 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeakRL: Synergizing Reasoning, Speaking, and Acting in Language Models with Reinforcement Learning
Dec 15, 2025



Effective human-agent collaboration is increasingly prevalent in real-world applications. Current trends in such collaborations are predominantly unidirectional, with users providing instructions or posing questions to agents, where agents respond directly without seeking necessary clarifications or confirmations. However, the evolving capabilities of these agents require more proactive engagement, where agents should dynamically participate in conversations to clarify user intents, resolve ambiguities, and adapt to changing circumstances. Existing prior work under-utilize the conversational capabilities of language models (LMs), thereby optimizing agents as better followers rather than effective speakers. In this work, we introduce SpeakRL, a reinforcement learning (RL) method that enhances agents' conversational capabilities by rewarding proactive interactions with users, such as asking right clarification questions when necessary. To support this, we curate SpeakER, a synthetic dataset that includes diverse scenarios from task-oriented dialogues, where tasks are resolved through interactive clarification questions. We present a systematic analysis of reward design for conversational proactivity and propose a principled reward formulation for teaching agents to balance asking with acting. Empirical evaluations demonstrate that our approach achieves a 20.14% absolute improvement in task completion over base models without increasing conversation turns even surpassing even much larger proprietary models, demonstrating the promise of clarification-centric user-agent interactions.
MAC: A Multi-Agent Framework for Interactive User Clarification in Multi-turn Conversations
Dec 15, 2025Conversational agents often encounter ambiguous user requests, requiring an effective clarification to successfully complete tasks. While recent advancements in real-world applications favor multi-agent architectures to manage complex conversational scenarios efficiently, ambiguity resolution remains a critical and underexplored challenge--particularly due to the difficulty of determining which agent should initiate a clarification and how agents should coordinate their actions when faced with uncertain or incomplete user input. The fundamental questions of when to interrupt a user and how to formulate the optimal clarification query within the most optimal multi-agent settings remain open. In this paper, we propose MAC (Multi-Agent Clarification), an interactive multi-agent framework specifically optimized to resolve user ambiguities by strategically managing clarification dialogues. We first introduce a novel taxonomy categorizing user ambiguities to systematically guide clarification strategies. Then, we present MAC that autonomously coordinates multiple agents to interact synergistically with users. Empirical evaluations on MultiWOZ 2.4 demonstrate that enabling clarification at both levels increases task success rate 7.8\% (54.5 to 62.3) and reduces the average number of dialogue turns (6.53 to 4.86) by eliciting all required user information up front and minimizing repetition. Our findings highlight the importance of active user interaction and role-aware clarification for more reliable human-agent communication.
Image is All You Need: Towards Efficient and Effective Large Language Model-Based Recommender Systems
Mar 08, 2025Large Language Models (LLMs) have recently emerged as a powerful backbone for recommender systems. Existing LLM-based recommender systems take two different approaches for representing items in natural language, i.e., Attribute-based Representation and Description-based Representation. In this work, we aim to address the trade-off between efficiency and effectiveness that these two approaches encounter, when representing items consumed by users. Based on our interesting observation that there is a significant information overlap between images and descriptions associated with items, we propose a novel method, Image is all you need for LLM-based Recommender system (I-LLMRec). Our main idea is to leverage images as an alternative to lengthy textual descriptions for representing items, aiming at reducing token usage while preserving the rich semantic information of item descriptions. Through extensive experiments, we demonstrate that I-LLMRec outperforms existing methods in both efficiency and effectiveness by leveraging images. Moreover, a further appeal of I-LLMRec is its ability to reduce sensitivity to noise in descriptions, leading to more robust recommendations.
Debiasing Neighbor Aggregation for Graph Neural Network in Recommender Systems
Aug 18, 2022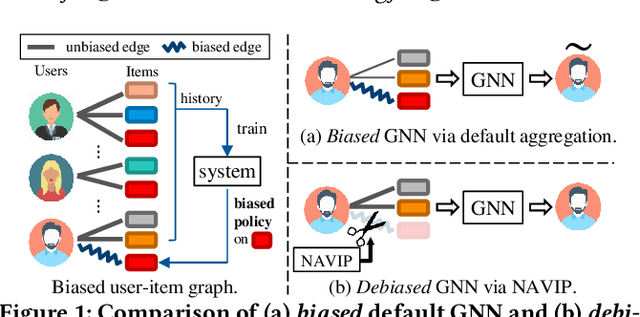

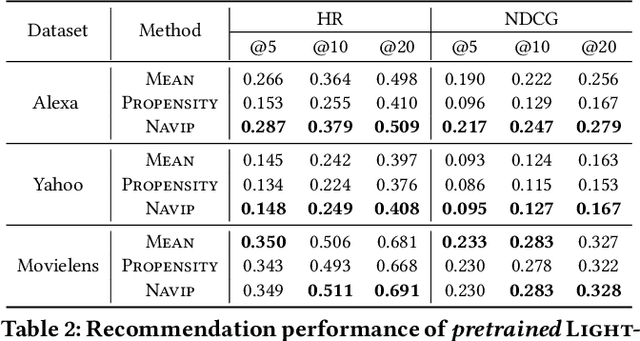
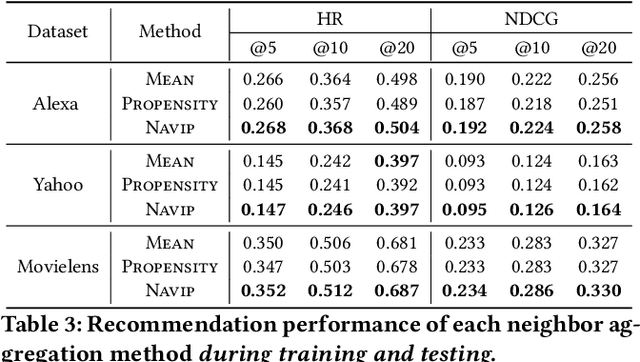
Graph neural networks (GNNs) have achieved remarkable success in recommender systems by representing users and items based on their historical interactions. However, little attention was paid to GNN's vulnerability to exposure bias: users are exposed to a limited number of items so that a system only learns a biased view of user preference to result in suboptimal recommendation quality. Although inverse propensity weighting is known to recognize and alleviate exposure bias, it usually works on the final objective with the model outputs, whereas GNN can also be biased during neighbor aggregation. In this paper, we propose a simple but effective approach, neighbor aggregation via inverse propensity (Navip) for GNNs. Specifically, given a user-item bipartite graph, we first derive propensity score of each user-item interaction in the graph. Then, inverse of the propensity score with Laplacian normalization is applied to debias neighbor aggregation from exposure bias. We validate the effectiveness of our approach through our extensive experiments on two public and Amazon Alexa datasets where the performance enhances up to 14.2%.
Learning Personalized Representations using Graph Convolutional Network
Jul 28, 2022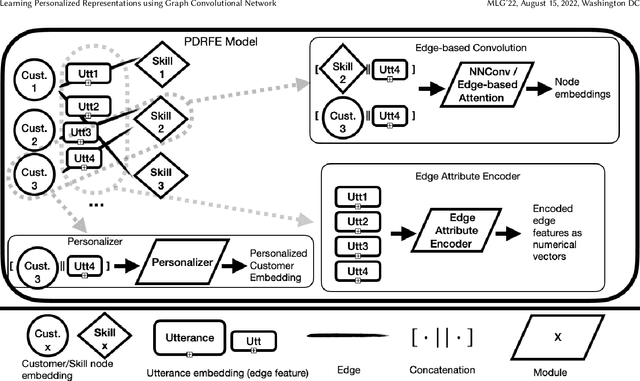

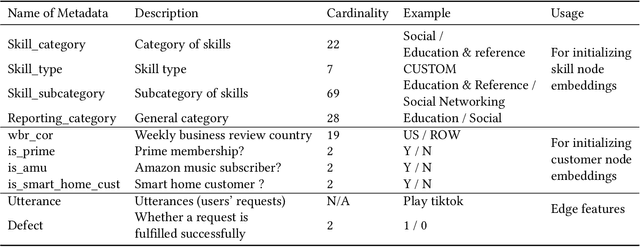
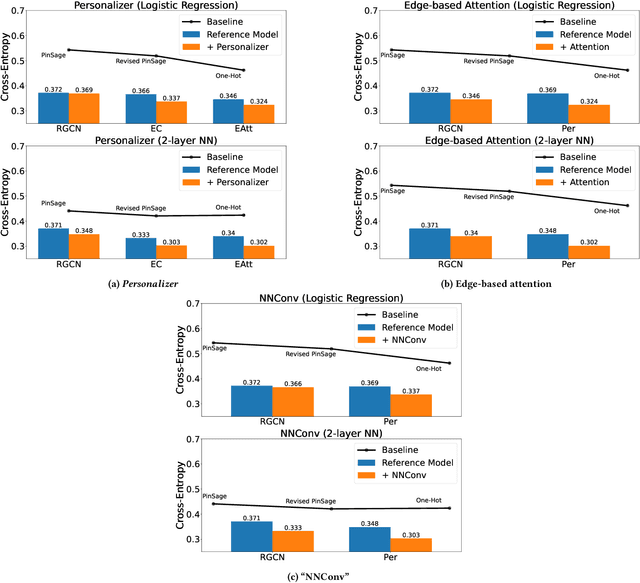
Generating representations that precisely reflect customers' behavior is an important task for providing personalized skill routing experience in Alexa. Currently, Dynamic Routing (DR) team, which is responsible for routing Alexa traffic to providers or skills, relies on two features to be served as personal signals: absolute traffic count and normalized traffic count of every skill usage per customer. Neither of them considers the network based structure for interactions between customers and skills, which contain richer information for customer preferences. In this work, we first build a heterogeneous edge attributed graph based customers' past interactions with the invoked skills, in which the user requests (utterances) are modeled as edges. Then we propose a graph convolutional network(GCN) based model, namely Personalized Dynamic Routing Feature Encoder(PDRFE), that generates personalized customer representations learned from the built graph. Compared with existing models, PDRFE is able to further capture contextual information in the graph convolutional function. The performance of our proposed model is evaluated by a downstream task, defect prediction, that predicts the defect label from the learned embeddings of customers and their triggered skills. We observe up to 41% improvements on the cross entropy metric for our proposed models compared to the baselines.