 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Improving Matrix Completion by Exploiting Rating Ordinality in Graph Neural Networks
Mar 07, 2024
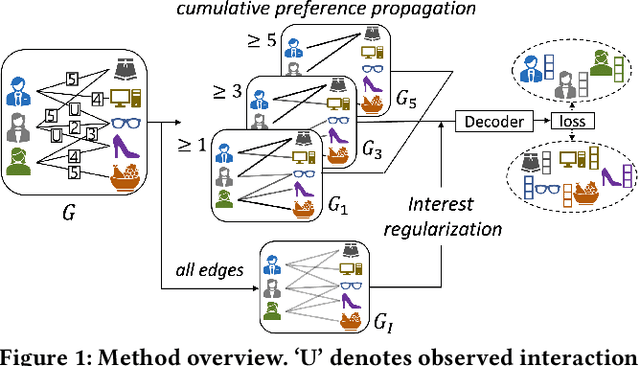
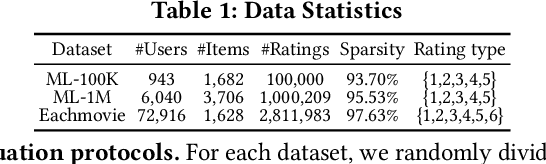
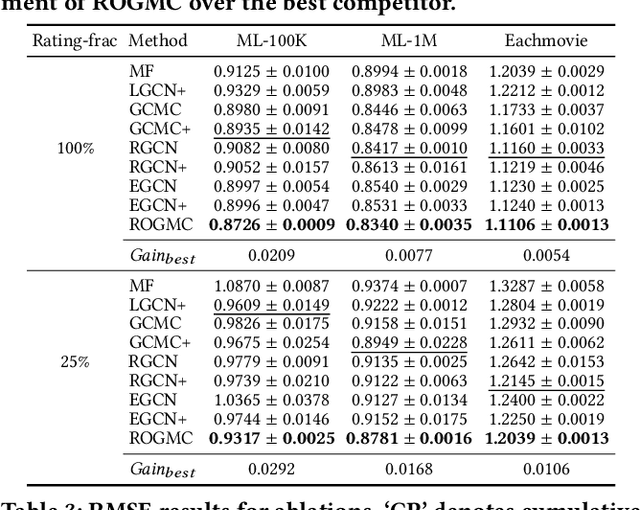
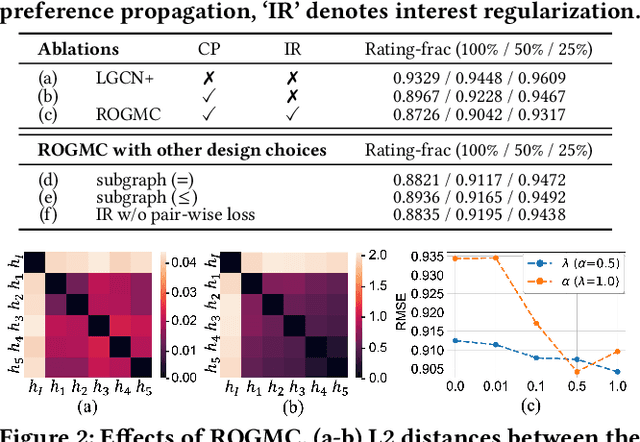
Matrix completion is an important area of research in recommender systems. Recent methods view a rating matrix as a user-item bi-partite graph with labeled edges denoting observed ratings and predict the edges between the user and item nodes by using the graph neural network (GNN). Despite their effectiveness, they treat each rating type as an independent relation type and thus cannot sufficiently consider the ordinal nature of the ratings. In this paper, we explore a new approach to exploit rating ordinality for GNN, which has not been studied well in the literature. We introduce a new method, called ROGMC, to leverage Rating Ordinality in GNN-based Matrix Completion. It uses cumulative preference propagation to directly incorporate rating ordinality in GNN's message passing, allowing for users' stronger preferences to be more emphasized based on inherent orders of rating types. This process is complemented by interest regularization which facilitates preference learning using the underlying interest information. Our extensive experiments show that ROGMC consistently outperforms the existing strategies of using rating types for GNN. We expect that our attempt to explore the feasibility of utilizing rating ordinality for GNN may stimulate further research in this direction.
Rethinking of Encoder-based Warm-start Methods in Hyperparameter Optimization
Mar 07, 2024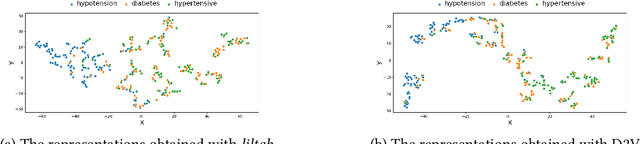
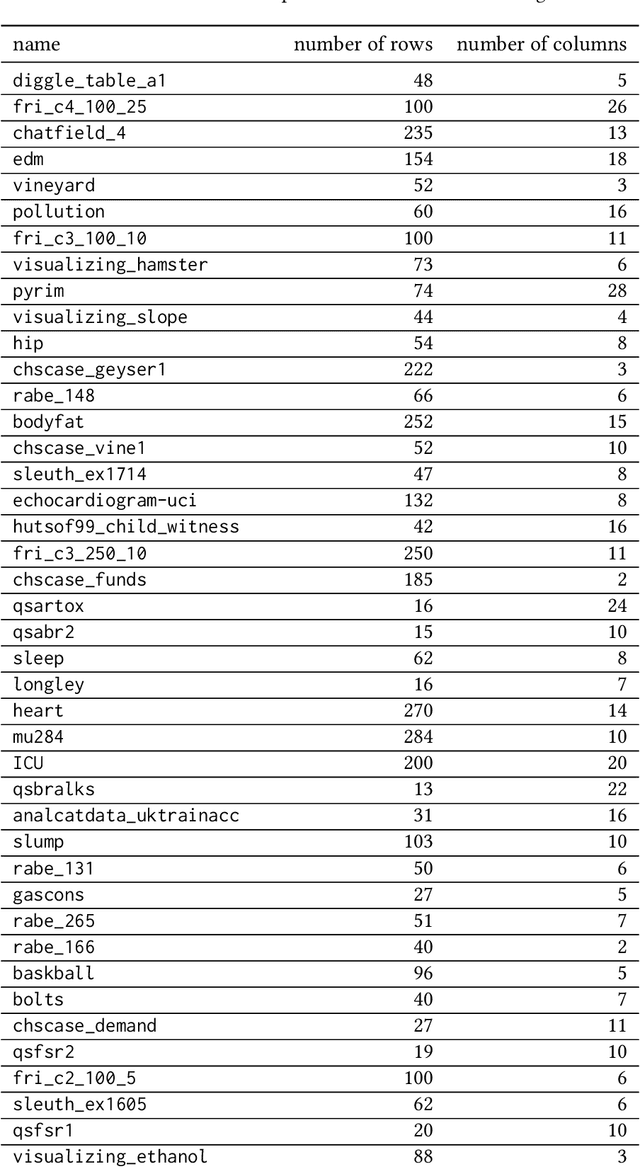

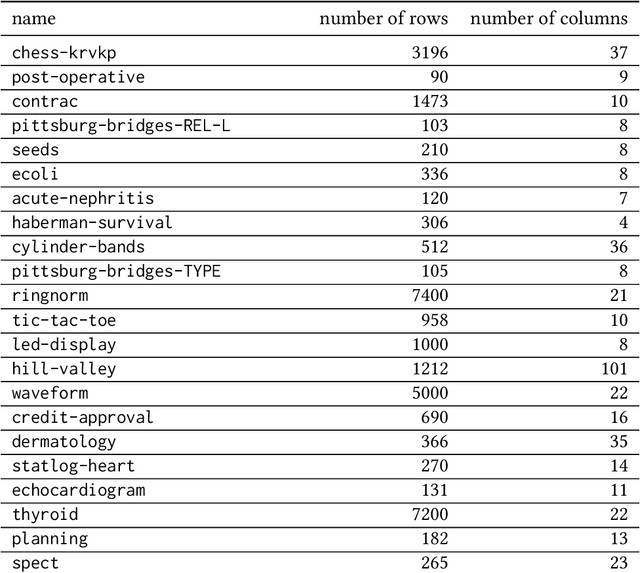
Effectively representing heterogeneous tabular datasets for meta-learning remains an open problem. Previous approaches rely on predefined meta-features, for example, statistical measures or landmarkers. Encoder-based models, such as Dataset2Vec, allow us to extract significant meta-features automatically without human intervention. This research introduces a novel encoder-based representation of tabular datasets implemented within the liltab package available on GitHub https://github.com/azoz01/liltab. Our package is based on an established model for heterogeneous tabular data proposed in [Iwata and Kumagai, 2020]. The proposed approach employs a different model for encoding feature relationships, generating alternative representations compared to existing methods like Dataset2Vec. Both of them leverage the fundamental assumption of dataset similarity learning. In this work, we evaluate Dataset2Vec and liltab on two common meta-tasks - representing entire datasets and hyperparameter optimization warm-start. However, validation on an independent metaMIMIC dataset highlights the nuanced challenges in representation learning. We show that general representations may not suffice for some meta-tasks where requirements are not explicitly considered during extraction. [Iwata and Kumagai, 2020] Tomoharu Iwata and Atsutoshi Kumagai. Meta-learning from Tasks with Heterogeneous Attribute Spaces. In Advances in Neural Information Processing Systems, 2020.
Efficient LoFTR: Semi-Dense Local Feature Matching with Sparse-Like Speed
Mar 07, 2024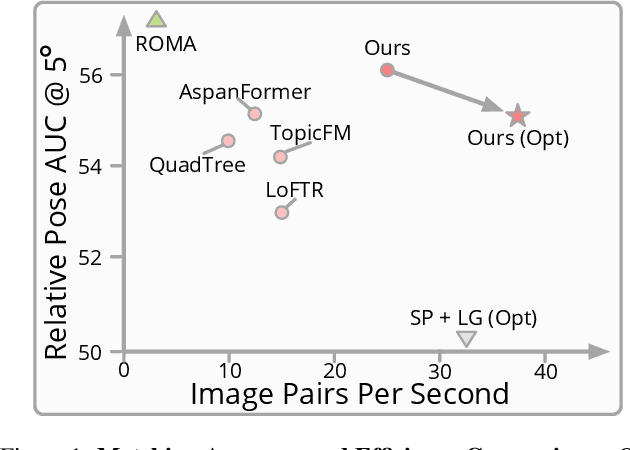
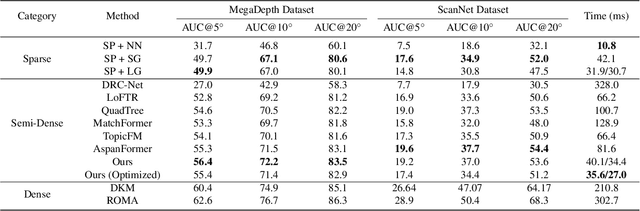
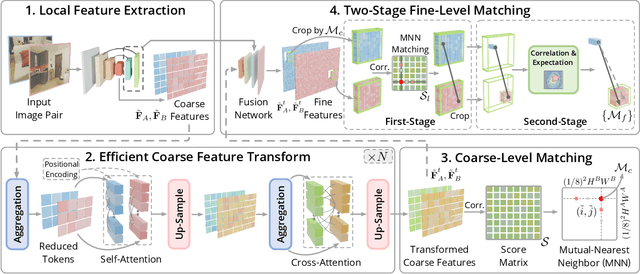
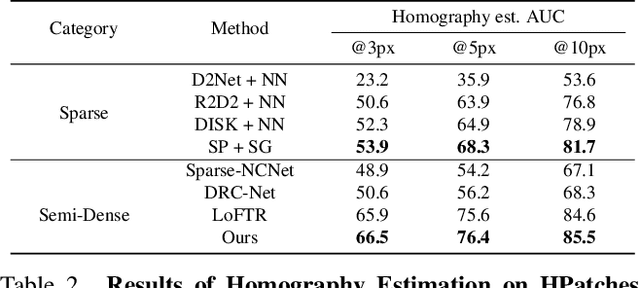
We present a novel method for efficiently producing semi-dense matches across images. Previous detector-free matcher LoFTR has shown remarkable matching capability in handling large-viewpoint change and texture-poor scenarios but suffers from low efficiency. We revisit its design choices and derive multiple improvements for both efficiency and accuracy. One key observation is that performing the transformer over the entire feature map is redundant due to shared local information, therefore we propose an aggregated attention mechanism with adaptive token selection for efficiency. Furthermore, we find spatial variance exists in LoFTR's fine correlation module, which is adverse to matching accuracy. A novel two-stage correlation layer is proposed to achieve accurate subpixel correspondences for accuracy improvement. Our efficiency optimized model is $\sim 2.5\times$ faster than LoFTR which can even surpass state-of-the-art efficient sparse matching pipeline SuperPoint + LightGlue. Moreover, extensive experiments show that our method can achieve higher accuracy compared with competitive semi-dense matchers, with considerable efficiency benefits. This opens up exciting prospects for large-scale or latency-sensitive applications such as image retrieval and 3D reconstruction. Project page: https://zju3dv.github.io/efficientloftr.
DA-Net: A Disentangled and Adaptive Network for Multi-Source Cross-Lingual Transfer Learning
Mar 07, 2024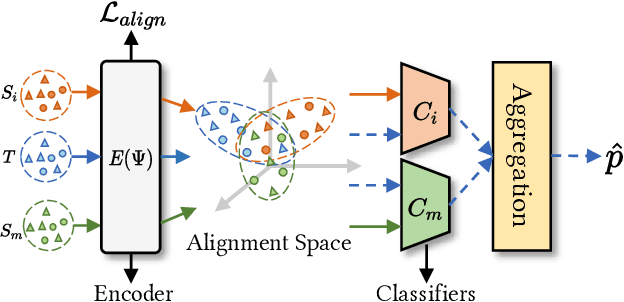
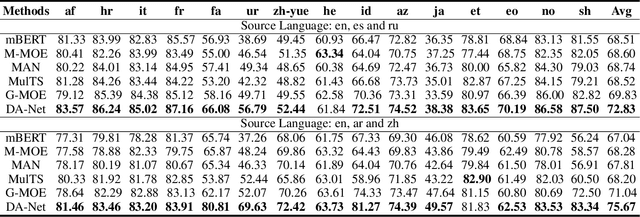
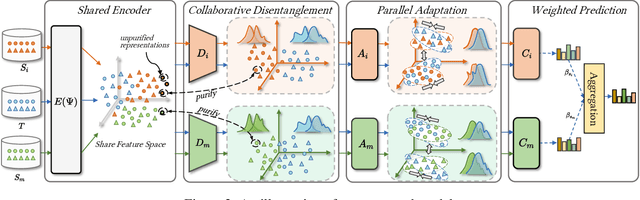

Multi-Source cross-lingual transfer learning deals with the transfer of task knowledge from multiple labelled source languages to an unlabeled target language under the language shift. Existing methods typically focus on weighting the predictions produced by language-specific classifiers of different sources that follow a shared encoder. However, all source languages share the same encoder, which is updated by all these languages. The extracted representations inevitably contain different source languages' information, which may disturb the learning of the language-specific classifiers. Additionally, due to the language gap, language-specific classifiers trained with source labels are unable to make accurate predictions for the target language. Both facts impair the model's performance. To address these challenges, we propose a Disentangled and Adaptive Network (DA-Net). Firstly, we devise a feedback-guided collaborative disentanglement method that seeks to purify input representations of classifiers, thereby mitigating mutual interference from multiple sources. Secondly, we propose a class-aware parallel adaptation method that aligns class-level distributions for each source-target language pair, thereby alleviating the language pairs' language gap. Experimental results on three different tasks involving 38 languages validate the effectiveness of our approach.
Improved Algorithm for Adversarial Linear Mixture MDPs with Bandit Feedback and Unknown Transition
Mar 07, 2024
We study reinforcement learning with linear function approximation, unknown transition, and adversarial losses in the bandit feedback setting. Specifically, we focus on linear mixture MDPs whose transition kernel is a linear mixture model. We propose a new algorithm that attains an $\widetilde{O}(d\sqrt{HS^3K} + \sqrt{HSAK})$ regret with high probability, where $d$ is the dimension of feature mappings, $S$ is the size of state space, $A$ is the size of action space, $H$ is the episode length and $K$ is the number of episodes. Our result strictly improves the previous best-known $\widetilde{O}(dS^2 \sqrt{K} + \sqrt{HSAK})$ result in Zhao et al. (2023a) since $H \leq S$ holds by the layered MDP structure. Our advancements are primarily attributed to (i) a new least square estimator for the transition parameter that leverages the visit information of all states, as opposed to only one state in prior work, and (ii) a new self-normalized concentration tailored specifically to handle non-independent noises, originally proposed in the dynamic assortment area and firstly applied in reinforcement learning to handle correlations between different states.
ProTrix: Building Models for Planning and Reasoning over Tables with Sentence Context
Mar 04, 2024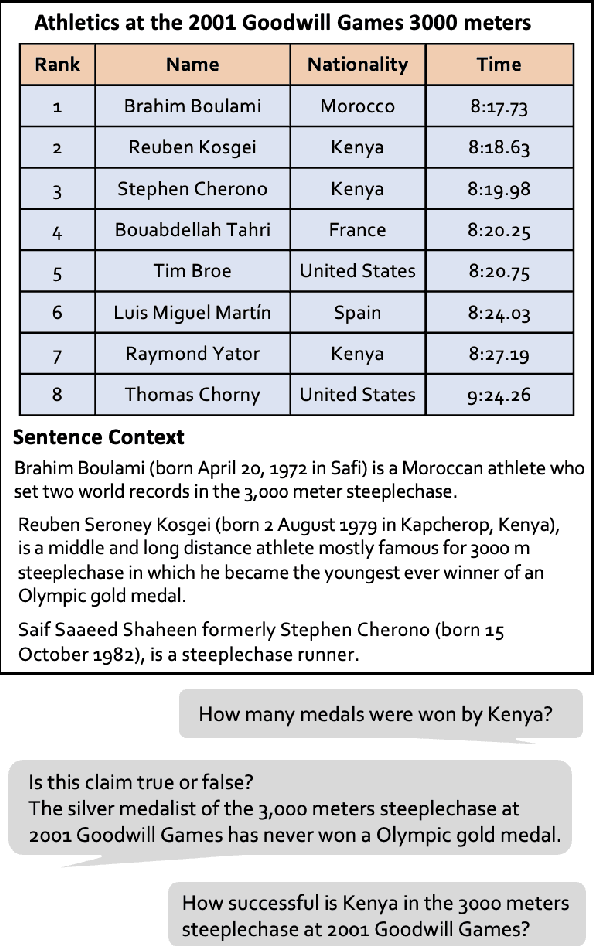
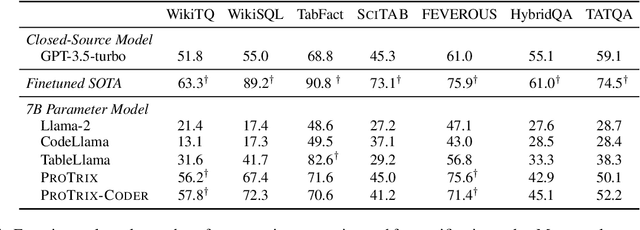
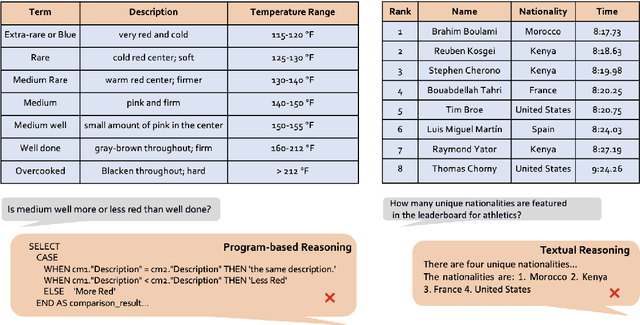
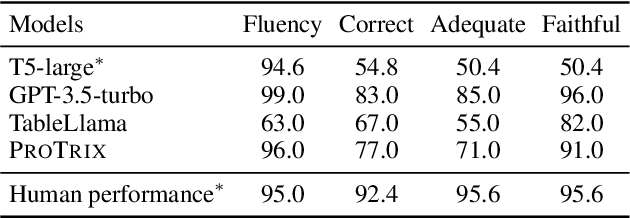
Tables play a crucial role in conveying information in various domains, serving as indispensable tools for organizing and presenting data in a structured manner. We propose a Plan-then-Reason framework to answer different types of user queries over tables with sentence context. The framework first plans the reasoning paths over the context, then assigns each step to program-based or textual reasoning to reach the final answer. We construct an instruction tuning set TrixInstruct following the framework. Our dataset cover queries that are program-unsolvable or need combining information from tables and sentences to obtain planning and reasoning abilities. We present ProTrix by finetuning Llama-2-7B on TrixInstruct. Our experiments show that ProTrix generalizes to diverse tabular tasks and achieves comparable performance to GPT-3.5-turbo. We further demonstrate that ProTrix can generate accurate and faithful explanations to answer complex free-form questions. Our work underscores the importance of the planning and reasoning abilities towards a model over tabular tasks with generalizability and interpretability. We will release our dataset and model at https://github.com/WilliamZR/ProTrix.
Modality-Aware and Shift Mixer for Multi-modal Brain Tumor Segmentation
Mar 04, 2024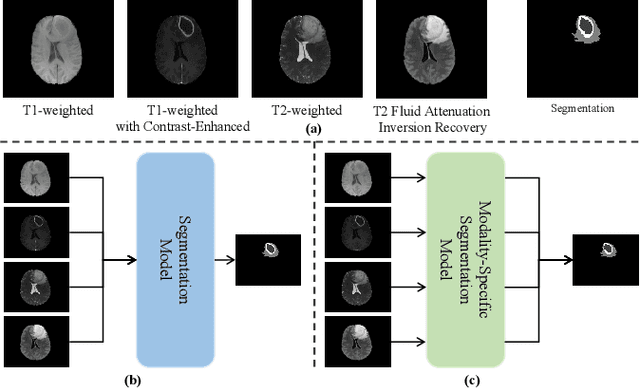
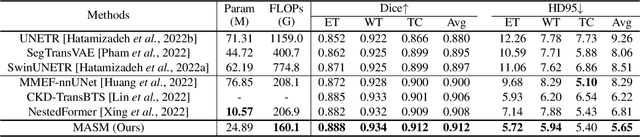
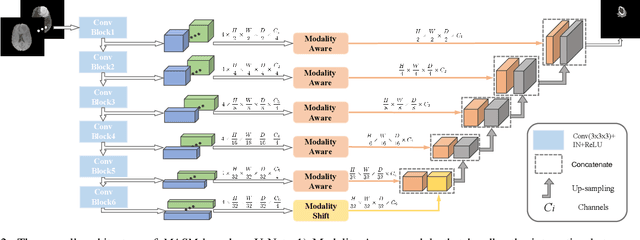
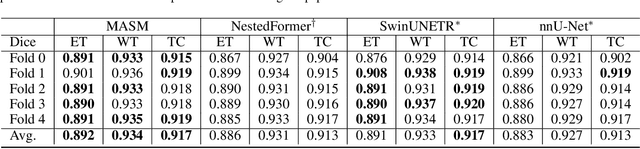
Combining images from multi-modalities is beneficial to explore various information in computer vision, especially in the medical domain. As an essential part of clinical diagnosis, multi-modal brain tumor segmentation aims to delineate the malignant entity involving multiple modalities. Although existing methods have shown remarkable performance in the task, the information exchange for cross-scale and high-level representations fusion in spatial and modality are limited in these methods. In this paper, we present a novel Modality Aware and Shift Mixer that integrates intra-modality and inter-modality dependencies of multi-modal images for effective and robust brain tumor segmentation. Specifically, we introduce a Modality-Aware module according to neuroimaging studies for modeling the specific modality pair relationships at low levels, and a Modality-Shift module with specific mosaic patterns is developed to explore the complex relationships across modalities at high levels via the self-attention. Experimentally, we outperform previous state-of-the-art approaches on the public Brain Tumor Segmentation (BraTS 2021 segmentation) dataset. Further qualitative experiments demonstrate the efficacy and robustness of MASM.
Mitigating Label Noise on Graph via Topological Sample Selection
Mar 04, 2024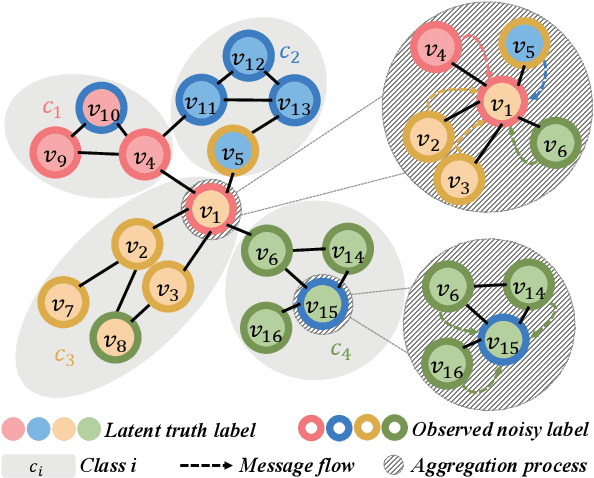
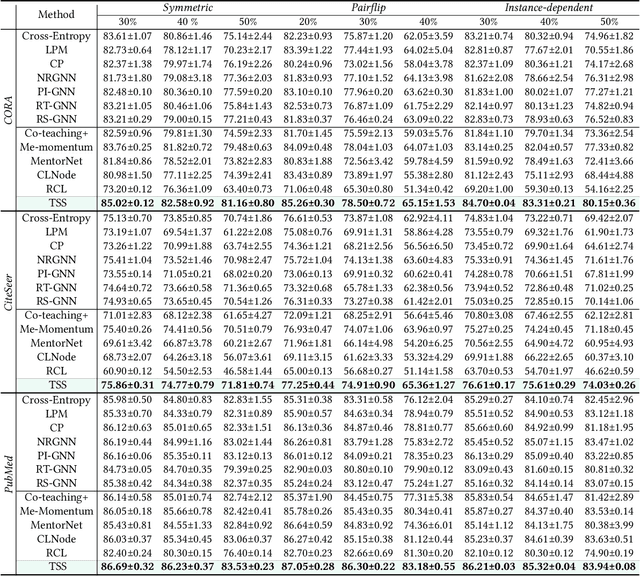
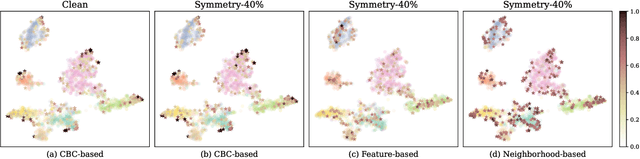
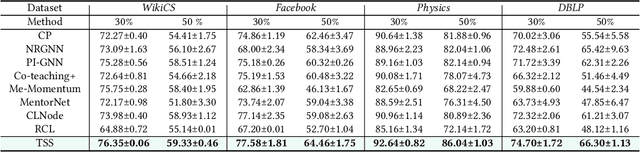
Despite the success of the carefully-annotated benchmarks, the effectiveness of existing graph neural networks (GNNs) can be considerably impaired in practice when the real-world graph data is noisily labeled. Previous explorations in sample selection have been demonstrated as an effective way for robust learning with noisy labels, however, the conventional studies focus on i.i.d data, and when moving to non-iid graph data and GNNs, two notable challenges remain: (1) nodes located near topological class boundaries are very informative for classification but cannot be successfully distinguished by the heuristic sample selection. (2) there is no available measure that considers the graph topological information to promote sample selection in a graph. To address this dilemma, we propose a $\textit{Topological Sample Selection}$ (TSS) method that boosts the informative sample selection process in a graph by utilising topological information. We theoretically prove that our procedure minimizes an upper bound of the expected risk under target clean distribution, and experimentally show the superiority of our method compared with state-of-the-art baselines.
Sensor-based Multi-Robot Search and Coverage with Spatial Separation in Unstructured Environments
Mar 04, 2024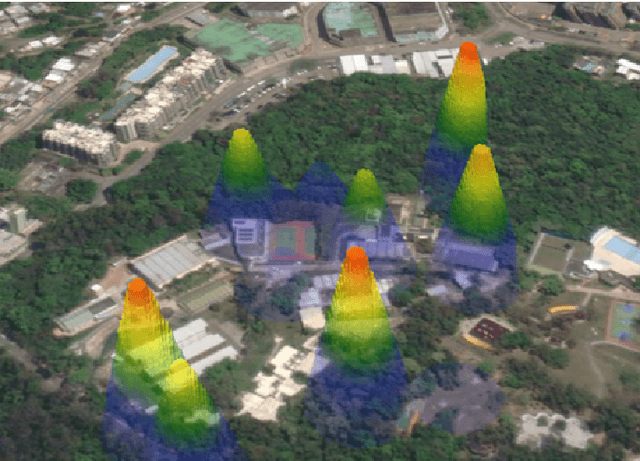
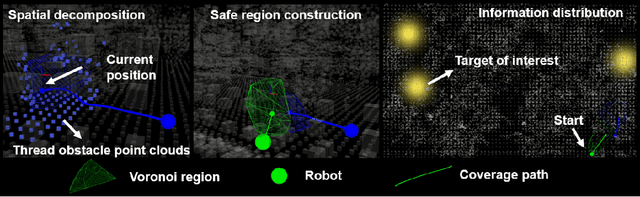
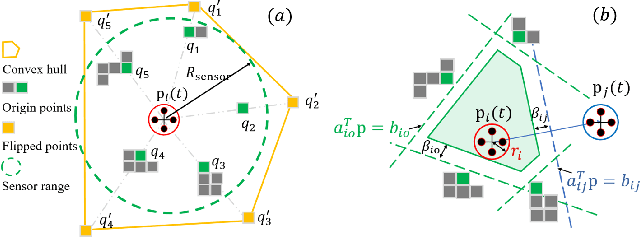

Multi-robot systems have increasingly become instrumental in tackling search and coverage problems. However, the challenge of optimizing task efficiency without compromising task success still persists, particularly in expansive, unstructured environments with dense obstacles. This paper presents an innovative, decentralized Voronoi-based approach for search and coverage to reactively navigate these complexities while maintaining safety. This approach leverages the active sensing capabilities of multi-robot systems to supplement GIS (Geographic Information System), offering a more comprehensive and real-time understanding of the environment. Based on point cloud data, which is inherently non-convex and unstructured, this method efficiently generates collision-free Voronoi regions using only local sensing information through spatial decomposition and spherical mirroring techniques. Then, deadlock-aware guided map integrated with a gradient-optimized, centroid Voronoi-based coverage control policy, is constructed to improve efficiency by avoiding exhaustive searches and local sensing pitfalls. The effectiveness of our algorithm has been validated through extensive numerical simulations in high-fidelity environments, demonstrating significant improvements in both task success rate, coverage ratio, and task execution time compared with others.
MCA: Moment Channel Attention Networks
Mar 04, 2024Channel attention mechanisms endeavor to recalibrate channel weights to enhance representation abilities of networks. However, mainstream methods often rely solely on global average pooling as the feature squeezer, which significantly limits the overall potential of models. In this paper, we investigate the statistical moments of feature maps within a neural network. Our findings highlight the critical role of high-order moments in enhancing model capacity. Consequently, we introduce a flexible and comprehensive mechanism termed Extensive Moment Aggregation (EMA) to capture the global spatial context. Building upon this mechanism, we propose the Moment Channel Attention (MCA) framework, which efficiently incorporates multiple levels of moment-based information while minimizing additional computation costs through our Cross Moment Convolution (CMC) module. The CMC module via channel-wise convolution layer to capture multiple order moment information as well as cross channel features. The MCA block is designed to be lightweight and easily integrated into a variety of neural network architectures. Experimental results on classical image classification, object detection, and instance segmentation tasks demonstrate that our proposed method achieves state-of-the-art results, outperforming existing channel attention methods.