 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Using Graph Neural Networks to Predict Local Culture
Feb 27, 2024
Urban research has long recognized that neighbourhoods are dynamic and relational. However, lack of data, methodologies, and computer processing power have hampered a formal quantitative examination of neighbourhood relational dynamics. To make progress on this issue, this study proposes a graph neural network (GNN) approach that permits combining and evaluating multiple sources of information about internal characteristics of neighbourhoods, their past characteristics, and flows of groups among them, potentially providing greater expressive power in predictive models. By exploring a public large-scale dataset from Yelp, we show the potential of our approach for considering structural connectedness in predicting neighbourhood attributes, specifically to predict local culture. Results are promising from a substantive and methodologically point of view. Substantively, we find that either local area information (e.g. area demographics) or group profiles (tastes of Yelp reviewers) give the best results in predicting local culture, and they are nearly equivalent in all studied cases. Methodologically, exploring group profiles could be a helpful alternative where finding local information for specific areas is challenging, since they can be extracted automatically from many forms of online data. Thus, our approach could empower researchers and policy-makers to use a range of data sources when other local area information is lacking.
OVEL: Large Language Model as Memory Manager for Online Video Entity Linking
Mar 03, 2024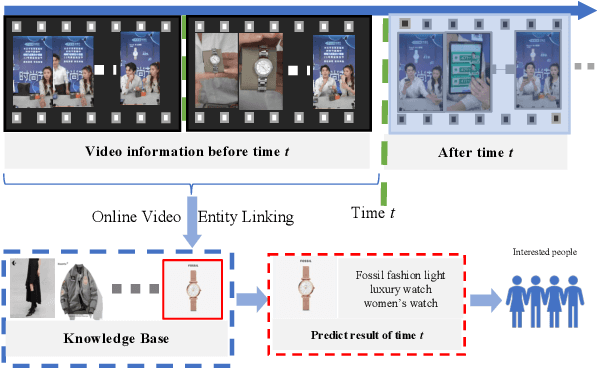
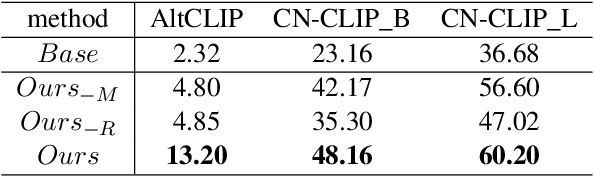
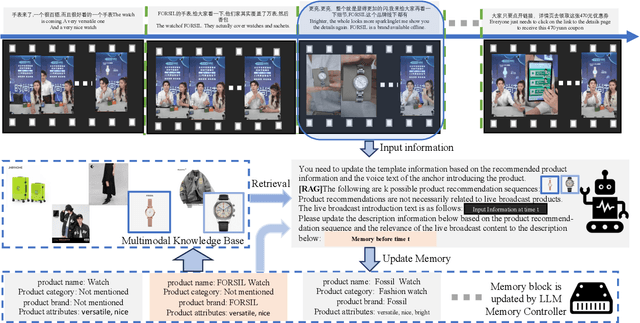
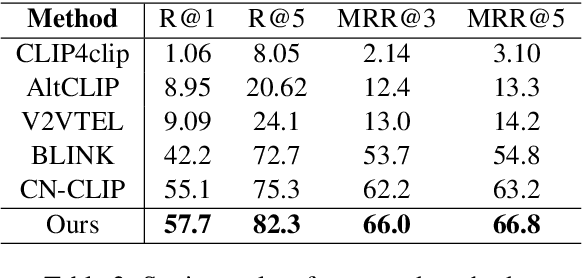
In recent years, multi-modal entity linking (MEL) has garnered increasing attention in the research community due to its significance in numerous multi-modal applications. Video, as a popular means of information transmission, has become prevalent in people's daily lives. However, most existing MEL methods primarily focus on linking textual and visual mentions or offline videos's mentions to entities in multi-modal knowledge bases, with limited efforts devoted to linking mentions within online video content. In this paper, we propose a task called Online Video Entity Linking OVEL, aiming to establish connections between mentions in online videos and a knowledge base with high accuracy and timeliness. To facilitate the research works of OVEL, we specifically concentrate on live delivery scenarios and construct a live delivery entity linking dataset called LIVE. Besides, we propose an evaluation metric that considers timelessness, robustness, and accuracy. Furthermore, to effectively handle OVEL task, we leverage a memory block managed by a Large Language Model and retrieve entity candidates from the knowledge base to augment LLM performance on memory management. The experimental results prove the effectiveness and efficiency of our method.
Multiview Subspace Clustering of Hyperspectral Images based on Graph Convolutional Networks
Mar 03, 2024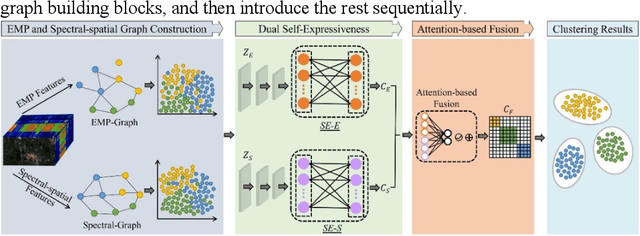
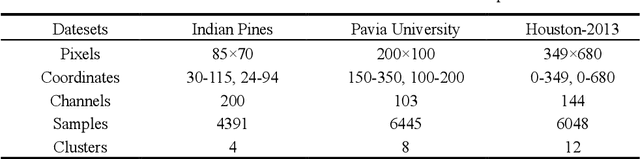
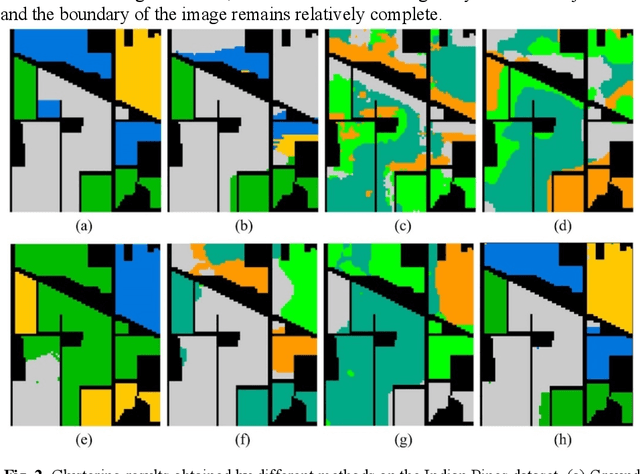

High-dimensional and complex spectral structures make clustering of hy-perspectral images (HSI) a challenging task. Subspace clustering has been shown to be an effective approach for addressing this problem. However, current subspace clustering algorithms are mainly designed for a single view and do not fully exploit spatial or texture feature information in HSI. This study proposed a multiview subspace clustering of HSI based on graph convolutional networks. (1) This paper uses the powerful classification ability of graph convolutional network and the learning ability of topologi-cal relationships between nodes to analyze and express the spatial relation-ship of HSI. (2) Pixel texture and pixel neighbor spatial-spectral infor-mation were sent to construct two graph convolutional subspaces. (3) An attention-based fusion module was used to adaptively construct a more discriminative feature map. The model was evaluated on three popular HSI datasets, including Indian Pines, Pavia University, and Houston. It achieved overall accuracies of 92.38%, 93.43%, and 83.82%, respectively and significantly outperformed the state-of-the-art clustering methods. In conclusion, the proposed model can effectively improve the clustering ac-curacy of HSI.
Collaborate to Adapt: Source-Free Graph Domain Adaptation via Bi-directional Adaptation
Mar 03, 2024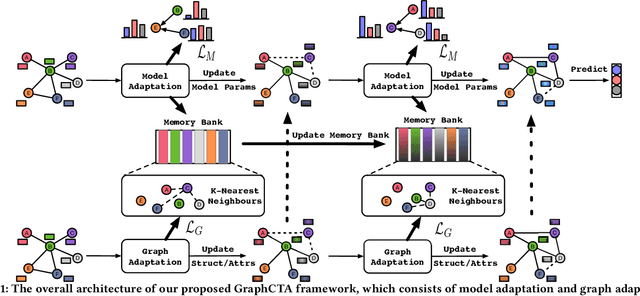
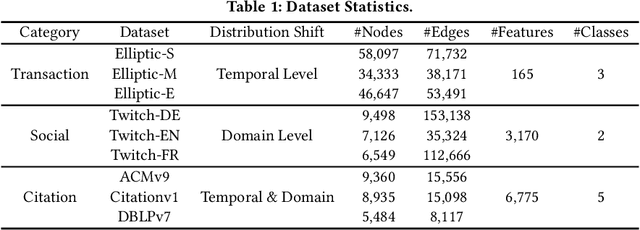
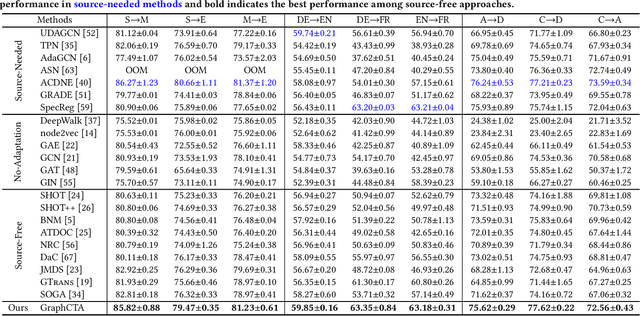
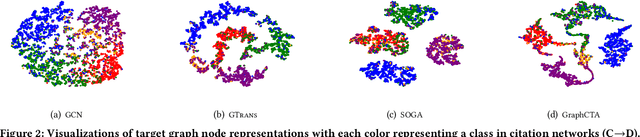
Unsupervised Graph Domain Adaptation (UGDA) has emerged as a practical solution to transfer knowledge from a label-rich source graph to a completely unlabelled target graph. However, most methods require a labelled source graph to provide supervision signals, which might not be accessible in the real-world settings due to regulations and privacy concerns. In this paper, we explore the scenario of source-free unsupervised graph domain adaptation, which tries to address the domain adaptation problem without accessing the labelled source graph. Specifically, we present a novel paradigm called GraphCTA, which performs model adaptation and graph adaptation collaboratively through a series of procedures: (1) conduct model adaptation based on node's neighborhood predictions in target graph considering both local and global information; (2) perform graph adaptation by updating graph structure and node attributes via neighborhood contrastive learning; and (3) the updated graph serves as an input to facilitate the subsequent iteration of model adaptation, thereby establishing a collaborative loop between model adaptation and graph adaptation. Comprehensive experiments are conducted on various public datasets. The experimental results demonstrate that our proposed model outperforms recent source-free baselines by large margins.
Density-based Isometric Mapping
Mar 04, 2024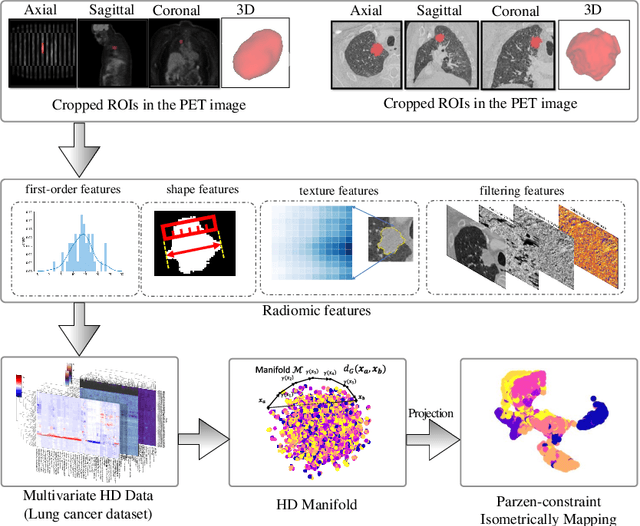
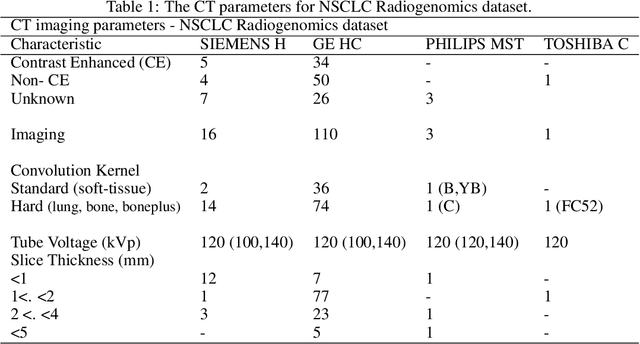
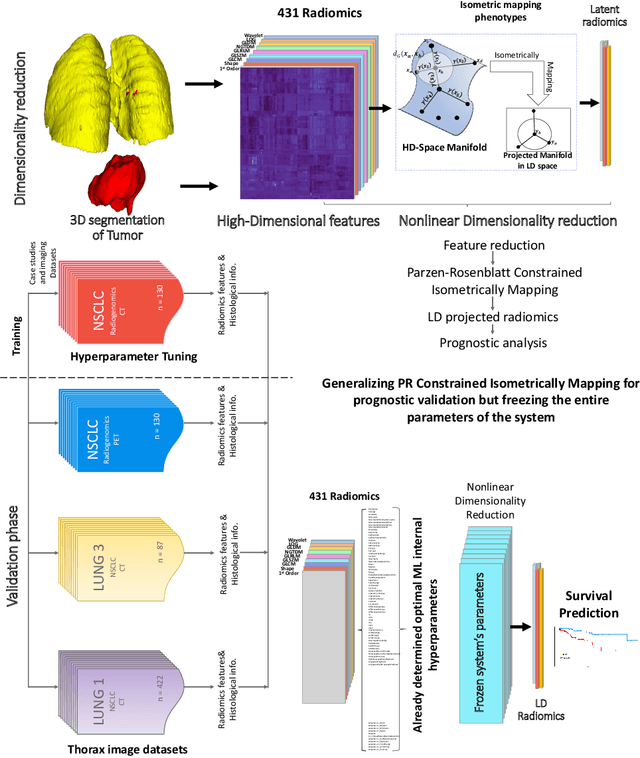
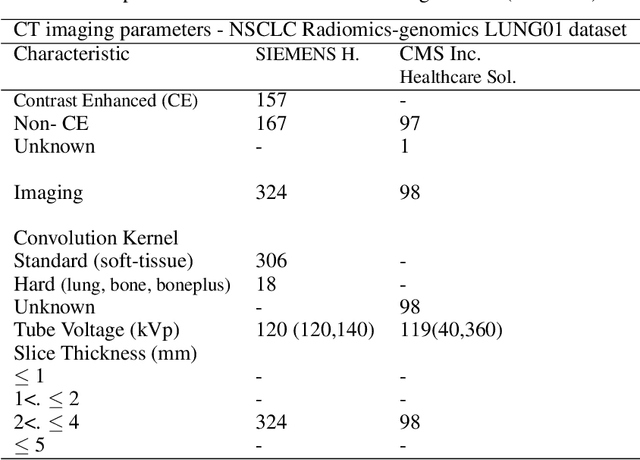
The isometric mapping method employs the shortest path algorithm to estimate the Euclidean distance between points on High dimensional (HD) manifolds. This may not be sufficient for weakly uniformed HD data as it could lead to overestimating distances between far neighboring points, resulting in inconsistencies between the intrinsic (local) and extrinsic (global) distances during the projection. To address this issue, we modify the shortest path algorithm by adding a novel constraint inspired by the Parzen-Rosenblatt (PR) window, which helps to maintain the uniformity of the constructed shortest-path graph in Isomap. Multiple imaging datasets overall of 72,236 cases, 70,000 MINST data, 1596 from multiple Chest-XRay pneumonia datasets, and three NSCLC CT/PET datasets with a total of 640 lung cancer patients, were used to benchmark and validate PR-Isomap. 431 imaging biomarkers were extracted from each modality. Our results indicate that PR-Isomap projects HD attributes into a lower-dimensional (LD) space while preserving information, visualized by the MNIST dataset indicating the maintaining local and global distances. PR-Isomap achieved the highest comparative accuracies of 80.9% (STD:5.8) for pneumonia and 78.5% (STD:4.4), 88.4% (STD:1.4), and 61.4% (STD:11.4) for three NSCLC datasets, with a confidence interval of 95% for outcome prediction. Similarly, the multivariate Cox model showed higher overall survival, measured with c-statistics and log-likelihood test, of PR-Isomap compared to other dimensionality reduction methods. Kaplan Meier survival curve also signifies the notable ability of PR-Isomap to distinguish between high-risk and low-risk patients using multimodal imaging biomarkers preserving HD imaging characteristics for precision medicine.
Can LLMs Generate Architectural Design Decisions? -An Exploratory Empirical study
Mar 04, 2024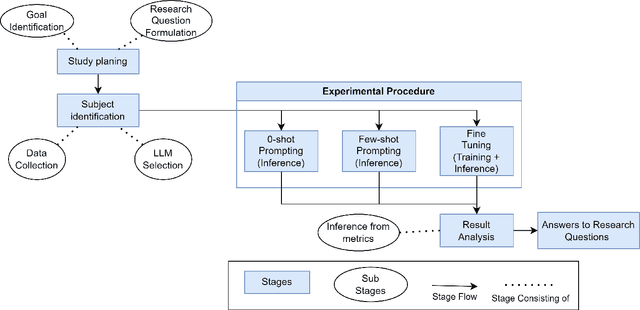



Architectural Knowledge Management (AKM) involves the organized handling of information related to architectural decisions and design within a project or organization. An essential artifact of AKM is the Architecture Decision Records (ADR), which documents key design decisions. ADRs are documents that capture decision context, decision made and various aspects related to a design decision, thereby promoting transparency, collaboration, and understanding. Despite their benefits, ADR adoption in software development has been slow due to challenges like time constraints and inconsistent uptake. Recent advancements in Large Language Models (LLMs) may help bridge this adoption gap by facilitating ADR generation. However, the effectiveness of LLM for ADR generation or understanding is something that has not been explored. To this end, in this work, we perform an exploratory study that aims to investigate the feasibility of using LLM for the generation of ADRs given the decision context. In our exploratory study, we utilize GPT and T5-based models with 0-shot, few-shot, and fine-tuning approaches to generate the Decision of an ADR given its Context. Our results indicate that in a 0-shot setting, state-of-the-art models such as GPT-4 generate relevant and accurate Design Decisions, although they fall short of human-level performance. Additionally, we observe that more cost-effective models like GPT-3.5 can achieve similar outcomes in a few-shot setting, and smaller models such as Flan-T5 can yield comparable results after fine-tuning. To conclude, this exploratory study suggests that LLM can generate Design Decisions, but further research is required to attain human-level generation and establish standardized widespread adoption.
UB-FineNet: Urban Building Fine-grained Classification Network for Open-access Satellite Images
Mar 04, 2024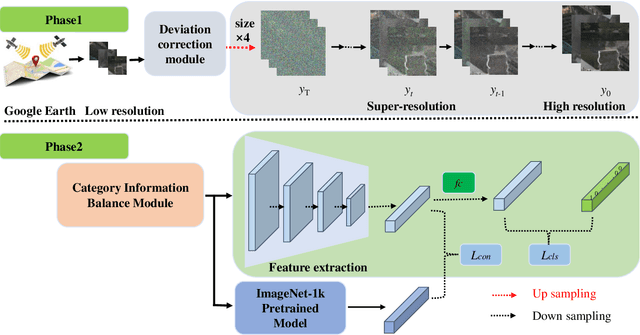
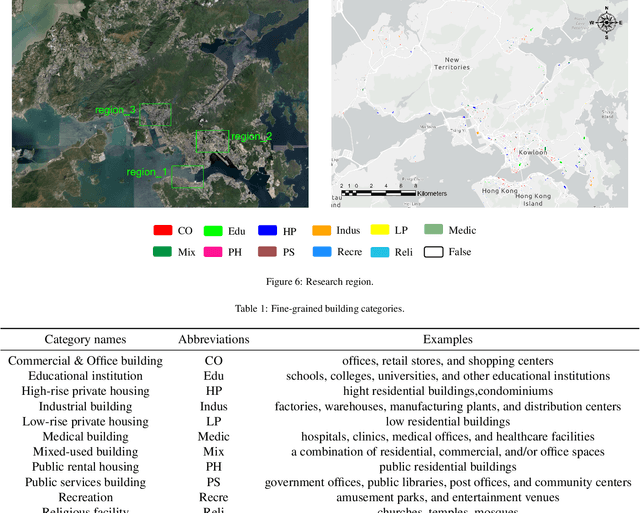
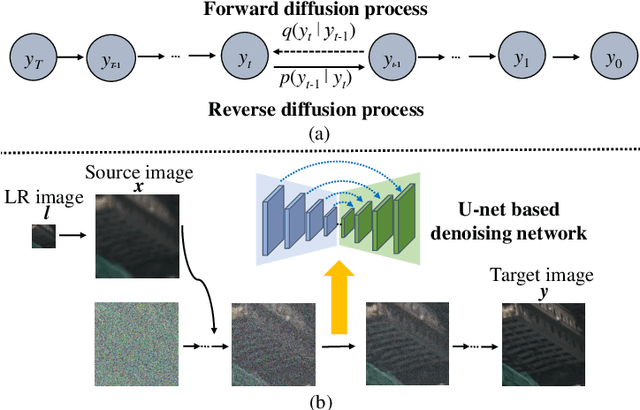
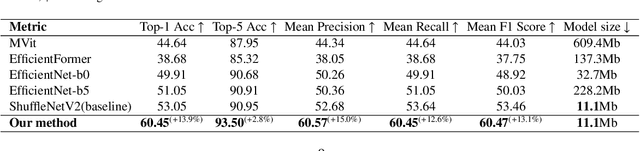
Fine classification of city-scale buildings from satellite remote sensing imagery is a crucial research area with significant implications for urban planning, infrastructure development, and population distribution analysis. However, the task faces big challenges due to low-resolution overhead images acquired from high altitude space-borne platforms and the long-tail sample distribution of fine-grained urban building categories, leading to severe class imbalance problem. To address these issues, we propose a deep network approach to fine-grained classification of urban buildings using open-access satellite images. A Denoising Diffusion Probabilistic Model (DDPM) based super-resolution method is first introduced to enhance the spatial resolution of satellite images, which benefits from domain-adaptive knowledge distillation. Then, a new fine-grained classification network with Category Information Balancing Module (CIBM) and Contrastive Supervision (CS) technique is proposed to mitigate the problem of class imbalance and improve the classification robustness and accuracy. Experiments on Hong Kong data set with 11 fine building types revealed promising classification results with a mean Top-1 accuracy of 60.45\%, which is on par with street-view image based approaches. Extensive ablation study shows that CIBM and CS improve Top-1 accuracy by 2.6\% and 3.5\% compared to the baseline method, respectively. And both modules can be easily inserted into other classification networks and similar enhancements have been achieved. Our research contributes to the field of urban analysis by providing a practical solution for fine classification of buildings in challenging mega city scenarios solely using open-access satellite images. The proposed method can serve as a valuable tool for urban planners, aiding in the understanding of economic, industrial, and population distribution.
A Data-Driven Two-Phase Multi-Split Causal Ensemble Model for Time Series
Mar 04, 2024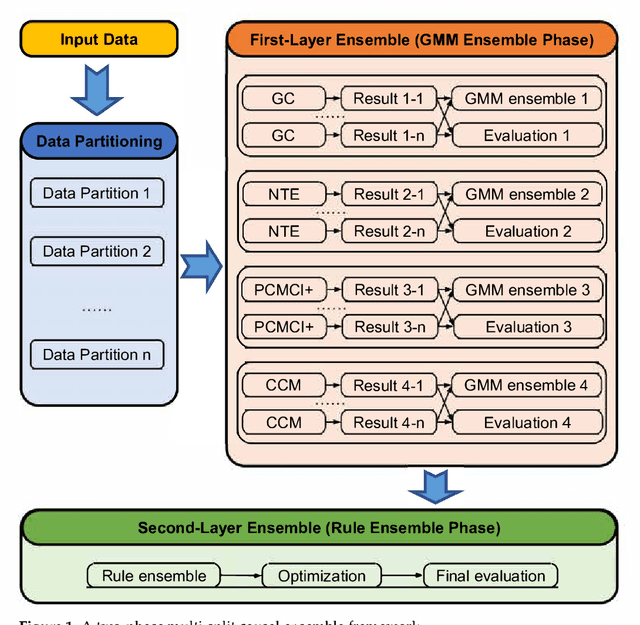

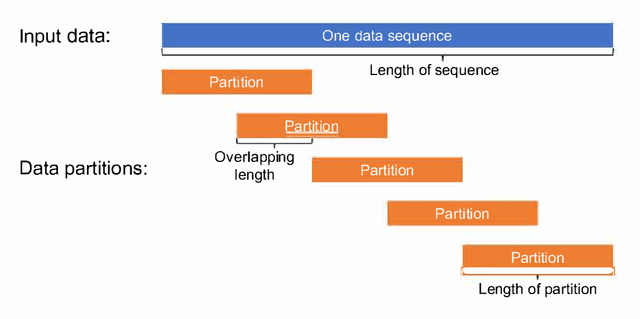

Causal inference is a fundamental research topic for discovering the cause-effect relationships in many disciplines. However, not all algorithms are equally well-suited for a given dataset. For instance, some approaches may only be able to identify linear relationships, while others are applicable for non-linearities. Algorithms further vary in their sensitivity to noise and their ability to infer causal information from coupled vs. non-coupled time series. Therefore, different algorithms often generate different causal relationships for the same input. To achieve a more robust causal inference result, this publication proposes a novel data-driven two-phase multi-split causal ensemble model to combine the strengths of different causality base algorithms. In comparison to existing approaches, the proposed ensemble method reduces the influence of noise through a data partitioning scheme in the first phase. To achieve this, the data are initially divided into several partitions and the base algorithms are applied to each partition. Subsequently, Gaussian mixture models are used to identify the causal relationships derived from the different partitions that are likely to be valid. In the second phase, the identified relationships from each base algorithm are then merged based on three combination rules. The proposed ensemble approach is evaluated using multiple metrics, among them a newly developed evaluation index for causal ensemble approaches. We perform experiments using three synthetic datasets with different volumes and complexity, which are specifically designed to test causality detection methods under different circumstances while knowing the ground truth causal relationships. In these experiments, our causality ensemble outperforms each of its base algorithms. In practical applications, the use of the proposed method could hence lead to more robust and reliable causality results.
RAGged Edges: The Double-Edged Sword of Retrieval-Augmented Chatbots
Mar 02, 2024

Large language models (LLMs) like ChatGPT demonstrate the remarkable progress of artificial intelligence. However, their tendency to hallucinate -- generate plausible but false information -- poses a significant challenge. This issue is critical, as seen in recent court cases where ChatGPT's use led to citations of non-existent legal rulings. This paper explores how Retrieval-Augmented Generation (RAG) can counter hallucinations by integrating external knowledge with prompts. We empirically evaluate RAG against standard LLMs using prompts designed to induce hallucinations. Our results show that RAG increases accuracy in some cases, but can still be misled when prompts directly contradict the model's pre-trained understanding. These findings highlight the complex nature of hallucinations and the need for more robust solutions to ensure LLM reliability in real-world applications. We offer practical recommendations for RAG deployment and discuss implications for the development of more trustworthy LLMs.
Reading Relevant Feature from Global Representation Memory for Visual Object Tracking
Feb 26, 2024Reference features from a template or historical frames are crucial for visual object tracking. Prior works utilize all features from a fixed template or memory for visual object tracking. However, due to the dynamic nature of videos, the required reference historical information for different search regions at different time steps is also inconsistent. Therefore, using all features in the template and memory can lead to redundancy and impair tracking performance. To alleviate this issue, we propose a novel tracking paradigm, consisting of a relevance attention mechanism and a global representation memory, which can adaptively assist the search region in selecting the most relevant historical information from reference features. Specifically, the proposed relevance attention mechanism in this work differs from previous approaches in that it can dynamically choose and build the optimal global representation memory for the current frame by accessing cross-frame information globally. Moreover, it can flexibly read the relevant historical information from the constructed memory to reduce redundancy and counteract the negative effects of harmful information. Extensive experiments validate the effectiveness of the proposed method, achieving competitive performance on five challenging datasets with 71 FPS.