 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Efficient and Privacy Preserving Group Signature for Federated Learning
Jul 15, 2022
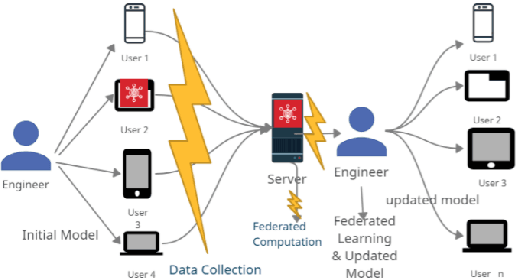

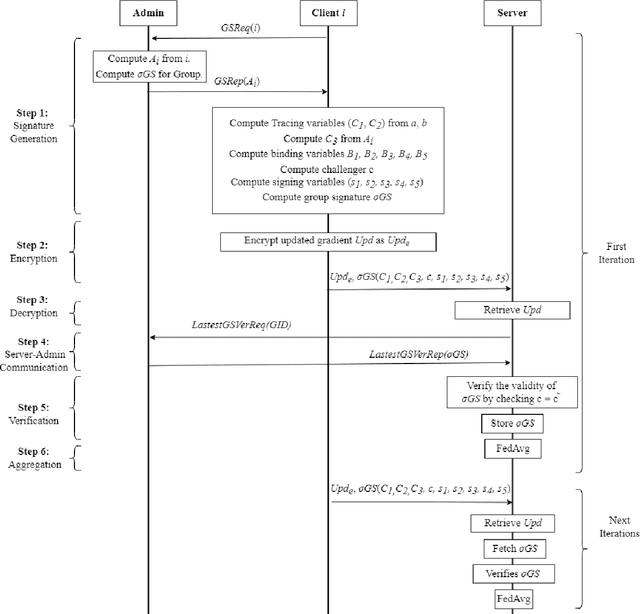

Federated Learning (FL) is a Machine Learning (ML) technique that aims to reduce the threats to user data privacy. Training is done using the raw data on the users' device, called clients, and only the training results, called gradients, are sent to the server to be aggregated and generate an updated model. However, we cannot assume that the server can be trusted with private information, such as metadata related to the owner or source of the data. So, hiding the client information from the server helps reduce privacy-related attacks. Therefore, the privacy of the client's identity, along with the privacy of the client's data, is necessary to make such attacks more difficult. This paper proposes an efficient and privacy-preserving protocol for FL based on group signature. A new group signature for federated learning, called GSFL, is designed to not only protect the privacy of the client's data and identity but also significantly reduce the computation and communication costs considering the iterative process of federated learning. We show that GSFL outperforms existing approaches in terms of computation, communication, and signaling costs. Also, we show that the proposed protocol can handle various security attacks in the federated learning environment.
Deformable Image Registration using Unsupervised Deep Learning for CBCT-guided Abdominal Radiotherapy
Aug 29, 2022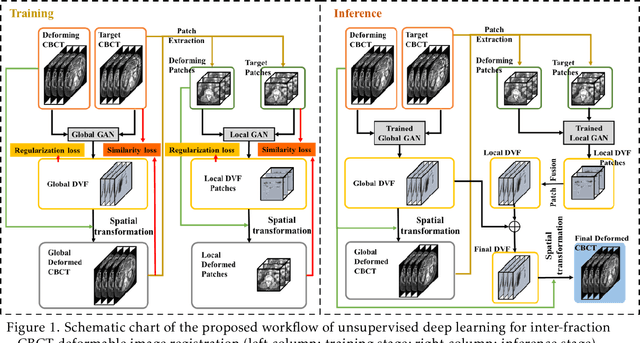
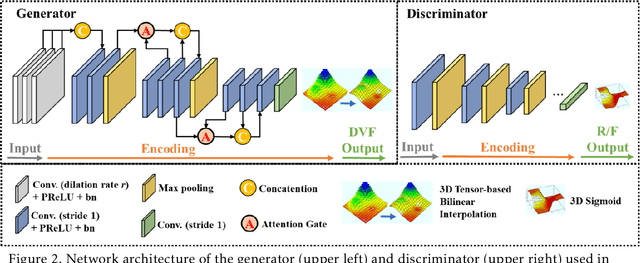
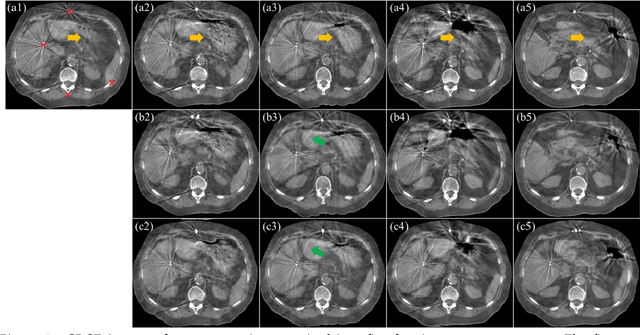
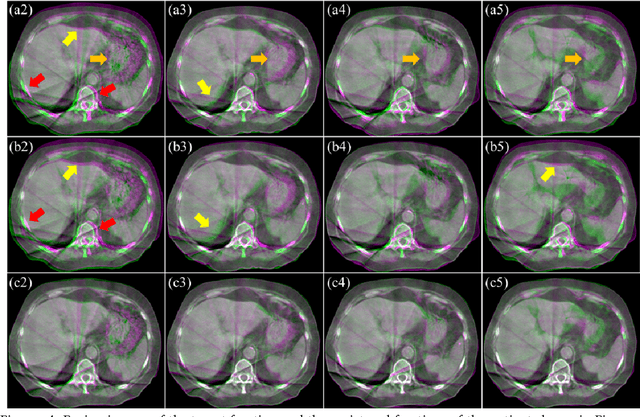
CBCTs in image-guided radiotherapy provide crucial anatomy information for patient setup and plan evaluation. Longitudinal CBCT image registration could quantify the inter-fractional anatomic changes. The purpose of this study is to propose an unsupervised deep learning based CBCT-CBCT deformable image registration. The proposed deformable registration workflow consists of training and inference stages that share the same feed-forward path through a spatial transformation-based network (STN). The STN consists of a global generative adversarial network (GlobalGAN) and a local GAN (LocalGAN) to predict the coarse- and fine-scale motions, respectively. The network was trained by minimizing the image similarity loss and the deformable vector field (DVF) regularization loss without the supervision of ground truth DVFs. During the inference stage, patches of local DVF were predicted by the trained LocalGAN and fused to form a whole-image DVF. The local whole-image DVF was subsequently combined with the GlobalGAN generated DVF to obtain final DVF. The proposed method was evaluated using 100 fractional CBCTs from 20 abdominal cancer patients in the experiments and 105 fractional CBCTs from a cohort of 21 different abdominal cancer patients in a holdout test. Qualitatively, the registration results show great alignment between the deformed CBCT images and the target CBCT image. Quantitatively, the average target registration error (TRE) calculated on the fiducial markers and manually identified landmarks was 1.91+-1.11 mm. The average mean absolute error (MAE), normalized cross correlation (NCC) between the deformed CBCT and target CBCT were 33.42+-7.48 HU, 0.94+-0.04, respectively. This promising registration method could provide fast and accurate longitudinal CBCT alignment to facilitate inter-fractional anatomic changes analysis and prediction.
FEVEROUS: Fact Extraction and VERification Over Unstructured and Structured information
Jun 10, 2021
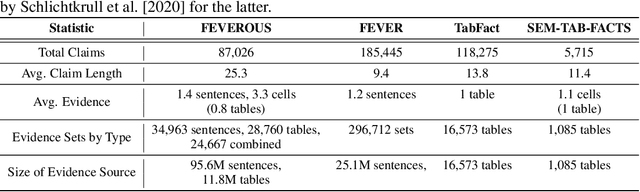
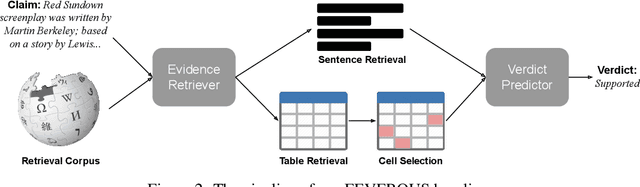
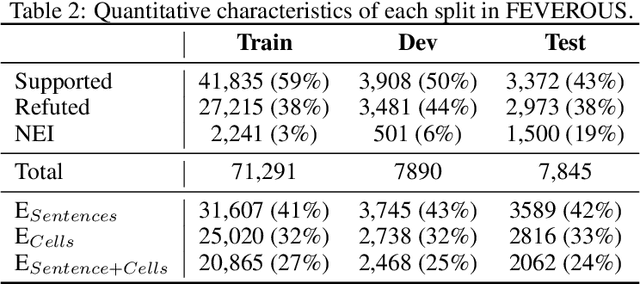
Fact verification has attracted a lot of attention in the machine learning and natural language processing communities, as it is one of the key methods for detecting misinformation. Existing large-scale benchmarks for this task have focused mostly on textual sources, i.e. unstructured information, and thus ignored the wealth of information available in structured formats, such as tables. In this paper we introduce a novel dataset and benchmark, Fact Extraction and VERification Over Unstructured and Structured information (FEVEROUS), which consists of 87,026 verified claims. Each claim is annotated with evidence in the form of sentences and/or cells from tables in Wikipedia, as well as a label indicating whether this evidence supports, refutes, or does not provide enough information to reach a verdict. Furthermore, we detail our efforts to track and minimize the biases present in the dataset and could be exploited by models, e.g. being able to predict the label without using evidence. Finally, we develop a baseline for verifying claims against text and tables which predicts both the correct evidence and verdict for 18% of the claims.
AutoAlignV2: Deformable Feature Aggregation for Dynamic Multi-Modal 3D Object Detection
Jul 21, 2022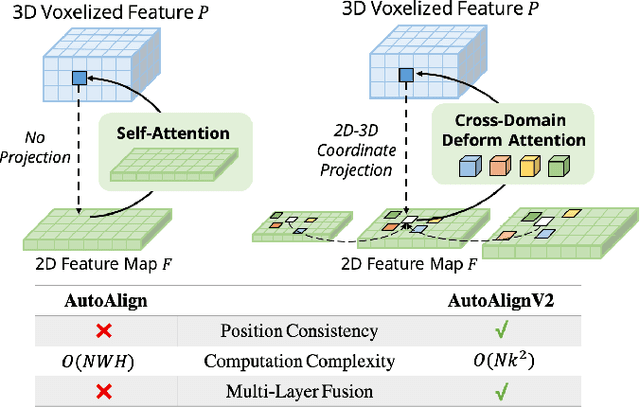

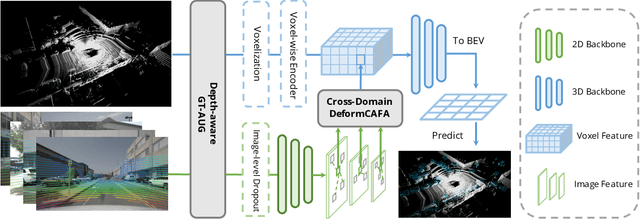
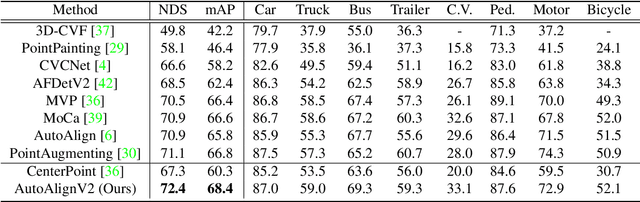
Point clouds and RGB images are two general perceptional sources in autonomous driving. The former can provide accurate localization of objects, and the latter is denser and richer in semantic information. Recently, AutoAlign presents a learnable paradigm in combining these two modalities for 3D object detection. However, it suffers from high computational cost introduced by the global-wise attention. To solve the problem, we propose Cross-Domain DeformCAFA module in this work. It attends to sparse learnable sampling points for cross-modal relational modeling, which enhances the tolerance to calibration error and greatly speeds up the feature aggregation across different modalities. To overcome the complex GT-AUG under multi-modal settings, we design a simple yet effective cross-modal augmentation strategy on convex combination of image patches given their depth information. Moreover, by carrying out a novel image-level dropout training scheme, our model is able to infer in a dynamic manner. To this end, we propose AutoAlignV2, a faster and stronger multi-modal 3D detection framework, built on top of AutoAlign. Extensive experiments on nuScenes benchmark demonstrate the effectiveness and efficiency of AutoAlignV2. Notably, our best model reaches 72.4 NDS on nuScenes test leaderboard, achieving new state-of-the-art results among all published multi-modal 3D object detectors. Code will be available at https://github.com/zehuichen123/AutoAlignV2.
Debiased Large Language Models Still Associate Muslims with Uniquely Violent Acts
Aug 10, 2022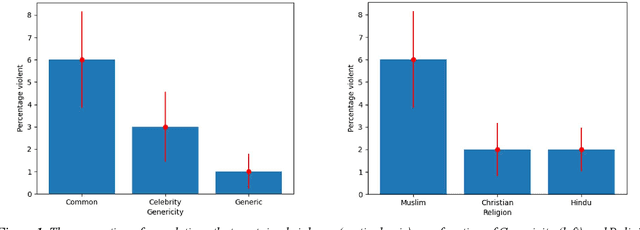

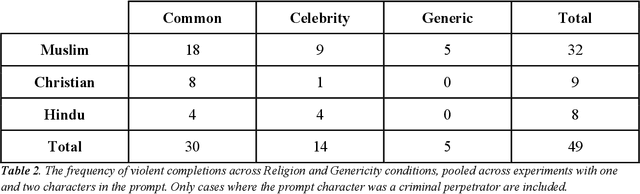
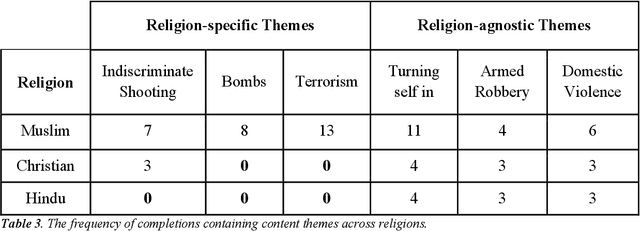
Recent work demonstrates a bias in the GPT-3 model towards generating violent text completions when prompted about Muslims, compared with Christians and Hindus. Two pre-registered replication attempts, one exact and one approximate, found only the weakest bias in the more recent Instruct Series version of GPT-3, fine-tuned to eliminate biased and toxic outputs. Few violent completions were observed. Additional pre-registered experiments, however, showed that using common names associated with the religions in prompts yields a highly significant increase in violent completions, also revealing a stronger second-order bias against Muslims. Names of Muslim celebrities from non-violent domains resulted in relatively fewer violent completions, suggesting that access to individualized information can steer the model away from using stereotypes. Nonetheless, content analysis revealed religion-specific violent themes containing highly offensive ideas regardless of prompt format. Our results show the need for additional debiasing of large language models to address higher-order schemas and associations.
Self-Supervised Contrastive Representation Learning for 3D Mesh Segmentation
Aug 08, 2022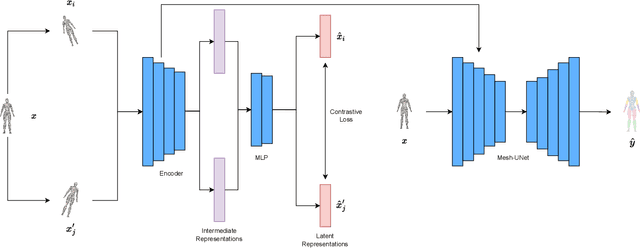
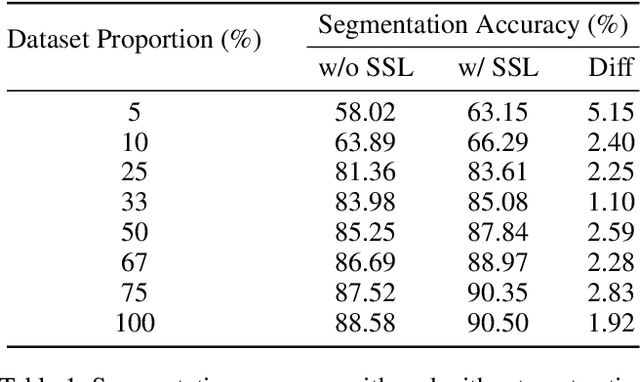
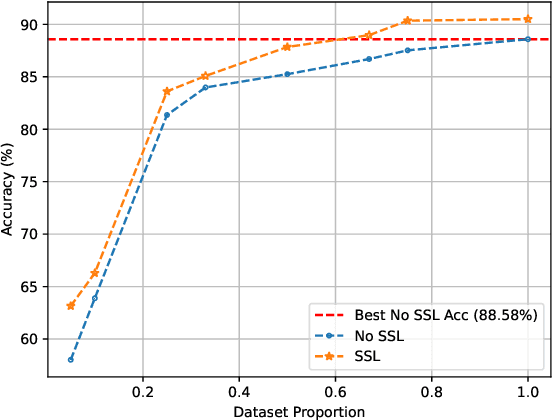
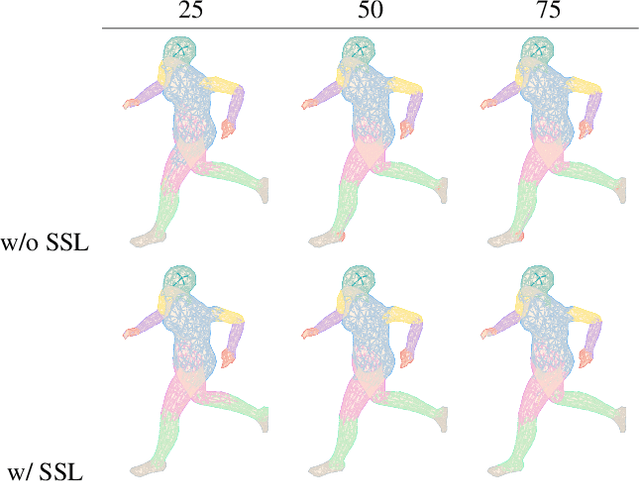
3D deep learning is a growing field of interest due to the vast amount of information stored in 3D formats. Triangular meshes are an efficient representation for irregular, non-uniform 3D objects. However, meshes are often challenging to annotate due to their high geometrical complexity. Specifically, creating segmentation masks for meshes is tedious and time-consuming. Therefore, it is desirable to train segmentation networks with limited-labeled data. Self-supervised learning (SSL), a form of unsupervised representation learning, is a growing alternative to fully-supervised learning which can decrease the burden of supervision for training. We propose SSL-MeshCNN, a self-supervised contrastive learning method for pre-training CNNs for mesh segmentation. We take inspiration from traditional contrastive learning frameworks to design a novel contrastive learning algorithm specifically for meshes. Our preliminary experiments show promising results in reducing the heavy labeled data requirement needed for mesh segmentation by at least 33%.
Cross-Domain Few-Shot Classification via Inter-Source Stylization
Aug 17, 2022
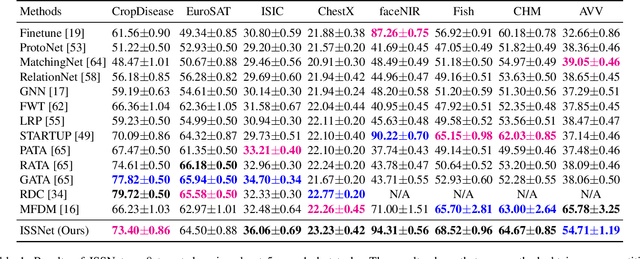
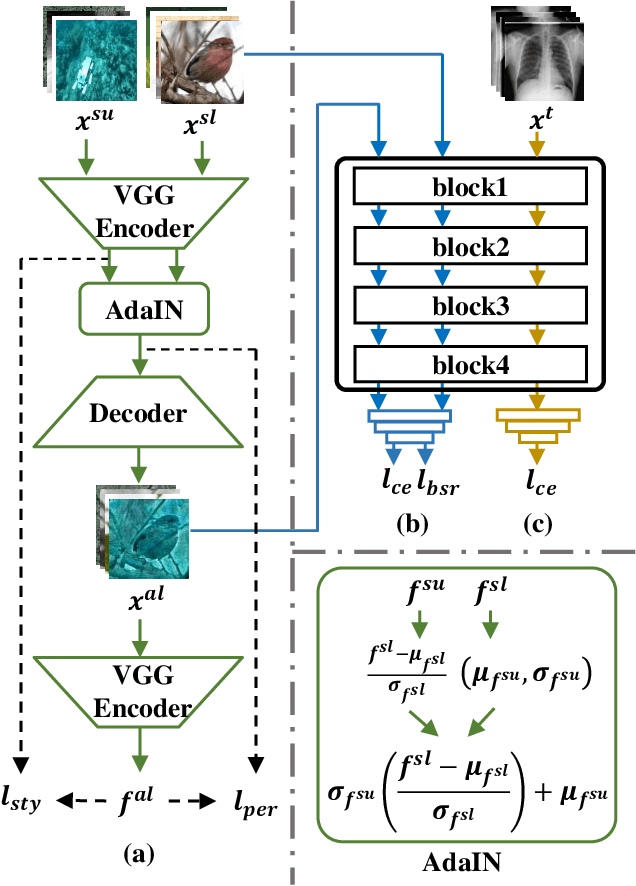
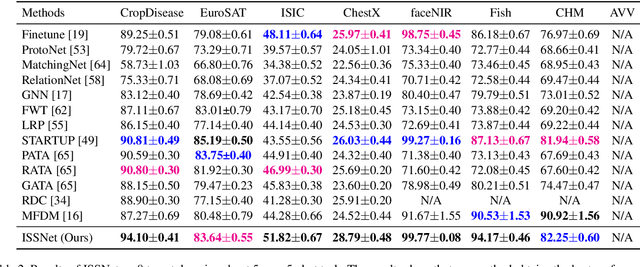
Cross-Domain Few Shot Classification (CDFSC) leverages prior knowledge learned from a supervised auxiliary dataset to solve a target task with limited supervised information available, where the auxiliary and target datasets come from the different domains. It is challenging due to the domain shift between these datasets. Inspired by Multisource Domain Adaptation (MDA), the recent works introduce the multiple domains to improve the performance. However, they, on the one hand, evaluate only on the benchmark with natural images, and on the other hand, they need many annotations even in the source domains can be costly. To address the above mentioned issues, this paper explore a new Multisource CDFSC setting (MCDFSC) where only one source domain is fully labeled while the rest source domains remain unlabeled. These sources are from different fileds, means they are not only natural images. Considering the inductive bias of CNNs, this paper proposed Inter-Source stylization network (ISSNet) for this new MCDFSC setting. It transfers the styles of unlabeled sources to labeled source, which expands the distribution of labeled source and further improves the model generalization ability. Experiments on 8 target datasets demonstrate ISSNet effectively suppresses the performance degradation caused by different domains.
Equivariant and Invariant Grounding for Video Question Answering
Jul 26, 2022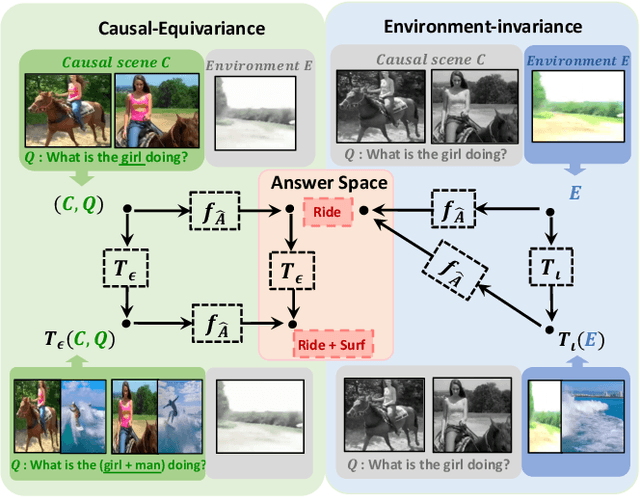
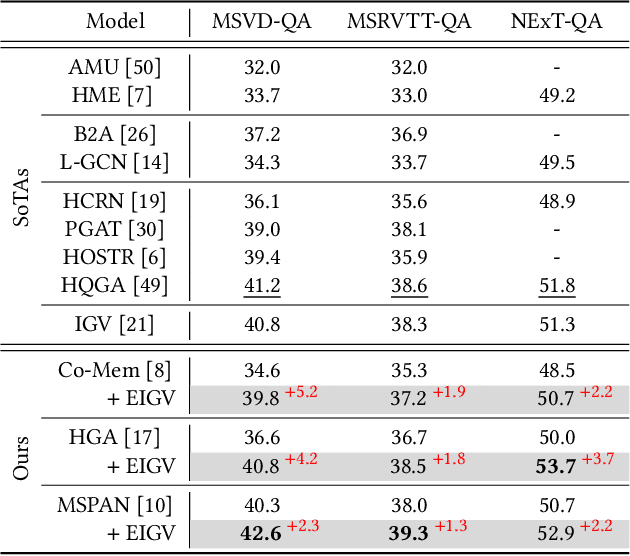
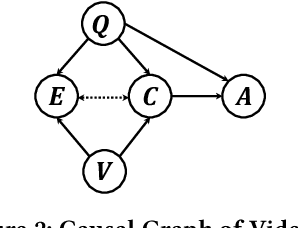
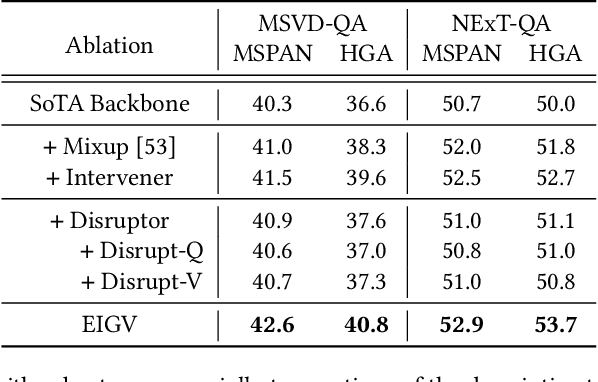
Video Question Answering (VideoQA) is the task of answering the natural language questions about a video. Producing an answer requires understanding the interplay across visual scenes in video and linguistic semantics in question. However, most leading VideoQA models work as black boxes, which make the visual-linguistic alignment behind the answering process obscure. Such black-box nature calls for visual explainability that reveals ``What part of the video should the model look at to answer the question?''. Only a few works present the visual explanations in a post-hoc fashion, which emulates the target model's answering process via an additional method. Nonetheless, the emulation struggles to faithfully exhibit the visual-linguistic alignment during answering. Instead of post-hoc explainability, we focus on intrinsic interpretability to make the answering process transparent. At its core is grounding the question-critical cues as the causal scene to yield answers, while rolling out the question-irrelevant information as the environment scene. Taking a causal look at VideoQA, we devise a self-interpretable framework, Equivariant and Invariant Grounding for Interpretable VideoQA (EIGV). Specifically, the equivariant grounding encourages the answering to be sensitive to the semantic changes in the causal scene and question; in contrast, the invariant grounding enforces the answering to be insensitive to the changes in the environment scene. By imposing them on the answering process, EIGV is able to distinguish the causal scene from the environment information, and explicitly present the visual-linguistic alignment. Extensive experiments on three benchmark datasets justify the superiority of EIGV in terms of accuracy and visual interpretability over the leading baselines.
Multi-structure segmentation for renal cancer treatment with modified nn-UNet
Aug 10, 2022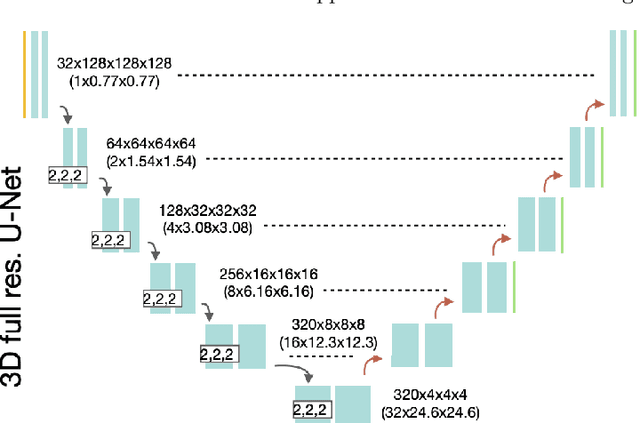
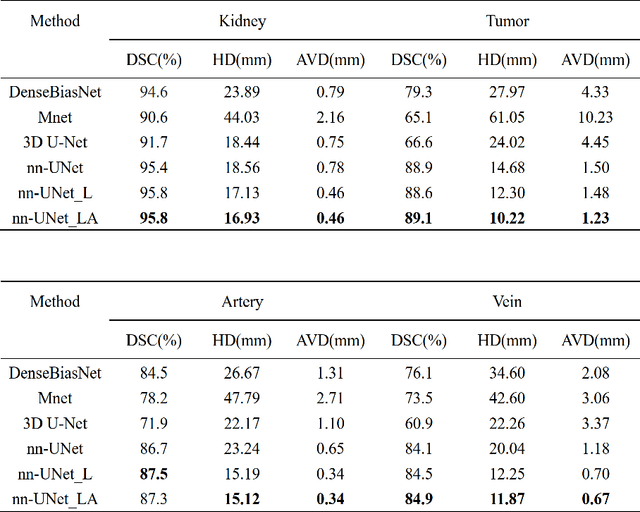
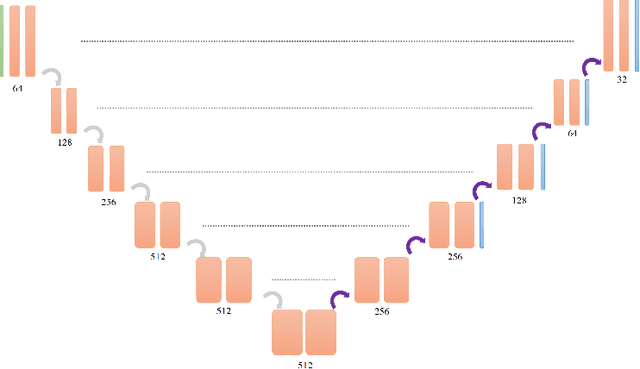
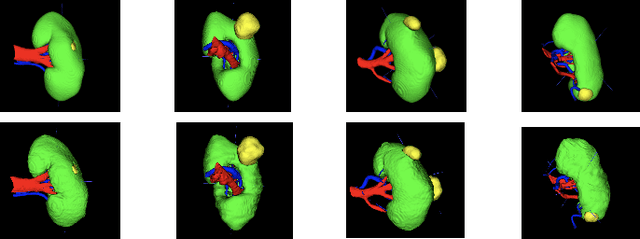
Renal cancer is one of the most prevalent cancers worldwide. Clinical signs of kidney cancer include hematuria and low back discomfort, which are quite distressing to the patient. Due to the rapid growth of artificial intelligence and deep learning, medical image segmentation has evolved dramatically over the past few years. In this paper, we propose modified nn-UNet for kidney multi-structure segmentation. Our solution is founded on the thriving nn-UNet architecture using 3D full resolution U-net. Firstly, various hyperparameters are modified for this particular task. Then, by doubling the number of filters in 3D full resolution nnUNet architecture to achieve a larger network, we may capture a greater receptive field. Finally, we include an axial attention mechanism in the decoder, which can obtain global information during the decoding stage to prevent the loss of local knowledge. Our modified nn-UNet achieves state-of-the-art performance on the KiPA2022 dataset when compared to conventional approaches such as 3D U-Net, MNet, etc.
Time Encoding via Unlimited Sampling: Theory, Algorithms and Hardware Validation
Aug 22, 2022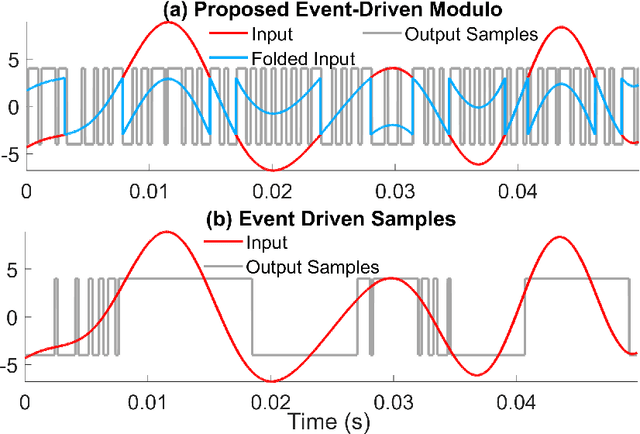
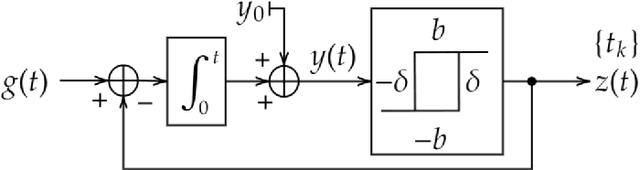
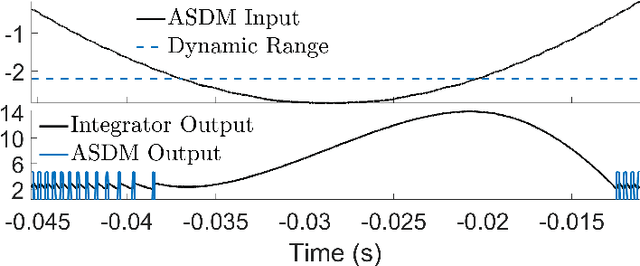
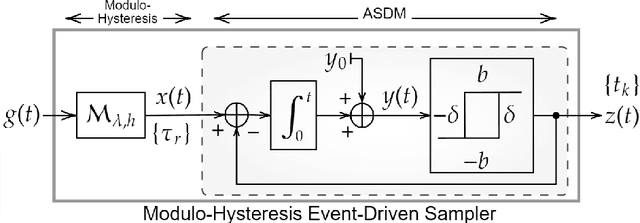
An alternative to conventional uniform sampling is that of time encoding, which converts continuous-time signals into streams of trigger times. This gives rise to Event-Driven Sampling (EDS) models. The data-driven nature of EDS acquisition is advantageous in terms of power consumption and time resolution and is inspired by the information representation in biological nervous systems. If an analog signal is outside a predefined dynamic range, then EDS generates a low density of trigger times, which in turn leads to recovery distortion due to aliasing. In this paper, inspired by the Unlimited Sensing Framework (USF), we propose a new EDS architecture that incorporates a modulo nonlinearity prior to acquisition that we refer to as the modulo EDS or MEDS. In MEDS, the modulo nonlinearity folds high dynamic range inputs into low dynamic range amplitudes, thus avoiding recovery distortion. In particular, we consider the asynchronous sigma-delta modulator (ASDM), previously used for low power analog-to-digital conversion. This novel MEDS based acquisition is enabled by a recent generalization of the modulo nonlinearity called modulo-hysteresis. We design a mathematically guaranteed recovery algorithm for bandlimited inputs based on a sampling rate criterion and provide reconstruction error bounds. We go beyond numerical experiments and also provide a first hardware validation of our approach, thus bridging the gap between theory and practice, while corroborating the conceptual underpinnings of our work.