 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
LFPS-Net: a lightweight fast pulse simulation network for BVP estimation
Jun 25, 2022
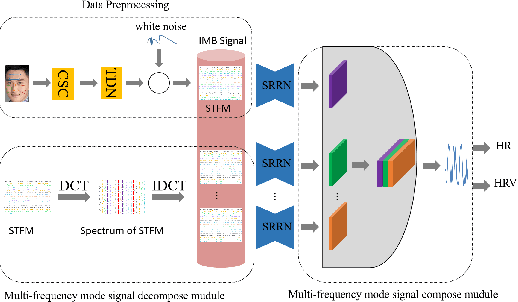
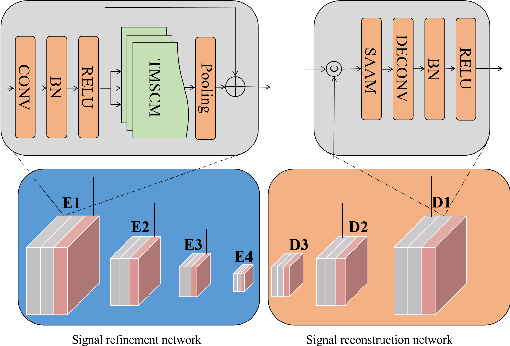

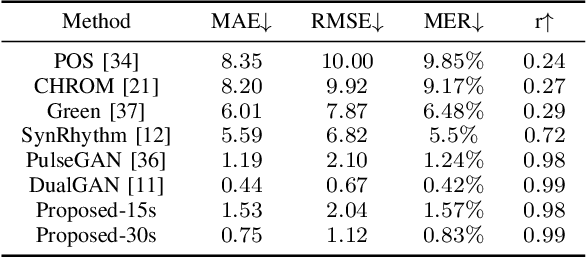
Heart rate estimation based on remote photoplethysmography plays an important role in several specific scenarios, such as health monitoring and fatigue detection. Existing well-established methods are committed to taking the average of the predicted HRs of multiple overlapping video clips as the final results for the 30-second facial video. Although these methods with hundreds of layers and thousands of channels are highly accurate and robust, they require enormous computational budget and a 30-second wait time, which greatly limits the application of the algorithms to scale. Under these cicumstacnces, We propose a lightweight fast pulse simulation network (LFPS-Net), pursuing the best accuracy within a very limited computational and time budget, focusing on common mobile platforms, such as smart phones. In order to suppress the noise component and get stable pulse in a short time, we design a multi-frequency modal signal fusion mechanism, which exploits the theory of time-frequency domain analysis to separate multi-modal information from complex signals. It helps proceeding network learn the effective fetures more easily without adding any parameter. In addition, we design a oversampling training strategy to solve the problem caused by the unbalanced distribution of dataset. For the 30-second facial videos, our proposed method achieves the best results on most of the evaluation metrics for estimating heart rate or heart rate variability compared to the best available papers. The proposed method can still obtain very competitive results by using a short-time (~15-second) facail video.
Multi-LexSum: Real-World Summaries of Civil Rights Lawsuits at Multiple Granularities
Jun 22, 2022
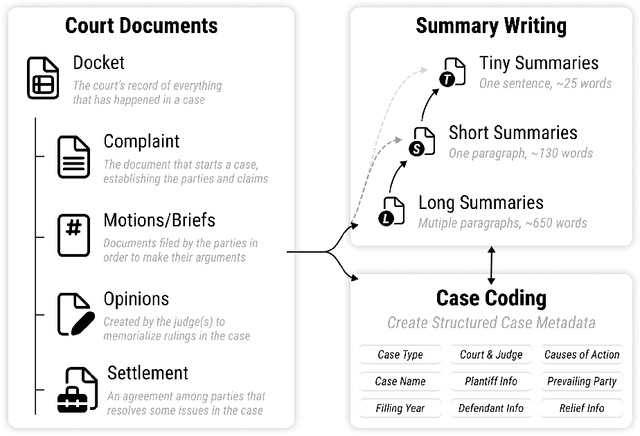


With the advent of large language models, methods for abstractive summarization have made great strides, creating potential for use in applications to aid knowledge workers processing unwieldy document collections. One such setting is the Civil Rights Litigation Clearinghouse (CRLC) (https://clearinghouse.net),which posts information about large-scale civil rights lawsuits, serving lawyers, scholars, and the general public. Today, summarization in the CRLC requires extensive training of lawyers and law students who spend hours per case understanding multiple relevant documents in order to produce high-quality summaries of key events and outcomes. Motivated by this ongoing real-world summarization effort, we introduce Multi-LexSum, a collection of 9,280 expert-authored summaries drawn from ongoing CRLC writing. Multi-LexSum presents a challenging multi-document summarization task given the length of the source documents, often exceeding two hundred pages per case. Furthermore, Multi-LexSum is distinct from other datasets in its multiple target summaries, each at a different granularity (ranging from one-sentence "extreme" summaries to multi-paragraph narrations of over five hundred words). We present extensive analysis demonstrating that despite the high-quality summaries in the training data (adhering to strict content and style guidelines), state-of-the-art summarization models perform poorly on this task. We release Multi-LexSum for further research in summarization methods as well as to facilitate development of applications to assist in the CRLC's mission at https://multilexsum.github.io.
Word Order Does Matter (And Shuffled Language Models Know It)
Mar 21, 2022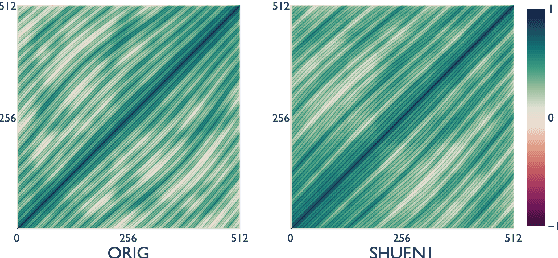
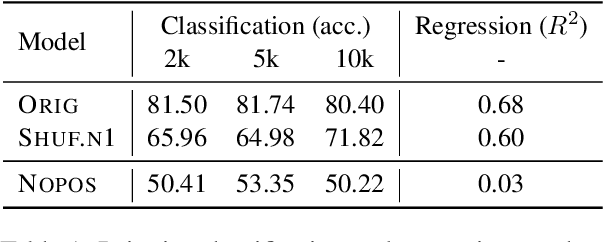
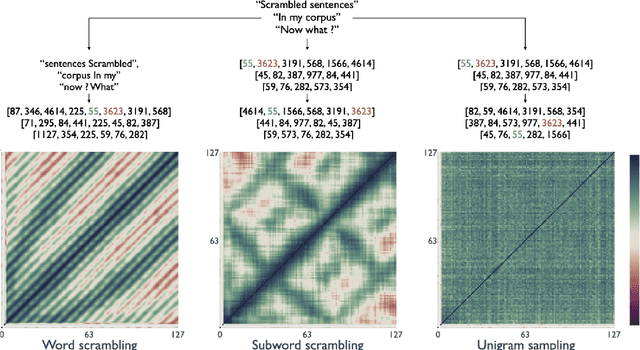
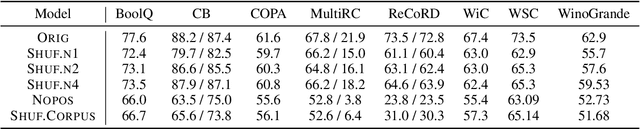
Recent studies have shown that language models pretrained and/or fine-tuned on randomly permuted sentences exhibit competitive performance on GLUE, putting into question the importance of word order information. Somewhat counter-intuitively, some of these studies also report that position embeddings appear to be crucial for models' good performance with shuffled text. We probe these language models for word order information and investigate what position embeddings learned from shuffled text encode, showing that these models retain information pertaining to the original, naturalistic word order. We show this is in part due to a subtlety in how shuffling is implemented in previous work -- before rather than after subword segmentation. Surprisingly, we find even Language models trained on text shuffled after subword segmentation retain some semblance of information about word order because of the statistical dependencies between sentence length and unigram probabilities. Finally, we show that beyond GLUE, a variety of language understanding tasks do require word order information, often to an extent that cannot be learned through fine-tuning.
FL-Defender: Combating Targeted Attacks in Federated Learning
Jul 02, 2022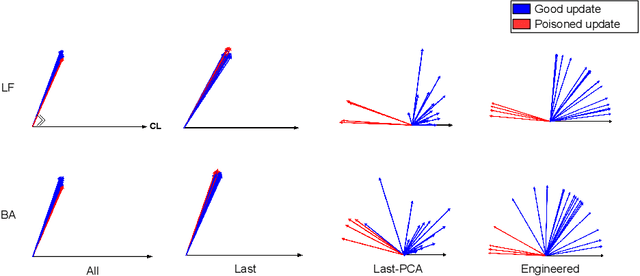
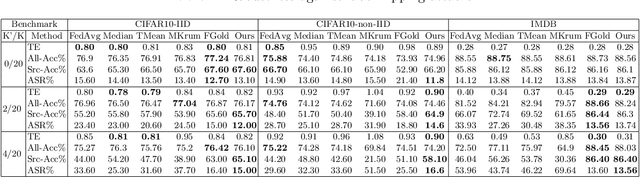
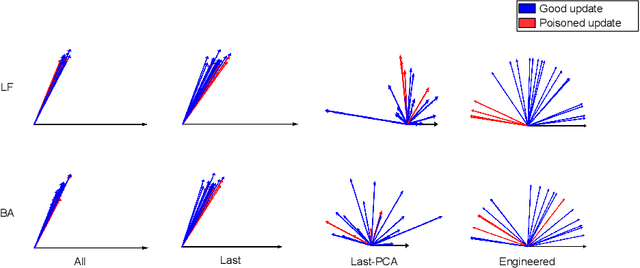
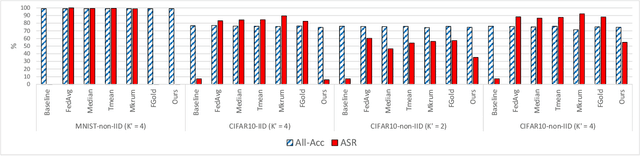
Federated learning (FL) enables learning a global machine learning model from local data distributed among a set of participating workers. This makes it possible i) to train more accurate models due to learning from rich joint training data, and ii) to improve privacy by not sharing the workers' local private data with others. However, the distributed nature of FL makes it vulnerable to targeted poisoning attacks that negatively impact the integrity of the learned model while, unfortunately, being difficult to detect. Existing defenses against those attacks are limited by assumptions on the workers' data distribution, may degrade the global model performance on the main task and/or are ill-suited to high-dimensional models. In this paper, we analyze targeted attacks against FL and find that the neurons in the last layer of a deep learning (DL) model that are related to the attacks exhibit a different behavior from the unrelated neurons, making the last-layer gradients valuable features for attack detection. Accordingly, we propose \textit{FL-Defender} as a method to combat FL targeted attacks. It consists of i) engineering more robust discriminative features by calculating the worker-wise angle similarity for the workers' last-layer gradients, ii) compressing the resulting similarity vectors using PCA to reduce redundant information, and iii) re-weighting the workers' updates based on their deviation from the centroid of the compressed similarity vectors. Experiments on three data sets with different DL model sizes and data distributions show the effectiveness of our method at defending against label-flipping and backdoor attacks. Compared to several state-of-the-art defenses, FL-Defender achieves the lowest attack success rates, maintains the performance of the global model on the main task and causes minimal computational overhead on the server.
Feature Re-calibration based MIL for Whole Slide Image Classification
Jun 22, 2022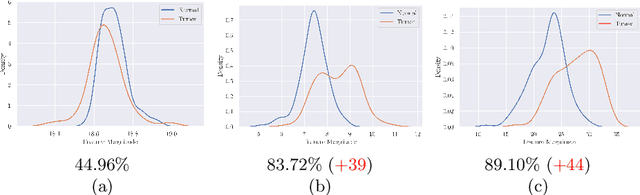
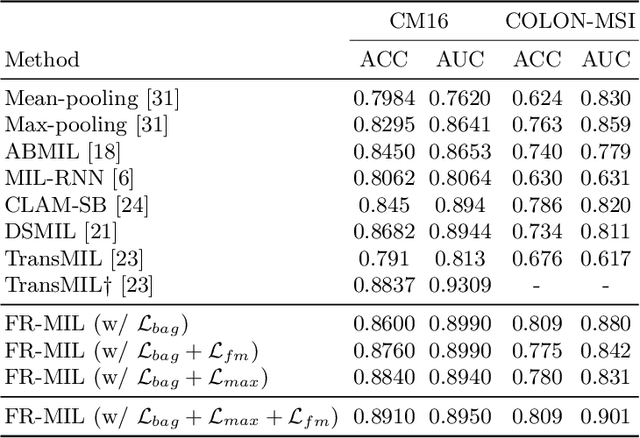
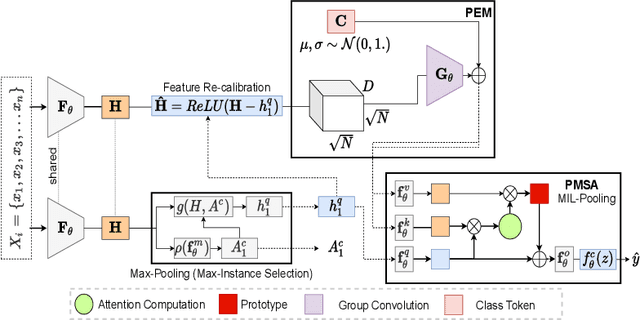
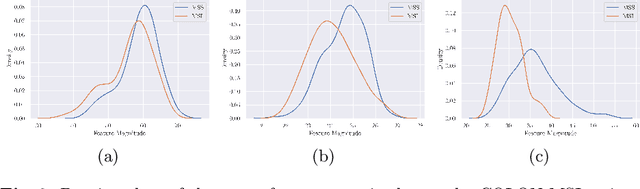
Whole slide image (WSI) classification is a fundamental task for the diagnosis and treatment of diseases; but, curation of accurate labels is time-consuming and limits the application of fully-supervised methods. To address this, multiple instance learning (MIL) is a popular method that poses classification as a weakly supervised learning task with slide-level labels only. While current MIL methods apply variants of the attention mechanism to re-weight instance features with stronger models, scant attention is paid to the properties of the data distribution. In this work, we propose to re-calibrate the distribution of a WSI bag (instances) by using the statistics of the max-instance (critical) feature. We assume that in binary MIL, positive bags have larger feature magnitudes than negatives, thus we can enforce the model to maximize the discrepancy between bags with a metric feature loss that models positive bags as out-of-distribution. To achieve this, unlike existing MIL methods that use single-batch training modes, we propose balanced-batch sampling to effectively use the feature loss i.e., (+/-) bags simultaneously. Further, we employ a position encoding module (PEM) to model spatial/morphological information, and perform pooling by multi-head self-attention (PSMA) with a Transformer encoder. Experimental results on existing benchmark datasets show our approach is effective and improves over state-of-the-art MIL methods.
Discrete Contrastive Diffusion for Cross-Modal and Conditional Generation
Jun 15, 2022
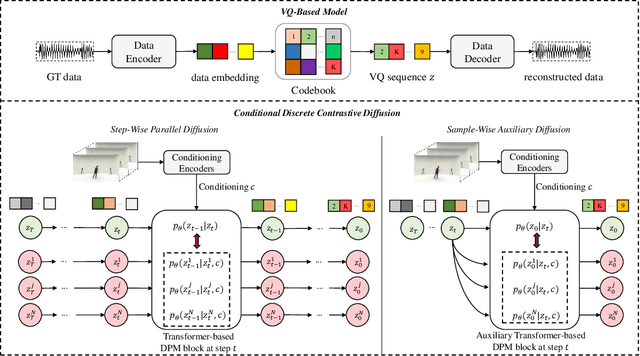

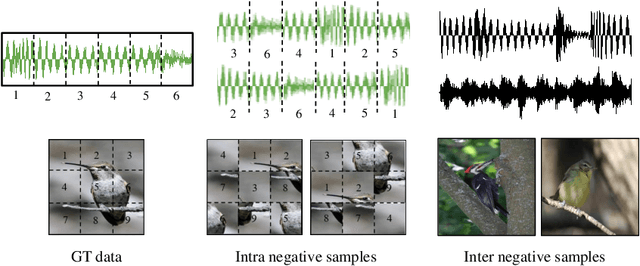
Diffusion probabilistic models (DPMs) have become a popular approach to conditional generation, due to their promising results and support for cross-modal synthesis. A key desideratum in conditional synthesis is to achieve high correspondence between the conditioning input and generated output. Most existing methods learn such relationships implicitly, by incorporating the prior into the variational lower bound. In this work, we take a different route -- we enhance input-output connections by maximizing their mutual information using contrastive learning. To this end, we introduce a Conditional Discrete Contrastive Diffusion (CDCD) loss and design two contrastive diffusion mechanisms to effectively incorporate it into the denoising process. We formulate CDCD by connecting it with the conventional variational objectives. We demonstrate the efficacy of our approach in evaluations with three diverse, multimodal conditional synthesis tasks: dance-to-music generation, text-to-image synthesis, and class-conditioned image synthesis. On each, we achieve state-of-the-art or higher synthesis quality and improve the input-output correspondence. Furthermore, the proposed approach improves the convergence of diffusion models, reducing the number of required diffusion steps by more than 35% on two benchmarks, significantly increasing the inference speed.
TrafficFlowGAN: Physics-informed Flow based Generative Adversarial Network for Uncertainty Quantification
Jun 19, 2022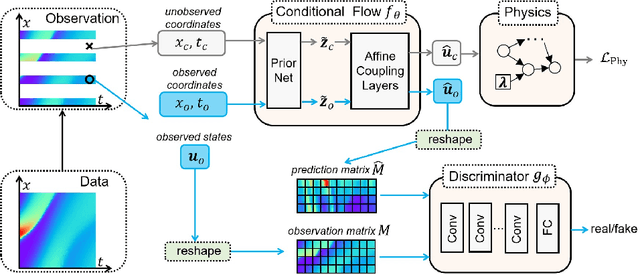
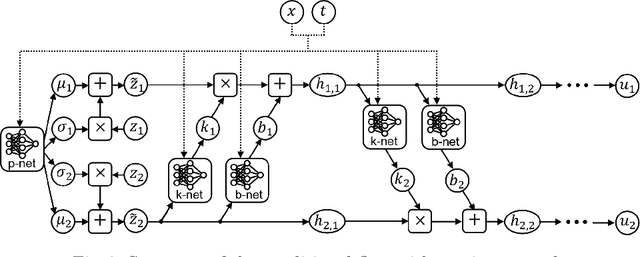
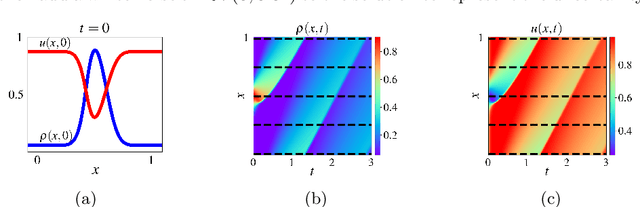
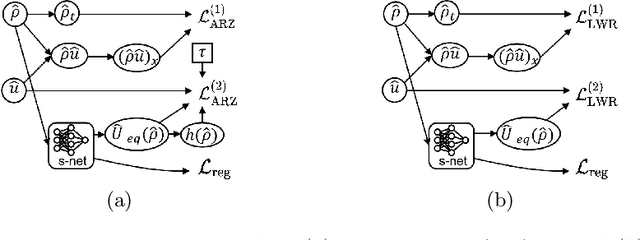
This paper proposes the TrafficFlowGAN, a physics-informed flow based generative adversarial network (GAN), for uncertainty quantification (UQ) of dynamical systems. TrafficFlowGAN adopts a normalizing flow model as the generator to explicitly estimate the data likelihood. This flow model is trained to maximize the data likelihood and to generate synthetic data that can fool a convolutional discriminator. We further regularize this training process using prior physics information, so-called physics-informed deep learning (PIDL). To the best of our knowledge, we are the first to propose an integration of flow, GAN and PIDL for the UQ problems. We take the traffic state estimation (TSE), which aims to estimate the traffic variables (e.g. traffic density and velocity) using partially observed data, as an example to demonstrate the performance of our proposed model. We conduct numerical experiments where the proposed model is applied to learn the solutions of stochastic differential equations. The results demonstrate the robustness and accuracy of the proposed model, together with the ability to learn a machine learning surrogate model. We also test it on a real-world dataset, the Next Generation SIMulation (NGSIM), to show that the proposed TrafficFlowGAN can outperform the baselines, including the pure flow model, the physics-informed flow model, and the flow based GAN model.
SAVi++: Towards End-to-End Object-Centric Learning from Real-World Videos
Jun 15, 2022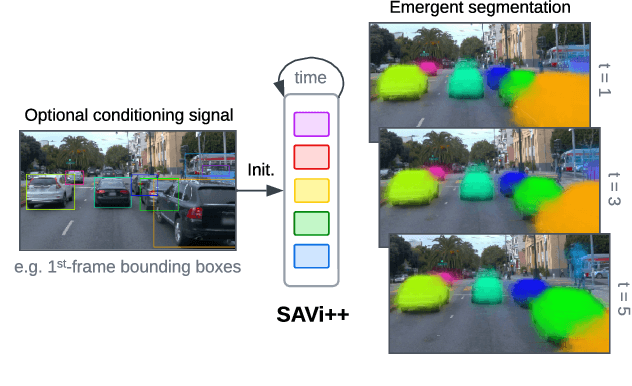
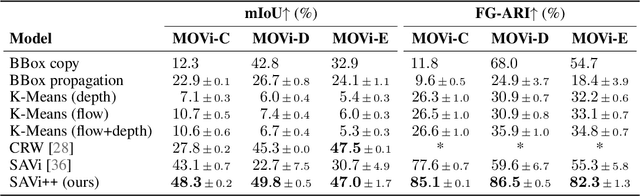
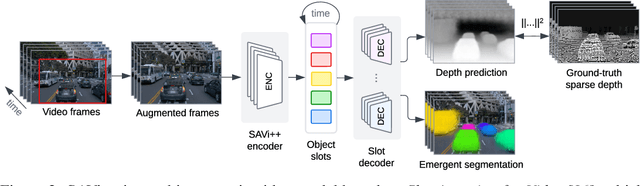

The visual world can be parsimoniously characterized in terms of distinct entities with sparse interactions. Discovering this compositional structure in dynamic visual scenes has proven challenging for end-to-end computer vision approaches unless explicit instance-level supervision is provided. Slot-based models leveraging motion cues have recently shown great promise in learning to represent, segment, and track objects without direct supervision, but they still fail to scale to complex real-world multi-object videos. In an effort to bridge this gap, we take inspiration from human development and hypothesize that information about scene geometry in the form of depth signals can facilitate object-centric learning. We introduce SAVi++, an object-centric video model which is trained to predict depth signals from a slot-based video representation. By further leveraging best practices for model scaling, we are able to train SAVi++ to segment complex dynamic scenes recorded with moving cameras, containing both static and moving objects of diverse appearance on naturalistic backgrounds, without the need for segmentation supervision. Finally, we demonstrate that by using sparse depth signals obtained from LiDAR, SAVi++ is able to learn emergent object segmentation and tracking from videos in the real-world Waymo Open dataset.
On the Capacity-Achieving Input of the Gaussian Channel with Polar Quantization
May 12, 2022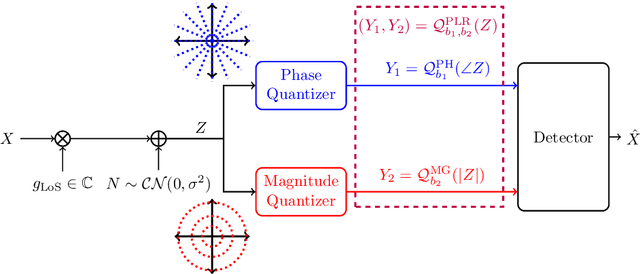
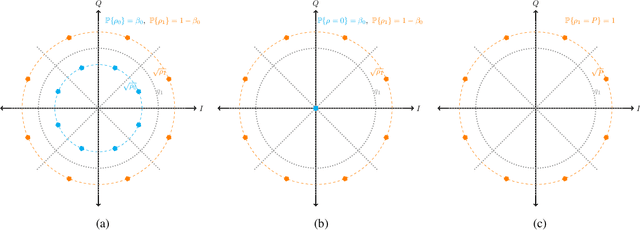
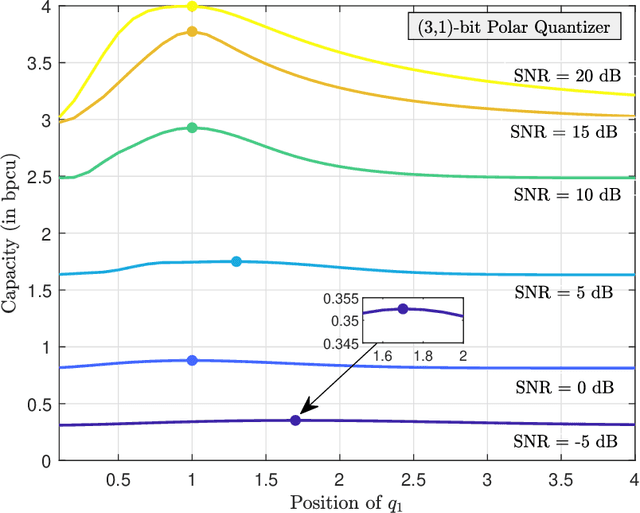
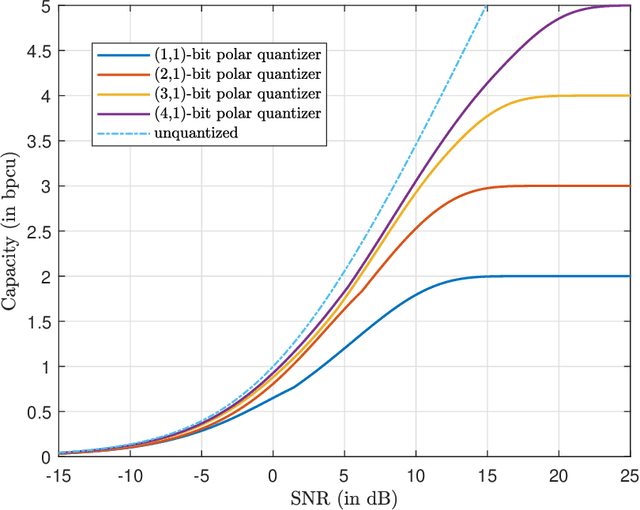
The polar receiver architecture is a receiver design that captures the envelope and phase information of the signal rather than its in-phase and quadrature components. Several studies have demonstrated the robustness of polar receivers to phase noise and other nonlinearities. Yet, the information-theoretic limits of polar receivers with finite-precision quantizers have not been investigated in the literature. The main contribution of this work is to identify the optimal signaling strategy for the additive white Gaussian noise (AWGN) channel with polar quantization at the output. More precisely, we show that the capacity-achieving modulation scheme has an amplitude phase shift keying (APSK) structure. Using this result, the capacity of the AWGN channel with polar quantization at the output is established by numerically optimizing the probability mass function of the amplitude. The capacity of the polar-quantized AWGN channel with $b_1$-bit phase quantizer and optimized single-bit magnitude quantizer is also presented. Our numerical findings suggest the existence of signal-to-noise ratio (SNR) thresholds, above which the number of amplitude levels of the optimal APSK scheme and their respective probabilities change abruptly. Moreover, the manner in which the capacity-achieving input evolves with increasing SNR depends on the number of phase quantization bits.
GOF-TTE: Generative Online Federated Learning Framework for Travel Time Estimation
Jul 02, 2022
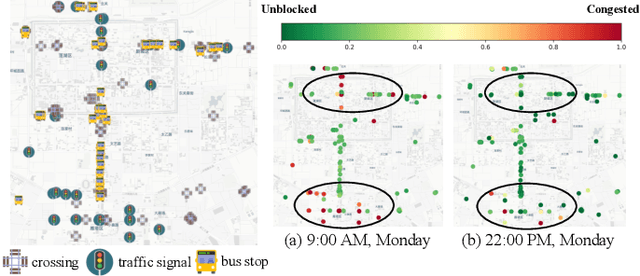
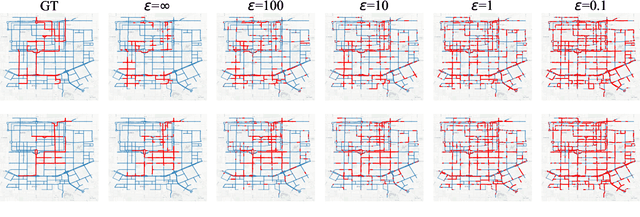
Estimating the travel time of a path is an essential topic for intelligent transportation systems. It serves as the foundation for real-world applications, such as traffic monitoring, route planning, and taxi dispatching. However, building a model for such a data-driven task requires a large amount of users' travel information, which directly relates to their privacy and thus is less likely to be shared. The non-Independent and Identically Distributed (non-IID) trajectory data across data owners also make a predictive model extremely challenging to be personalized if we directly apply federated learning. Finally, previous work on travel time estimation does not consider the real-time traffic state of roads, which we argue can significantly influence the prediction. To address the above challenges, we introduce GOF-TTE for the mobile user group, Generative Online Federated Learning Framework for Travel Time Estimation, which I) utilizes the federated learning approach, allowing private data to be kept on client devices while training, and designs the global model as an online generative model shared by all clients to infer the real-time road traffic state. II) apart from sharing a base model at the server, adapts a fine-tuned personalized model for every client to study their personal driving habits, making up for the residual error made by localized global model prediction. % III) designs the global model as an online generative model shared by all clients to infer the real-time road traffic state. We also employ a simple privacy attack to our framework and implement the differential privacy mechanism to further guarantee privacy safety. Finally, we conduct experiments on two real-world public taxi datasets of DiDi Chengdu and Xi'an. The experimental results demonstrate the effectiveness of our proposed framework.