 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Research Agenda on Agents and Software Engineering: Outcomes from the Rio A2SE Seminar
May 12, 2026The rise of agentic AI is reshaping software engineering in two intertwined directions: agents are increasingly applied to support software engineering tasks, and Agentic AI systems themselves are complex systems that require re-thinking currently established software engineering practices. To chart a coherent research agenda covering the two directions, we organized the A2SE seminar in Rio de Janeiro, bringing together 18 experts from academia and industry. Through structured presentations, collaborative topic clustering, and focused group discussions, participants identified six thematic areas: Governance, Software Engineering for Agents, Agents for Software Architecture, Quality and Evaluation, Sustainability, and Code, and they prioritized short-term and long-term research directions for each. This paper presents the resulting community-driven, opinionated research agenda, offering the SE community a structured foundation for coordinating efforts at this critical juncture.
LLM-based Automated Architecture View Generation: Where Are We Now?
Mar 22, 2026Architecture views are essential for software architecture documentation, yet their manual creation is labor intensive and often leads to outdated artifacts. As systems grow in complexity, the automated generation of views from source code becomes increasingly valuable. Goal: We empirically evaluate the ability of LLMs and agentic approaches to generate architecture views from source code. Method: We analyze 340 open-source repositories across 13 experimental configurations using 3 LLMs with 3 prompting techniques and 2 agentic approaches, yielding 4,137 generated views. We evaluate the generated views by comparing them with the ground-truth using a combination of automated metrics complemented by human evaluations. Results: Prompting strategies offer marginal improvements. Few-shot prompting reduces clarity failures by 9.2% compared to zero-shot baselines. The custom agentic approach consistently outperforms the general-purpose agent, achieving the best clarity (22.6% failure rate) and level-of-detail success (50%). Conclusions: LLM and agentic approaches demonstrate capabilities in generating syntactically valid architecture views. However, they consistently exhibit granularity mismatches, operating at the code level rather than architectural abstractions. This suggests that there is still a need for human expertise, positioning LLMs and agents as assistive tools rather than autonomous architects.
Harmonica: A Self-Adaptation Exemplar for Sustainable MLOps
Jan 17, 2026Machine learning enabled systems (MLS) often operate in settings where they regularly encounter uncertainties arising from changes in their surrounding environment. Without structured oversight, such changes can degrade model behavior, increase operational cost, and reduce the usefulness of deployed systems. Although Machine Learning Operations (MLOps) streamlines the lifecycle of ML models, it provides limited support for addressing runtime uncertainties that influence the longer term sustainability of MLS. To support continued viability, these systems need a mechanism that detects when execution drifts outside acceptable bounds and adjusts system behavior in response. Despite the growing interest in sustainable and self-adaptive MLS, there has been limited work towards exemplars that allow researchers to study these challenges in MLOps pipelines. This paper presents Harmonica, a self-adaptation exemplar built on the HarmonE approach, designed to enable the sustainable operation of such pipelines. Harmonica introduces structured adaptive control through MAPE-K loop, separating high-level adaptation policy from low-level tactic execution. It continuously monitors sustainability metrics, evaluates them against dynamic adaptation boundaries, and automatically triggers architectural tactics when thresholds are violated. We demonstrate the tool through case studies in time series regression and computer vision, examining its ability to improve system stability and reduce manual intervention. The results show that Harmonica offers a practical and reusable foundation for enabling adaptive behavior in MLS that rely on MLOps pipelines for sustained operation.
Beyond Task Completion: An Assessment Framework for Evaluating Agentic AI Systems
Dec 16, 2025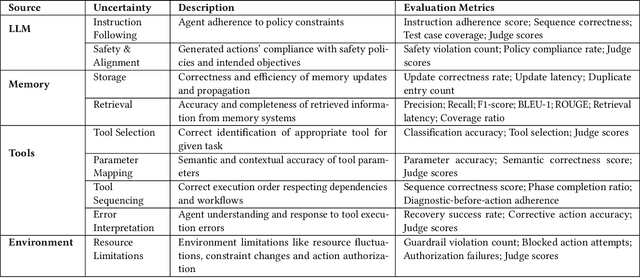
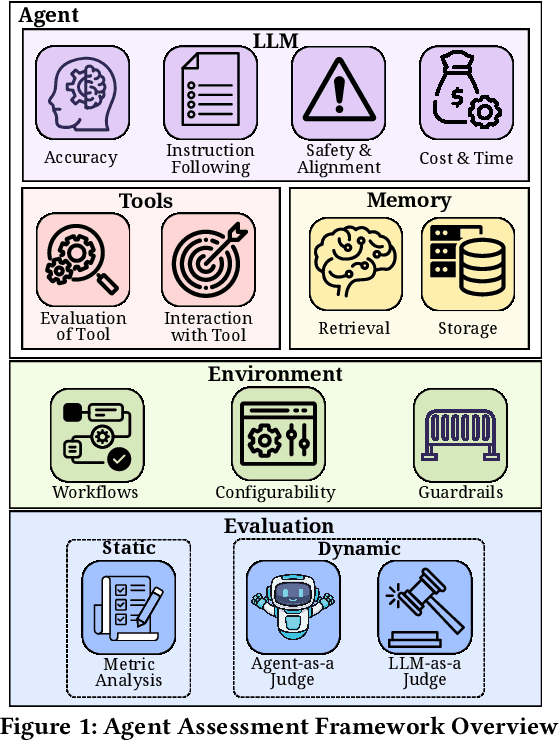
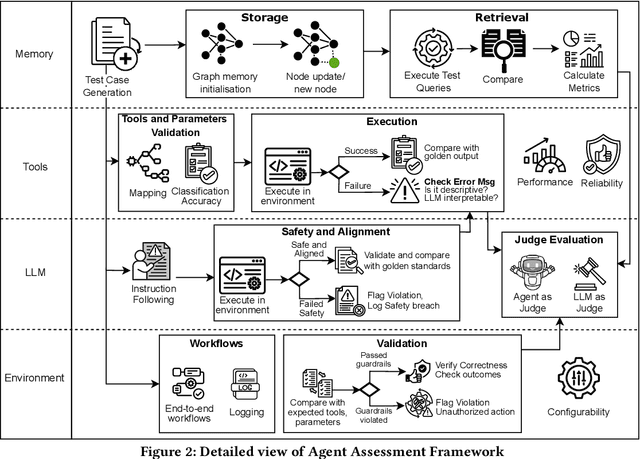
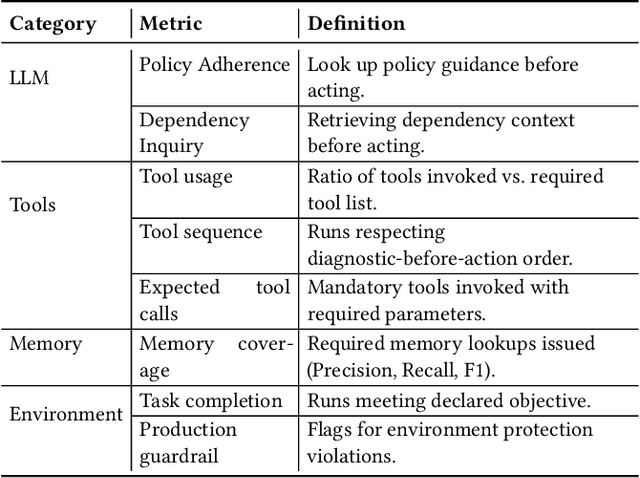
Recent advances in agentic AI have shifted the focus from standalone Large Language Models (LLMs) to integrated systems that combine LLMs with tools, memory, and other agents to perform complex tasks. These multi-agent architectures enable coordinated reasoning, planning, and execution across diverse domains, allowing agents to collaboratively automate complex workflows. Despite these advances, evaluation and assessment of LLM agents and the multi-agent systems they constitute remain a fundamental challenge. Although various approaches have been proposed in the software engineering literature for evaluating conventional software components, existing methods for AI-based systems often overlook the non-deterministic nature of models. This non-determinism introduces behavioral uncertainty during execution, yet existing evaluations rely on binary task completion metrics that fail to capture it. Evaluating agentic systems therefore requires examining additional dimensions, including the agent ability to invoke tools, ingest and retrieve memory, collaborate with other agents, and interact effectively with its environment. These challenges emerged during our ongoing industry collaboration with MontyCloud Inc., when we deployed an agentic system in production. These limitations surfaced during deployment, highlighting practical gaps in the current evaluation methods and the need for a systematic assessment of agent behavior beyond task outcomes. Informed by these observations and established definitions of agentic systems, we propose an end-to-end Agent Assessment Framework with four evaluation pillars encompassing LLMs, Memory, Tools, and Environment. We validate the framework on a representative Autonomous CloudOps use case, where experiments reveal behavioral deviations overlooked by conventional metrics, demonstrating its effectiveness in capturing runtime uncertainties.
SWEnergy: An Empirical Study on Energy Efficiency in Agentic Issue Resolution Frameworks with SLMs
Dec 11, 2025Context. LLM-based autonomous agents in software engineering rely on large, proprietary models, limiting local deployment. This has spurred interest in Small Language Models (SLMs), but their practical effectiveness and efficiency within complex agentic frameworks for automated issue resolution remain poorly understood. Goal. We investigate the performance, energy efficiency, and resource consumption of four leading agentic issue resolution frameworks when deliberately constrained to using SLMs. We aim to assess the viability of these systems for this task in resource-limited settings and characterize the resulting trade-offs. Method. We conduct a controlled evaluation of four leading agentic frameworks (SWE-Agent, OpenHands, Mini SWE Agent, AutoCodeRover) using two SLMs (Gemma-3 4B, Qwen-3 1.7B) on the SWE-bench Verified Mini benchmark. On fixed hardware, we measure energy, duration, token usage, and memory over 150 runs per configuration. Results. We find that framework architecture is the primary driver of energy consumption. The most energy-intensive framework, AutoCodeRover (Gemma), consumed 9.4x more energy on average than the least energy-intensive, OpenHands (Gemma). However, this energy is largely wasted. Task resolution rates were near-zero, demonstrating that current frameworks, when paired with SLMs, consume significant energy on unproductive reasoning loops. The SLM's limited reasoning was the bottleneck for success, but the framework's design was the bottleneck for efficiency. Conclusions. Current agentic frameworks, designed for powerful LLMs, fail to operate efficiently with SLMs. We find that framework architecture is the primary driver of energy consumption, but this energy is largely wasted due to the SLMs' limited reasoning. Viable low-energy solutions require shifting from passive orchestration to architectures that actively manage SLM weaknesses.
SCAR: State-Space Compression for AI-Driven Resource Management in 6G-Enabled Vehicular Infotainment Systems
Aug 08, 2025The advent of 6G networks opens new possibilities for connected infotainment services in vehicular environments. However, traditional Radio Resource Management (RRM) techniques struggle with the increasing volume and complexity of data such as Channel Quality Indicators (CQI) from autonomous vehicles. To address this, we propose SCAR (State-Space Compression for AI-Driven Resource Management), an Edge AI-assisted framework that optimizes scheduling and fairness in vehicular infotainment. SCAR employs ML-based compression techniques (e.g., clustering and RBF networks) to reduce CQI data size while preserving essential features. These compressed states are used to train 6G-enabled Reinforcement Learning policies that maximize throughput while meeting fairness objectives defined by the NGMN. Simulations show that SCAR increases time in feasible scheduling regions by 14\% and reduces unfair scheduling time by 15\% compared to RL baselines without CQI compression. Furthermore, Simulated Annealing with Stochastic Tunneling (SAST)-based clustering reduces CQI clustering distortion by 10\%, confirming its efficiency. These results demonstrate SCAR's scalability and fairness benefits for dynamic vehicular networks.
HarmonE: A Self-Adaptive Approach to Architecting Sustainable MLOps
May 19, 2025



Machine Learning Enabled Systems (MLS) are becoming integral to real-world applications, but ensuring their sustainable performance over time remains a significant challenge. These systems operate in dynamic environments and face runtime uncertainties like data drift and model degradation, which affect the sustainability of MLS across multiple dimensions: technical, economical, environmental, and social. While Machine Learning Operations (MLOps) addresses the technical dimension by streamlining the ML model lifecycle, it overlooks other dimensions. Furthermore, some traditional practices, such as frequent retraining, incur substantial energy and computational overhead, thus amplifying sustainability concerns. To address them, we introduce HarmonE, an architectural approach that enables self-adaptive capabilities in MLOps pipelines using the MAPE-K loop. HarmonE allows system architects to define explicit sustainability goals and adaptation thresholds at design time, and performs runtime monitoring of key metrics, such as prediction accuracy, energy consumption, and data distribution shifts, to trigger appropriate adaptation strategies. We validate our approach using a Digital Twin (DT) of an Intelligent Transportation System (ITS), focusing on traffic flow prediction as our primary use case. The DT employs time series ML models to simulate real-time traffic and assess various flow scenarios. Our results show that HarmonE adapts effectively to evolving conditions while maintaining accuracy and meeting sustainability goals.
Small Models, Big Tasks: An Exploratory Empirical Study on Small Language Models for Function Calling
Apr 27, 2025Function calling is a complex task with widespread applications in domains such as information retrieval, software engineering and automation. For example, a query to book the shortest flight from New York to London on January 15 requires identifying the correct parameters to generate accurate function calls. Large Language Models (LLMs) can automate this process but are computationally expensive and impractical in resource-constrained settings. In contrast, Small Language Models (SLMs) can operate efficiently, offering faster response times, and lower computational demands, making them potential candidates for function calling on edge devices. In this exploratory empirical study, we evaluate the efficacy of SLMs in generating function calls across diverse domains using zero-shot, few-shot, and fine-tuning approaches, both with and without prompt injection, while also providing the finetuned models to facilitate future applications. Furthermore, we analyze the model responses across a range of metrics, capturing various aspects of function call generation. Additionally, we perform experiments on an edge device to evaluate their performance in terms of latency and memory usage, providing useful insights into their practical applicability. Our findings show that while SLMs improve from zero-shot to few-shot and perform best with fine-tuning, they struggle significantly with adhering to the given output format. Prompt injection experiments further indicate that the models are generally robust and exhibit only a slight decline in performance. While SLMs demonstrate potential for the function call generation task, our results also highlight areas that need further refinement for real-time functioning.
DRAFT-ing Architectural Design Decisions using LLMs
Apr 11, 2025



Architectural Knowledge Management (AKM) is crucial for software development but remains challenging due to the lack of standardization and high manual effort. Architecture Decision Records (ADRs) provide a structured approach to capture Architecture Design Decisions (ADDs), but their adoption is limited due to the manual effort involved and insufficient tool support. Our previous work has shown that Large Language Models (LLMs) can assist in generating ADDs. However, simply prompting the LLM does not produce quality ADDs. Moreover, using third-party LLMs raises privacy concerns, while self-hosting them poses resource challenges. To this end, we experimented with different approaches like few-shot, retrieval-augmented generation (RAG) and fine-tuning to enhance LLM's ability to generate ADDs. Our results show that both techniques improve effectiveness. Building on this, we propose Domain Specific Retreival Augumented Few Shot Fine Tuninng, DRAFT, which combines the strengths of all these three approaches for more effective ADD generation. DRAFT operates in two phases: an offline phase that fine-tunes an LLM on generating ADDs augmented with retrieved examples and an online phase that generates ADDs by leveraging retrieved ADRs and the fine-tuned model. We evaluated DRAFT against existing approaches on a dataset of 4,911 ADRs and various LLMs and analyzed them using automated metrics and human evaluations. Results show DRAFT outperforms all other approaches in effectiveness while maintaining efficiency. Our findings indicate that DRAFT can aid architects in drafting ADDs while addressing privacy and resource constraints.
Generative AI for Software Architecture. Applications, Trends, Challenges, and Future Directions
Mar 17, 2025



Context: Generative Artificial Intelligence (GenAI) is transforming much of software development, yet its application in software architecture is still in its infancy, and no prior study has systematically addressed the topic. Aim: We aim to systematically synthesize the use, rationale, contexts, usability, and future challenges of GenAI in software architecture. Method: We performed a multivocal literature review (MLR), analyzing peer-reviewed and gray literature, identifying current practices, models, adoption contexts, and reported challenges, extracting themes via open coding. Results: Our review identified significant adoption of GenAI for architectural decision support and architectural reconstruction. OpenAI GPT models are predominantly applied, and there is consistent use of techniques such as few-shot prompting and retrieved-augmented generation (RAG). GenAI has been applied mostly to initial stages of the Software Development Life Cycle (SDLC), such as Requirements-to-Architecture and Architecture-to-Code. Monolithic and microservice architectures were the dominant targets. However, rigorous testing of GenAI outputs was typically missing from the studies. Among the most frequent challenges are model precision, hallucinations, ethical aspects, privacy issues, lack of architecture-specific datasets, and the absence of sound evaluation frameworks. Conclusions: GenAI shows significant potential in software design, but several challenges remain on its path to greater adoption. Research efforts should target designing general evaluation methodologies, handling ethics and precision, increasing transparency and explainability, and promoting architecture-specific datasets and benchmarks to bridge the gap between theoretical possibilities and practical use.