 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCheXmix: Unified Generative Pretraining for Vision Language Models in Medical Imaging
Apr 24, 2026Recent medical multimodal foundation models are built as multimodal LLMs (MLLMs) by connecting a CLIP-pretrained vision encoder to an LLM using LLaVA-style finetuning. This two-stage, decoupled approach introduces a projection layer that can distort visual features. This is especially concerning in medical imaging where subtle cues are essential for accurate diagnoses. In contrast, early-fusion generative approaches such as Chameleon eliminate the projection bottleneck by processing image and text tokens within a single unified sequence, enabling joint representation learning that leverages the inductive priors of language models. We present CheXmix, a unified early-fusion generative model trained on a large corpus of chest X-rays paired with radiology reports. We expand on Chameleon's autoregressive framework by introducing a two-stage multimodal generative pretraining strategy that combines the representational strengths of masked autoencoders with MLLMs. The resulting models are highly flexible, supporting both discriminative and generative tasks at both coarse and fine-grained scales. Our approach outperforms well-established generative models across all masking ratios by 6.0% and surpasses CheXagent by 8.6% on AUROC at high image masking ratios on the CheXpert classification task. We further inpaint images over 51.0% better than text-only generative models and outperform CheXagent by 45% on the GREEN metric for radiology report generation. These results demonstrate that CheXmix captures fine-grained information across a broad spectrum of chest X-ray tasks. Our code is at: https://github.com/StanfordMIMI/CheXmix.
GrounDial: Human-norm Grounded Safe Dialog Response Generation
Feb 14, 2024



Current conversational AI systems based on large language models (LLMs) are known to generate unsafe responses, agreeing to offensive user input or including toxic content. Previous research aimed to alleviate the toxicity, by fine-tuning LLM with manually annotated safe dialogue histories. However, the dependency on additional tuning requires substantial costs. To remove the dependency, we propose GrounDial, where response safety is achieved by grounding responses to commonsense social rules without requiring fine-tuning. A hybrid approach of in-context learning and human-norm-guided decoding of GrounDial enables the response to be quantitatively and qualitatively safer even without additional data or tuning.
Learning Personalized Representations using Graph Convolutional Network
Jul 28, 2022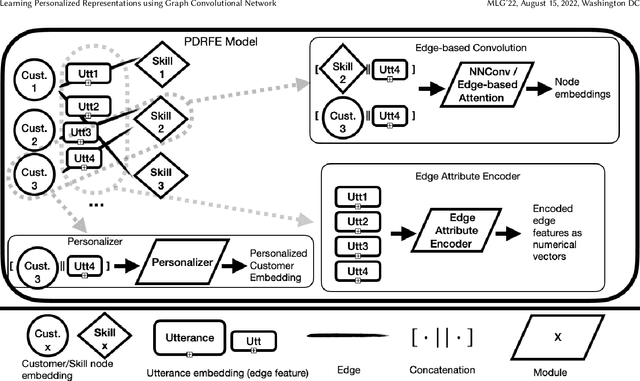

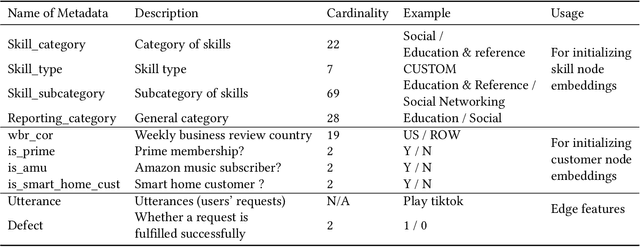
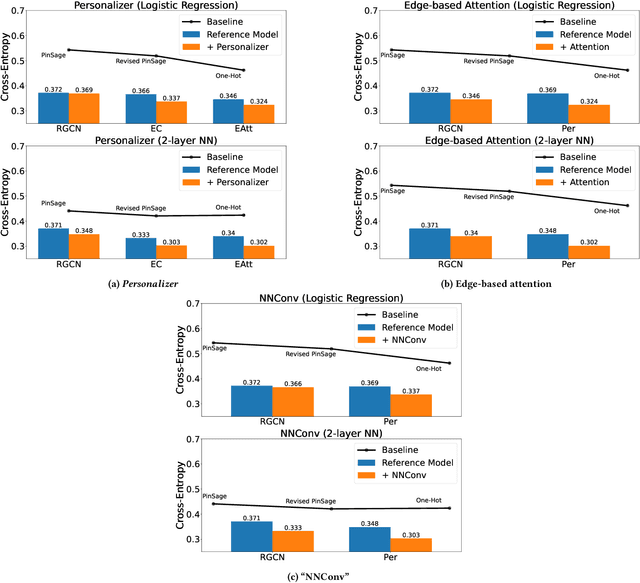
Generating representations that precisely reflect customers' behavior is an important task for providing personalized skill routing experience in Alexa. Currently, Dynamic Routing (DR) team, which is responsible for routing Alexa traffic to providers or skills, relies on two features to be served as personal signals: absolute traffic count and normalized traffic count of every skill usage per customer. Neither of them considers the network based structure for interactions between customers and skills, which contain richer information for customer preferences. In this work, we first build a heterogeneous edge attributed graph based customers' past interactions with the invoked skills, in which the user requests (utterances) are modeled as edges. Then we propose a graph convolutional network(GCN) based model, namely Personalized Dynamic Routing Feature Encoder(PDRFE), that generates personalized customer representations learned from the built graph. Compared with existing models, PDRFE is able to further capture contextual information in the graph convolutional function. The performance of our proposed model is evaluated by a downstream task, defect prediction, that predicts the defect label from the learned embeddings of customers and their triggered skills. We observe up to 41% improvements on the cross entropy metric for our proposed models compared to the baselines.