 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge4DGS360: 360° Gaussian Reconstruction of Dynamic Objects from a Single Video
Mar 23, 2026We introduce 4DGS360, a diffusion-free framework for 360$^{\circ}$ dynamic object reconstruction from casual monocular video. Existing methods often fail to reconstruct consistent 360$^{\circ}$ geometry, as their heavy reliance on 2D-native priors causes initial points to overfit to visible surface in each training view. 4DGS360 addresses this challenge through a advanced 3D-native initialization that mitigates the geometric ambiguity of occluded regions. Our proposed 3D tracker, AnchorTAP3D, produces reinforced 3D point trajectories by leveraging confident 2D track points as anchors, suppressing drift and providing reliable initialization that preserves geometry in occluded regions. This initialization, combined with optimization, yields coherent 360$^{\circ}$ 4D reconstructions. We further present iPhone360, a new benchmark where test cameras are placed up to 135$^{\circ}$ apart from training views, enabling 360$^{\circ}$ evaluation that existing datasets cannot provide. Experiments show that 4DGS360 achieves state-of-the-art performance on the iPhone360, iPhone, and DAVIS datasets, both qualitatively and quantitatively.
DivCon-NeRF: Generating Augmented Rays with Diversity and Consistency for Few-shot View Synthesis
Mar 17, 2025



Neural Radiance Field (NeRF) has shown remarkable performance in novel view synthesis but requires many multiview images, making it impractical for few-shot scenarios. Ray augmentation was proposed to prevent overfitting for sparse training data by generating additional rays. However, existing methods, which generate augmented rays only near the original rays, produce severe floaters and appearance distortion due to limited viewpoints and inconsistent rays obstructed by nearby obstacles and complex surfaces. To address these problems, we propose DivCon-NeRF, which significantly enhances both diversity and consistency. It employs surface-sphere augmentation, which preserves the distance between the original camera and the predicted surface point. This allows the model to compare the order of high-probability surface points and filter out inconsistent rays easily without requiring the exact depth. By introducing inner-sphere augmentation, DivCon-NeRF randomizes angles and distances for diverse viewpoints, further increasing diversity. Consequently, our method significantly reduces floaters and visual distortions, achieving state-of-the-art performance on the Blender, LLFF, and DTU datasets. Our code will be publicly available.
Efficient and Privacy Preserving Group Signature for Federated Learning
Jul 15, 2022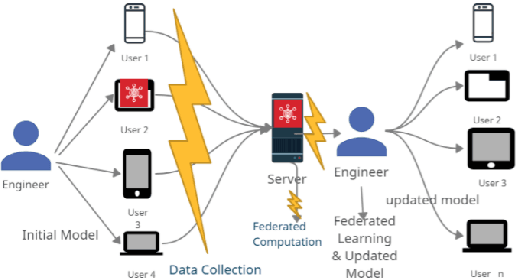

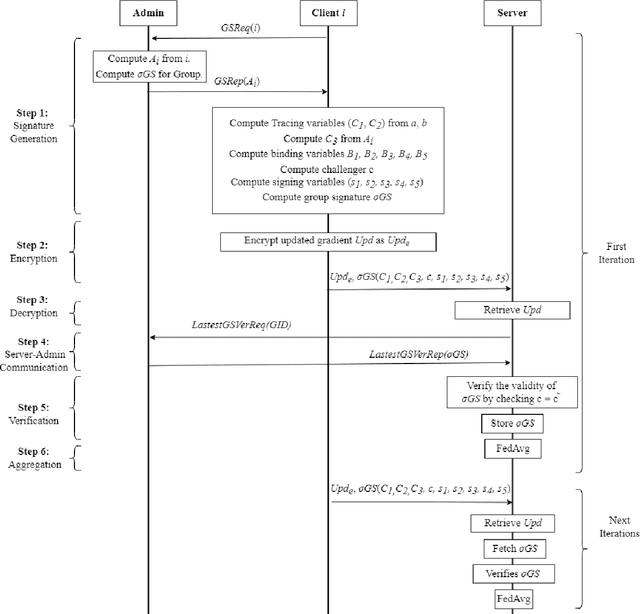

Federated Learning (FL) is a Machine Learning (ML) technique that aims to reduce the threats to user data privacy. Training is done using the raw data on the users' device, called clients, and only the training results, called gradients, are sent to the server to be aggregated and generate an updated model. However, we cannot assume that the server can be trusted with private information, such as metadata related to the owner or source of the data. So, hiding the client information from the server helps reduce privacy-related attacks. Therefore, the privacy of the client's identity, along with the privacy of the client's data, is necessary to make such attacks more difficult. This paper proposes an efficient and privacy-preserving protocol for FL based on group signature. A new group signature for federated learning, called GSFL, is designed to not only protect the privacy of the client's data and identity but also significantly reduce the computation and communication costs considering the iterative process of federated learning. We show that GSFL outperforms existing approaches in terms of computation, communication, and signaling costs. Also, we show that the proposed protocol can handle various security attacks in the federated learning environment.