 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Information-Theoretic Segmentation by Inpainting Error Maximization
Dec 14, 2020

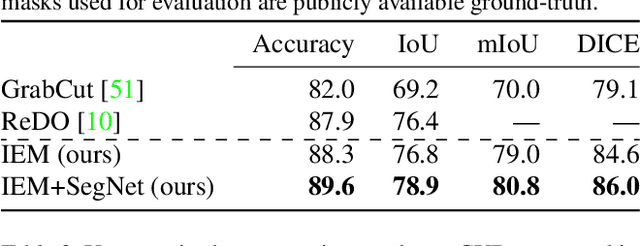
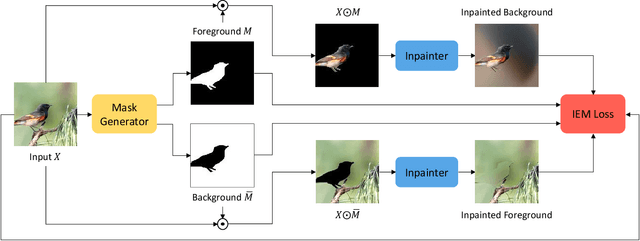
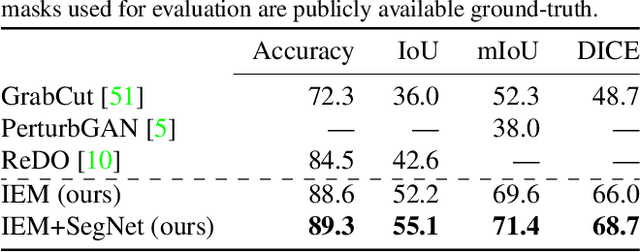
We study image segmentation from an information-theoretic perspective, proposing a novel adversarial method that performs unsupervised segmentation by partitioning images into maximally independent sets. More specifically, we group image pixels into foreground and background, with the goal of minimizing predictability of one set from the other. An easily computed loss drives a greedy search process to maximize inpainting error over these partitions. Our method does not involve training deep networks, is computationally cheap, class-agnostic, and even applicable in isolation to a single unlabeled image. Experiments demonstrate that it achieves a new state-of-the-art in unsupervised segmentation quality, while being substantially faster and more general than competing approaches.
Graph Pre-training for AMR Parsing and Generation
Mar 31, 2022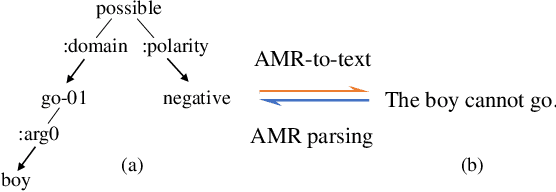

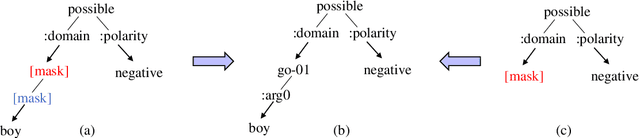

Abstract meaning representation (AMR) highlights the core semantic information of text in a graph structure. Recently, pre-trained language models (PLMs) have advanced tasks of AMR parsing and AMR-to-text generation, respectively. However, PLMs are typically pre-trained on textual data, thus are sub-optimal for modeling structural knowledge. To this end, we investigate graph self-supervised training to improve the structure awareness of PLMs over AMR graphs. In particular, we introduce two graph auto-encoding strategies for graph-to-graph pre-training and four tasks to integrate text and graph information during pre-training. We further design a unified framework to bridge the gap between pre-training and fine-tuning tasks. Experiments on both AMR parsing and AMR-to-text generation show the superiority of our model. To our knowledge, we are the first to consider pre-training on semantic graphs.
CompleteDT: Point Cloud Completion with Dense Augment Inference Transformers
May 30, 2022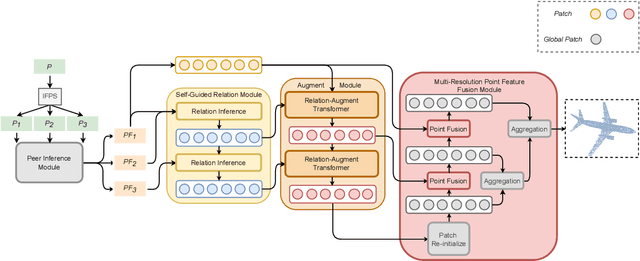

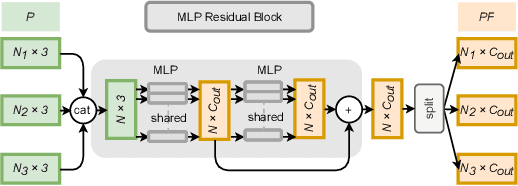

Point cloud completion task aims to predict the missing part of incomplete point clouds and generate complete point clouds with details. In this paper, we propose a novel point cloud completion network, CompleteDT, which is based on the transformer. CompleteDT can learn features within neighborhoods and explore the relationship among these neighborhoods. By sampling the incomplete point cloud to obtain point clouds with different resolutions, we extract features from these point clouds in a self-guided manner, while converting these features into a series of $patches$ based on the geometrical structure. To facilitate transformers to leverage sufficient information about point clouds, we provide a plug-and-play module named Relation-Augment Attention Module (RAA), consisting of Point Cross-Attention Module (PCA) and Point Dense Multi-Scale Attention Module (PDMA). These two modules can enhance the ability to learn features within Patches and consider the correlation among these Patches. Thus, RAA enables to learn structures of incomplete point clouds and contribute to infer the local details of complete point clouds generated. In addition, we predict the complete shape from $patches$ with an efficient generation module, namely, Multi-resolution Point Fusion Module (MPF). MPF gradually generates complete point clouds from $patches$, and updates $patches$ based on these generated point clouds. Experimental results show that our method largely outperforms the state-of-the-art methods.
Active Learning Through a Covering Lens
May 23, 2022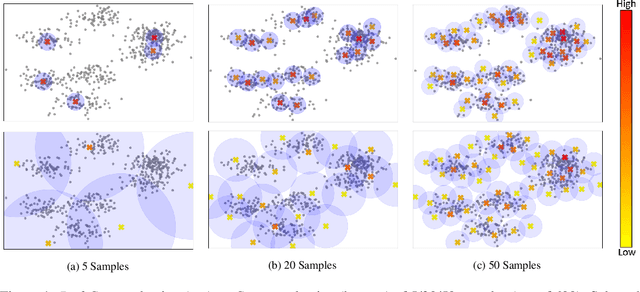
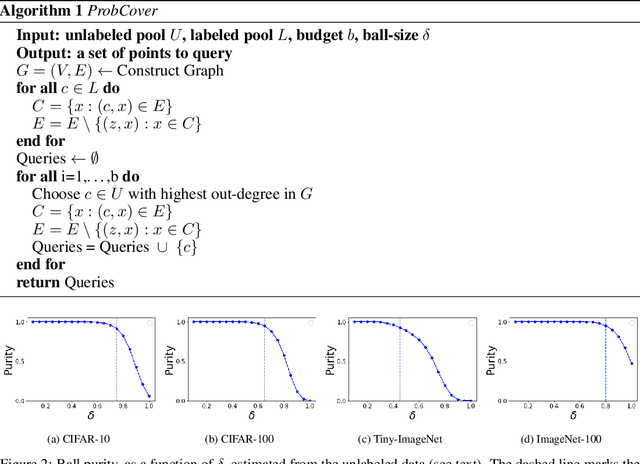
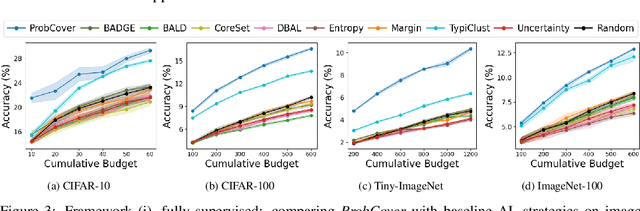
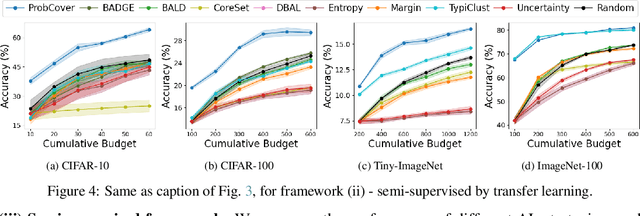
Deep active learning aims to reduce the annotation cost for deep neural networks, which are notoriously data-hungry. Until recently, deep active learning methods struggled in the low-budget regime, where only a small amount of samples are annotated. The situation has been alleviated by recent advances in self-supervised representation learning methods, which impart the geometry of the data representation with rich information about the points. Taking advantage of this progress, we study the problem of subset selection for annotation through a "covering" lens, proposing ProbCover -- a new active learning algorithm for the low budget regime, which seeks to maximize Probability Coverage. We describe a dual way to view our formulation, from which one can derive strategies suitable for the high budget regime of active learning, related to existing methods like Coreset. We conclude with extensive experiments, evaluating ProbCover in the low budget regime. We show that our principled active learning strategy improves the state-of-the-art in the low-budget regime in several image recognition benchmarks. This method is especially beneficial in semi-supervised settings, allowing state-of-the-art semi-supervised methods to achieve high accuracy with only a few labels.
PLAID: An Efficient Engine for Late Interaction Retrieval
May 19, 2022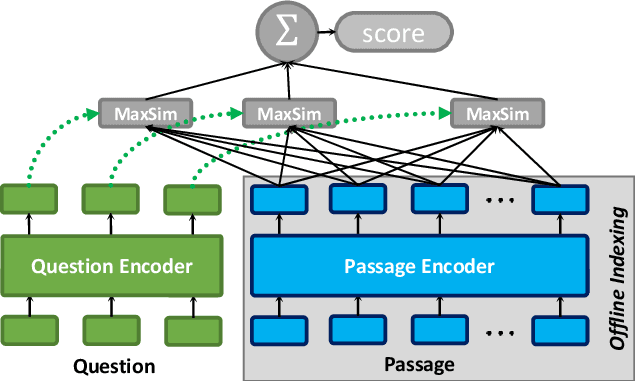
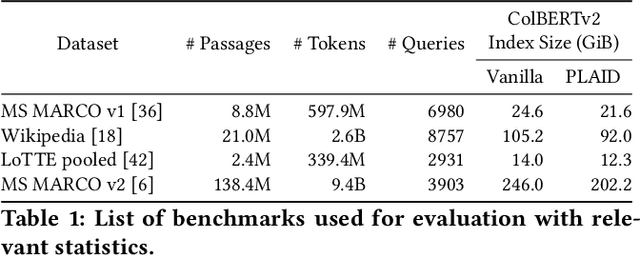
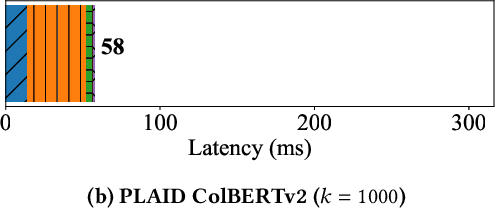

Pre-trained language models are increasingly important components across multiple information retrieval (IR) paradigms. Late interaction, introduced with the ColBERT model and recently refined in ColBERTv2, is a popular paradigm that holds state-of-the-art status across many benchmarks. To dramatically speed up the search latency of late interaction, we introduce the Performance-optimized Late Interaction Driver (PLAID). Without impacting quality, PLAID swiftly eliminates low-scoring passages using a novel centroid interaction mechanism that treats every passage as a lightweight bag of centroids. PLAID uses centroid interaction as well as centroid pruning, a mechanism for sparsifying the bag of centroids, within a highly-optimized engine to reduce late interaction search latency by up to 7$\times$ on a GPU and 45$\times$ on a CPU against vanilla ColBERTv2, while continuing to deliver state-of-the-art retrieval quality. This allows the PLAID engine with ColBERTv2 to achieve latency of tens of milliseconds on a GPU and tens or just few hundreds of milliseconds on a CPU at large scale, even at the largest scales we evaluate with 140M passages.
3-D generalized analytic signal associated with linear canonical transform in Clifford biquaternion domain
Apr 27, 2022

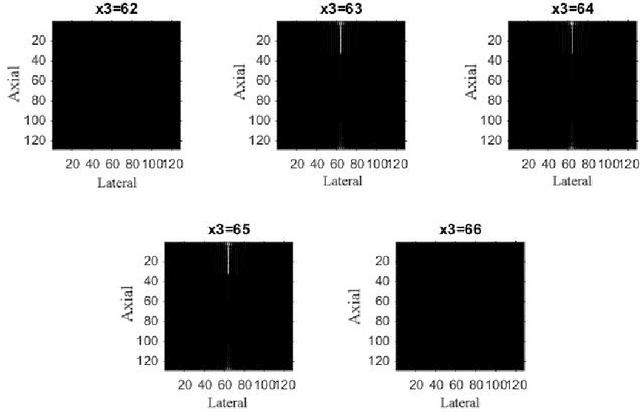
The analytic signal is a useful mathematical tool. It separates qualitative and quantitative information of a signal in form of the local phase and local amplitude. The Clifford Fourier transform (CFT) plays a vital role in the representation of multidimensional signals. By generalizing the CFT to the Clifford linear canonical transform (CLCT), we present a new type of Clifford biquaternionic analytic signal. Due to the advantages of more freedom, the envelop detection problems of 3D images, with the help of this new analytic signal, can get a better visual appearance. Synthesis examples are presented to demonstrate these advantages.
Confederated Learning: Federated Learning with Decentralized Edge Servers
May 30, 2022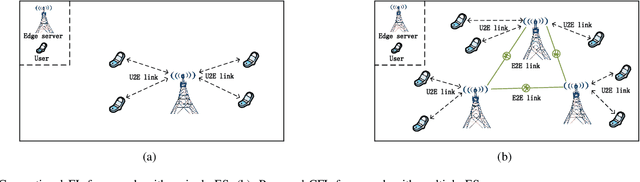
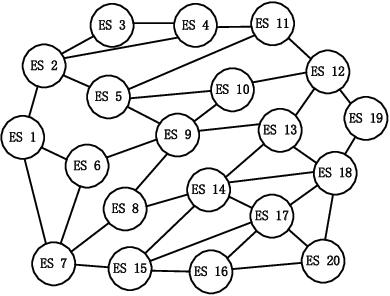
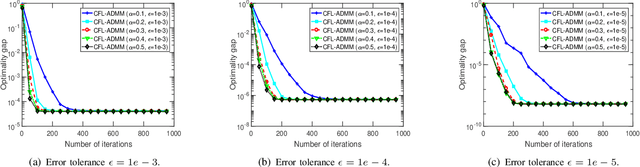
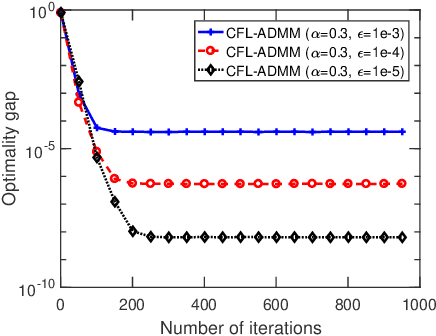
Federated learning (FL) is an emerging machine learning paradigm that allows to accomplish model training without aggregating data at a central server. Most studies on FL consider a centralized framework, in which a single server is endowed with a central authority to coordinate a number of devices to perform model training in an iterative manner. Due to stringent communication and bandwidth constraints, such a centralized framework has limited scalability as the number of devices grows. To address this issue, in this paper, we propose a ConFederated Learning (CFL) framework. The proposed CFL consists of multiple servers, in which each server is connected with an individual set of devices as in the conventional FL framework, and decentralized collaboration is leveraged among servers to make full use of the data dispersed throughout the network. We develop an alternating direction method of multipliers (ADMM) algorithm for CFL. The proposed algorithm employs a random scheduling policy which randomly selects a subset of devices to access their respective servers at each iteration, thus alleviating the need of uploading a huge amount of information from devices to servers. Theoretical analysis is presented to justify the proposed method. Numerical results show that the proposed method can converge to a decent solution significantly faster than gradient-based FL algorithms, thus boasting a substantial advantage in terms of communication efficiency.
A Survey of Deep Learning Models for Structural Code Understanding
May 03, 2022
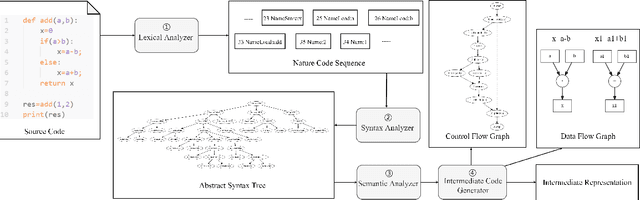
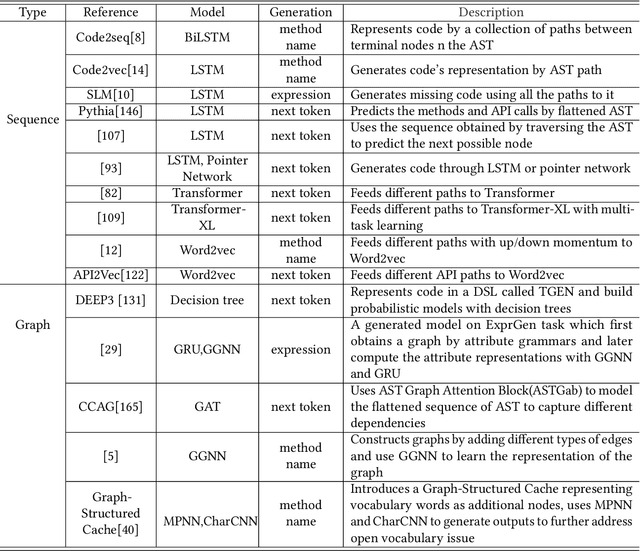
In recent years, the rise of deep learning and automation requirements in the software industry has elevated Intelligent Software Engineering to new heights. The number of approaches and applications in code understanding is growing, with deep learning techniques being used in many of them to better capture the information in code data. In this survey, we present a comprehensive overview of the structures formed from code data. We categorize the models for understanding code in recent years into two groups: sequence-based and graph-based models, further make a summary and comparison of them. We also introduce metrics, datasets and the downstream tasks. Finally, we make some suggestions for future research in structural code understanding field.
Contextual Attention Network: Transformer Meets U-Net
Mar 31, 2022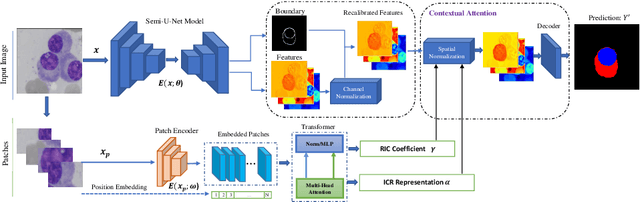
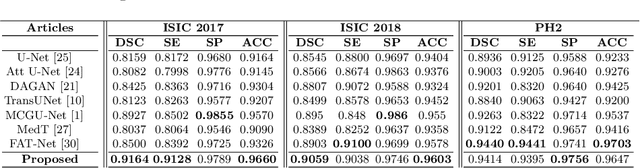


Currently, convolutional neural networks (CNN) (e.g., U-Net) have become the de facto standard and attained immense success in medical image segmentation. However, as a downside, CNN based methods are a double-edged sword as they fail to build long-range dependencies and global context connections due to the limited receptive field that stems from the intrinsic characteristics of the convolution operation. Hence, recent articles have exploited Transformer variants for medical image segmentation tasks which open up great opportunities due to their innate capability of capturing long-range correlations through the attention mechanism. Although being feasibly designed, most of the cohort studies incur prohibitive performance in capturing local information, thereby resulting in less lucidness of boundary areas. In this paper, we propose a contextual attention network to tackle the aforementioned limitations. The proposed method uses the strength of the Transformer module to model the long-range contextual dependency. Simultaneously, it utilizes the CNN encoder to capture local semantic information. In addition, an object-level representation is included to model the regional interaction map. The extracted hierarchical features are then fed to the contextual attention module to adaptively recalibrate the representation space using the local information. Then, they emphasize the informative regions while taking into account the long-range contextual dependency derived by the Transformer module. We validate our method on several large-scale public medical image segmentation datasets and achieve state-of-the-art performance. We have provided the implementation code in https://github.com/rezazad68/TMUnet.
Online greedy identification of linear dynamical systems
Apr 13, 2022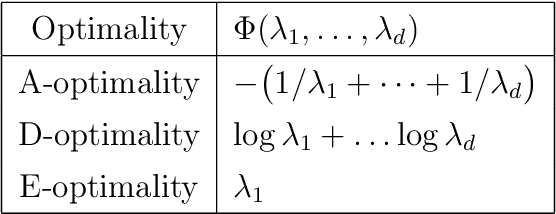
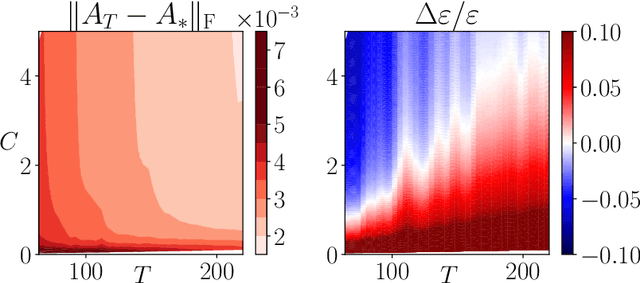
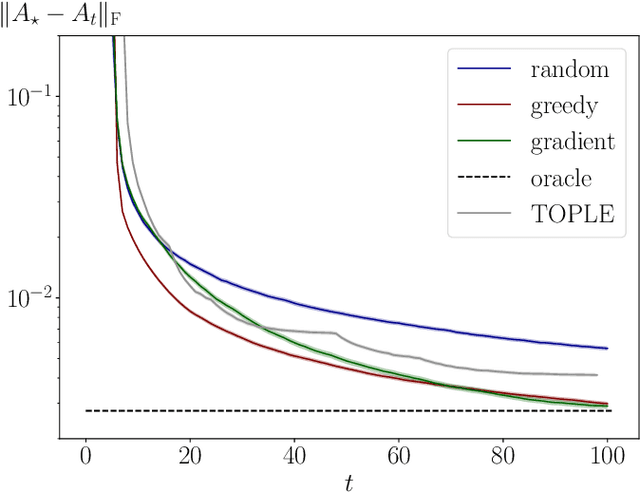
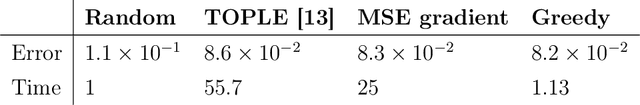
This work addresses the problem of exploration in an unknown environment. For linear dynamical systems, we use an experimental design framework and introduce an online greedy policy where the control maximizes the information of the next step. In a setting with a limited number of experimental trials, our algorithm has low complexity and shows experimentally competitive performances compared to more elaborate gradient-based methods.