 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Many-Class Text Classification with Matching
May 23, 2022
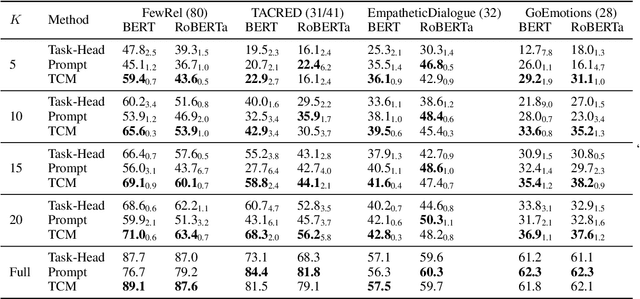
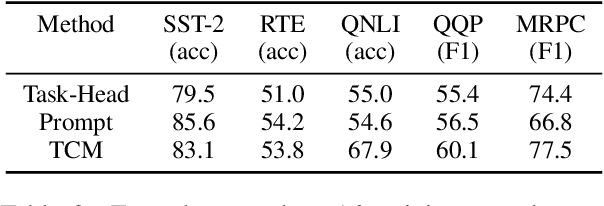
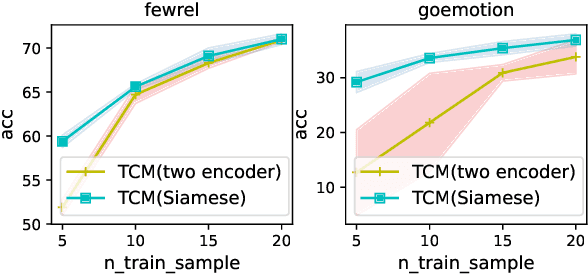
In this work, we formulate \textbf{T}ext \textbf{C}lassification as a \textbf{M}atching problem between the text and the labels, and propose a simple yet effective framework named TCM. Compared with previous text classification approaches, TCM takes advantage of the fine-grained semantic information of the classification labels, which helps distinguish each class better when the class number is large, especially in low-resource scenarios. TCM is also easy to implement and is compatible with various large pretrained language models. We evaluate TCM on 4 text classification datasets (each with 20+ labels) in both few-shot and full-data settings, and this model demonstrates significant improvements over other text classification paradigms. We also conduct extensive experiments with different variants of TCM and discuss the underlying factors of its success. Our method and analyses offer a new perspective on text classification.
Fault-Aware Neural Code Rankers
Jun 04, 2022

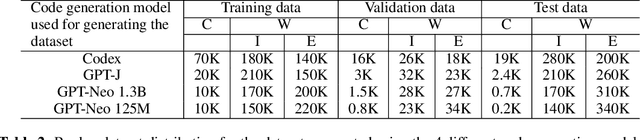

Large language models (LLMs) have demonstrated an impressive ability to generate code for various programming tasks. In many instances, LLMs can generate a correct program for a task when given numerous trials. Consequently, a recent trend is to do large scale sampling of programs using a model and then filtering/ranking the programs based on the program execution on a small number of known unit tests to select one candidate solution. However, these approaches assume that the unit tests are given and assume the ability to safely execute the generated programs (which can do arbitrary dangerous operations such as file manipulations). Both of the above assumptions are impractical in real-world software development. In this paper, we propose fault-aware neural code rankers that can predict the correctness of a sampled program without executing it. The fault-aware rankers are trained to predict different kinds of execution information such as predicting the exact compile/runtime error type (e.g., an IndexError or a TypeError). We show that our fault-aware rankers can significantly increase the pass@1 accuracy of various code generation models (including Codex, GPT-Neo, GPT-J) on APPS, HumanEval and MBPP datasets.
Multi-Temporal Spatial-Spectral Comparison Network for Hyperspectral Anomalous Change Detection
May 23, 2022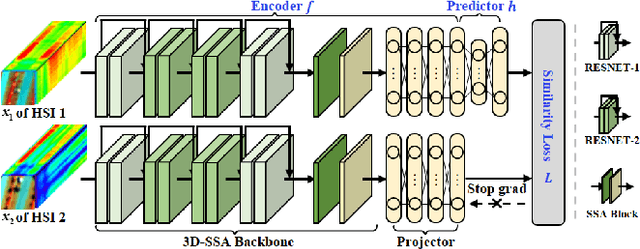
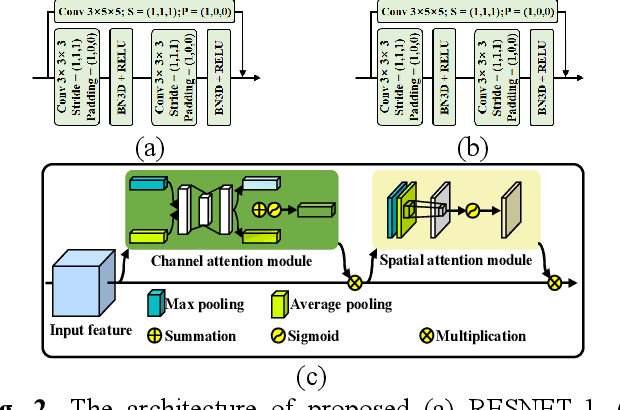


Hyperspectral anomalous change detection has been a challenging task for its emphasis on the dynamics of small and rare objects against the prevalent changes. In this paper, we have proposed a Multi-Temporal spatial-spectral Comparison Network for hyperspectral anomalous change detection (MTC-NET). The whole model is a deep siamese network, aiming at learning the prevalent spectral difference resulting from the complex imaging conditions from the hyperspectral images by contrastive learning. A three-dimensional spatial spectral attention module is designed to effectively extract the spatial semantic information and the key spectral differences. Then the gaps between the multi-temporal features are minimized, boosting the alignment of the semantic and spectral features and the suppression of the multi-temporal background spectral difference. The experiments on the "Viareggio 2013" datasets demonstrate the effectiveness of proposed MTC-NET.
User Clustering for Rate Splitting using Machine Learning
May 23, 2022
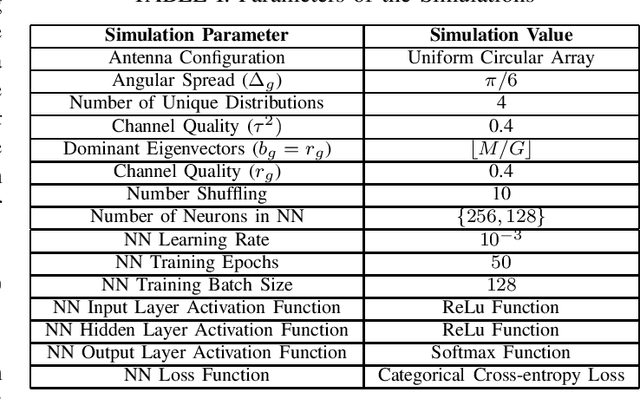
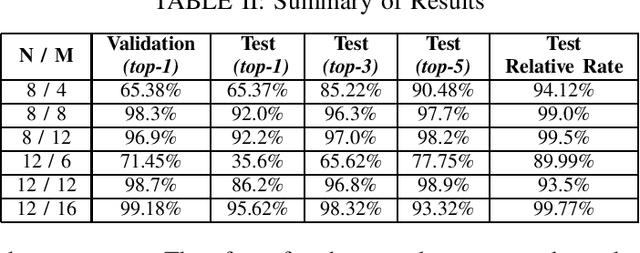
Hierarchical Rate Splitting (HRS) schemes proposed in recent years have shown to provide significant improvements in exploiting spatial diversity in wireless networks and provide high throughput for all users while minimising interference among them. Hence, one of the major challenges for such HRS schemes is the necessity to know the optimal clustering of these users based only on their Channel State Information (CSI). This clustering problem is known to be NP hard and, to deal with the unmanageable complexity of finding an optimal solution, in this work a scalable and much lighter clustering mechanism based on Neural Network (NN) is proposed. The accuracy and performance metrics show that the NN is able to learn and cluster the users based on the noisy channel response and is able to achieve a rate comparable to other more complex clustering schemes from the literature.
LILE: Look In-Depth before Looking Elsewhere -- A Dual Attention Network using Transformers for Cross-Modal Information Retrieval in Histopathology Archives
Mar 04, 2022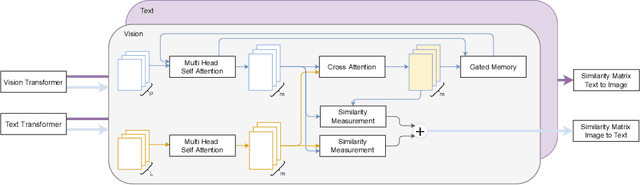
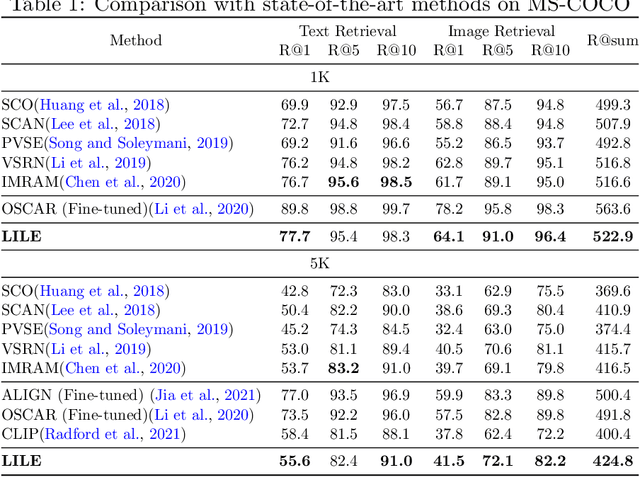
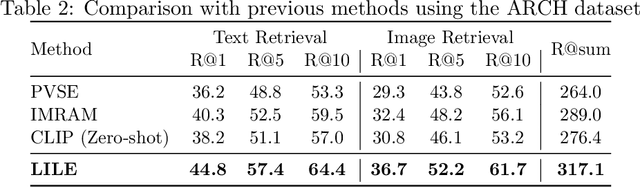
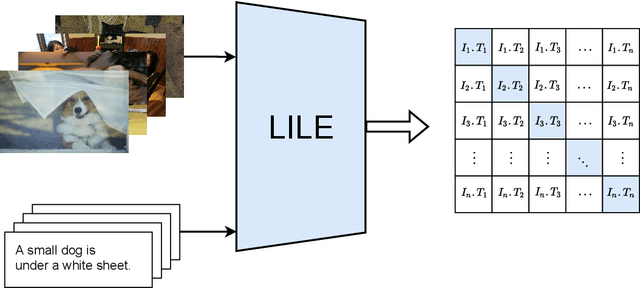
The volume of available data has grown dramatically in recent years in many applications. Furthermore, the age of networks that used multiple modalities separately has practically ended. Therefore, enabling bidirectional cross-modality data retrieval capable of processing has become a requirement for many domains and disciplines of research. This is especially true in the medical field, as data comes in a multitude of types, including various types of images and reports as well as molecular data. Most contemporary works apply cross attention to highlight the essential elements of an image or text in relation to the other modalities and try to match them together. However, regardless of their importance in their own modality, these approaches usually consider features of each modality equally. In this study, self-attention as an additional loss term will be proposed to enrich the internal representation provided into the cross attention module. This work suggests a novel architecture with a new loss term to help represent images and texts in the joint latent space. Experiment results on two benchmark datasets, i.e. MS-COCO and ARCH, show the effectiveness of the proposed method.
Towards Unification of Discourse Annotation Frameworks
Apr 16, 2022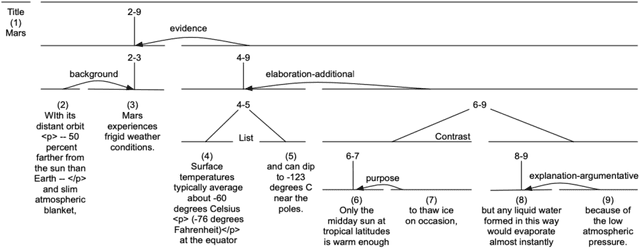
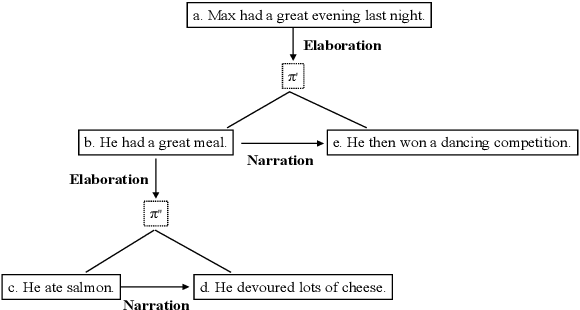
Discourse information is difficult to represent and annotate. Among the major frameworks for annotating discourse information, RST, PDTB and SDRT are widely discussed and used, each having its own theoretical foundation and focus. Corpora annotated under different frameworks vary considerably. To make better use of the existing discourse corpora and achieve the possible synergy of different frameworks, it is worthwhile to investigate the systematic relations between different frameworks and devise methods of unifying the frameworks. Although the issue of framework unification has been a topic of discussion for a long time, there is currently no comprehensive approach which considers unifying both discourse structure and discourse relations and evaluates the unified framework intrinsically and extrinsically. We plan to use automatic means for the unification task and evaluate the result with structural complexity and downstream tasks. We will also explore the application of the unified framework in multi-task learning and graphical models.
Investigating End-user Acceptance of Last-mile Delivery by Autonomous Vehicles in the United States
May 28, 2022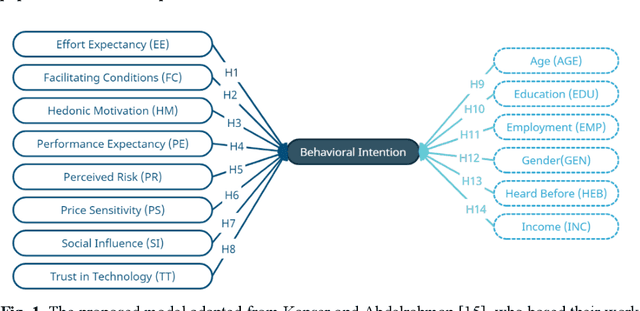
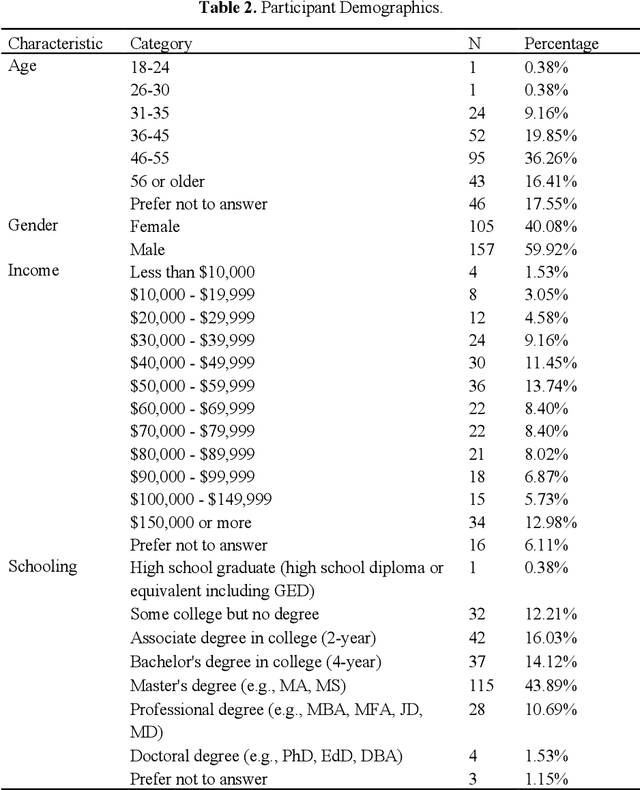
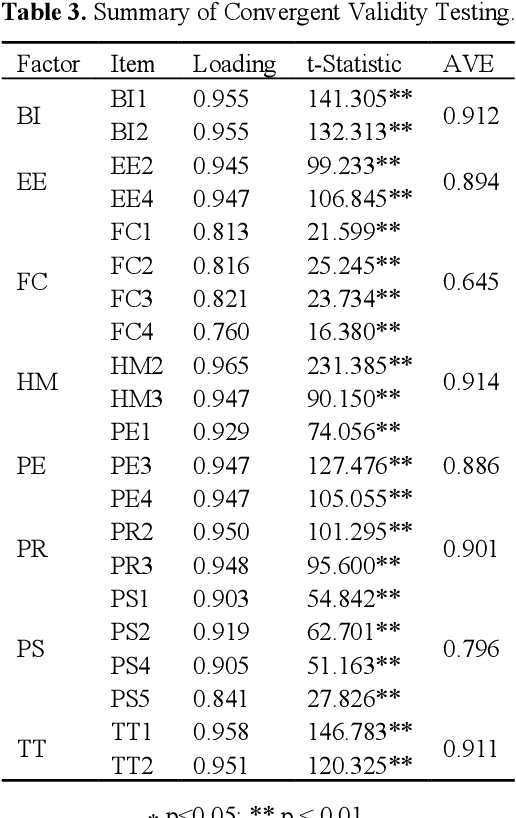
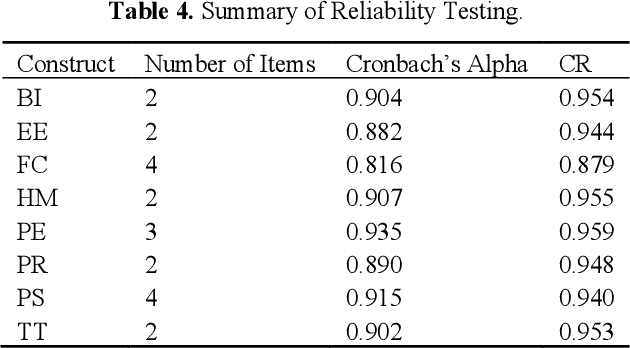
This paper investigates the end-user acceptance of last-mile delivery carried out by autonomous vehicles within the United States. A total of 296 participants were presented with information on this technology and then asked to complete a questionnaire on their perceptions to gauge their behavioral intention concerning acceptance. Structural equation modeling of the partial least squares flavor (PLS-SEM) was employed to analyze the collected data. The results indicated that the perceived usefulness of the technology played the greatest role in end-user acceptance decisions, followed by the influence of others, and then the enjoyment received by interacting with the technology. Furthermore, the perception of risk associated with using autonomous delivery vehicles for last-mile delivery led to a decrease in acceptance. However, most participants did not perceive the use of this technology to be risky. The paper concludes by summarizing the implications our findings have on the respective stakeholders and proposing the next steps in this area of research.
Differentiable Invariant Causal Discovery
Jun 01, 2022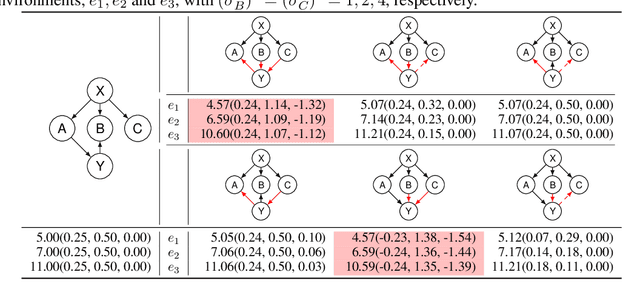
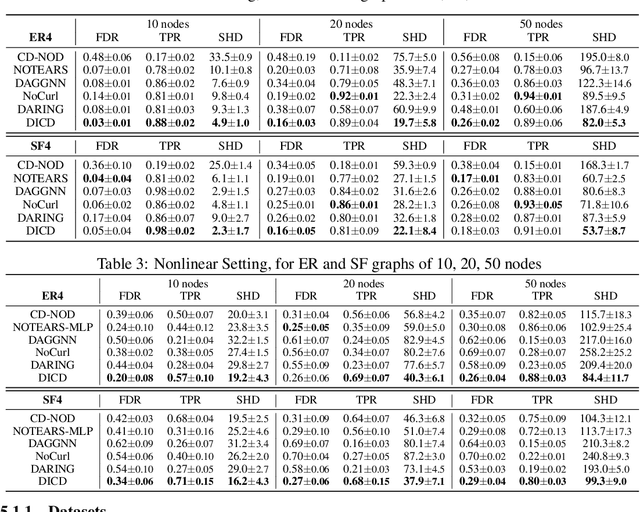
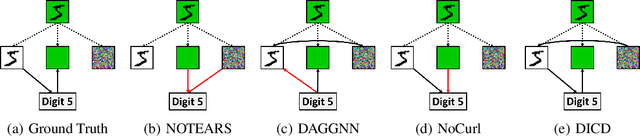

Learning causal structure from observational data is a fundamental challenge in machine learning. The majority of commonly used differentiable causal discovery methods are non-identifiable, turning this problem into a continuous optimization task prone to data biases. In many real-life situations, data is collected from different environments, in which the functional relations remain consistent across environments, while the distribution of additive noises may vary. This paper proposes Differentiable Invariant Causal Discovery (DICD), utilizing the multi-environment information based on a differentiable framework to avoid learning spurious edges and wrong causal directions. Specifically, DICD aims to discover the environment-invariant causation while removing the environment-dependent correlation. We further formulate the constraint that enforces the target structure equation model to maintain optimal across the environments. Theoretical guarantees for the identifiability of proposed DICD are provided under mild conditions with enough environments. Extensive experiments on synthetic and real-world datasets verify that DICD outperforms state-of-the-art causal discovery methods up to 36% in SHD. Our code will be open-sourced upon acceptance.
Neuromorphic Artificial Intelligence Systems
May 25, 2022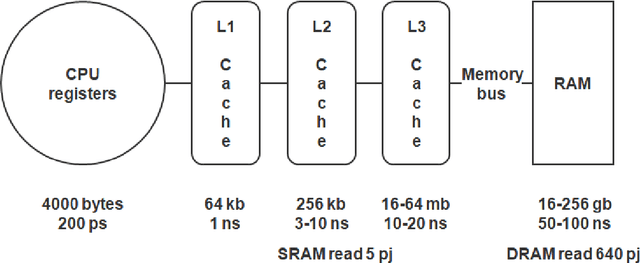
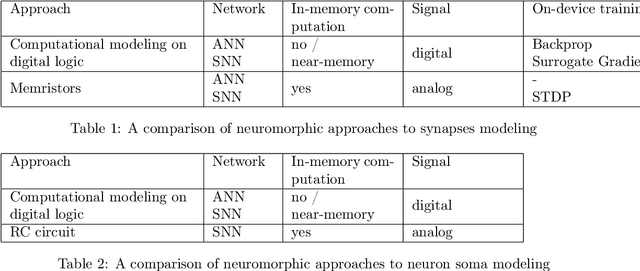
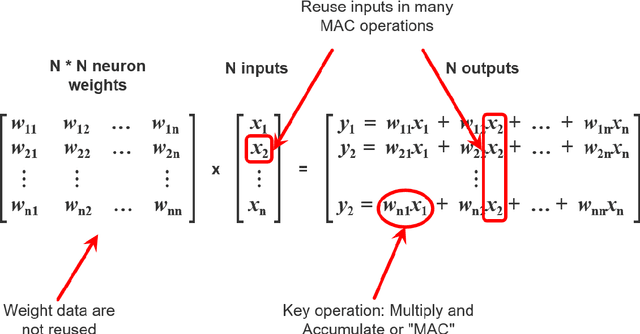
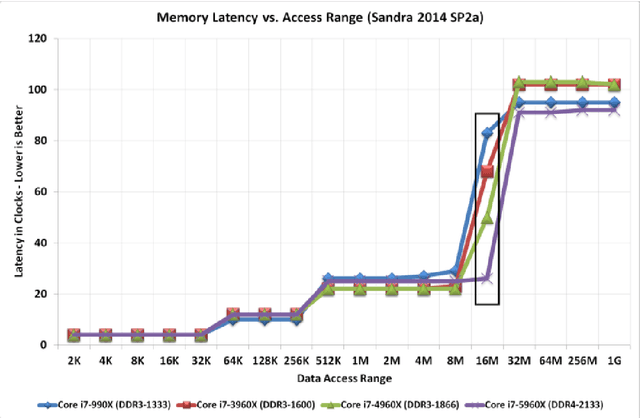
Modern AI systems, based on von Neumann architecture and classical neural networks, have a number of fundamental limitations in comparison with the brain. This article discusses such limitations and the ways they can be mitigated. Next, it presents an overview of currently available neuromorphic AI projects in which these limitations are overcame by bringing some brain features into the functioning and organization of computing systems (TrueNorth, Loihi, Tianjic, SpiNNaker, BrainScaleS, NeuronFlow, DYNAP, Akida). Also, the article presents the principle of classifying neuromorphic AI systems by the brain features they use (neural networks, parallelism and asynchrony, impulse nature of information transfer, local learning, sparsity, analog and in-memory computing). In addition to new architectural approaches used in neuromorphic devices based on existing silicon microelectronics technologies, the article also discusses the prospects of using new memristor element base. Examples of recent advances in the use of memristors in euromorphic applications are also given.
BSRT: Improving Burst Super-Resolution with Swin Transformer and Flow-Guided Deformable Alignment
Apr 18, 2022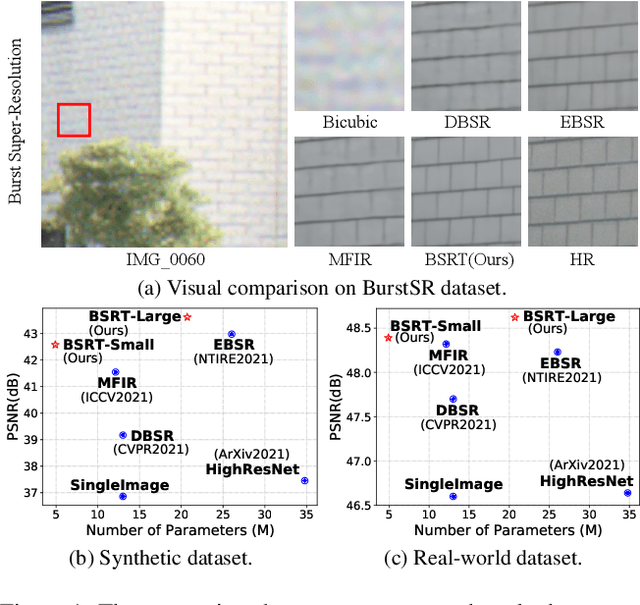
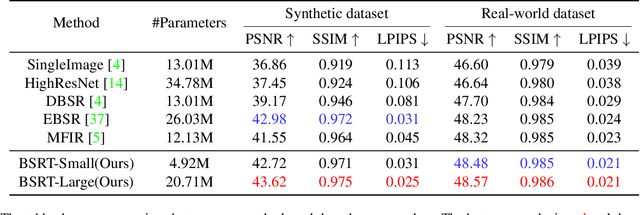
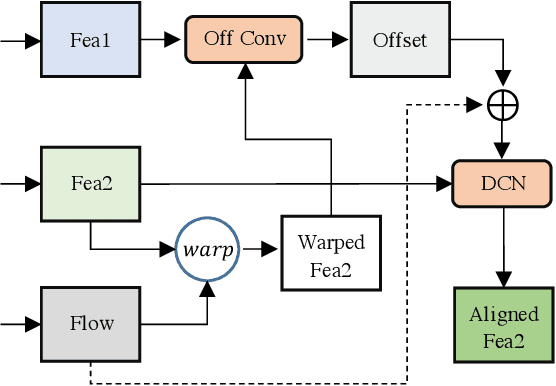
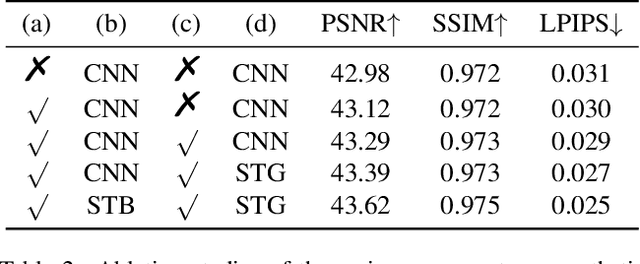
This work addresses the Burst Super-Resolution (BurstSR) task using a new architecture, which requires restoring a high-quality image from a sequence of noisy, misaligned, and low-resolution RAW bursts. To overcome the challenges in BurstSR, we propose a Burst Super-Resolution Transformer (BSRT), which can significantly improve the capability of extracting inter-frame information and reconstruction. To achieve this goal, we propose a Pyramid Flow-Guided Deformable Convolution Network (Pyramid FG-DCN) and incorporate Swin Transformer Blocks and Groups as our main backbone. More specifically, we combine optical flows and deformable convolutions, hence our BSRT can handle misalignment and aggregate the potential texture information in multi-frames more efficiently. In addition, our Transformer-based structure can capture long-range dependency to further improve the performance. The evaluation on both synthetic and real-world tracks demonstrates that our approach achieves a new state-of-the-art in BurstSR task. Further, our BSRT wins the championship in the NTIRE2022 Burst Super-Resolution Challenge.