 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Conditional Contrastive Learning: Removing Undesirable Information in Self-Supervised Representations
Jun 05, 2021
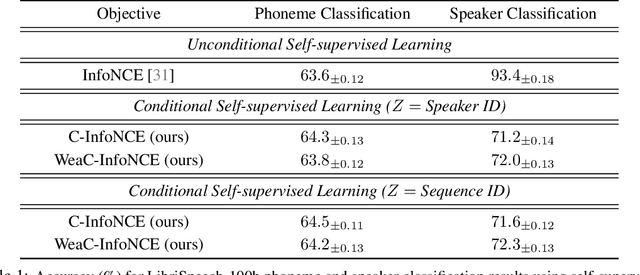
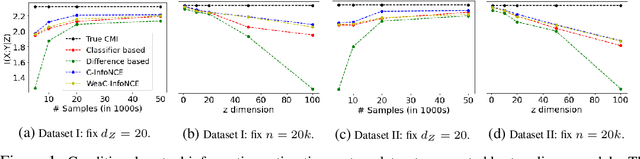
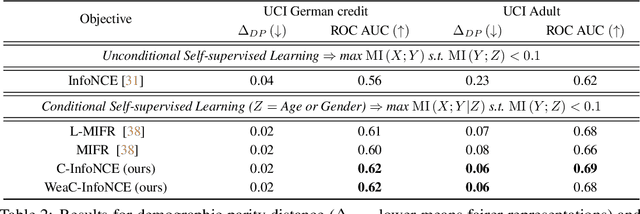
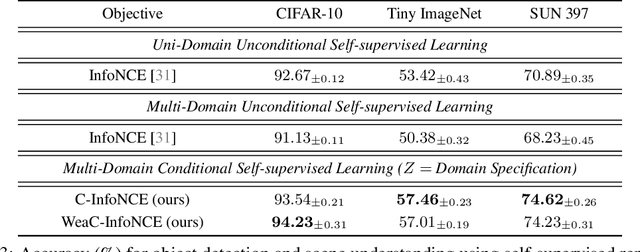
Self-supervised learning is a form of unsupervised learning that leverages rich information in data to learn representations. However, data sometimes contains certain information that may be undesirable for downstream tasks. For instance, gender information may lead to biased decisions on many gender-irrelevant tasks. In this paper, we develop conditional contrastive learning to remove undesirable information in self-supervised representations. To remove the effect of the undesirable variable, our proposed approach conditions on the undesirable variable (i.e., by fixing the variations of it) during the contrastive learning process. In particular, inspired by the contrastive objective InfoNCE, we introduce Conditional InfoNCE (C-InfoNCE), and its computationally efficient variant, Weak-Conditional InfoNCE (WeaC-InfoNCE), for conditional contrastive learning. We demonstrate empirically that our methods can successfully learn self-supervised representations for downstream tasks while removing a great level of information related to the undesirable variables. We study three scenarios, each with a different type of undesirable variables: task-irrelevant meta-information for self-supervised speech representation learning, sensitive attributes for fair representation learning, and domain specification for multi-domain visual representation learning.
FaVIQ: FAct Verification from Information-seeking Questions
Jul 05, 2021
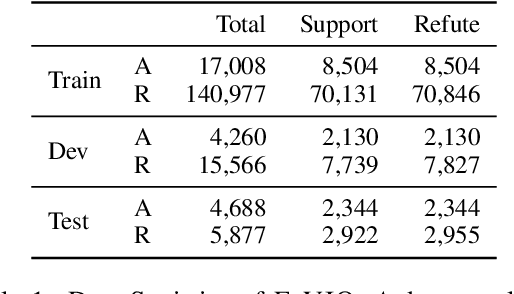
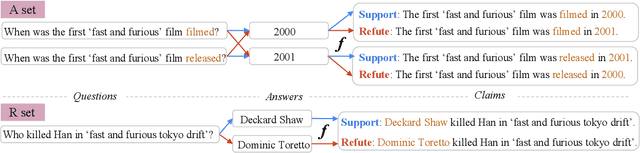
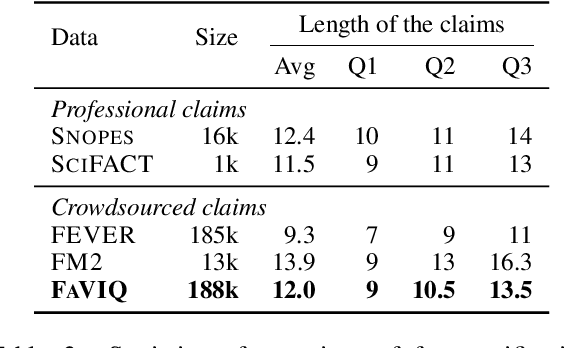
Despite significant interest in developing general purpose fact checking models, it is challenging to construct a large-scale fact verification dataset with realistic claims that would occur in the real world. Existing claims are either authored by crowdworkers, thereby introducing subtle biases that are difficult to control for, or manually verified by professional fact checkers, causing them to be expensive and limited in scale. In this paper, we construct a challenging, realistic, and large-scale fact verification dataset called FaVIQ, using information-seeking questions posed by real users who do not know how to answer. The ambiguity in information-seeking questions enables automatically constructing true and false claims that reflect confusions arisen from users (e.g., the year of the movie being filmed vs. being released). Our claims are verified to be natural, contain little lexical bias, and require a complete understanding of the evidence for verification. Our experiments show that the state-of-the-art models are far from solving our new task. Moreover, training on our data helps in professional fact-checking, outperforming models trained on the most widely used dataset FEVER or in-domain data by up to 17% absolute. Altogether, our data will serve as a challenging benchmark for natural language understanding and support future progress in professional fact checking.
CAEN: A Hierarchically Attentive Evolution Network for Item-Attribute-Change-Aware Recommendation in the Growing E-commerce Environment
Aug 29, 2022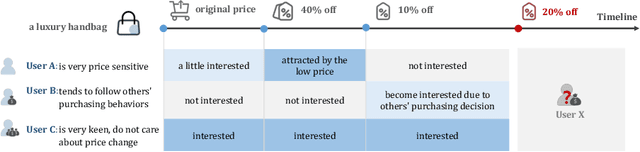

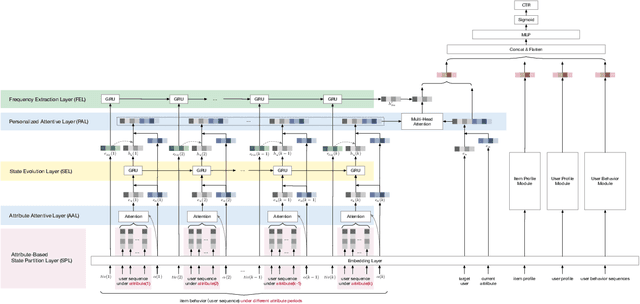
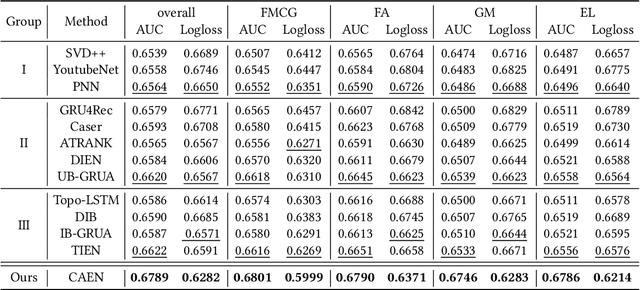
Traditional recommendation systems mainly focus on modeling user interests. However, the dynamics of recommended items caused by attribute modifications (e.g. changes in prices) are also of great importance in real systems, especially in the fast-growing e-commerce environment, which may cause the users' demands to emerge, shift and disappear. Recent studies that make efforts on dynamic item representations treat the item attributes as side information but ignore its temporal dependency, or model the item evolution with a sequence of related users but do not consider item attributes. In this paper, we propose Core Attribute Evolution Network (CAEN), which partitions the user sequence according to the attribute value and thus models the item evolution over attribute dynamics with these users. Under this framework, we further devise a hierarchical attention mechanism that applies attribute-aware attention for user aggregation under each attribute, as well as personalized attention for activating similar users in assessing the matching degree between target user and item. Results from the extensive experiments over actual e-commerce datasets show that our approach outperforms the state-of-art methods and achieves significant improvements on the items with rapid changes over attributes, therefore helping the item recommendation to adapt to the growth of the e-commerce platform.
Learning Personalized Representations using Graph Convolutional Network
Jul 28, 2022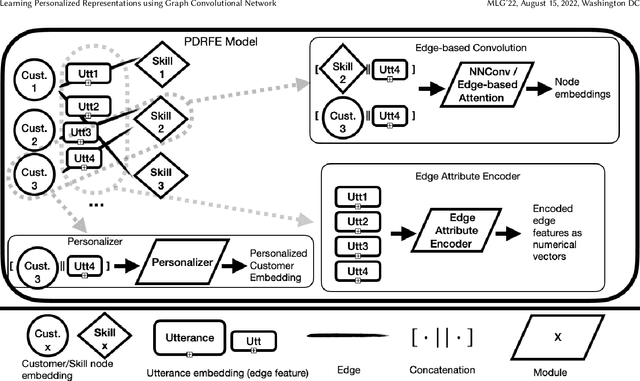

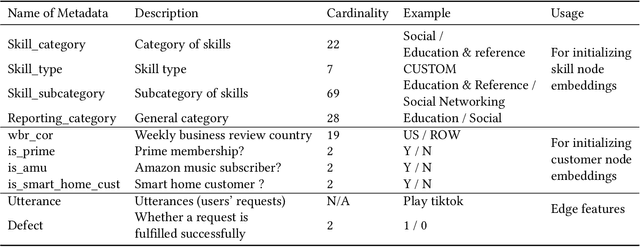
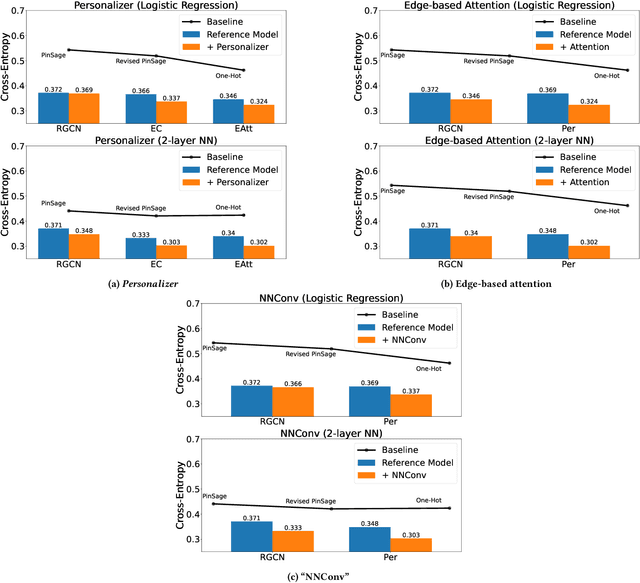
Generating representations that precisely reflect customers' behavior is an important task for providing personalized skill routing experience in Alexa. Currently, Dynamic Routing (DR) team, which is responsible for routing Alexa traffic to providers or skills, relies on two features to be served as personal signals: absolute traffic count and normalized traffic count of every skill usage per customer. Neither of them considers the network based structure for interactions between customers and skills, which contain richer information for customer preferences. In this work, we first build a heterogeneous edge attributed graph based customers' past interactions with the invoked skills, in which the user requests (utterances) are modeled as edges. Then we propose a graph convolutional network(GCN) based model, namely Personalized Dynamic Routing Feature Encoder(PDRFE), that generates personalized customer representations learned from the built graph. Compared with existing models, PDRFE is able to further capture contextual information in the graph convolutional function. The performance of our proposed model is evaluated by a downstream task, defect prediction, that predicts the defect label from the learned embeddings of customers and their triggered skills. We observe up to 41% improvements on the cross entropy metric for our proposed models compared to the baselines.
Neural Embedding: Learning the Embedding of the Manifold of Physics Data
Aug 14, 2022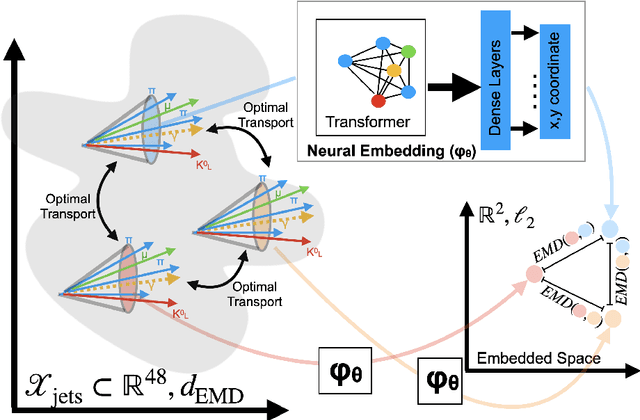
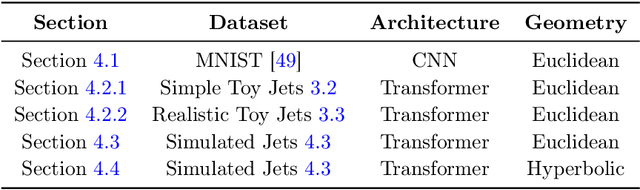
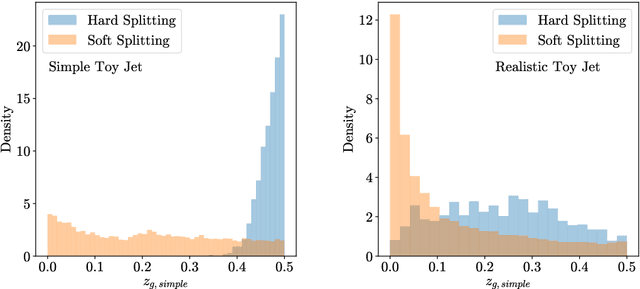

In this paper, we present a method of embedding physics data manifolds with metric structure into lower dimensional spaces with simpler metrics, such as Euclidean and Hyperbolic spaces. We then demonstrate that it can be a powerful step in the data analysis pipeline for many applications. Using progressively more realistic simulated collisions at the Large Hadron Collider, we show that this embedding approach learns the underlying latent structure. With the notion of volume in Euclidean spaces, we provide for the first time a viable solution to quantifying the true search capability of model agnostic search algorithms in collider physics (i.e. anomaly detection). Finally, we discuss how the ideas presented in this paper can be employed to solve many practical challenges that require the extraction of physically meaningful representations from information in complex high dimensional datasets.
Fast Re-Optimization of LeadingOnes with Frequent Changes
Sep 09, 2022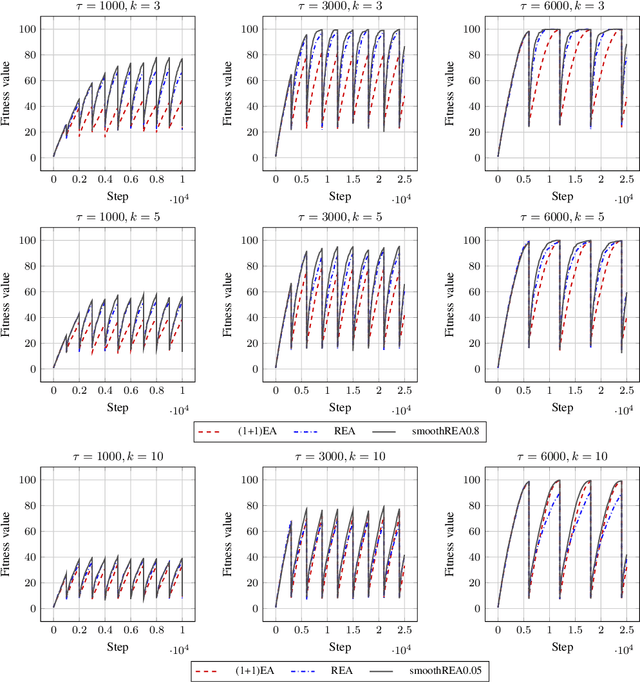
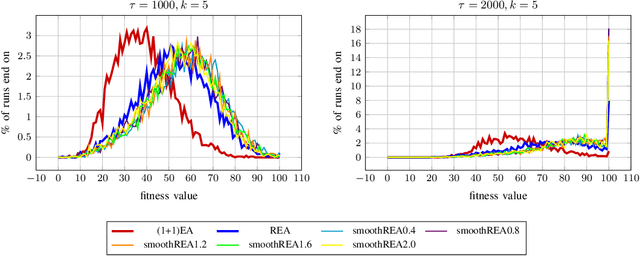
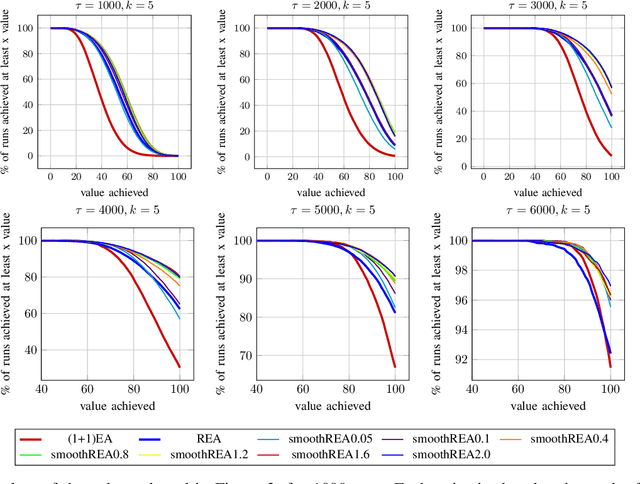
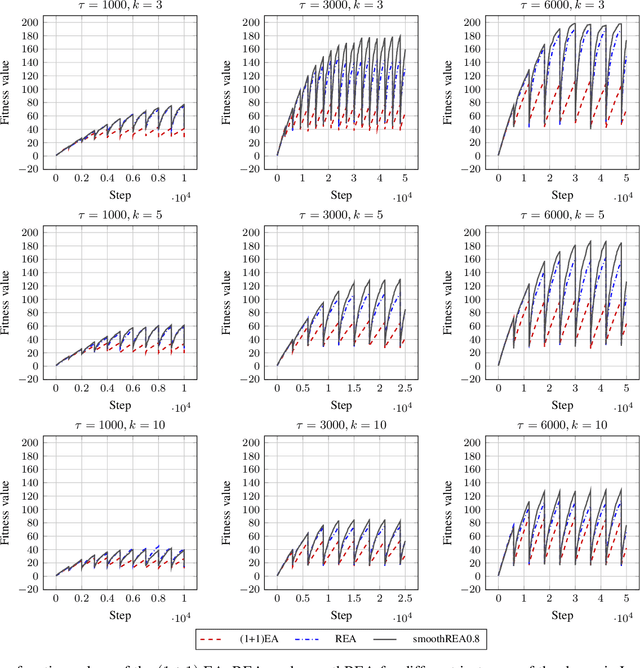
In real-world optimization scenarios, the problem instance that we are asked to solve may change during the optimization process, e.g., when new information becomes available or when the environmental conditions change. In such situations, one could hope to achieve reasonable performance by continuing the search from the best solution found for the original problem. Likewise, one may hope that when solving several problem instances that are similar to each other, it can be beneficial to ``warm-start'' the optimization process of the second instance by the best solution found for the first. However, it was shown in [Doerr et al., GECCO 2019] that even when initialized with structurally good solutions, evolutionary algorithms can have a tendency to replace these good solutions by structurally worse ones, resulting in optimization times that have no advantage over the same algorithms started from scratch. Doerr et al. also proposed a diversity mechanism to overcome this problem. Their approach balances greedy search around a best-so-far solution for the current problem with search in the neighborhood around the best-found solution for the previous instance. In this work, we first show that the re-optimization approach suggested by Doerr et al. reaches a limit when the problem instances are prone to more frequent changes. More precisely, we show that they get stuck on the dynamic LeadingOnes problem in which the target string changes periodically. We then propose a modification of their algorithm which interpolates between greedy search around the previous-best and the current-best solution. We empirically evaluate our smoothed re-optimization algorithm on LeadingOnes instances with various frequencies of change and with different perturbation factors and show that it outperforms both a fully restarted (1+1) Evolutionary Algorithm and the re-optimization approach by Doerr et al.
Intention-Conditioned Long-Term Human Egocentric Action Forecasting @ EGO4D Challenge 2022
Jul 25, 2022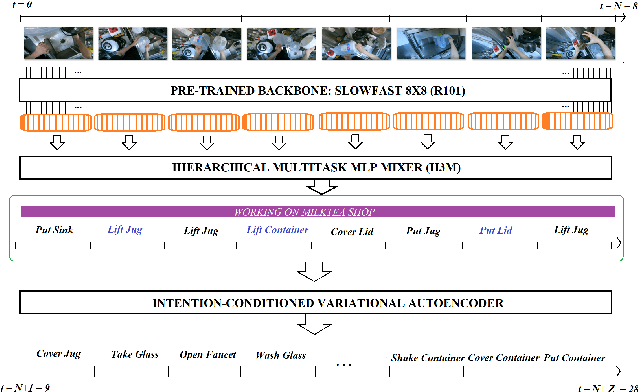
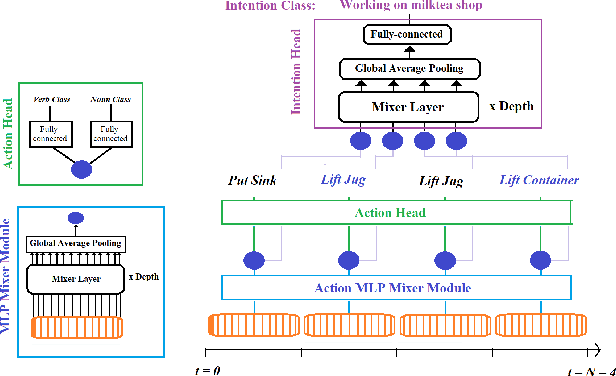
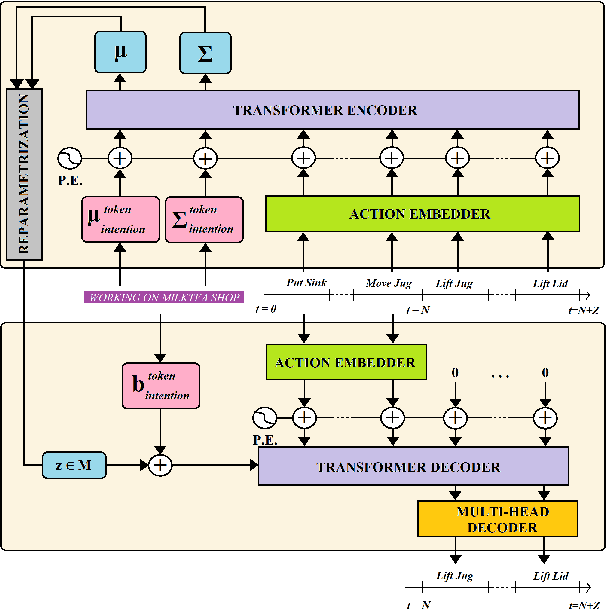
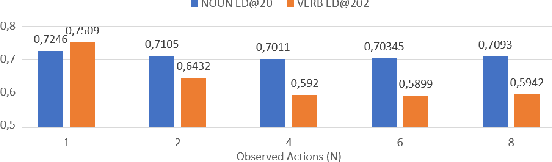
To anticipate how a human would act in the future, it is essential to understand the human intention since it guides the human towards a certain goal. In this paper, we propose a hierarchical architecture which assumes a sequence of human action (low-level) can be driven from the human intention (high-level). Based on this, we deal with Long-Term Action Anticipation task in egocentric videos. Our framework first extracts two level of human information over the N observed videos human actions through a Hierarchical Multi-task MLP Mixer (H3M). Then, we condition the uncertainty of the future through an Intention-Conditioned Variational Auto-Encoder (I-CVAE) that generates K stable predictions of the next Z=20 actions that the observed human might perform. By leveraging human intention as high-level information, we claim that our model is able to anticipate more time-consistent actions in the long-term, thus improving the results over baseline methods in EGO4D Challenge. This work ranked first in the EGO4D LTA Challenge by providing more plausible anticipated sequences, improving the anticipation of nouns and overall actions. The code is available at https://github.com/Evm7/ego4dlta-icvae.
Cohort comfort models -- Using occupants' similarity to predict personal thermal preference with less data
Aug 05, 2022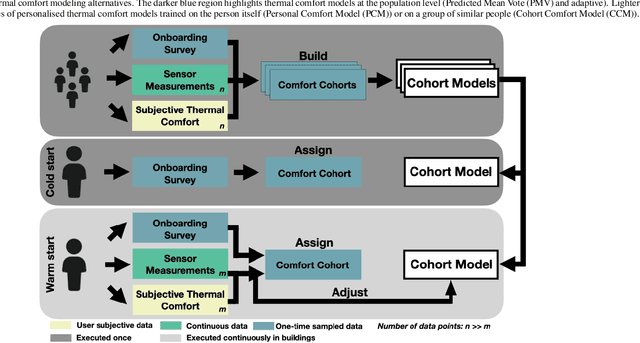
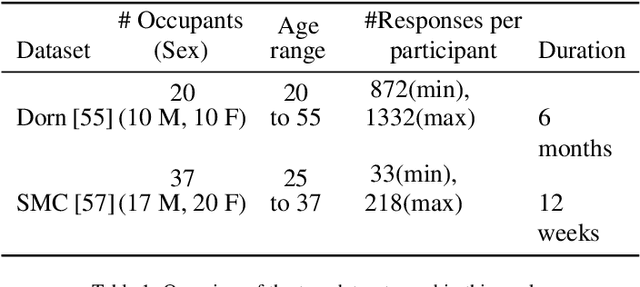
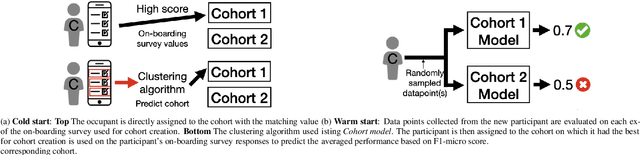

We introduce Cohort Comfort Models, a new framework for predicting how new occupants would perceive their thermal environment. Cohort Comfort Models leverage historical data collected from a sample population, who have some underlying preference similarity, to predict thermal preference responses of new occupants. Our framework is capable of exploiting available background information such as physical characteristics and one-time on-boarding surveys (satisfaction with life scale, highly sensitive person scale, the Big Five personality traits) from the new occupant as well as physiological and environmental sensor measurements paired with thermal preference responses. We implemented our framework in two publicly available datasets containing longitudinal data from 55 people, comprising more than 6,000 individual thermal comfort surveys. We observed that, a Cohort Comfort Model that uses background information provided very little change in thermal preference prediction performance but uses none historical data. On the other hand, for half and one third of each dataset occupant population, using Cohort Comfort Models, with less historical data from target occupants, Cohort Comfort Models increased their thermal preference prediction by 8~\% and 5~\% on average, and up to 36~\% and 46~\% for some occupants, when compared to general-purpose models trained on the whole population of occupants. The framework is presented in a data and site agnostic manner, with its different components easily tailored to the data availability of the occupants and the buildings. Cohort Comfort Models can be an important step towards personalization without the need of developing a personalized model for each new occupant.
Trust Calibration as a Function of the Evolution of Uncertainty in Knowledge Generation: A Survey
Sep 09, 2022User trust is a crucial consideration in designing robust visual analytics systems that can guide users to reasonably sound conclusions despite inevitable biases and other uncertainties introduced by the human, the machine, and the data sources which paint the canvas upon which knowledge emerges. A multitude of factors emerge upon studied consideration which introduce considerable complexity and exacerbate our understanding of how trust relationships evolve in visual analytics systems, much as they do in intelligent sociotechnical systems. A visual analytics system, however, does not by its nature provoke exactly the same phenomena as its simpler cousins, nor are the phenomena necessarily of the same exact kind. Regardless, both application domains present the same root causes from which the need for trustworthiness arises: Uncertainty and the assumption of risk. In addition, visual analytics systems, even more than the intelligent systems which (traditionally) tend to be closed to direct human input and direction during processing, are influenced by a multitude of cognitive biases that further exacerbate an accounting of the uncertainties that may afflict the user's confidence, and ultimately trust in the system. In this article we argue that accounting for the propagation of uncertainty from data sources all the way through extraction of information and hypothesis testing is necessary to understand how user trust in a visual analytics system evolves over its lifecycle, and that the analyst's selection of visualization parameters affords us a simple means to capture the interactions between uncertainty and cognitive bias as a function of the attributes of the search tasks the analyst executes while evaluating explanations. We sample a broad cross-section of the literature from visual analytics, human cognitive theory, and uncertainty, and attempt to synthesize a useful perspective.
Unsupervised Speaker Diarization that is Agnostic to Language, Overlap-Aware, and Tuning Free
Jul 25, 2022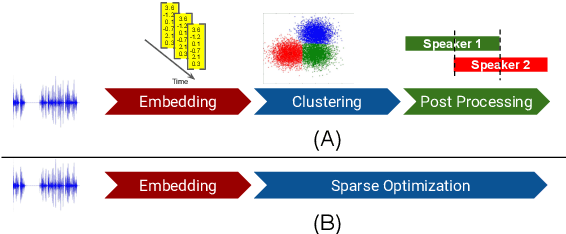
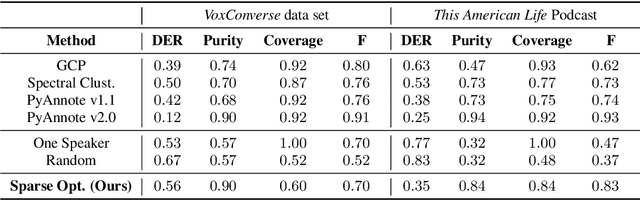
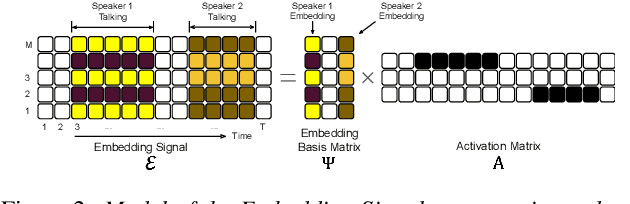
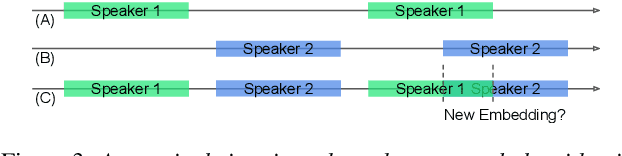
Podcasts are conversational in nature and speaker changes are frequent -- requiring speaker diarization for content understanding. We propose an unsupervised technique for speaker diarization without relying on language-specific components. The algorithm is overlap-aware and does not require information about the number of speakers. Our approach shows 79% improvement on purity scores (34% on F-score) against the Google Cloud Platform solution on podcast data.