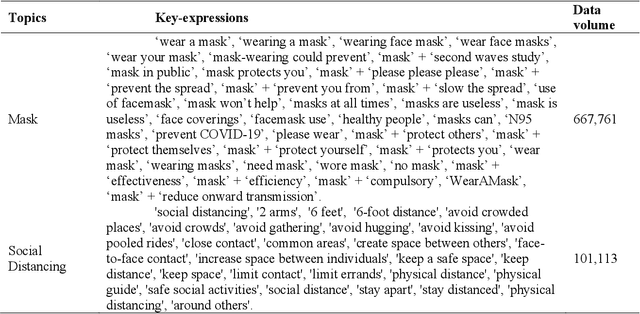
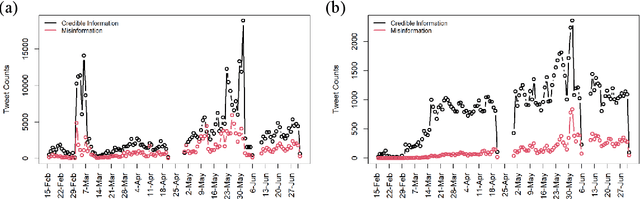
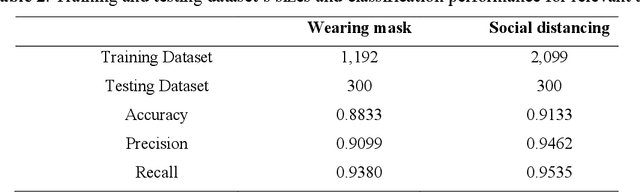
During COVID-19, misinformation on social media affects the adoption of appropriate prevention behaviors. It is urgent to suppress the misinformation to prevent negative public health consequences. Although an array of studies has proposed misinformation suppression strategies, few have investigated the role of predominant credible information during crises. None has examined its effect quantitatively using longitudinal social media data. Therefore, this research investigates the temporal correlations between credible information and misinformation, and whether predominant credible information can suppress misinformation for two prevention measures (i.e. topics), i.e. wearing masks and social distancing using tweets collected from February 15 to June 30, 2020. We trained Support Vector Machine classifiers to retrieve relevant tweets and classify tweets containing credible information and misinformation for each topic. Based on cross-correlation analyses of credible and misinformation time series for both topics, we find that the previously predominant credible information can lead to the decrease of misinformation (i.e. suppression) with a time lag. The research findings provide empirical evidence for suppressing misinformation with credible information in complex online environments and suggest practical strategies for future information management during crises and emergencies.
Characterizing player's playing styles based on Player Vectors for each playing position in the Chinese Football Super League
May 05, 2022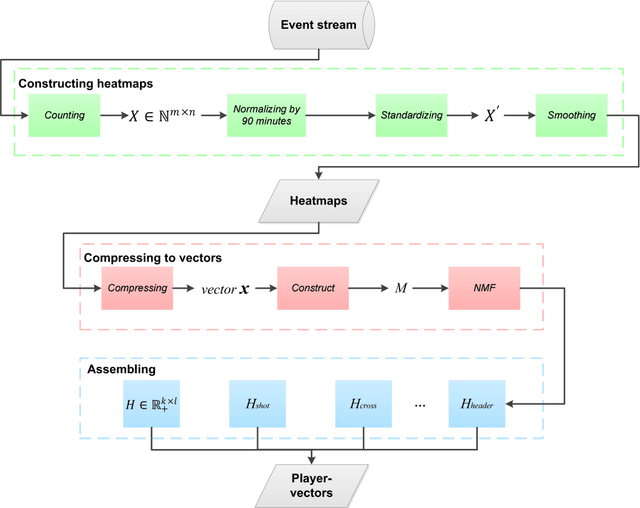
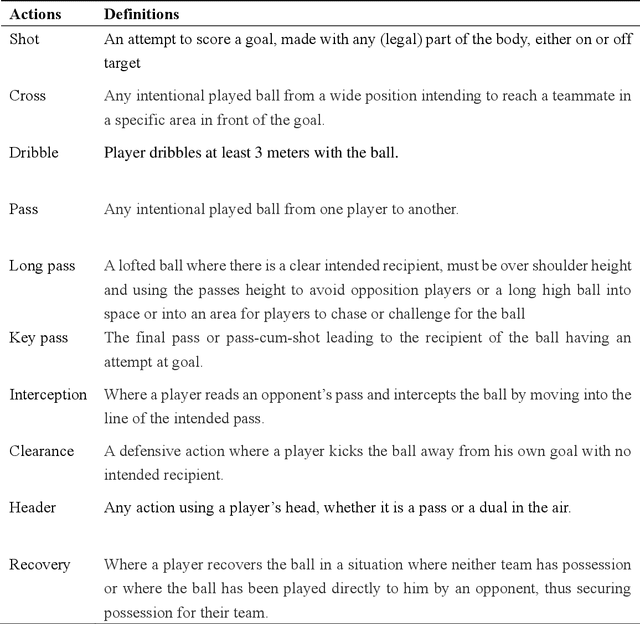
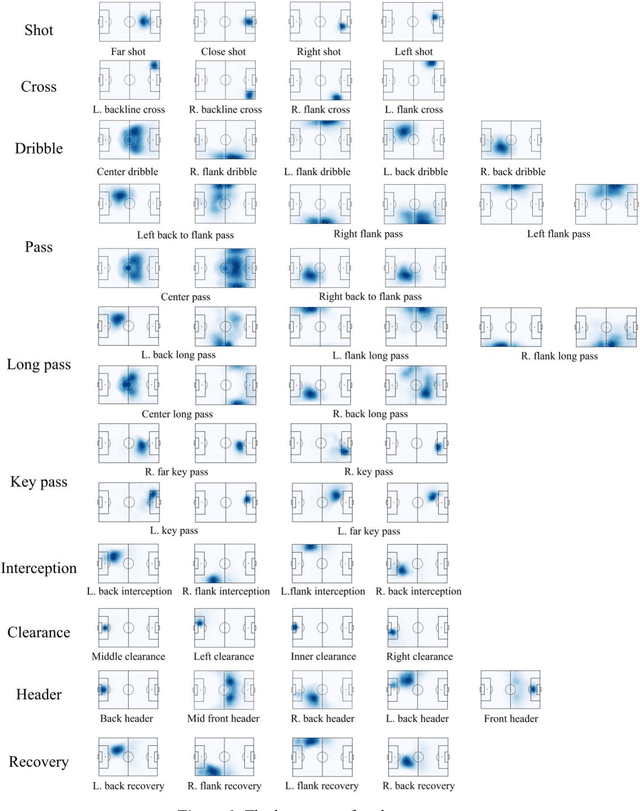
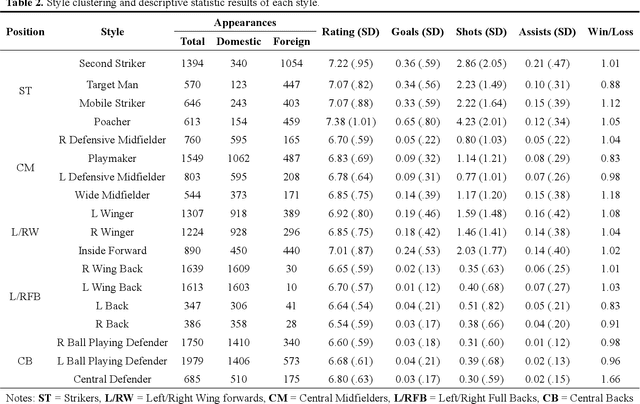
Characterizing playing style is important for football clubs on scouting, monitoring and match preparation. Previous studies considered a player's style as a combination of technical performances, failing to consider the spatial information. Therefore, this study aimed to characterize the playing styles of each playing position in the Chinese Football Super League (CSL) matches, integrating a recently adopted Player Vectors framework. Data of 960 matches from 2016-2019 CSL were used. Match ratings, and ten types of match events with the corresponding coordinates for all the lineup players whose on-pitch time exceeded 45 minutes were extracted. Players were first clustered into 8 positions. A player vector was constructed for each player in each match based on the Player Vectors using Nonnegative Matrix Factorization (NMF). Another NMF process was run on the player vectors to extract different types of playing styles. The resulting player vectors discovered 18 different playing styles in the CSL. Six performance indicators of each style were investigated to observe their contributions. In general, the playing styles of forwards and midfielders are in line with football performance evolution trends, while the styles of defenders should be reconsidered. Multifunctional playing styles were also found in high rated CSL players.
Improving Multimodal Speech Recognition by Data Augmentation and Speech Representations
Apr 27, 2022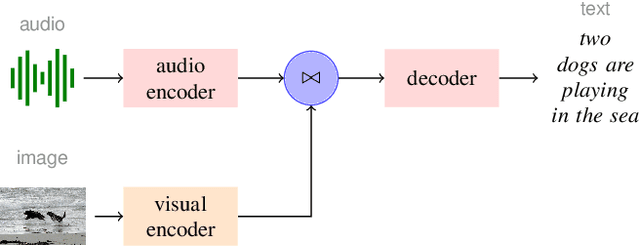
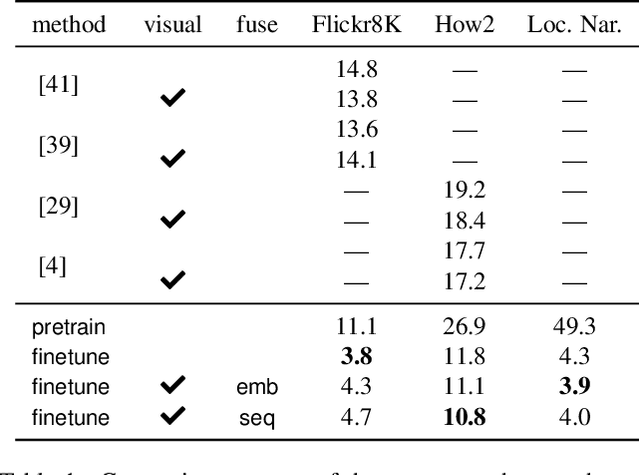
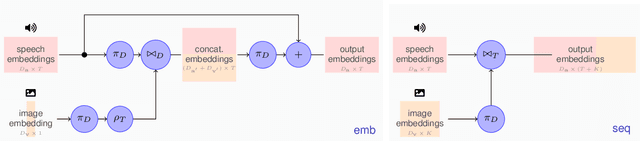
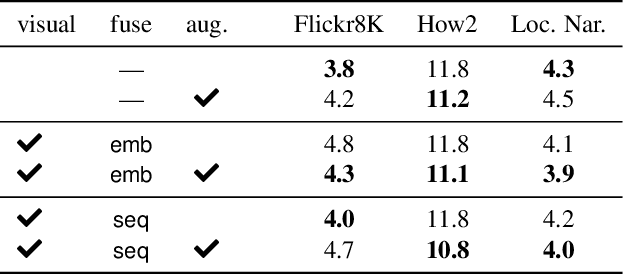
Multimodal speech recognition aims to improve the performance of automatic speech recognition (ASR) systems by leveraging additional visual information that is usually associated to the audio input. While previous approaches make crucial use of strong visual representations, e.g. by finetuning pretrained image recognition networks, significantly less attention has been paid to its counterpart: the speech component. In this work, we investigate ways of improving the base speech recognition system by following similar techniques to the ones used for the visual encoder, namely, transferring representations and data augmentation. First, we show that starting from a pretrained ASR significantly improves the state-of-the-art performance; remarkably, even when building upon a strong unimodal system, we still find gains by including the visual modality. Second, we employ speech data augmentation techniques to encourage the multimodal system to attend to the visual stimuli. This technique replaces previously used word masking and comes with the benefits of being conceptually simpler and yielding consistent improvements in the multimodal setting. We provide empirical results on three multimodal datasets, including the newly introduced Localized Narratives.
Hybrid CNN Based Attention with Category Prior for User Image Behavior Modeling
May 05, 2022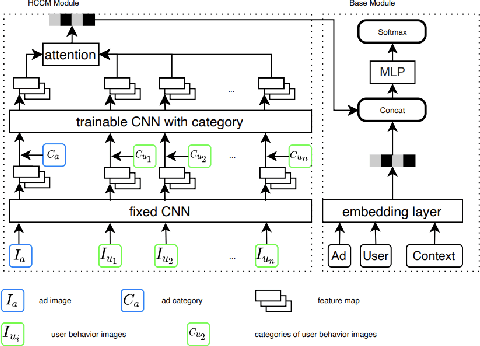
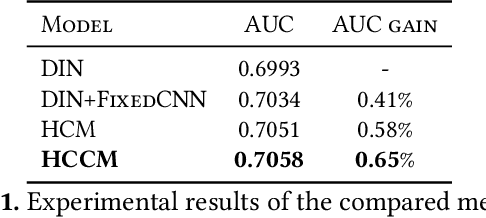
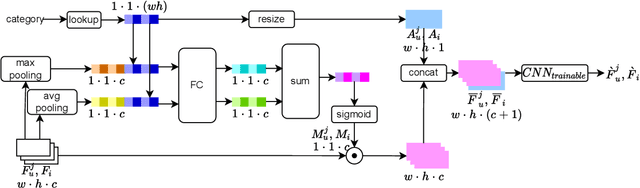
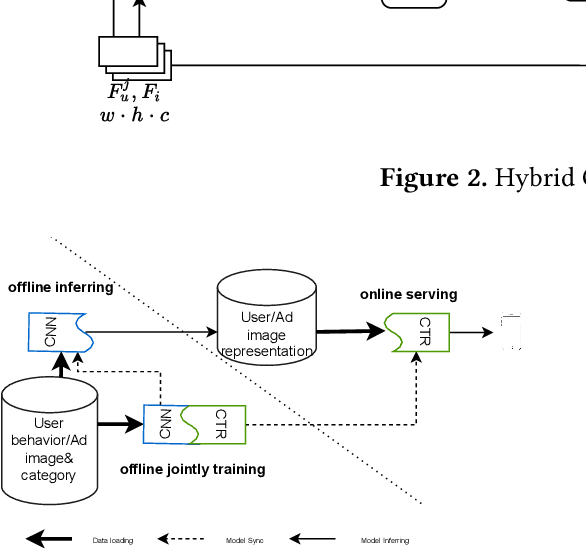
User historical behaviors are proved useful for Click Through Rate (CTR) prediction in online advertising system. In Meituan, one of the largest e-commerce platform in China, an item is typically displayed with its image and whether a user clicks the item or not is usually influenced by its image, which implies that user's image behaviors are helpful for understanding user's visual preference and improving the accuracy of CTR prediction. Existing user image behavior models typically use a two-stage architecture, which extracts visual embeddings of images through off-the-shelf Convolutional Neural Networks (CNNs) in the first stage, and then jointly trains a CTR model with those visual embeddings and non-visual features. We find that the two-stage architecture is sub-optimal for CTR prediction. Meanwhile, precisely labeled categories in online ad systems contain abundant visual prior information, which can enhance the modeling of user image behaviors. However, off-the-shelf CNNs without category prior may extract category unrelated features, limiting CNN's expression ability. To address the two issues, we propose a hybrid CNN based attention module, unifying user's image behaviors and category prior, for CTR prediction. Our approach achieves significant improvements in both online and offline experiments on a billion scale real serving dataset.
Neural Network Activation Quantization with Bitwise Information Bottlenecks
Jun 09, 2020
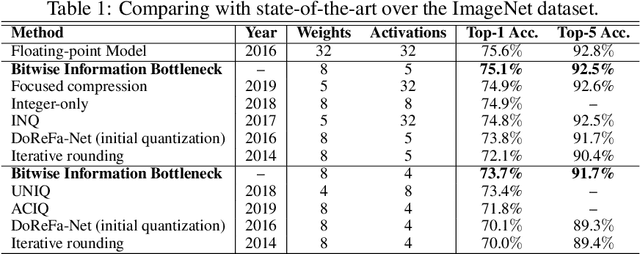


Recent researches on information bottleneck shed new light on the continuous attempts to open the black box of neural signal encoding. Inspired by the problem of lossy signal compression for wireless communication, this paper presents a Bitwise Information Bottleneck approach for quantizing and encoding neural network activations. Based on the rate-distortion theory, the Bitwise Information Bottleneck attempts to determine the most significant bits in activation representation by assigning and approximating the sparse coefficient associated with each bit. Given the constraint of a limited average code rate, the information bottleneck minimizes the rate-distortion for optimal activation quantization in a flexible layer-by-layer manner. Experiments over ImageNet and other datasets show that, by minimizing the quantization rate-distortion of each layer, the neural network with information bottlenecks achieves the state-of-the-art accuracy with low-precision activation. Meanwhile, by reducing the code rate, the proposed method can improve the memory and computational efficiency by over six times compared with the deep neural network with standard single-precision representation. Codes will be available on GitHub when the paper is accepted \url{https://github.com/BitBottleneck/PublicCode}.