 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CLIPping Privacy: Identity Inference Attacks on Multi-Modal Machine Learning Models
Sep 15, 2022
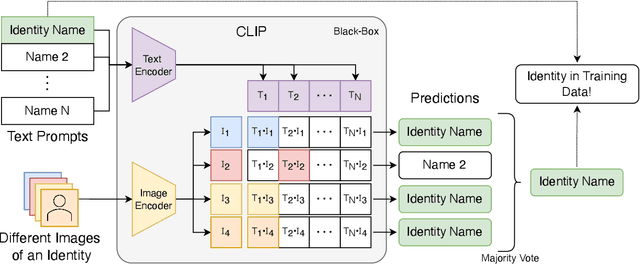
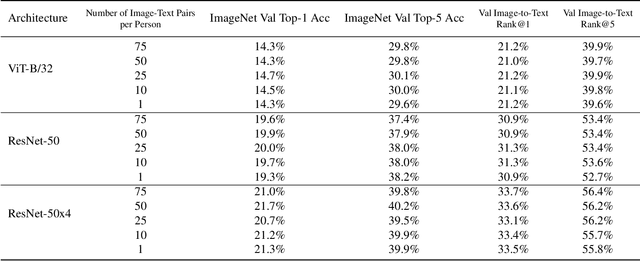


As deep learning is now used in many real-world applications, research has focused increasingly on the privacy of deep learning models and how to prevent attackers from obtaining sensitive information about the training data. However, image-text models like CLIP have not yet been looked at in the context of privacy attacks. While membership inference attacks aim to tell whether a specific data point was used for training, we introduce a new type of privacy attack, named identity inference attack (IDIA), designed for multi-modal image-text models like CLIP. Using IDIAs, an attacker can reveal whether a particular person, was part of the training data by querying the model in a black-box fashion with different images of the same person. Letting the model choose from a wide variety of possible text labels, the attacker can probe the model whether it recognizes the person and, therefore, was used for training. Through several experiments on CLIP, we show that the attacker can identify individuals used for training with very high accuracy and that the model learns to connect the names with the depicted people. Our experiments show that a multi-modal image-text model indeed leaks sensitive information about its training data and, therefore, should be handled with care.
Privacy-Preserving Deep Learning Model for Covid-19 Disease Detection
Sep 07, 2022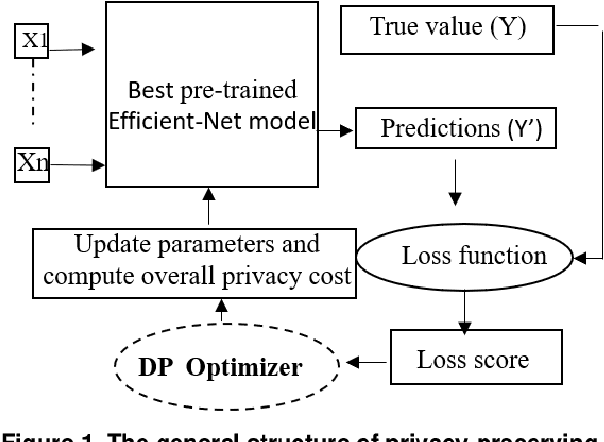
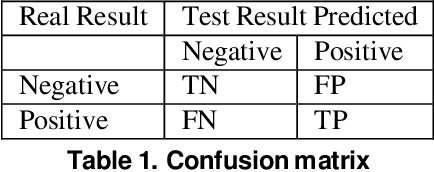
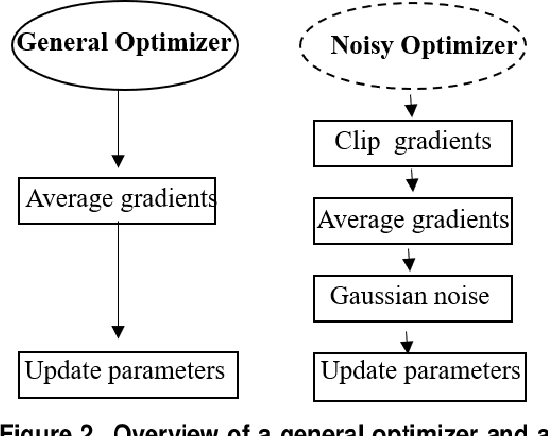
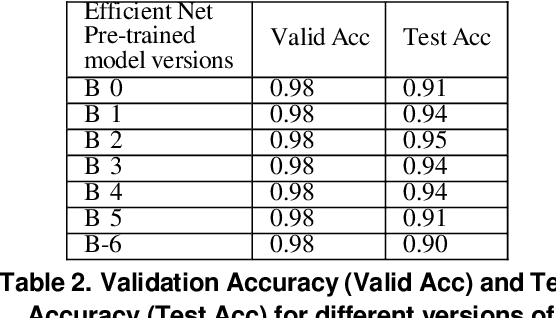
Recent studies demonstrated that X-ray radiography showed higher accuracy than Polymerase Chain Reaction (PCR) testing for COVID-19 detection. Therefore, applying deep learning models to X-rays and radiography images increases the speed and accuracy of determining COVID-19 cases. However, due to Health Insurance Portability and Accountability (HIPAA) compliance, the hospitals were unwilling to share patient data due to privacy concerns. To maintain privacy, we propose differential private deep learning models to secure the patients' private information. The dataset from the Kaggle website is used to evaluate the designed model for COVID-19 detection. The EfficientNet model version was selected according to its highest test accuracy. The injection of differential privacy constraints into the best-obtained model was made to evaluate performance. The accuracy is noted by varying the trainable layers, privacy loss, and limiting information from each sample. We obtained 84\% accuracy with a privacy loss of 10 during the fine-tuning process.
Streaming Encoding Algorithms for Scalable Hyperdimensional Computing
Sep 28, 2022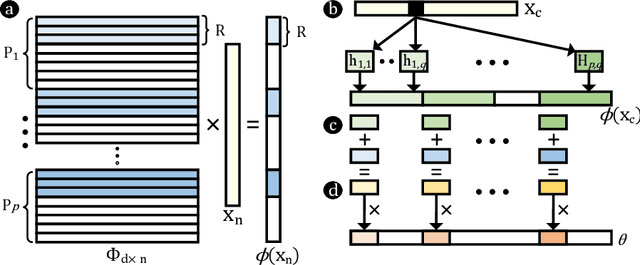


Hyperdimensional computing (HDC) is a paradigm for data representation and learning originating in computational neuroscience. HDC represents data as high-dimensional, low-precision vectors which can be used for a variety of information processing tasks like learning or recall. The mapping to high-dimensional space is a fundamental problem in HDC, and existing methods encounter scalability issues when the input data itself is high-dimensional. In this work, we explore a family of streaming encoding techniques based on hashing. We show formally that these methods enjoy comparable guarantees on performance for learning applications while being substantially more efficient than existing alternatives. We validate these results experimentally on a popular high-dimensional classification problem and show that our approach easily scales to very large data sets.
Learning to Occlusion-Robustly Estimate 3-D States of Deformable Linear Objects from Single-Frame Point Clouds
Oct 04, 2022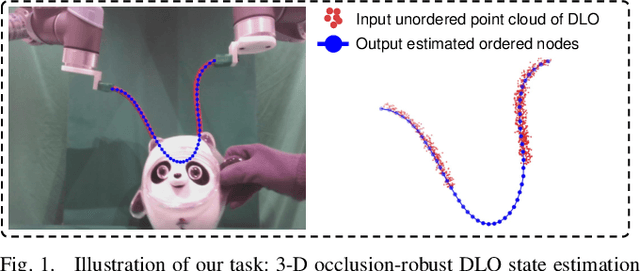
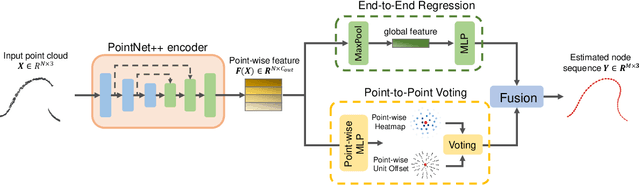
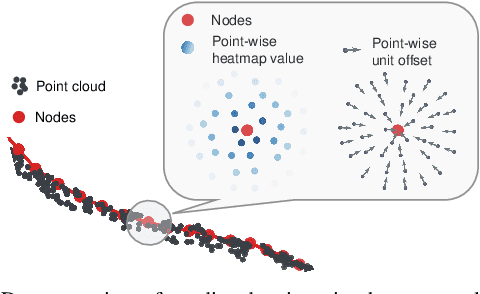
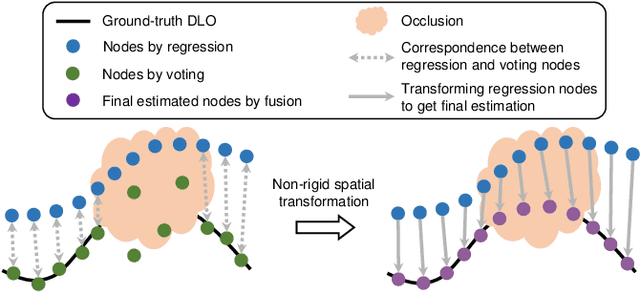
Accurately and robustly estimating the state of deformable linear objects (DLOs), such as ropes and wires, is crucial for DLO manipulation and other applications. However, it remains a challenging open issue due to the high dimensionality of the state space, frequent occlusion, and noises. This paper focuses on learning to robustly estimate the states of DLOs from single-frame point clouds in the presence of occlusions using a data-driven method. We propose a novel two-branch network architecture to exploit global and local information of input point cloud respectively and design a fusion module to effectively leverage both the advantages. Simulation and real-world experimental results demonstrate that our method can generate globally smooth and locally precise DLO state estimation results even with heavily occluded point clouds, which can be directly applied to real-world robotic manipulation of DLOs in 3-D space.
A Framework for Undergraduate Data Collection Strategies for Student Support Recommendation Systems in Higher Education
Oct 16, 2022
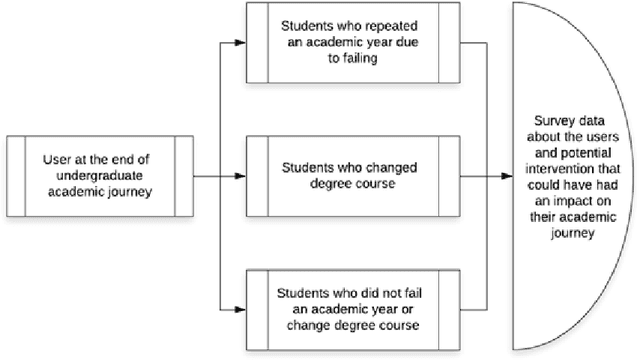
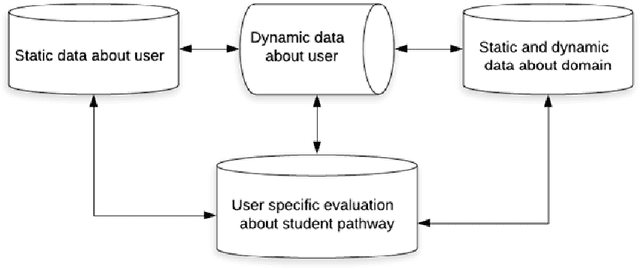
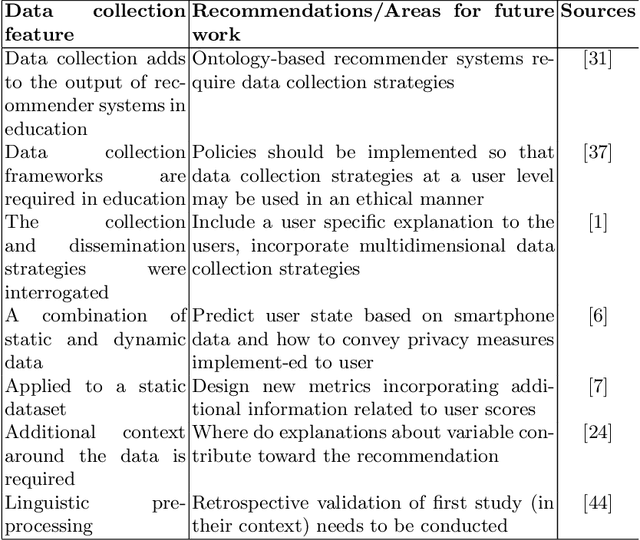
Understanding which student support strategies mitigate dropout and improve student retention is an important part of modern higher educational research. One of the largest challenges institutions of higher learning currently face is the scalability of student support. Part of this is due to the shortage of staff addressing the needs of students, and the subsequent referral pathways associated to provide timeous student support strategies. This is further complicated by the difficulty of these referrals, especially as students are often faced with a combination of administrative, academic, social, and socio-economic challenges. A possible solution to this problem can be a combination of student outcome predictions and applying algorithmic recommender systems within the context of higher education. While much effort and detail has gone into the expansion of explaining algorithmic decision making in this context, there is still a need to develop data collection strategies Therefore, the purpose of this paper is to outline a data collection framework specific to recommender systems within this context in order to reduce collection biases, understand student characteristics, and find an ideal way to infer optimal influences on the student journey. If confirmation biases, challenges in data sparsity and the type of information to collect from students are not addressed, it will have detrimental effects on attempts to assess and evaluate the effects of these systems within higher education.
Structure Information is the Key: Self-Attention RoI Feature Extractor in 3D Object Detection
Nov 15, 2021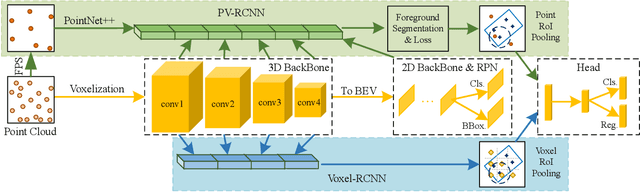
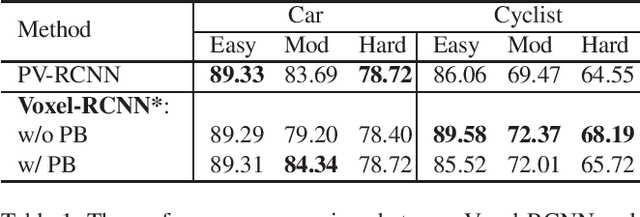

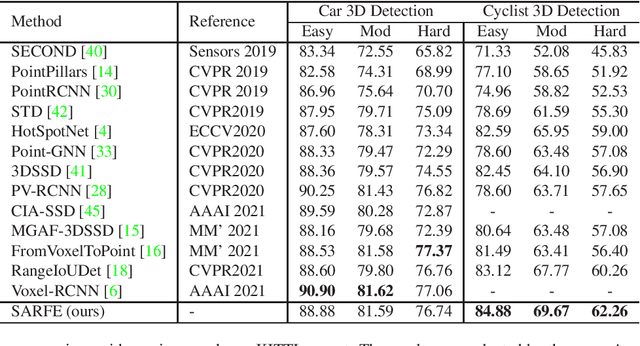
Unlike 2D object detection where all RoI features come from grid pixels, the RoI feature extraction of 3D point cloud object detection is more diverse. In this paper, we first compare and analyze the differences in structure and performance between the two state-of-the-art models PV-RCNN and Voxel-RCNN. Then, we find that the performance gap between the two models does not come from point information, but structural information. The voxel features contain more structural information because they do quantization instead of downsampling to point cloud so that they can contain basically the complete information of the whole point cloud. The stronger structural information in voxel features makes the detector have higher performance in our experiments even if the voxel features don't have accurate location information. Then, we propose that structural information is the key to 3D object detection. Based on the above conclusion, we propose a Self-Attention RoI Feature Extractor (SARFE) to enhance structural information of the feature extracted from 3D proposals. SARFE is a plug-and-play module that can be easily used on existing 3D detectors. Our SARFE is evaluated on both KITTI dataset and Waymo Open dataset. With the newly introduced SARFE, we improve the performance of the state-of-the-art 3D detectors by a large margin in cyclist on KITTI dataset while keeping real-time capability.
Exploiting Hybrid Semantics of Relation Paths for Multi-hop Question Answering Over Knowledge Graphs
Sep 02, 2022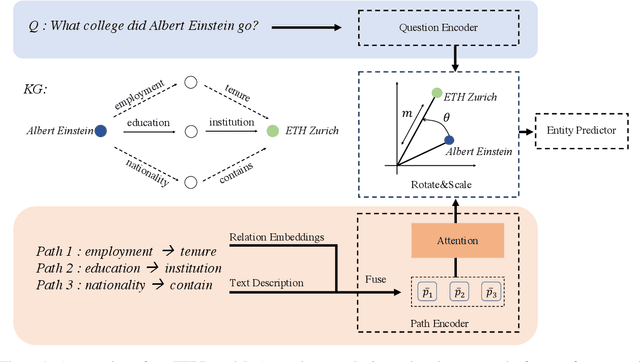
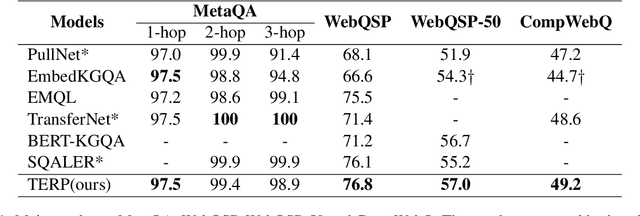
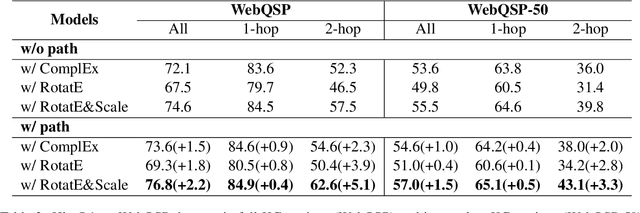
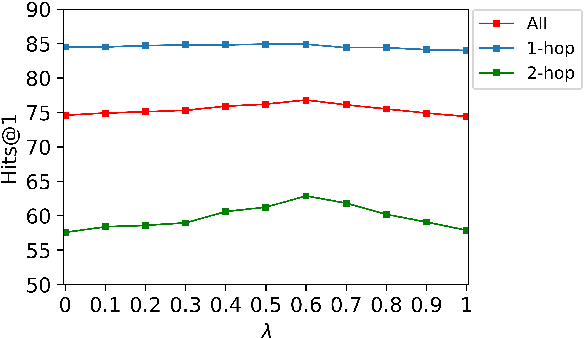
Answering natural language questions on knowledge graphs (KGQA) remains a great challenge in terms of understanding complex questions via multi-hop reasoning. Previous efforts usually exploit large-scale entity-related text corpora or knowledge graph (KG) embeddings as auxiliary information to facilitate answer selection. However, the rich semantics implied in off-the-shelf relation paths between entities is far from well explored. This paper proposes improving multi-hop KGQA by exploiting relation paths' hybrid semantics. Specifically, we integrate explicit textual information and implicit KG structural features of relation paths based on a novel rotate-and-scale entity link prediction framework. Extensive experiments on three existing KGQA datasets demonstrate the superiority of our method, especially in multi-hop scenarios. Further investigation confirms our method's systematical coordination between questions and relation paths to identify answer entities.
Industrial Data Science for Batch Manufacturing Processes
Sep 20, 2022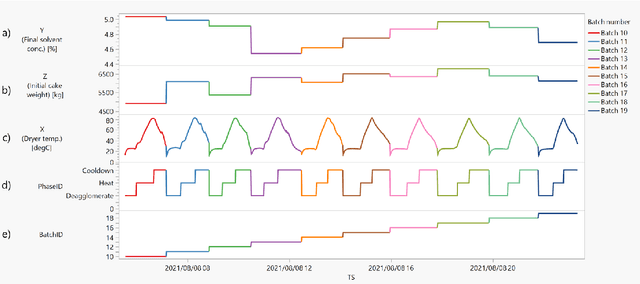

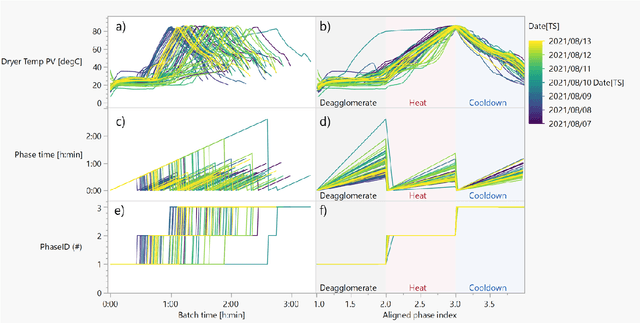
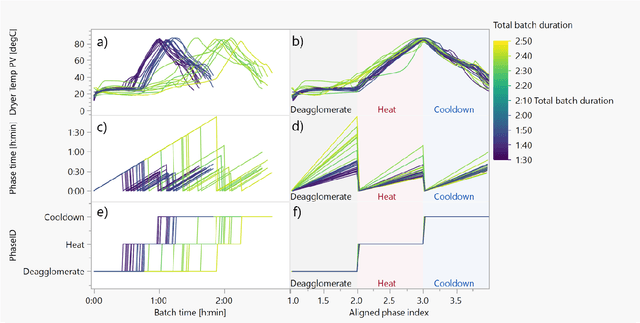
Batch processes show several sources of variability, from raw materials' properties to initial and evolving conditions that change during the different events in the manufacturing process. In this chapter, we will illustrate with an industrial example how to use machine learning to reduce this apparent excess of data while maintaining the relevant information for process engineers. Two common use cases will be presented: 1) AutoML analysis to quickly find correlations in batch process data, and 2) trajectory analysis to monitor and identify anomalous batches leading to process control improvements.
On the Ergodic Mutual Information of Keyhole MIMO Channels with Finite Inputs
Dec 10, 2021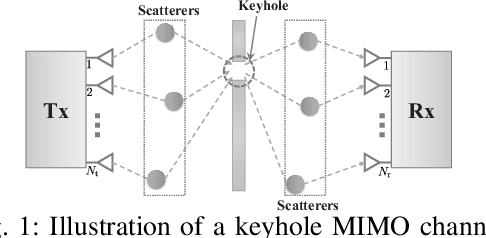
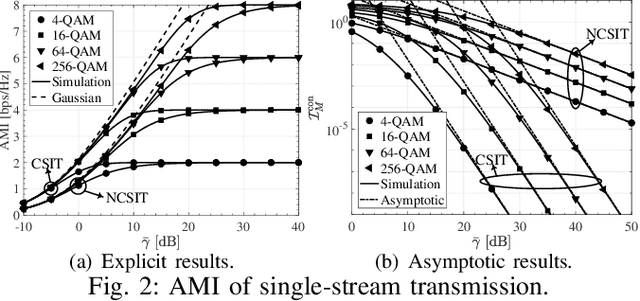
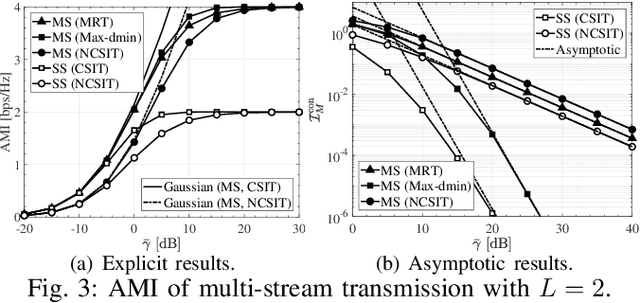
This letter studies the ergodic mutual information (EMI) of keyhole multiple-input multiple-output (MIMO) channels having finite input signals. At first, the EMI of single-stream transmission is investigated depending on whether the channel state information at the transmitter (CSIT) is available or not. Then, the derived results are extended to the case of multi-stream transmission. For the sake of providing more system insights, asymptotic analyses are performed in the regime of high signal-to-noise ratio (SNR), which suggests that the high-SNR EMI converges to some constant with its rate of convergence (ROC) determined by the diversity order. All the results are validated by numerical simulations and are in excellent agreement.
Optimal Phase Design for RIS Channel Estimation
Oct 18, 2022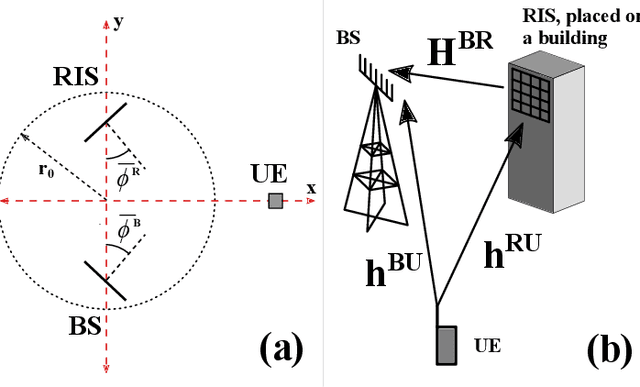
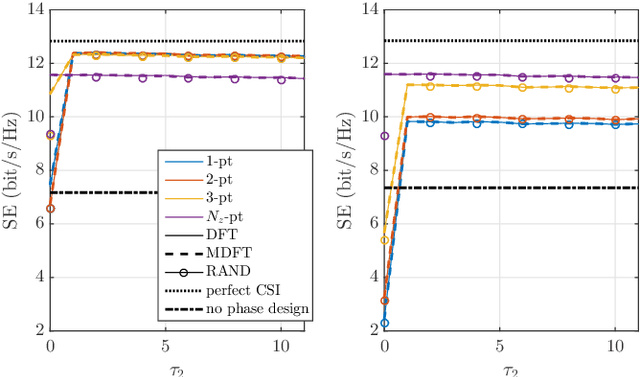
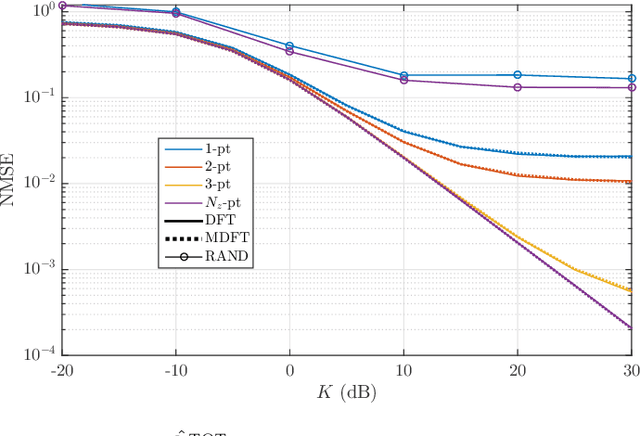
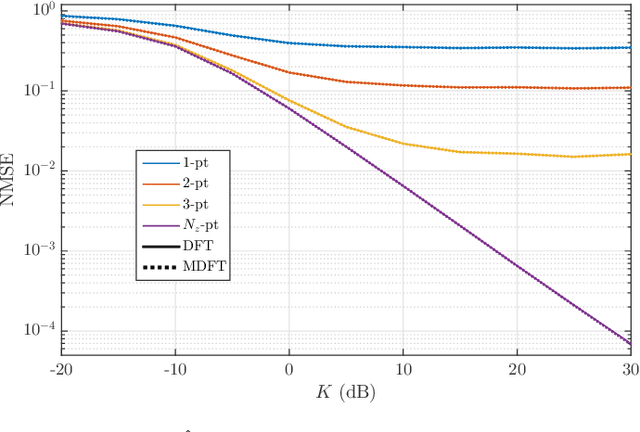
We develop an optimal version of a prior two-stage channel estimation protocol for RIS-assisted channels. The new design uses a modified DFT matrix (MDFT) for the training phases at the RIS and is shown to minimize the total channel estimation error variance. In conjunction with interpolation (estimating fewer RIS channels), the MDFT approach accelerates channel estimation even when the channel from base station to RIS is line-of-sight. In contrast, prior two-stage techniques required a full-rank channel for efficient estimation. We investigate the resulting channel estimation errors by comparing different training phase designs for a variety of propagation conditions using a ray-based channel model. To examine the overall performance, we simulate the spectral efficiency with MRC processing for a single-user RIS-assisted system using an existing optimal design for the RIS transmission phases. Results verify the optimality of MDFT while simulations and analysis show that the performance is more dependent on the user-to-RIS channel correlation and the coarseness of the interpolation used, rather than the training phase design. For example, under a scenario with more highly correlated channels, the procedure accelerates channel estimation by a factor of 16, while the improvement is a factor of 5 in a less correlated case. The overall procedure is extremely robust, with a maximum performance loss of 1.5bits/sec/Hz compared to that with perfect channel state information for the considered channel conditions.