 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multimodal Speech Enhancement Using Burst Propagation
Sep 07, 2022
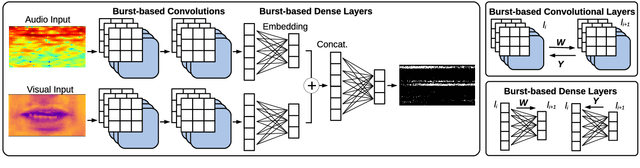
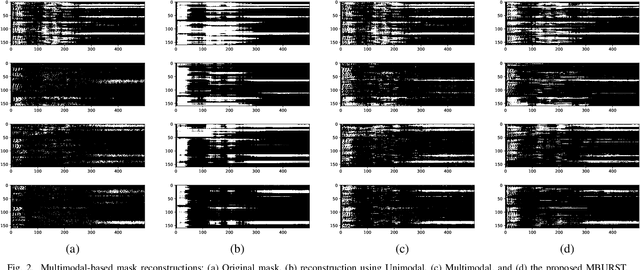
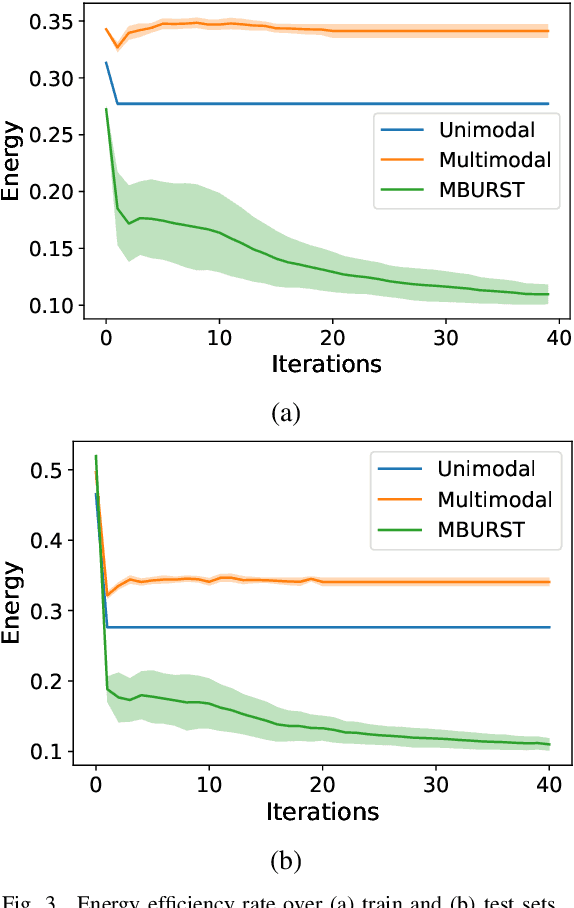
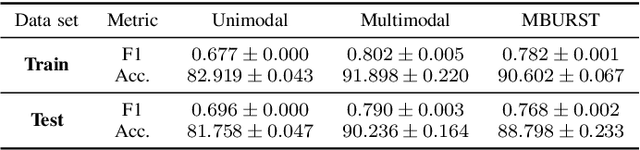
This paper proposes the MBURST, a novel multimodal solution for audio-visual speech enhancements that consider the most recent neurological discoveries regarding pyramidal cells of the prefrontal cortex and other brain regions. The so-called burst propagation implements several criteria to address the credit assignment problem in a more biologically plausible manner: steering the sign and magnitude of plasticity through feedback, multiplexing the feedback and feedforward information across layers through different weight connections, approximating feedback and feedforward connections, and linearizing the feedback signals. MBURST benefits from such capabilities to learn correlations between the noisy signal and the visual stimuli, thus attributing meaning to the speech by amplifying relevant information and suppressing noise. Experiments conducted over a Grid Corpus and CHiME3-based dataset show that MBURST can reproduce similar mask reconstructions to the multimodal backpropagation-based baseline while demonstrating outstanding energy efficiency management, reducing the neuron firing rates to values up to \textbf{$70\%$} lower. Such a feature implies more sustainable implementations, suitable and desirable for hearing aids or any other similar embedded systems.
Probing Cross-modal Semantics Alignment Capability from the Textual Perspective
Oct 18, 2022

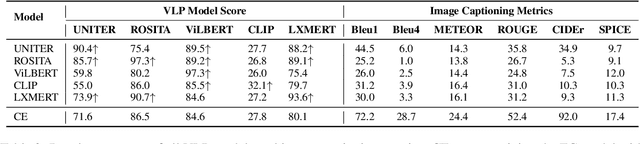
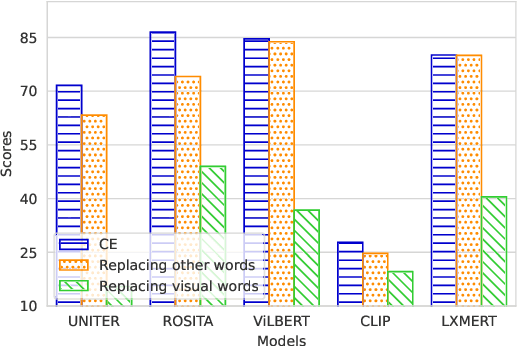
In recent years, vision and language pre-training (VLP) models have advanced the state-of-the-art results in a variety of cross-modal downstream tasks. Aligning cross-modal semantics is claimed to be one of the essential capabilities of VLP models. However, it still remains unclear about the inner working mechanism of alignment in VLP models. In this paper, we propose a new probing method that is based on image captioning to first empirically study the cross-modal semantics alignment of VLP models. Our probing method is built upon the fact that given an image-caption pair, the VLP models will give a score, indicating how well two modalities are aligned; maximizing such scores will generate sentences that VLP models believe are of good alignment. Analyzing these sentences thus will reveal in what way different modalities are aligned and how well these alignments are in VLP models. We apply our probing method to five popular VLP models, including UNITER, ROSITA, ViLBERT, CLIP, and LXMERT, and provide a comprehensive analysis of the generated captions guided by these models. Our results show that VLP models (1) focus more on just aligning objects with visual words, while neglecting global semantics; (2) prefer fixed sentence patterns, thus ignoring more important textual information including fluency and grammar; and (3) deem the captions with more visual words are better aligned with images. These findings indicate that VLP models still have weaknesses in cross-modal semantics alignment and we hope this work will draw researchers' attention to such problems when designing a new VLP model.
Digital Audio Tampering Detection Based on ENF Spatio-temporal Features Representation Learning
Aug 25, 2022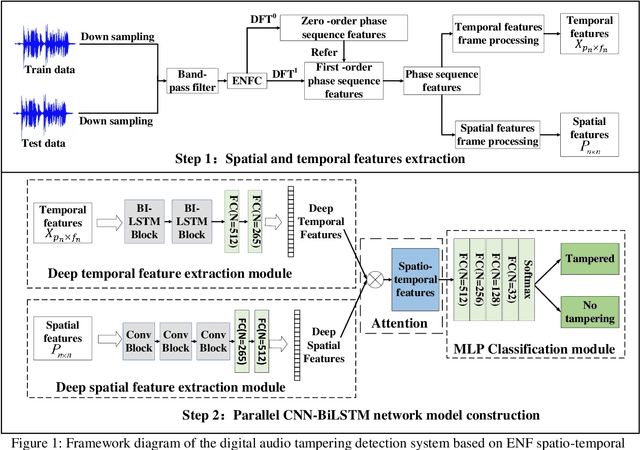
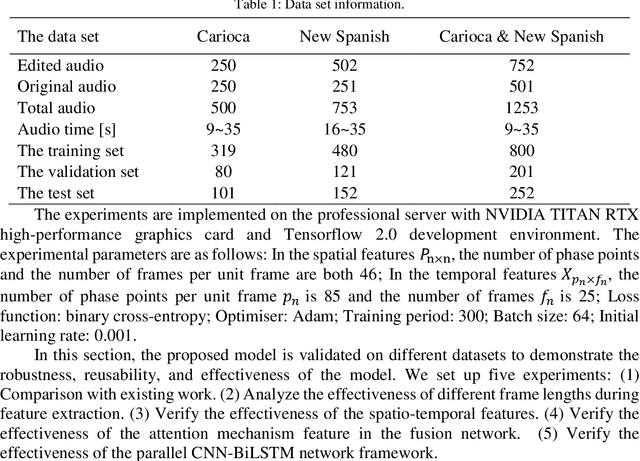
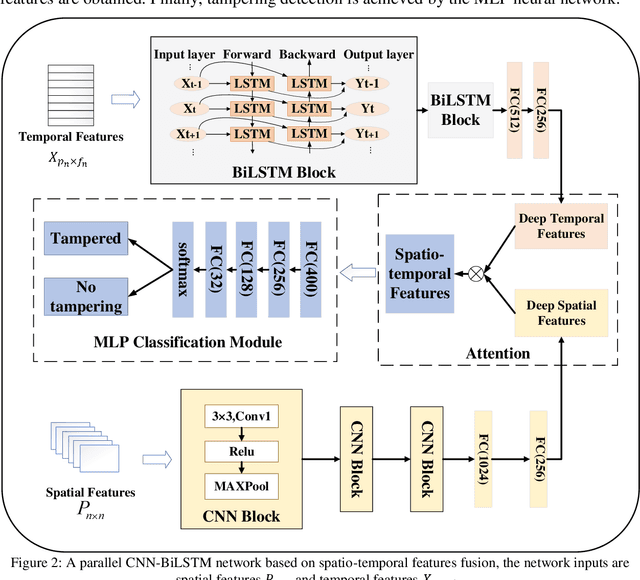
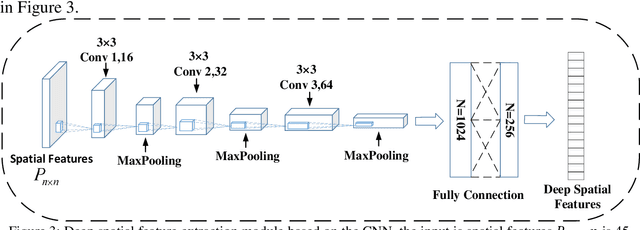
Most digital audio tampering detection methods based on electrical network frequency (ENF) only utilize the static spatial information of ENF, ignoring the variation of ENF in time series, which limit the ability of ENF feature representation and reduce the accuracy of tampering detection. This paper proposes a new method for digital audio tampering detection based on ENF spatio-temporal features representation learning. A parallel spatio-temporal network model is constructed using CNN and BiLSTM, which deeply extracts ENF spatial feature information and ENF temporal feature information to enhance the feature representation capability to improve the tampering detection accuracy. In order to extract the spatial and temporal features of the ENF, this paper firstly uses digital audio high-precision Discrete Fourier Transform analysis to extract the phase sequences of the ENF. The unequal phase series is divided into frames by adaptive frame shifting to obtain feature matrices of the same size to represent the spatial features of the ENF. At the same time, the phase sequences are divided into frames based on ENF time changes information to represent the temporal features of the ENF. Then deep spatial and temporal features are further extracted using CNN and BiLSTM respectively, and an attention mechanism is used to adaptively assign weights to the deep spatial and temporal features to obtain spatio-temporal features with stronger representation capability. Finally, the deep neural network is used to determine whether the audio has been tampered with. The experimental results show that the proposed method improves the accuracy by 2.12%-7.12% compared with state-of-the-art methods under the public database Carioca, New Spanish.
More Interpretable Graph Similarity Computation via Maximum Common Subgraph Inference
Aug 25, 2022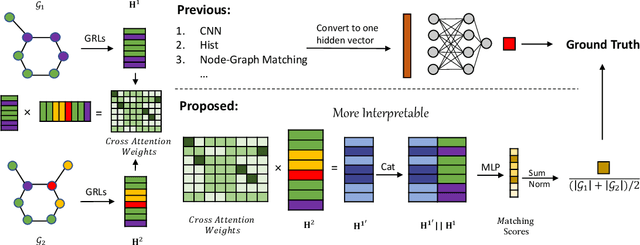
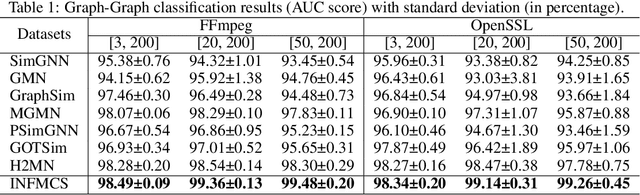
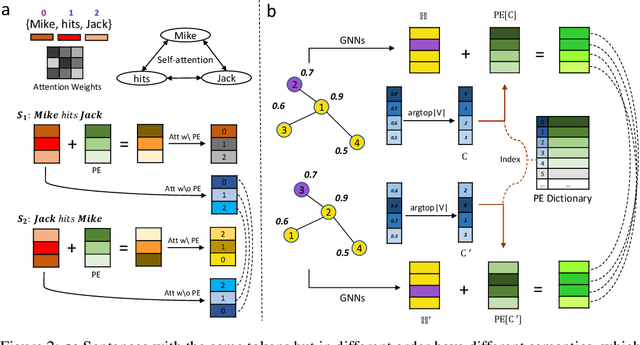
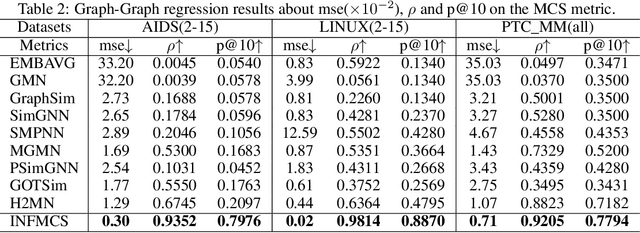
Graph similarity measurement, which computes the distance/similarity between two graphs, arises in various graph-related tasks. Recent learning-based methods lack interpretability, as they directly transform interaction information between two graphs into one hidden vector and then map it to similarity. To cope with this problem, this study proposes a more interpretable end-to-end paradigm for graph similarity learning, named Similarity Computation via Maximum Common Subgraph Inference (INFMCS). Our critical insight into INFMCS is the strong correlation between similarity score and Maximum Common Subgraph (MCS). We implicitly infer MCS to obtain the normalized MCS size, with the supervision information being only the similarity score during training. To capture more global information, we also stack some vanilla transformer encoder layers with graph convolution layers and propose a novel permutation-invariant node Positional Encoding. The entire model is quite simple yet effective. Comprehensive experiments demonstrate that INFMCS consistently outperforms state-of-the-art baselines for graph-graph classification and regression tasks. Ablation experiments verify the effectiveness of the proposed computation paradigm and other components. Also, visualization and statistics of results reveal the interpretability of INFMCS.
Explanations as Programs in Probabilistic Logic Programming
Oct 06, 2022The generation of comprehensible explanations is an essential feature of modern artificial intelligence systems. In this work, we consider probabilistic logic programming, an extension of logic programming which can be useful to model domains with relational structure and uncertainty. Essentially, a program specifies a probability distribution over possible worlds (i.e., sets of facts). The notion of explanation is typically associated with that of a world, so that one often looks for the most probable world as well as for the worlds where the query is true. Unfortunately, such explanations exhibit no causal structure. In particular, the chain of inferences required for a specific prediction (represented by a query) is not shown. In this paper, we propose a novel approach where explanations are represented as programs that are generated from a given query by a number of unfolding-like transformations. Here, the chain of inferences that proves a given query is made explicit. Furthermore, the generated explanations are minimal (i.e., contain no irrelevant information) and can be parameterized w.r.t. a specification of visible predicates, so that the user may hide uninteresting details from explanations.
Conversational Semantic Role Labeling with Predicate-Oriented Latent Graph
Oct 06, 2022
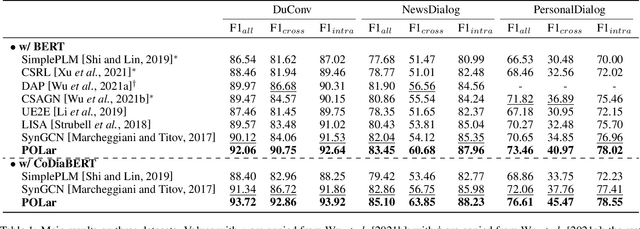
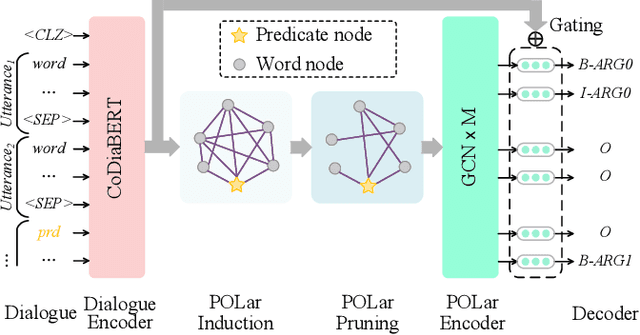
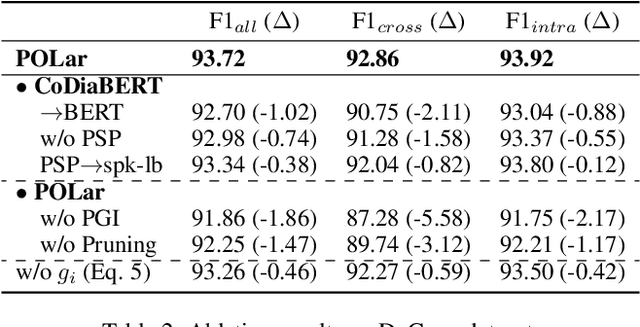
Conversational semantic role labeling (CSRL) is a newly proposed task that uncovers the shallow semantic structures in a dialogue text. Unfortunately several important characteristics of the CSRL task have been overlooked by the existing works, such as the structural information integration, near-neighbor influence. In this work, we investigate the integration of a latent graph for CSRL. We propose to automatically induce a predicate-oriented latent graph (POLar) with a predicate-centered Gaussian mechanism, by which the nearer and informative words to the predicate will be allocated with more attention. The POLar structure is then dynamically pruned and refined so as to best fit the task need. We additionally introduce an effective dialogue-level pre-trained language model, CoDiaBERT, for better supporting multiple utterance sentences and handling the speaker coreference issue in CSRL. Our system outperforms best-performing baselines on three benchmark CSRL datasets with big margins, especially achieving over 4% F1 score improvements on the cross-utterance argument detection. Further analyses are presented to better understand the effectiveness of our proposed methods.
Domain-Specific Word Embeddings with Structure Prediction
Oct 06, 2022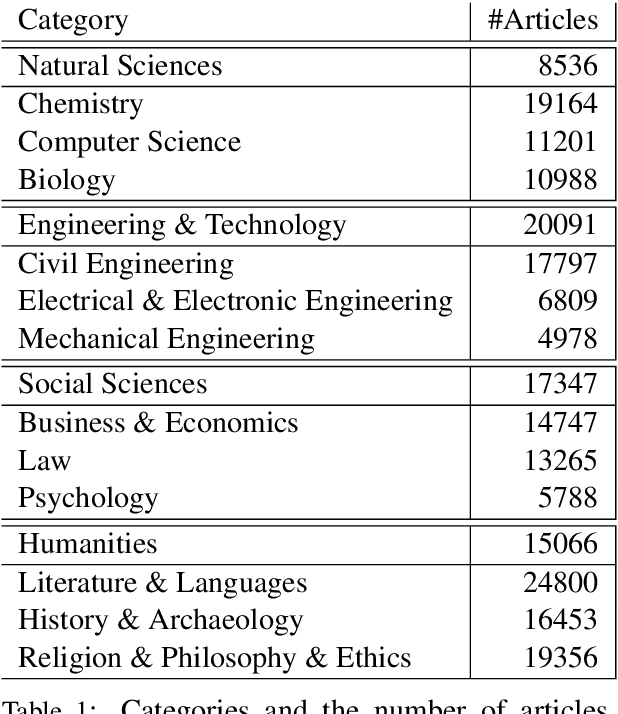
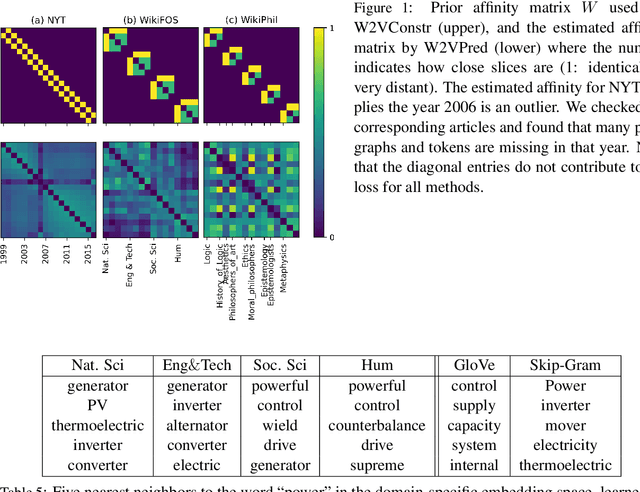
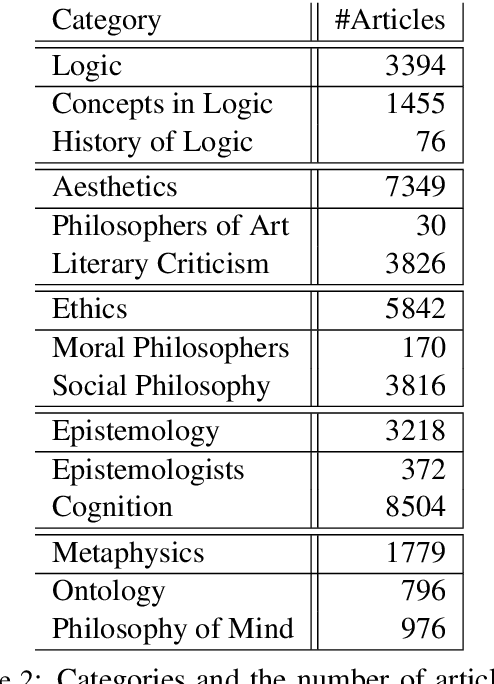
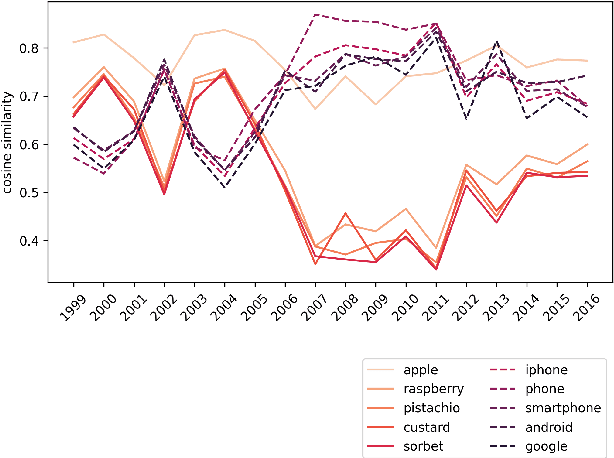
Complementary to finding good general word embeddings, an important question for representation learning is to find dynamic word embeddings, e.g., across time or domain. Current methods do not offer a way to use or predict information on structure between sub-corpora, time or domain and dynamic embeddings can only be compared after post-alignment. We propose novel word embedding methods that provide general word representations for the whole corpus, domain-specific representations for each sub-corpus, sub-corpus structure, and embedding alignment simultaneously. We present an empirical evaluation on New York Times articles and two English Wikipedia datasets with articles on science and philosophy. Our method, called Word2Vec with Structure Prediction (W2VPred), provides better performance than baselines in terms of the general analogy tests, domain-specific analogy tests, and multiple specific word embedding evaluations as well as structure prediction performance when no structure is given a priori. As a use case in the field of Digital Humanities we demonstrate how to raise novel research questions for high literature from the German Text Archive.
Robust Double-Encoder Network for RGB-D Panoptic Segmentation
Oct 06, 2022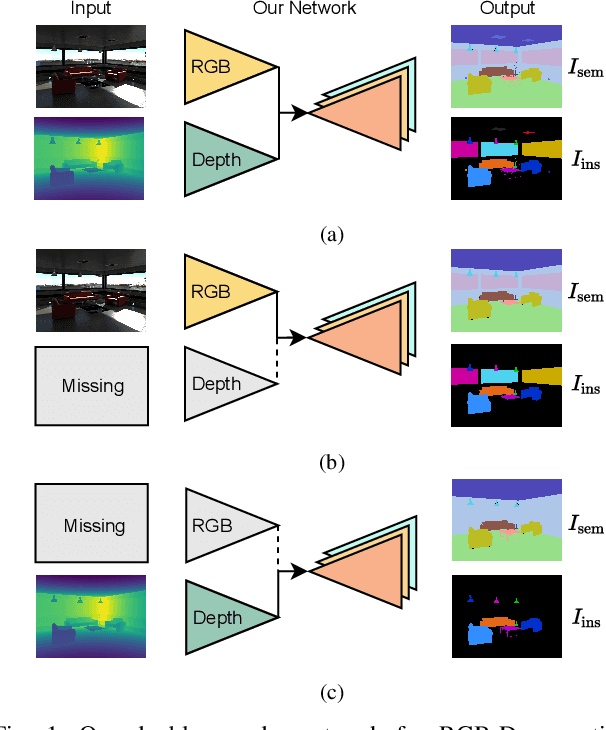
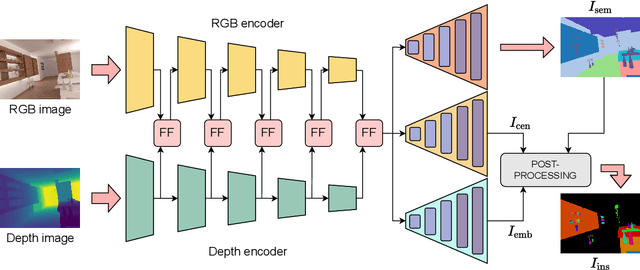
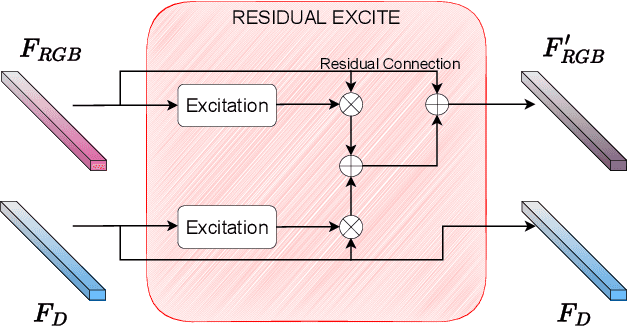

Perception is crucial for robots that act in real-world environments, as autonomous systems need to see and understand the world around them to act appropriately. Panoptic segmentation provides an interpretation of the scene by computing a pixel-wise semantic label together with instance IDs. In this paper, we address panoptic segmentation using RGB-D data of indoor scenes. We propose a novel encoder-decoder neural network that processes RGB and depth separately through two encoders. The features of the individual encoders are progressively merged at different resolutions, such that the RGB features are enhanced using complementary depth information. We propose a novel merging approach called ResidualExcite, which reweighs each entry of the feature map according to its importance. With our double-encoder architecture, we are robust to missing cues. In particular, the same model can train and infer on RGB-D, RGB-only, and depth-only input data, without the need to train specialized models. We evaluate our method on publicly available datasets and show that our approach achieves superior results compared to other common approaches for panoptic segmentation.
Self-supervised Human Mesh Recovery with Cross-Representation Alignment
Sep 10, 2022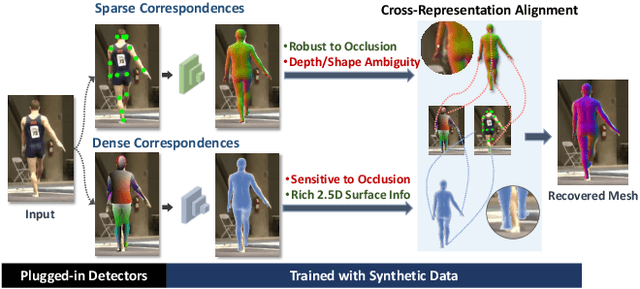
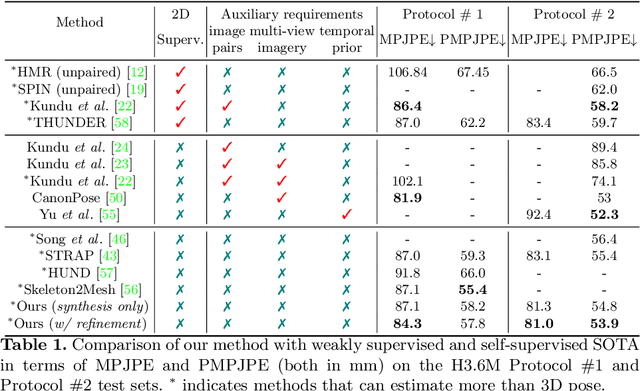
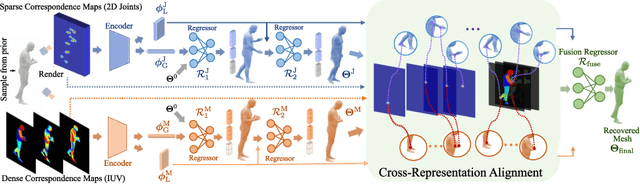
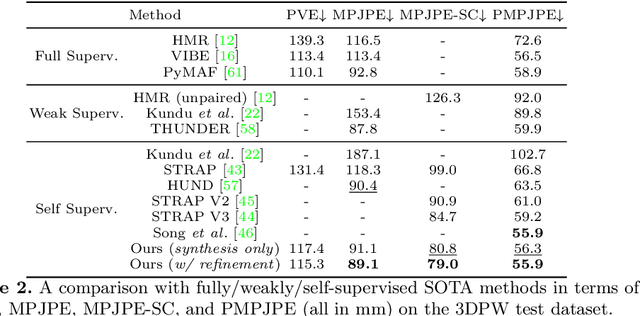
Fully supervised human mesh recovery methods are data-hungry and have poor generalizability due to the limited availability and diversity of 3D-annotated benchmark datasets. Recent progress in self-supervised human mesh recovery has been made using synthetic-data-driven training paradigms where the model is trained from synthetic paired 2D representation (e.g., 2D keypoints and segmentation masks) and 3D mesh. However, on synthetic dense correspondence maps (i.e., IUV) few have been explored since the domain gap between synthetic training data and real testing data is hard to address for 2D dense representation. To alleviate this domain gap on IUV, we propose cross-representation alignment utilizing the complementary information from the robust but sparse representation (2D keypoints). Specifically, the alignment errors between initial mesh estimation and both 2D representations are forwarded into regressor and dynamically corrected in the following mesh regression. This adaptive cross-representation alignment explicitly learns from the deviations and captures complementary information: robustness from sparse representation and richness from dense representation. We conduct extensive experiments on multiple standard benchmark datasets and demonstrate competitive results, helping take a step towards reducing the annotation effort needed to produce state-of-the-art models in human mesh estimation.
Mastering Spatial Graph Prediction of Road Networks
Oct 03, 2022
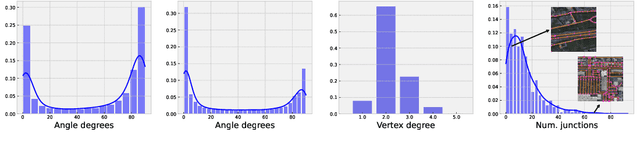
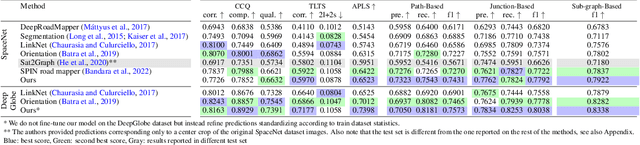
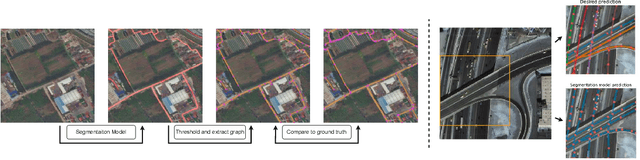
Accurately predicting road networks from satellite images requires a global understanding of the network topology. We propose to capture such high-level information by introducing a graph-based framework that simulates the addition of sequences of graph edges using a reinforcement learning (RL) approach. In particular, given a partially generated graph associated with a satellite image, an RL agent nominates modifications that maximize a cumulative reward. As opposed to standard supervised techniques that tend to be more restricted to commonly used surrogate losses, these rewards can be based on various complex, potentially non-continuous, metrics of interest. This yields more power and flexibility to encode problem-dependent knowledge. Empirical results on several benchmark datasets demonstrate enhanced performance and increased high-level reasoning about the graph topology when using a tree-based search. We further highlight the superiority of our approach under substantial occlusions by introducing a new synthetic benchmark dataset for this task.