 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Synthetic Tabular Data Generation Between a Probabilistic Model and a Deep Learning Model for Education Use Cases
Oct 16, 2022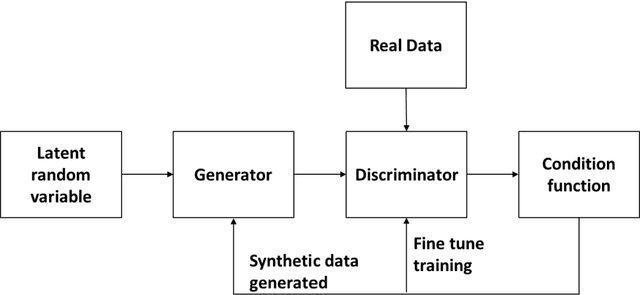
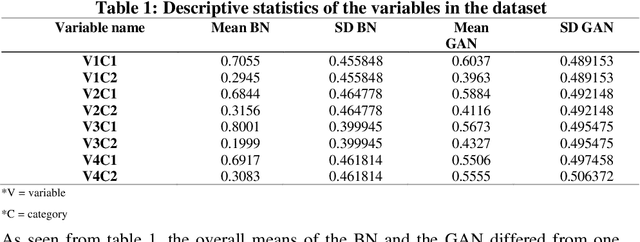

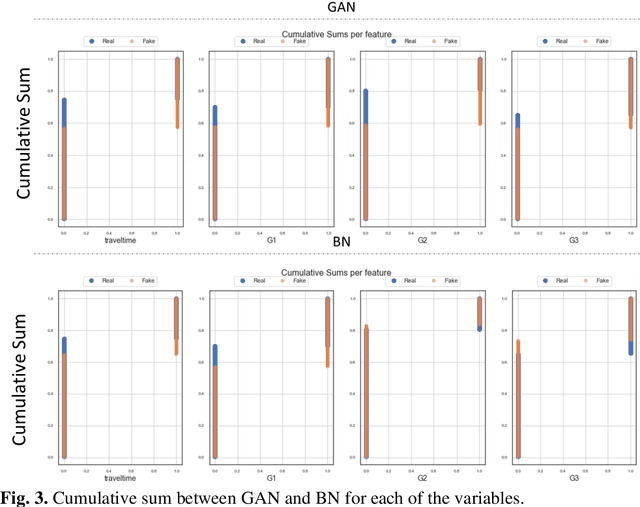
The ability to generate synthetic data has a variety of use cases across different domains. In education research, there is a growing need to have access to synthetic data to test certain concepts and ideas. In recent years, several deep learning architectures were used to aid in the generation of synthetic data but with varying results. In the education context, the sophistication of implementing different models requiring large datasets is becoming very important. This study aims to compare the application of synthetic tabular data generation between a probabilistic model specifically a Bayesian Network, and a deep learning model, specifically a Generative Adversarial Network using a classification task. The results of this study indicate that synthetic tabular data generation is better suited for the education context using probabilistic models (overall accuracy of 75%) than deep learning architecture (overall accuracy of 38%) because of probabilistic interdependence. Lastly, we recommend that other data types, should be explored and evaluated for their application in generating synthetic data for education use cases.
A Framework for Undergraduate Data Collection Strategies for Student Support Recommendation Systems in Higher Education
Oct 16, 2022
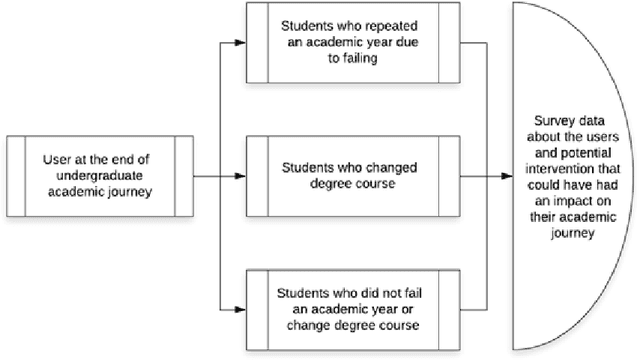
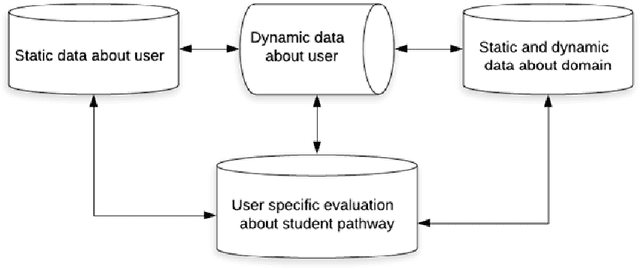
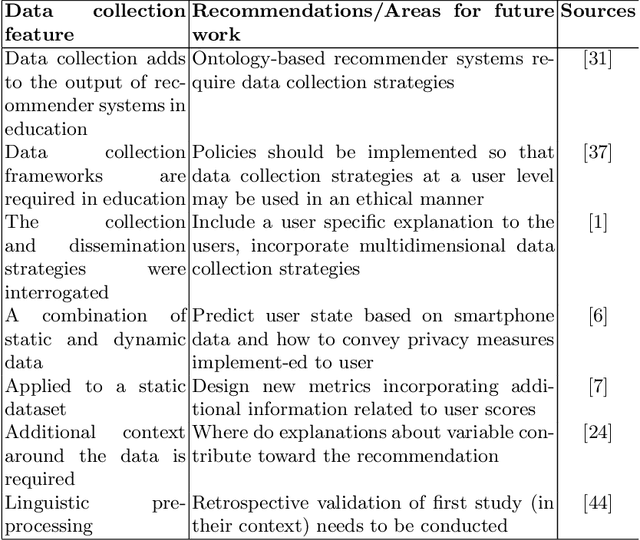
Understanding which student support strategies mitigate dropout and improve student retention is an important part of modern higher educational research. One of the largest challenges institutions of higher learning currently face is the scalability of student support. Part of this is due to the shortage of staff addressing the needs of students, and the subsequent referral pathways associated to provide timeous student support strategies. This is further complicated by the difficulty of these referrals, especially as students are often faced with a combination of administrative, academic, social, and socio-economic challenges. A possible solution to this problem can be a combination of student outcome predictions and applying algorithmic recommender systems within the context of higher education. While much effort and detail has gone into the expansion of explaining algorithmic decision making in this context, there is still a need to develop data collection strategies Therefore, the purpose of this paper is to outline a data collection framework specific to recommender systems within this context in order to reduce collection biases, understand student characteristics, and find an ideal way to infer optimal influences on the student journey. If confirmation biases, challenges in data sparsity and the type of information to collect from students are not addressed, it will have detrimental effects on attempts to assess and evaluate the effects of these systems within higher education.