 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnow your limits! Optimize the robot's behavior through self-awareness
Sep 16, 2024



As humanoid robots transition from labs to real-world environments, it is essential to democratize robot control for non-expert users. Recent human-robot imitation algorithms focus on following a reference human motion with high precision, but they are susceptible to the quality of the reference motion and require the human operator to simplify its movements to match the robot's capabilities. Instead, we consider that the robot should understand and adapt the reference motion to its own abilities, facilitating the operator's task. For that, we introduce a deep-learning model that anticipates the robot's performance when imitating a given reference. Then, our system can generate multiple references given a high-level task command, assign a score to each of them, and select the best reference to achieve the desired robot behavior. Our Self-AWare model (SAW) ranks potential robot behaviors based on various criteria, such as fall likelihood, adherence to the reference motion, and smoothness. We integrate advanced motion generation, robot control, and SAW in one unique system, ensuring optimal robot behavior for any task command. For instance, SAW can anticipate falls with 99.29% accuracy. For more information check our project page: https://evm7.github.io/Self-AWare
I-CTRL: Imitation to Control Humanoid Robots Through Constrained Reinforcement Learning
May 14, 2024This paper addresses the critical need for refining robot motions that, despite achieving a high visual similarity through human-to-humanoid retargeting methods, fall short of practical execution in the physical realm. Existing techniques in the graphics community often prioritize visual fidelity over physics-based feasibility, posing a significant challenge for deploying bipedal systems in practical applications. Our research introduces a constrained reinforcement learning algorithm to produce physics-based high-quality motion imitation onto legged humanoid robots that enhance motion resemblance while successfully following the reference human trajectory. We name our framework: I-CTRL. By reformulating the motion imitation problem as a constrained refinement over non-physics-based retargeted motions, our framework excels in motion imitation with simple and unique rewards that generalize across four robots. Moreover, our framework can follow large-scale motion datasets with a unique RL agent. The proposed approach signifies a crucial step forward in advancing the control of bipedal robots, emphasizing the importance of aligning visual and physical realism for successful motion imitation.
Robot Interaction Behavior Generation based on Social Motion Forecasting for Human-Robot Interaction
Feb 07, 2024Integrating robots into populated environments is a complex challenge that requires an understanding of human social dynamics. In this work, we propose to model social motion forecasting in a shared human-robot representation space, which facilitates us to synthesize robot motions that interact with humans in social scenarios despite not observing any robot in the motion training. We develop a transformer-based architecture called ECHO, which operates in the aforementioned shared space to predict the future motions of the agents encountered in social scenarios. Contrary to prior works, we reformulate the social motion problem as the refinement of the predicted individual motions based on the surrounding agents, which facilitates the training while allowing for single-motion forecasting when only one human is in the scene. We evaluate our model in multi-person and human-robot motion forecasting tasks and obtain state-of-the-art performance by a large margin while being efficient and performing in real-time. Additionally, our qualitative results showcase the effectiveness of our approach in generating human-robot interaction behaviors that can be controlled via text commands.
HOI4ABOT: Human-Object Interaction Anticipation for Human Intention Reading Collaborative roBOTs
Sep 28, 2023



Robots are becoming increasingly integrated into our lives, assisting us in various tasks. To ensure effective collaboration between humans and robots, it is essential that they understand our intentions and anticipate our actions. In this paper, we propose a Human-Object Interaction (HOI) anticipation framework for collaborative robots. We propose an efficient and robust transformer-based model to detect and anticipate HOIs from videos. This enhanced anticipation empowers robots to proactively assist humans, resulting in more efficient and intuitive collaborations. Our model outperforms state-of-the-art results in HOI detection and anticipation in VidHOI dataset with an increase of 1.76% and 1.04% in mAP respectively while being 15.4 times faster. We showcase the effectiveness of our approach through experimental results in a real robot, demonstrating that the robot's ability to anticipate HOIs is key for better Human-Robot Interaction. More information can be found on our project webpage: https://evm7.github.io/HOI4ABOT_page/
Unsupervised human-to-robot motion retargeting via expressive latent space
Sep 11, 2023This paper introduces a novel approach for human-to-robot motion retargeting, enabling robots to mimic human motion with precision while preserving the semantics of the motion. For that, we propose a deep learning method for direct translation from human to robot motion. Our method does not require annotated paired human-to-robot motion data, which reduces the effort when adopting new robots. To this end, we first propose a cross-domain similarity metric to compare the poses from different domains (i.e., human and robot). Then, our method achieves the construction of a shared latent space via contrastive learning and decodes latent representations to robot motion control commands. The learned latent space exhibits expressiveness as it captures the motions precisely and allows direct motion control in the latent space. We showcase how to generate in-between motion through simple linear interpolation in the latent space between two projected human poses. Additionally, we conducted a comprehensive evaluation of robot control using diverse modality inputs, such as texts, RGB videos, and key-poses, which enhances the ease of robot control to users of all backgrounds. Finally, we compare our model with existing works and quantitatively and qualitatively demonstrate the effectiveness of our approach, enhancing natural human-robot communication and fostering trust in integrating robots into daily life.
A Unified Masked Autoencoder with Patchified Skeletons for Motion Synthesis
Aug 14, 2023



The synthesis of human motion has traditionally been addressed through task-dependent models that focus on specific challenges, such as predicting future motions or filling in intermediate poses conditioned on known key-poses. In this paper, we present a novel task-independent model called UNIMASK-M, which can effectively address these challenges using a unified architecture. Our model obtains comparable or better performance than the state-of-the-art in each field. Inspired by Vision Transformers (ViTs), our UNIMASK-M model decomposes a human pose into body parts to leverage the spatio-temporal relationships existing in human motion. Moreover, we reformulate various pose-conditioned motion synthesis tasks as a reconstruction problem with different masking patterns given as input. By explicitly informing our model about the masked joints, our UNIMASK-M becomes more robust to occlusions. Experimental results show that our model successfully forecasts human motion on the Human3.6M dataset. Moreover, it achieves state-of-the-art results in motion inbetweening on the LaFAN1 dataset, particularly in long transition periods. More information can be found on the project website https://sites.google.com/view/estevevallsmascaro/publications/unimask-m.
Can We Use Diffusion Probabilistic Models for 3D Motion Prediction?
Feb 28, 2023



After many researchers observed fruitfulness from the recent diffusion probabilistic model, its effectiveness in image generation is actively studied these days. In this paper, our objective is to evaluate the potential of diffusion probabilistic models for 3D human motion-related tasks. To this end, this paper presents a study of employing diffusion probabilistic models to predict future 3D human motion(s) from the previously observed motion. Based on the Human 3.6M and HumanEva-I datasets, our results show that diffusion probabilistic models are competitive for both single (deterministic) and multiple (stochastic) 3D motion prediction tasks, after finishing a single training process. In addition, we find out that diffusion probabilistic models can offer an attractive compromise, since they can strike the right balance between the likelihood and diversity of the predicted future motions. Our code is publicly available on the project website: https://sites.google.com/view/diffusion-motion-prediction.
Robust Human Motion Forecasting using Transformer-based Model
Feb 16, 2023



Comprehending human motion is a fundamental challenge for developing Human-Robot Collaborative applications. Computer vision researchers have addressed this field by only focusing on reducing error in predictions, but not taking into account the requirements to facilitate its implementation in robots. In this paper, we propose a new model based on Transformer that simultaneously deals with the real time 3D human motion forecasting in the short and long term. Our 2-Channel Transformer (2CH-TR) is able to efficiently exploit the spatio-temporal information of a shortly observed sequence (400ms) and generates a competitive accuracy against the current state-of-the-art. 2CH-TR stands out for the efficient performance of the Transformer, being lighter and faster than its competitors. In addition, our model is tested in conditions where the human motion is severely occluded, demonstrating its robustness in reconstructing and predicting 3D human motion in a highly noisy environment. Our experiment results show that the proposed 2CH-TR outperforms the ST-Transformer, which is another state-of-the-art model based on the Transformer, in terms of reconstruction and prediction under the same conditions of input prefix. Our model reduces in 8.89% the mean squared error of ST-Transformer in short-term prediction, and 2.57% in long-term prediction in Human3.6M dataset with 400ms input prefix.
* This paper has been already accepted to the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2022)
Intention-Conditioned Long-Term Human Egocentric Action Forecasting @ EGO4D Challenge 2022
Jul 25, 2022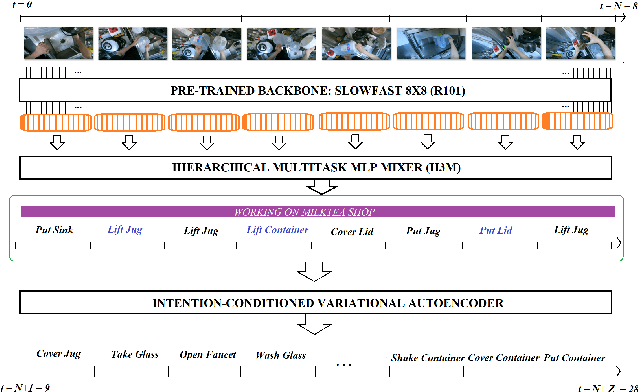
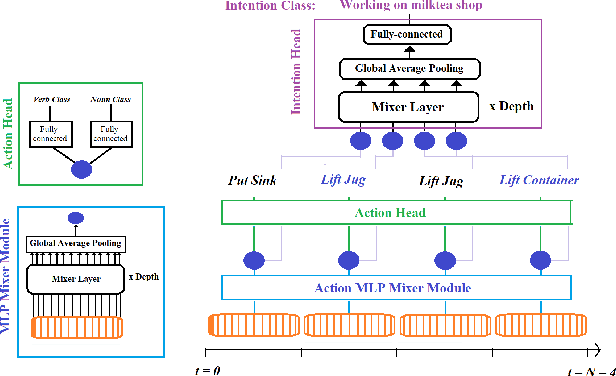
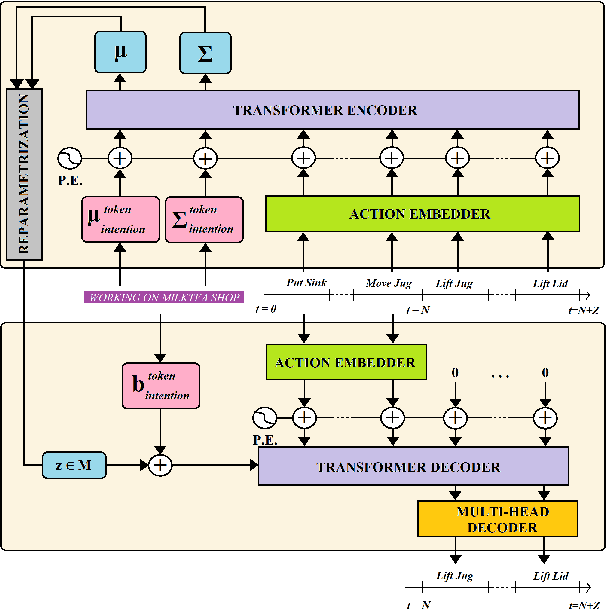
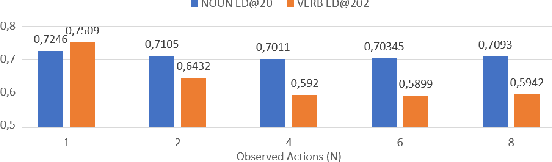
To anticipate how a human would act in the future, it is essential to understand the human intention since it guides the human towards a certain goal. In this paper, we propose a hierarchical architecture which assumes a sequence of human action (low-level) can be driven from the human intention (high-level). Based on this, we deal with Long-Term Action Anticipation task in egocentric videos. Our framework first extracts two level of human information over the N observed videos human actions through a Hierarchical Multi-task MLP Mixer (H3M). Then, we condition the uncertainty of the future through an Intention-Conditioned Variational Auto-Encoder (I-CVAE) that generates K stable predictions of the next Z=20 actions that the observed human might perform. By leveraging human intention as high-level information, we claim that our model is able to anticipate more time-consistent actions in the long-term, thus improving the results over baseline methods in EGO4D Challenge. This work ranked first in the EGO4D LTA Challenge by providing more plausible anticipated sequences, improving the anticipation of nouns and overall actions. The code is available at https://github.com/Evm7/ego4dlta-icvae.