 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Spatio-Temporal Zero-shot Action Recognition with Language-driven Description Attributes
Nov 03, 2025Vision-Language Models (VLMs) have demonstrated impressive capabilities in zero-shot action recognition by learning to associate video embeddings with class embeddings. However, a significant challenge arises when relying solely on action classes to provide semantic context, particularly due to the presence of multi-semantic words, which can introduce ambiguity in understanding the intended concepts of actions. To address this issue, we propose an innovative approach that harnesses web-crawled descriptions, leveraging a large-language model to extract relevant keywords. This method reduces the need for human annotators and eliminates the laborious manual process of attribute data creation. Additionally, we introduce a spatio-temporal interaction module designed to focus on objects and action units, facilitating alignment between description attributes and video content. In our zero-shot experiments, our model achieves impressive results, attaining accuracies of 81.0%, 53.1%, and 68.9% on UCF-101, HMDB-51, and Kinetics-600, respectively, underscoring the model's adaptability and effectiveness across various downstream tasks.
ID-EA: Identity-driven Text Enhancement and Adaptation with Textual Inversion for Personalized Text-to-Image Generation
Jul 16, 2025Recently, personalized portrait generation with a text-to-image diffusion model has significantly advanced with Textual Inversion, emerging as a promising approach for creating high-fidelity personalized images. Despite its potential, current Textual Inversion methods struggle to maintain consistent facial identity due to semantic misalignments between textual and visual embedding spaces regarding identity. We introduce ID-EA, a novel framework that guides text embeddings to align with visual identity embeddings, thereby improving identity preservation in a personalized generation. ID-EA comprises two key components: the ID-driven Enhancer (ID-Enhancer) and the ID-conditioned Adapter (ID-Adapter). First, the ID-Enhancer integrates identity embeddings with a textual ID anchor, refining visual identity embeddings derived from a face recognition model using representative text embeddings. Then, the ID-Adapter leverages the identity-enhanced embedding to adapt the text condition, ensuring identity preservation by adjusting the cross-attention module in the pre-trained UNet model. This process encourages the text features to find the most related visual clues across the foreground snippets. Extensive quantitative and qualitative evaluations demonstrate that ID-EA substantially outperforms state-of-the-art methods in identity preservation metrics while achieving remarkable computational efficiency, generating personalized portraits approximately 15 times faster than existing approaches.
Style-Guided Domain Adaptation for Face Presentation Attack Detection
Mar 28, 2022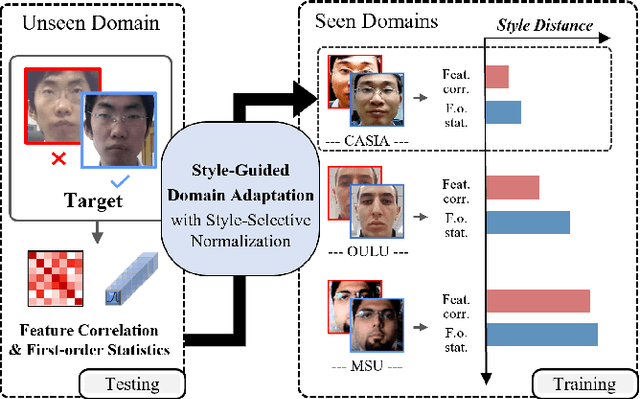
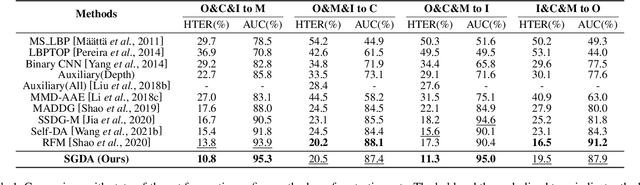
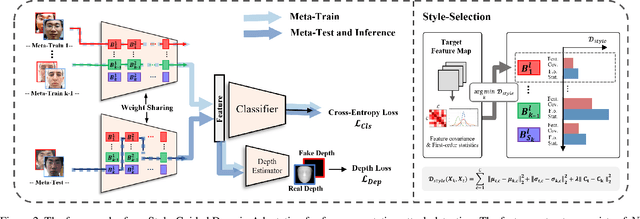

Domain adaptation (DA) or domain generalization (DG) for face presentation attack detection (PAD) has attracted attention recently with its robustness against unseen attack scenarios. Existing DA/DG-based PAD methods, however, have not yet fully explored the domain-specific style information that can provide knowledge regarding attack styles (e.g., materials, background, illumination and resolution). In this paper, we introduce a novel Style-Guided Domain Adaptation (SGDA) framework for inference-time adaptive PAD. Specifically, Style-Selective Normalization (SSN) is proposed to explore the domain-specific style information within the high-order feature statistics. The proposed SSN enables the adaptation of the model to the target domain by reducing the style difference between the target and the source domains. Moreover, we carefully design Style-Aware Meta-Learning (SAML) to boost the adaptation ability, which simulates the inference-time adaptation with style selection process on virtual test domain. In contrast to previous domain adaptation approaches, our method does not require either additional auxiliary models (e.g., domain adaptors) or the unlabeled target domain during training, which makes our method more practical to PAD task. To verify our experiments, we utilize the public datasets: MSU-MFSD, CASIA-FASD, OULU-NPU and Idiap REPLAYATTACK. In most assessments, the result demonstrates a notable gap of performance compared to the conventional DA/DG-based PAD methods.