 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDySurface: Consistent 4D Surface Reconstruction via Bridging Explicit Gaussians and Implicit Functions
May 11, 2026While novel view synthesis (NVS) for dynamic scenes has seen significant progress, reconstructing temporally consistent geometric surfaces remains a challenge. Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) offer powerful dynamic scene rendering capabilities; however, relying solely on photometric optimization often leads to geometric ambiguities. This results in discontinuous surfaces, severe artifacts, and broken surfaces over time. To address these limitations, we present DySurface, a novel framework that bridges the effectiveness of explicit Gaussians with the geometric fidelity of implicit Signed Distance Functions (SDFs) in dynamic scenes. Our approach tackles the structural discrepancy between the forward deformation of 3DGS ($canonical \rightarrow dynamic$) and the backward deformation required for volumetric SDF rendering ($dynamic \rightarrow canonical$). Specifically, we propose the VoxGS-DSDF branch that leverages deformed Gaussians to construct a dynamic sparse voxel grid, providing explicit geometric guidance to the implicit SDF field. This explicit anchoring effectively regularizes the volumetric rendering process, significantly improving surface reconstruction quality, with watertight boundaries and detailed representations. Quantitative and qualitative experiments demonstrate that DySurface significantly outperforms state-of-the-art baselines in geometric accuracy metrics while maintaining competitive rendering performance.
HEART-PFL: Stable Personalized Federated Learning under Heterogeneity with Hierarchical Directional Alignment and Adversarial Knowledge Transfer
Mar 25, 2026Personalized Federated Learning (PFL) aims to deliver effective client-specific models under heterogeneous distributions, yet existing methods suffer from shallow prototype alignment and brittle server-side distillation. We propose HEART-PFL, a dual-sided framework that (i) performs depth-aware Hierarchical Directional Alignment (HDA) using cosine similarity in the early stage and MSE matching in the deep stage to preserve client specificity, and (ii) stabilizes global updates through Adversarial Knowledge Transfer (AKT) with symmetric KL distillation on clean and adversarial proxy data. Using lightweight adapters with only 1.46M trainable parameters, HEART-PFL achieves state-of-the-art personalized accuracy on CIFAR-100, Flowers-102, and Caltech-101 (63.42%, 84.23%, and 95.67%, respectively) under Dirichlet non-IID partitions, and remains robust to out-of-domain proxy data. Ablation studies further confirm that HDA and AKT provide complementary gains in alignment, robustness, and optimization stability, offering insights into how the two components mutually reinforce effective personalization. Overall, these results demonstrate that HEART-PFL simultaneously enhances personalization and global stability, highlighting its potential as a strong and scalable solution for PFL(code available at https://github.com/danny0628/HEART-PFL).
Something from Nothing: Data Augmentation for Robust Severity Level Estimation of Dysarthric Speech
Mar 16, 2026Dysarthric speech quality assessment (DSQA) is critical for clinical diagnostics and inclusive speech technologies. However, subjective evaluation is costly and difficult to scale, and the scarcity of labeled data limits robust objective modeling. To address this, we propose a three-stage framework that leverages unlabeled dysarthric speech and large-scale typical speech datasets to scale training. A teacher model first generates pseudo-labels for unlabeled samples, followed by weakly supervised pretraining using a label-aware contrastive learning strategy that exposes the model to diverse speakers and acoustic conditions. The pretrained model is then fine-tuned for the downstream DSQA task. Experiments on five unseen datasets spanning multiple etiologies and languages demonstrate the robustness of our approach. Our Whisper-based baseline significantly outperforms SOTA DSQA predictors such as SpICE, and the full framework achieves an average SRCC of 0.761 across unseen test datasets.
Gencho: Room Impulse Response Generation from Reverberant Speech and Text via Diffusion Transformers
Feb 09, 2026Blind room impulse response (RIR) estimation is a core task for capturing and transferring acoustic properties; yet existing methods often suffer from limited modeling capability and degraded performance under unseen conditions. Moreover, emerging generative audio applications call for more flexible impulse response generation methods. We propose Gencho, a diffusion-transformer-based model that predicts complex spectrogram RIRs from reverberant speech. A structure-aware encoder leverages isolation between early and late reflections to encode the input audio into a robust representation for conditioning, while the diffusion decoder generates diverse and perceptually realistic impulse responses from it. Gencho integrates modularly with standard speech processing pipelines for acoustic matching. Results show richer generated RIRs than non-generative baselines while maintaining strong performance in standard RIR metrics. We further demonstrate its application to text-conditioned RIR generation, highlighting Gencho's versatility for controllable acoustic simulation and generative audio tasks.
From Hallucination to Articulation: Language Model-Driven Losses for Ultra Low-Bitrate Neural Speech Coding
Feb 05, 2026``Phoneme Hallucinations (PH)'' commonly occur in low-bitrate DNN-based codecs. It is the generative decoder's attempt to synthesize plausible outputs from excessively compressed tokens missing some semantic information. In this work, we propose language model-driven losses (LM loss) and show they may alleviate PHs better than a semantic distillation (SD) objective in very-low-bitrate settings. The proposed LM losses build upon language models pretrained to associate speech with text. When ground-truth transcripts are unavailable, we propose to modify a popular automatic speech recognition (ASR) model, Whisper, to compare the decoded utterance against the ASR-inferred transcriptions of the input speech. Else, we propose to use the timed-text regularizer (TTR) to compare WavLM representations of the decoded utterance against BERT representations of the ground-truth transcriptions. We test and compare LM losses against an SD objective, using a reference codec whose three-stage training regimen was designed after several popular codecs. Subjective and objective evaluations conclude that LM losses may provide stronger guidance to extract semantic information from self-supervised speech representations, boosting human-perceived semantic adherence while preserving overall output quality. Demo samples, code, and checkpoints are available online.
Semantics-Aware Generative Latent Data Augmentation for Learning in Low-Resource Domains
Feb 02, 2026Despite strong performance in data-rich regimes, deep learning often underperforms in the data-scarce settings common in practice. While foundation models (FMs) trained on massive datasets demonstrate strong generalization by extracting general-purpose features, they can still suffer from scarce labeled data during downstream fine-tuning. To address this, we propose GeLDA, a semantics-aware generative latent data augmentation framework that leverages conditional diffusion models to synthesize samples in an FM-induced latent space. Because this space is low-dimensional and concentrates task-relevant information compared to the input space, GeLDA enables efficient, high-quality data generation. GeLDA conditions generation on auxiliary feature vectors that capture semantic relationships among classes or subdomains, facilitating data augmentation in low-resource domains. We validate GeLDA in two large-scale recognition tasks: (a) in zero-shot language-specific speech emotion recognition, GeLDA improves the Whisper-large baseline's unweighted average recall by 6.13%; and (b) in long-tailed image classification, it achieves 74.7% tail-class accuracy on ImageNet-LT, setting a new state-of-the-art result.
PromptSep: Generative Audio Separation via Multimodal Prompting
Nov 06, 2025Recent breakthroughs in language-queried audio source separation (LASS) have shown that generative models can achieve higher separation audio quality than traditional masking-based approaches. However, two key limitations restrict their practical use: (1) users often require operations beyond separation, such as sound removal; and (2) relying solely on text prompts can be unintuitive for specifying sound sources. In this paper, we propose PromptSep to extend LASS into a broader framework for general-purpose sound separation. PromptSep leverages a conditional diffusion model enhanced with elaborated data simulation to enable both audio extraction and sound removal. To move beyond text-only queries, we incorporate vocal imitation as an additional and more intuitive conditioning modality for our model, by incorporating Sketch2Sound as a data augmentation strategy. Both objective and subjective evaluations on multiple benchmarks demonstrate that PromptSep achieves state-of-the-art performance in sound removal and vocal-imitation-guided source separation, while maintaining competitive results on language-queried source separation.
User-guided Generative Source Separation
Jul 02, 2025



Music source separation (MSS) aims to extract individual instrument sources from their mixture. While most existing methods focus on the widely adopted four-stem separation setup (vocals, bass, drums, and other instruments), this approach lacks the flexibility needed for real-world applications. To address this, we propose GuideSep, a diffusion-based MSS model capable of instrument-agnostic separation beyond the four-stem setup. GuideSep is conditioned on multiple inputs: a waveform mimicry condition, which can be easily provided by humming or playing the target melody, and mel-spectrogram domain masks, which offer additional guidance for separation. Unlike prior approaches that relied on fixed class labels or sound queries, our conditioning scheme, coupled with the generative approach, provides greater flexibility and applicability. Additionally, we design a mask-prediction baseline using the same model architecture to systematically compare predictive and generative approaches. Our objective and subjective evaluations demonstrate that GuideSep achieves high-quality separation while enabling more versatile instrument extraction, highlighting the potential of user participation in the diffusion-based generative process for MSS. Our code and demo page are available at https://yutongwen.github.io/GuideSep/
Discrete Audio Tokens: More Than a Survey!
Jun 12, 2025Discrete audio tokens are compact representations that aim to preserve perceptual quality, phonetic content, and speaker characteristics while enabling efficient storage and inference, as well as competitive performance across diverse downstream tasks.They provide a practical alternative to continuous features, enabling the integration of speech and audio into modern large language models (LLMs). As interest in token-based audio processing grows, various tokenization methods have emerged, and several surveys have reviewed the latest progress in the field. However, existing studies often focus on specific domains or tasks and lack a unified comparison across various benchmarks. This paper presents a systematic review and benchmark of discrete audio tokenizers, covering three domains: speech, music, and general audio. We propose a taxonomy of tokenization approaches based on encoder-decoder, quantization techniques, training paradigm, streamability, and application domains. We evaluate tokenizers on multiple benchmarks for reconstruction, downstream performance, and acoustic language modeling, and analyze trade-offs through controlled ablation studies. Our findings highlight key limitations, practical considerations, and open challenges, providing insight and guidance for future research in this rapidly evolving area. For more information, including our main results and tokenizer database, please refer to our website: https://poonehmousavi.github.io/dates-website/.
Perceptual Audio Coding: A 40-Year Historical Perspective
Apr 22, 2025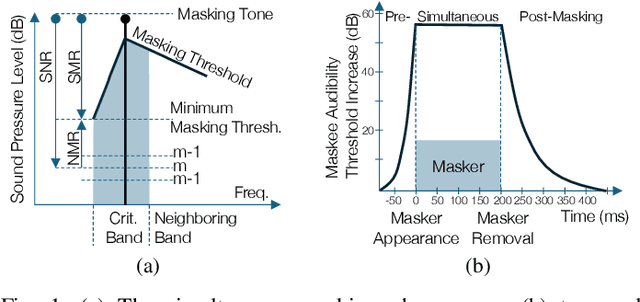
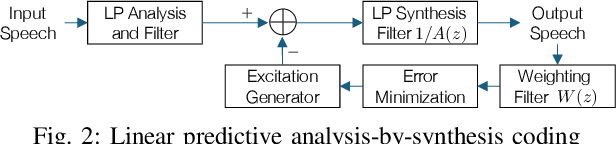
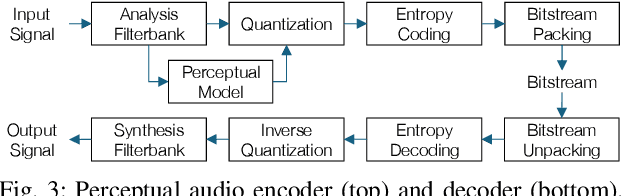
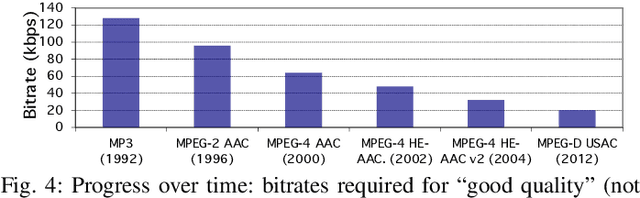
In the history of audio and acoustic signal processing, perceptual audio coding has certainly excelled as a bright success story by its ubiquitous deployment in virtually all digital media devices, such as computers, tablets, mobile phones, set-top-boxes, and digital radios. From a technology perspective, perceptual audio coding has undergone tremendous development from the first very basic perceptually driven coders (including the popular mp3 format) to today's full-blown integrated coding/rendering systems. This paper provides a historical overview of this research journey by pinpointing the pivotal development steps in the evolution of perceptual audio coding. Finally, it provides thoughts about future directions in this area.