 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Few-Shot Font Generation by Learning Fine-Grained Local Styles
May 23, 2022
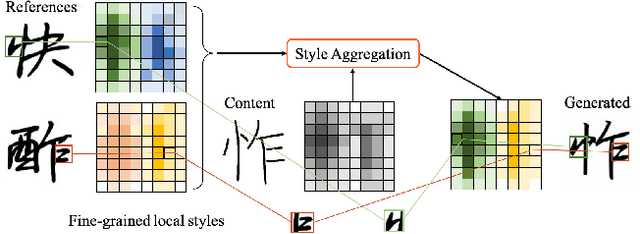
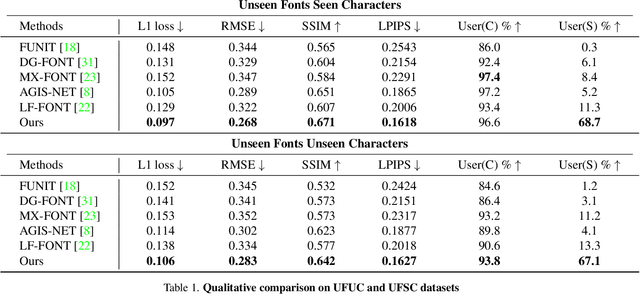
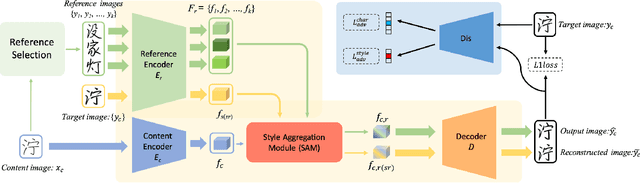
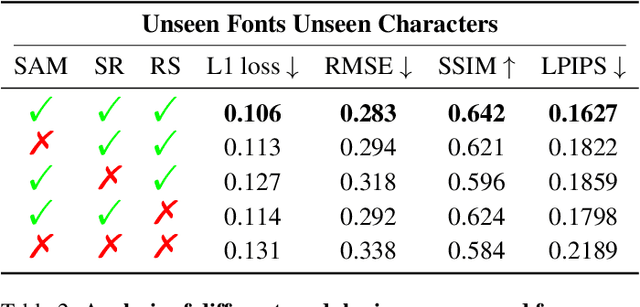
Few-shot font generation (FFG), which aims to generate a new font with a few examples, is gaining increasing attention due to the significant reduction in labor cost. A typical FFG pipeline considers characters in a standard font library as content glyphs and transfers them to a new target font by extracting style information from the reference glyphs. Most existing solutions explicitly disentangle content and style of reference glyphs globally or component-wisely. However, the style of glyphs mainly lies in the local details, i.e. the styles of radicals, components, and strokes together depict the style of a glyph. Therefore, even a single character can contain different styles distributed over spatial locations. In this paper, we propose a new font generation approach by learning 1) the fine-grained local styles from references, and 2) the spatial correspondence between the content and reference glyphs. Therefore, each spatial location in the content glyph can be assigned with the right fine-grained style. To this end, we adopt cross-attention over the representation of the content glyphs as the queries and the representations of the reference glyphs as the keys and values. Instead of explicitly disentangling global or component-wise modeling, the cross-attention mechanism can attend to the right local styles in the reference glyphs and aggregate the reference styles into a fine-grained style representation for the given content glyphs. The experiments show that the proposed method outperforms the state-of-the-art methods in FFG. In particular, the user studies also demonstrate the style consistency of our approach significantly outperforms previous methods.
SpaIn-Net: Spatially-Informed Stereophonic Music Source Separation
Feb 15, 2022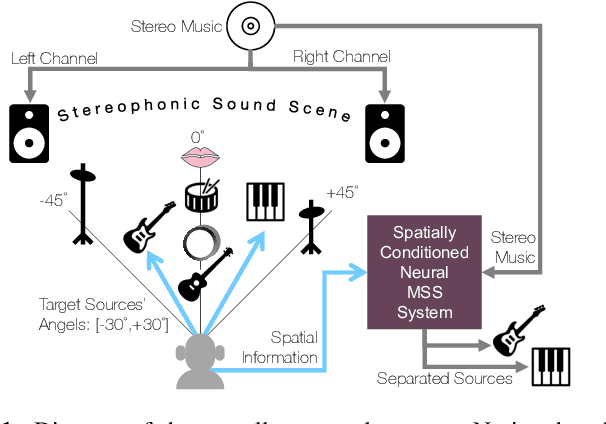
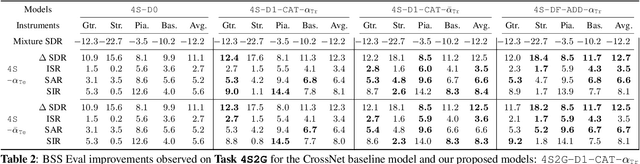
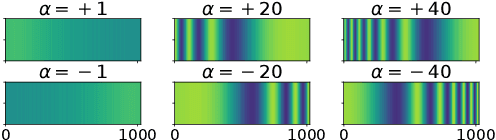
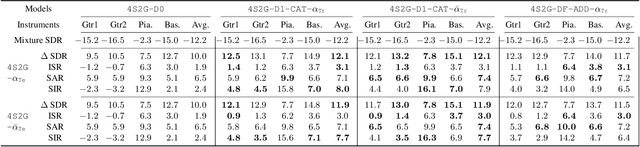
With the recent advancements of data driven approaches using deep neural networks, music source separation has been formulated as an instrument-specific supervised problem. While existing deep learning models implicitly absorb the spatial information conveyed by the multi-channel input signals, we argue that a more explicit and active use of spatial information could not only improve the separation process but also provide an entry-point for many user-interaction based tools. To this end, we introduce a control method based on the stereophonic location of the sources of interest, expressed as the panning angle. We present various conditioning mechanisms, including the use of raw angle and its derived feature representations, and show that spatial information helps. Our proposed approaches improve the separation performance compared to location agnostic architectures by 1.8 dB SI-SDR in our Slakh-based simulated experiments. Furthermore, the proposed methods allow for the disentanglement of same-class instruments, for example, in mixtures containing two guitar tracks. Finally, we also demonstrate that our approach is robust to incorrect source panning information, which can be incurred by our proposed user interaction.
Dense residual Transformer for image denoising
May 14, 2022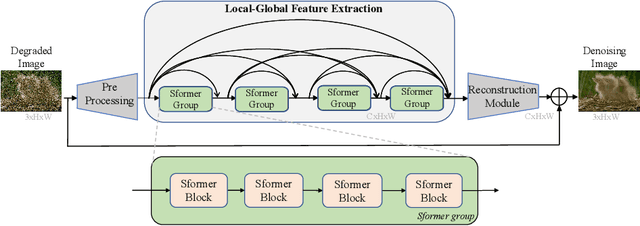
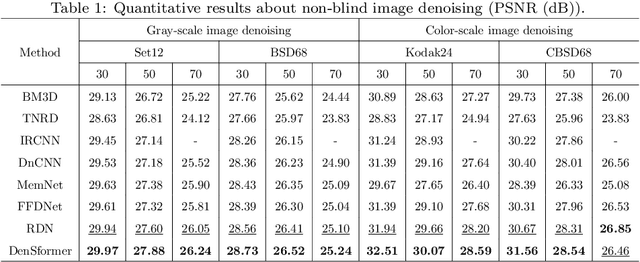
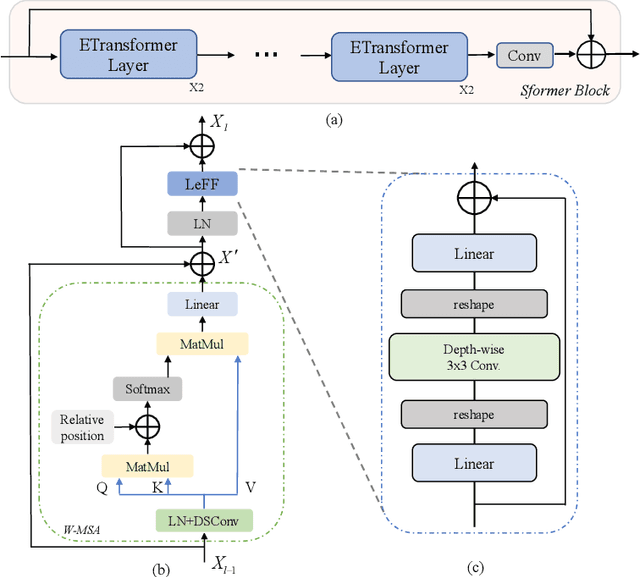
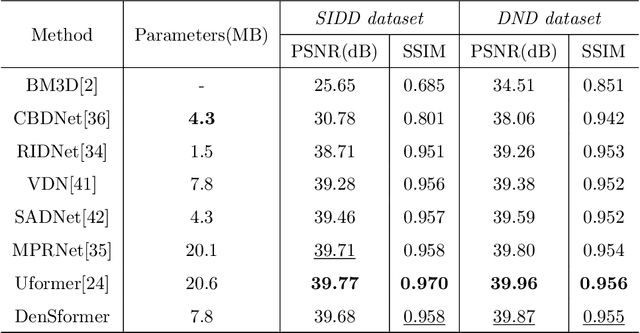
Image denoising is an important low-level computer vision task, which aims to reconstruct a noise-free and high-quality image from a noisy image. With the development of deep learning, convolutional neural network (CNN) has been gradually applied and achieved great success in image denoising, image compression, image enhancement, etc. Recently, Transformer has been a hot technique, which is widely used to tackle computer vision tasks. However, few Transformer-based methods have been proposed for low-level vision tasks. In this paper, we proposed an image denoising network structure based on Transformer, which is named DenSformer. DenSformer consists of three modules, including a preprocessing module, a local-global feature extraction module, and a reconstruction module. Specifically, the local-global feature extraction module consists of several Sformer groups, each of which has several ETransformer layers and a convolution layer, together with a residual connection. These Sformer groups are densely skip-connected to fuse the feature of different layers, and they jointly capture the local and global information from the given noisy images. We conduct our model on comprehensive experiments. Experimental results prove that our DenSformer achieves improvement compared to some state-of-the-art methods, both for the synthetic noise data and real noise data, in the objective and subjective evaluations.
How to Minimize the Weighted Sum AoI in Two-Source Status Update Systems: OMA or NOMA?
May 06, 2022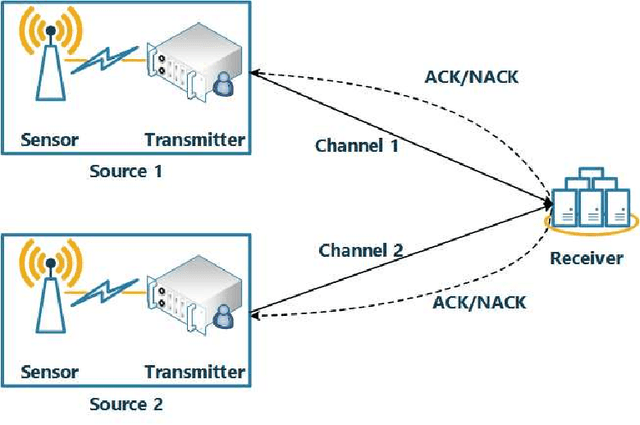
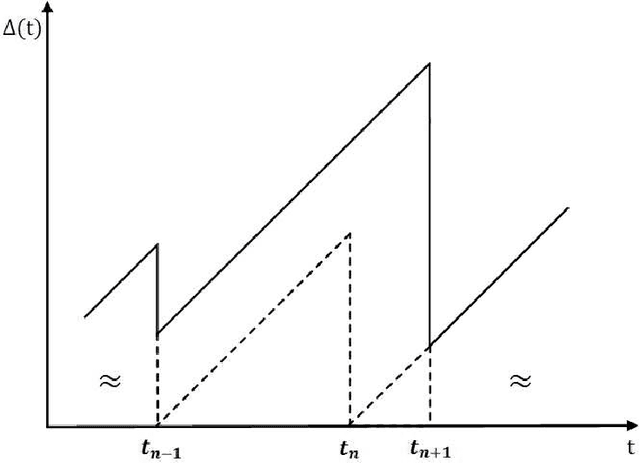
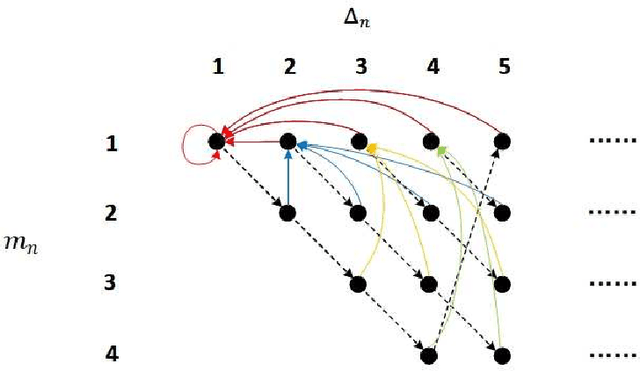
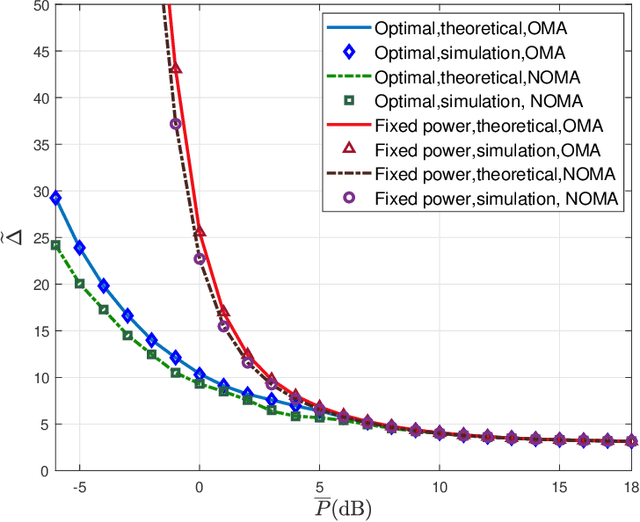
In this paper, the minimization of the weighted sum average age of information (AoI) in a two-source status update communication system is studied. Two independent sources send update packets to a common destination node in a time-slotted manner under the limit of maximum retransmission rounds. Different multiple access schemes, i.e., orthogonal multiple access (OMA) and non-orthogonal multiple access (NOMA) are exploited here over a block-fading multiple access channel (MAC). Constrained Markov decision process (CMDP) problems are formulated to describe the AoI minimization problems considering both transmission schemes. The Lagrangian method is utilised to convert CMDP problems to unconstraint Markov decision process (MDP) problems and corresponding algorithms to derive the power allocation policies are obtained. On the other hand, for the case of unknown environments, two online reinforcement learning approaches considering both multiple access schemes are proposed to achieve near-optimal age performance. Numerical simulations validate the improvement of the proposed policy in terms of weighted sum AoI compared to the fixed power transmission policy, and illustrate that NOMA is more favorable in case of larger packet size.
Are Deep Neural Architectures Losing Information? Invertibility Is Indispensable
Sep 07, 2020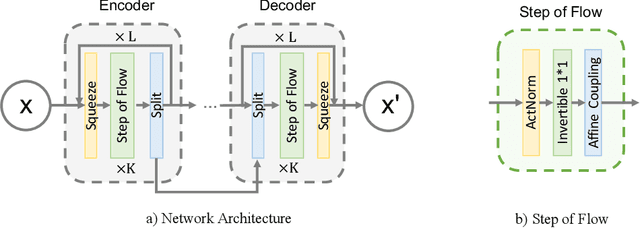
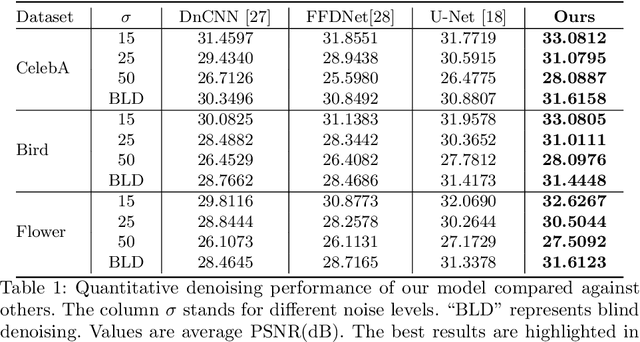

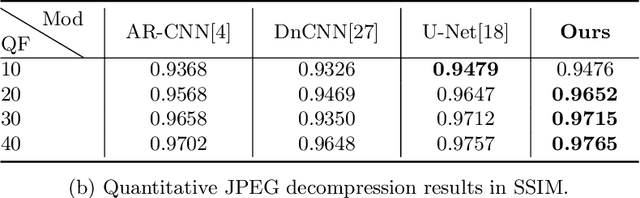
Ever since the advent of AlexNet, designing novel deep neural architectures for different tasks has consistently been a productive research direction. Despite the exceptional performance of various architectures in practice, we study a theoretical question: what is the condition for deep neural architectures to preserve all the information of the input data? Identifying the information lossless condition for deep neural architectures is important, because tasks such as image restoration require keep the detailed information of the input data as much as possible. Using the definition of mutual information, we show that: a deep neural architecture can preserve maximum details about the given data if and only if the architecture is invertible. We verify the advantages of our Invertible Restoring Autoencoder (IRAE) network by comparing it with competitive models on three perturbed image restoration tasks: image denoising, jpeg image decompression and image inpainting. Experimental results show that IRAE consistently outperforms non-invertible ones. Our model even contains far fewer parameters. Thus, it may be worthwhile to try replacing standard components of deep neural architectures, such as residual blocks and ReLU, with their invertible counterparts. We believe our work provides a unique perspective and direction for future deep learning research.
Towards Robotic Laboratory Automation Plug & Play: Teaching-free Robot Integration with the LAPP Digital Twin
May 17, 2022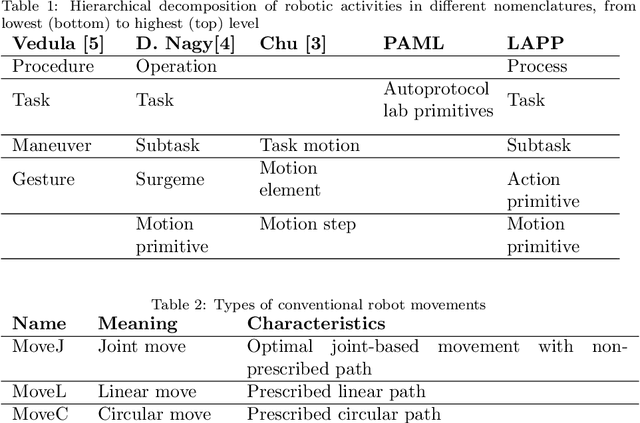
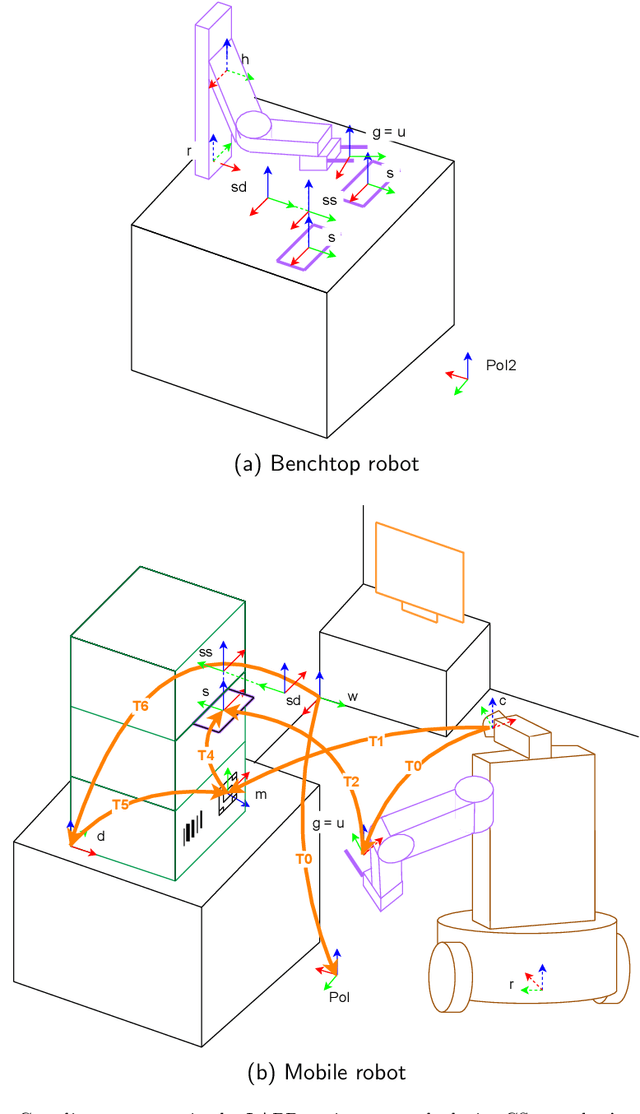
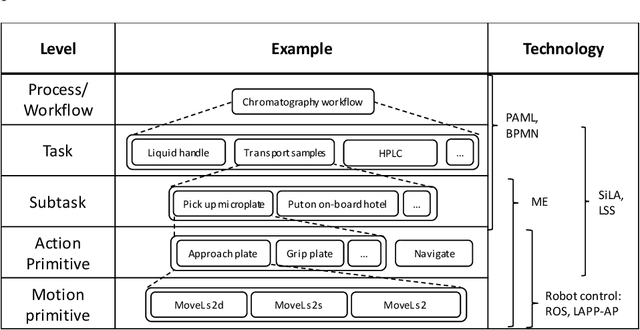
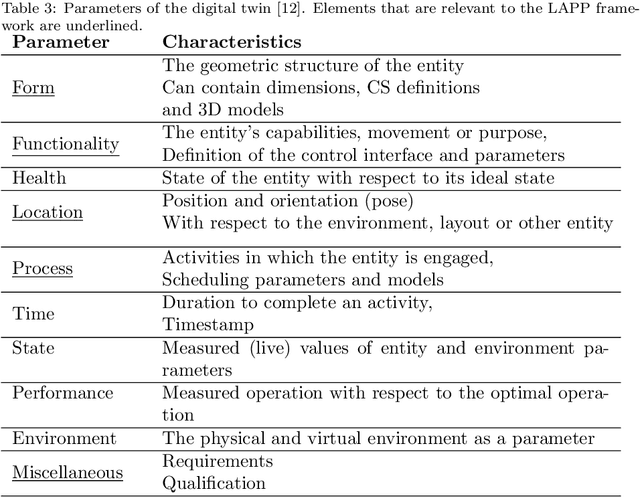
The Laboratory Automation Plug & Play (LAPP) framework is a high-level abstraction layer that makes the autonomous operation of life science laboratory robots possible. The plug & play nature lies in the fact that the manual teaching and configuration of robots is not required. A digital twin (DT) based concept is proposed that outlines the types of information that has to be provided for each relevant component of the system. In particular, for the devices that the robot interfaces with, the robot positions have to be defined beforehand in a device-attached coordinate system (CS) by the vendor. This CS has to be detectable by the vision system of the robot by means of optical markers placed on the front side of the device. With that, the robot is capable of tending the machine by performing the pick-and-place type transportation of standard sample carriers. This basic use case is the primary scope of the LAPP-DT framework. The hardware scope is limited to simple benchtop and mobile manipulators with parallel grippers at this stage. This paper first provides an overview of relevant literature and state-of-the-art solutions, after which it outlines the framework on the conceptual level, followed by the specification of the relevant DT parameters for the robot, for the devices and for the facility. Finally, appropriate technologies and strategies are identified for the implementation.
A Method of Query Graph Reranking for Knowledge Base Question Answering
Apr 27, 2022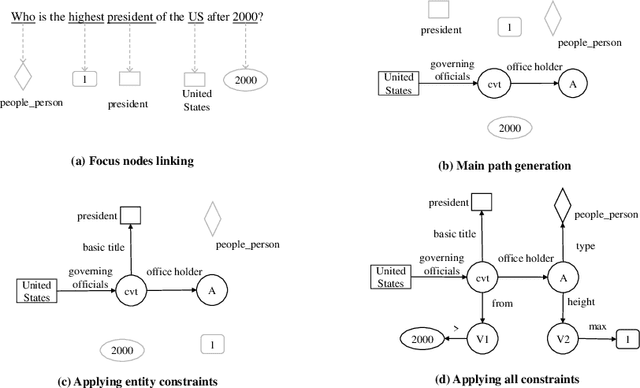

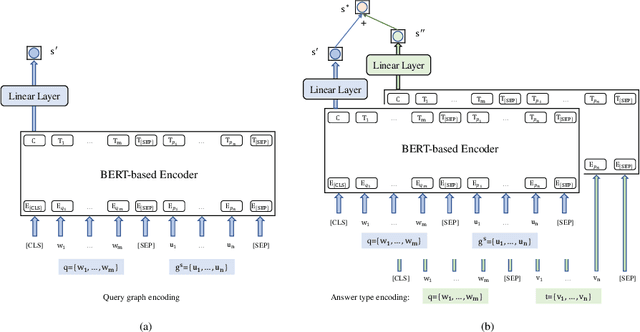
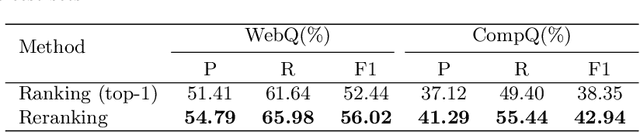
This paper presents a novel reranking method to better choose the optimal query graph, a sub-graph of knowledge graph, to retrieve the answer for an input question in Knowledge Base Question Answering (KBQA). Existing methods suffer from a severe problem that there is a significant gap between top-1 performance and the oracle score of top-n results. To address this problem, our method divides the choosing procedure into two steps: query graph ranking and query graph reranking. In the first step, we provide top-n query graphs for each question. Then we propose to rerank the top-n query graphs by combining with the information of answer type. Experimental results on two widely used datasets show that our proposed method achieves the best results on the WebQuestions dataset and the second best on the ComplexQuestions dataset.
Phase-Aware Spoof Speech Detection Based on Res2Net with Phase Network
Mar 21, 2022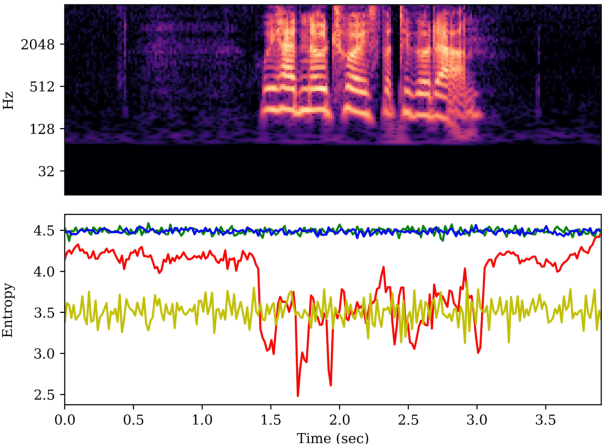
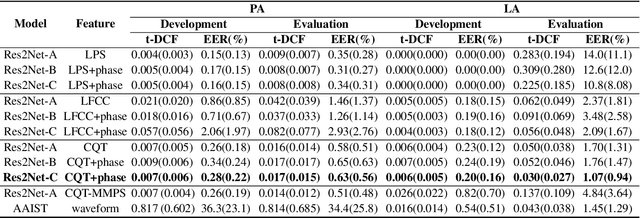
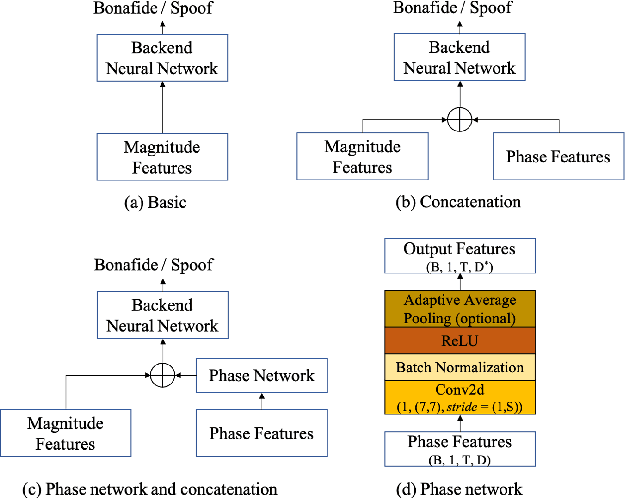

The spoof speech detection (SSD) is the essential countermeasure for automatic speaker verification systems. Although SSD with magnitude features in the frequency domain has shown promising results, the phase information also can be important to capture the artefacts of certain types of spoofing attacks. Thus, both magnitude and phase features must be considered to ensure the generalization ability to diverse types of spoofing attacks. In this paper, we investigate the failure reason of feature-level fusion of the previous works through the entropy analysis from which we found that the randomness difference between magnitude and phase features is large, which can interrupt the feature-level fusion via backend neural network; thus, we propose a phase network to reduce that difference. Our SSD system: phase network equipped Res2Net achieved significant performance improvement, specifically in the spoofing attack for which the phase information is considered to be important. Also, we demonstrate our SSD system in both known- and unknown-kind SSD scenarios for practical applications.
MCRB-based Performance Analysis of 6G Localization under Hardware Impairments
Apr 27, 2022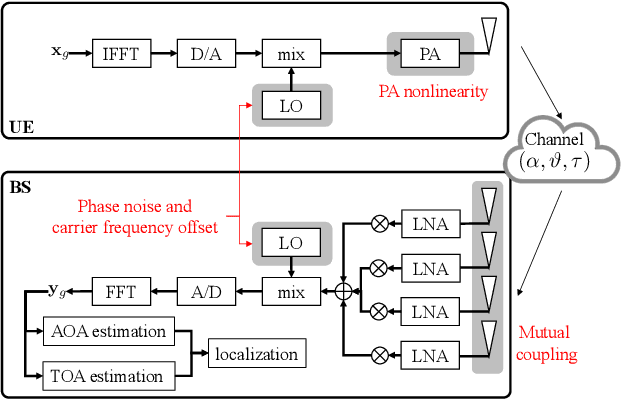
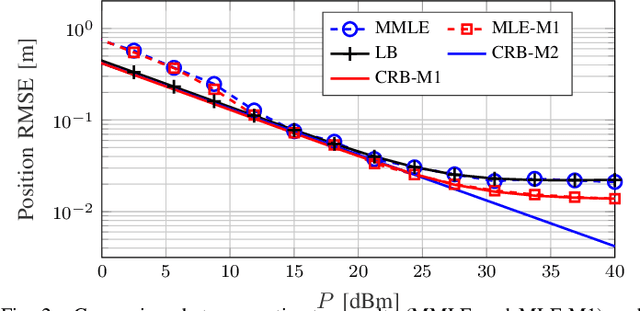
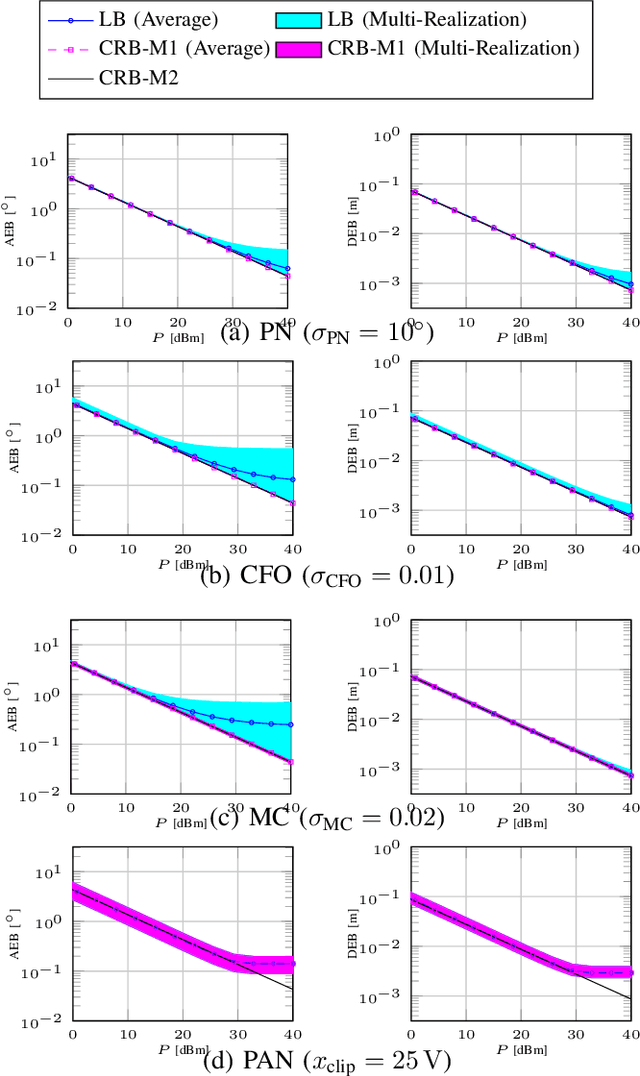
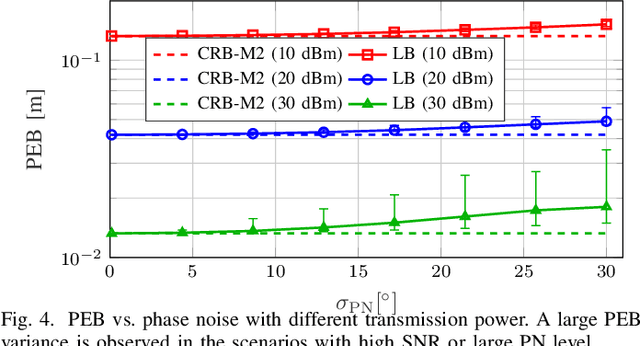
Location information is expected to be the key to meeting the needs of communication and context-aware services in 6G systems. User localization is achieved based on delay and/or angle estimation using uplink or downlink pilot signals. However, hardware impairments (HWIs) distort the signals at both the transmitter and receiver sides and thus affect the localization performance. While this impact can be ignored at lower frequencies where HWIs are less severe, modeling and analysis efforts are needed for 6G to evaluate the localization degradation due to HWIs. In this work, we model various types of impairments and conduct a misspecified Cram\'er-Rao bound analysis to evaluate the HWI-induced performance loss. Simulation results with different types of HWIs show that each HWI leads to a different level of degradation in angle and delay estimation performance.
Continual learning on 3D point clouds with random compressed rehearsal
May 20, 2022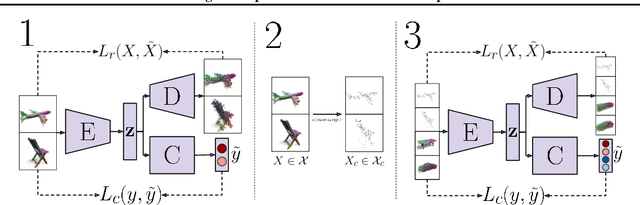

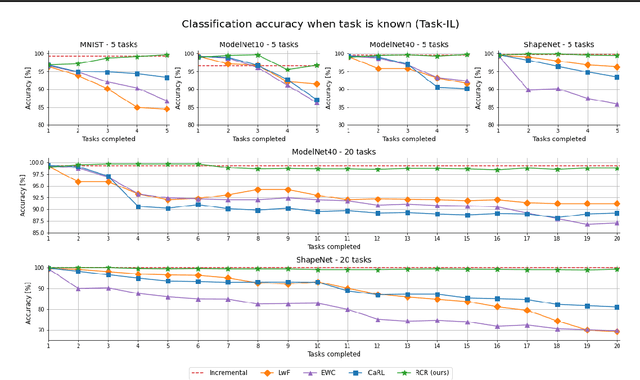
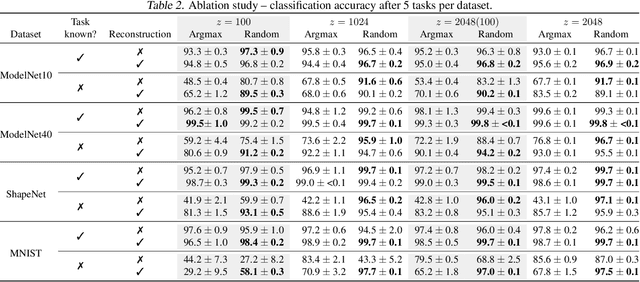
Contemporary deep neural networks offer state-of-the-art results when applied to visual reasoning, e.g., in the context of 3D point cloud data. Point clouds are important datatype for precise modeling of three-dimensional environments, but effective processing of this type of data proves to be challenging. In the world of large, heavily-parameterized network architectures and continuously-streamed data, there is an increasing need for machine learning models that can be trained on additional data. Unfortunately, currently available models cannot fully leverage training on additional data without losing their past knowledge. Combating this phenomenon, called catastrophic forgetting, is one of the main objectives of continual learning. Continual learning for deep neural networks has been an active field of research, primarily in 2D computer vision, natural language processing, reinforcement learning, and robotics. However, in 3D computer vision, there are hardly any continual learning solutions specifically designed to take advantage of point cloud structure. This work proposes a novel neural network architecture capable of continual learning on 3D point cloud data. We utilize point cloud structure properties for preserving a heavily compressed set of past data. By using rehearsal and reconstruction as regularization methods of the learning process, our approach achieves a significant decrease of catastrophic forgetting compared to the existing solutions on several most popular point cloud datasets considering two continual learning settings: when a task is known beforehand, and in the challenging scenario of when task information is unknown to the model.