 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Preregistered protocol for: Articulatory changes in speech following treatment for oral or oropharyngeal cancer: a systematic review
Sep 14, 2022


This document outlines a PROSPERO pre-registered protocol for a systematic review regarding articulatory changes in speech following oral or orophayrngeal cancer treatment. Treatment of tumours in the oral cavity may result in physiological changes that could lead to articulatory difficulties. The tongue becomes less mobile due to scar tissue and/or potential (postoperative) radiation therapy. Moreover, tissue loss may create a bypass for airflow or limit constriction possibilities. In order to gain a better understanding of the nature of the speech problems, information regarding the movement of the articulators is needed since perceptual or acoustic information provide only indirect evidence of articulatory changes. Therefore, this systematic review will review studies that directly measured the articulatory movements of the tongue, jaw, and lips following treatment for oral or oropharyngeal cancer.
Neuroevolution is a Competitive Alternative to Reinforcement Learning for Skill Discovery
Oct 06, 2022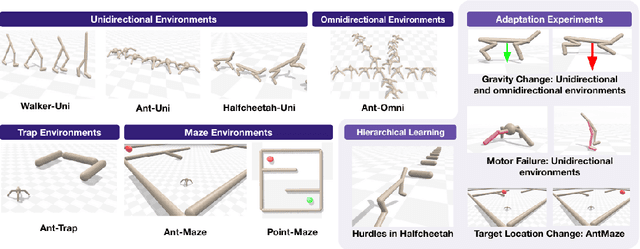
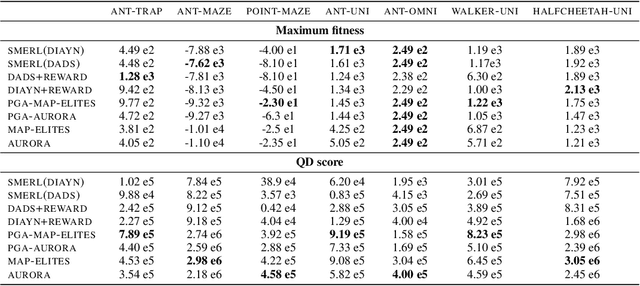
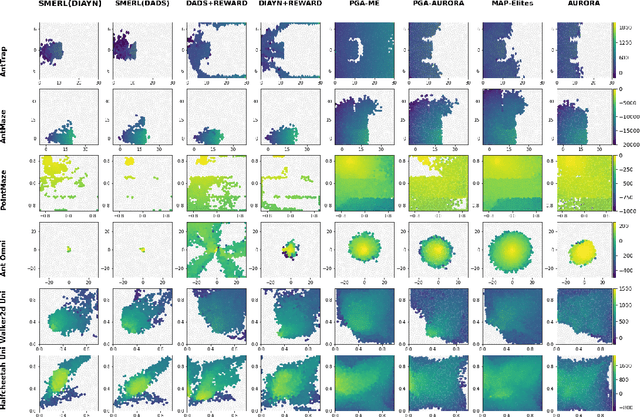
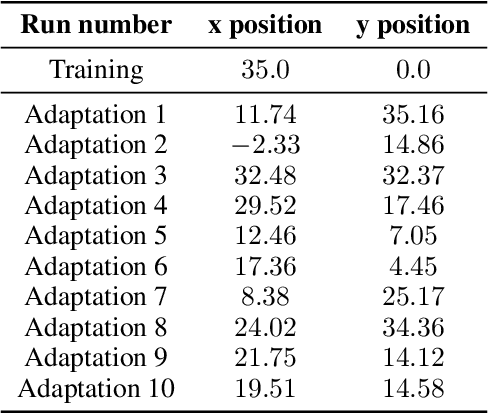
Deep Reinforcement Learning (RL) has emerged as a powerful paradigm for training neural policies to solve complex control tasks. However, these policies tend to be overfit to the exact specifications of the task and environment they were trained on, and thus do not perform well when conditions deviate slightly or when composed hierarchically to solve even more complex tasks. Recent work has shown that training a mixture of policies, as opposed to a single one, that are driven to explore different regions of the state-action space can address this shortcoming by generating a diverse set of behaviors, referred to as skills, that can be collectively used to great effect in adaptation tasks or for hierarchical planning. This is typically realized by including a diversity term - often derived from information theory - in the objective function optimized by RL. However these approaches often require careful hyperparameter tuning to be effective. In this work, we demonstrate that less widely-used neuroevolution methods, specifically Quality Diversity (QD), are a competitive alternative to information-theory-augmented RL for skill discovery. Through an extensive empirical evaluation comparing eight state-of-the-art methods on the basis of (i) metrics directly evaluating the skills' diversity, (ii) the skills' performance on adaptation tasks, and (iii) the skills' performance when used as primitives for hierarchical planning; QD methods are found to provide equal, and sometimes improved, performance whilst being less sensitive to hyperparameters and more scalable. As no single method is found to provide near-optimal performance across all environments, there is a rich scope for further research which we support by proposing future directions and providing optimized open-source implementations.
Label distribution learning via label correlation grid
Oct 15, 2022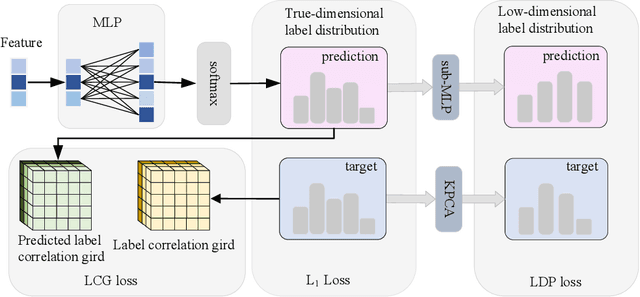
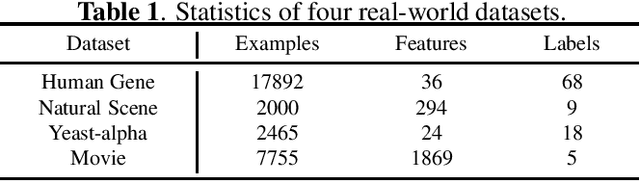
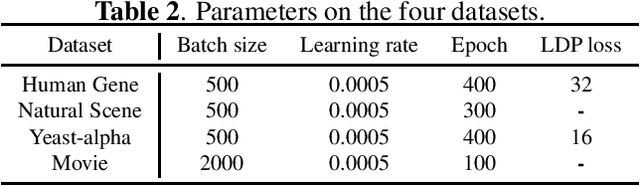
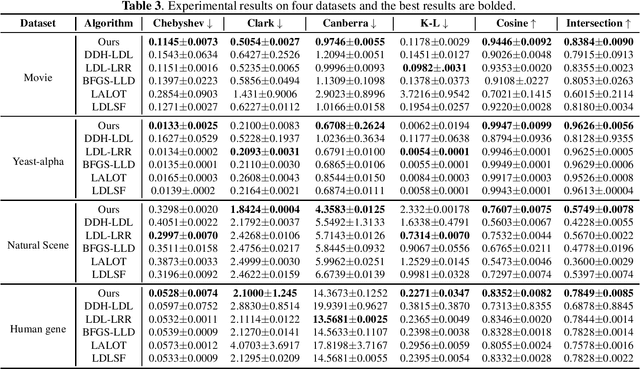
Label distribution learning can characterize the polysemy of an instance through label distributions. However, some noise and uncertainty may be introduced into the label space when processing label distribution data due to artificial or environmental factors. To alleviate this problem, we propose a \textbf{L}abel \textbf{C}orrelation \textbf{G}rid (LCG) to model the uncertainty of label relationships. Specifically, we compute a covariance matrix for the label space in the training set to represent the relationships between labels, then model the information distribution (Gaussian distribution function) for each element in the covariance matrix to obtain an LCG. Finally, our network learns the LCG to accurately estimate the label distribution for each instance. In addition, we propose a label distribution projection algorithm as a regularization term in the model training process. Extensive experiments verify the effectiveness of our method on several real benchmarks.
Fast OT for Latent Domain Adaptation
Oct 02, 2022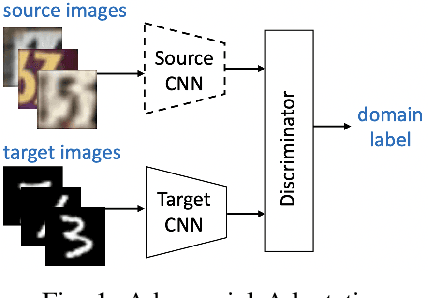
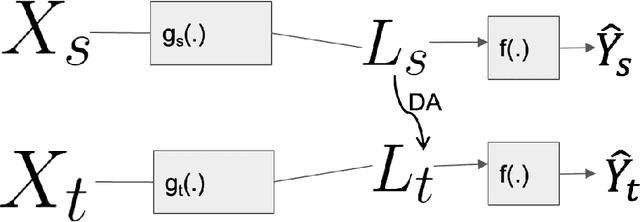
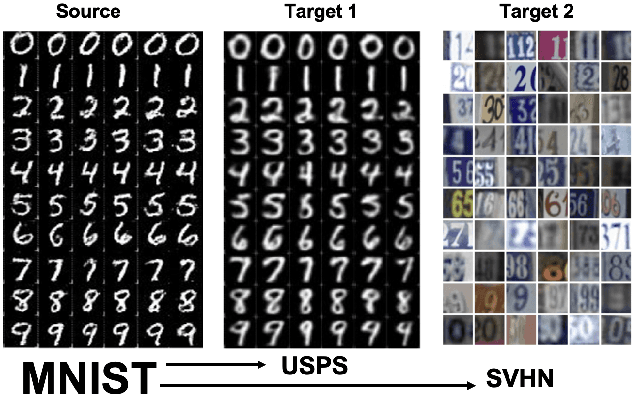
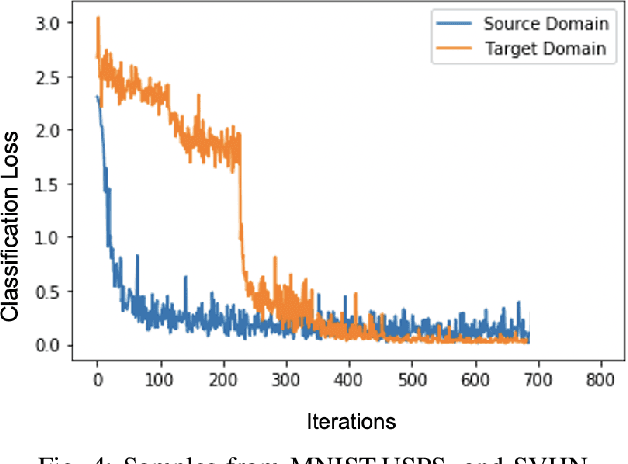
In this paper, we address the problem of unsupervised Domain Adaptation. The need for such an adaptation arises when the distribution of the target data differs from that which is used to develop the model and the ground truth information of the target data is unknown. We propose an algorithm that uses optimal transport theory with a verifiably efficient and implementable solution to learn the best latent feature representation. This is achieved by minimizing the cost of transporting the samples from the target domain to the distribution of the source domain.
DeepGraphONet: A Deep Graph Operator Network to Learn and Zero-shot Transfer the Dynamic Response of Networked Systems
Sep 21, 2022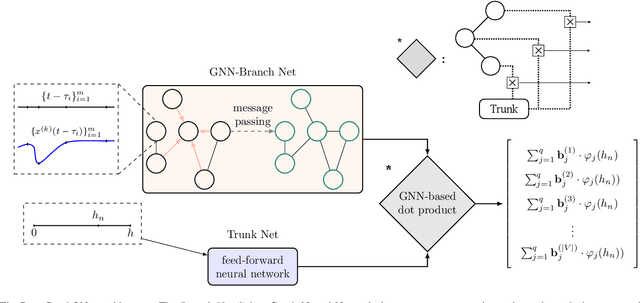
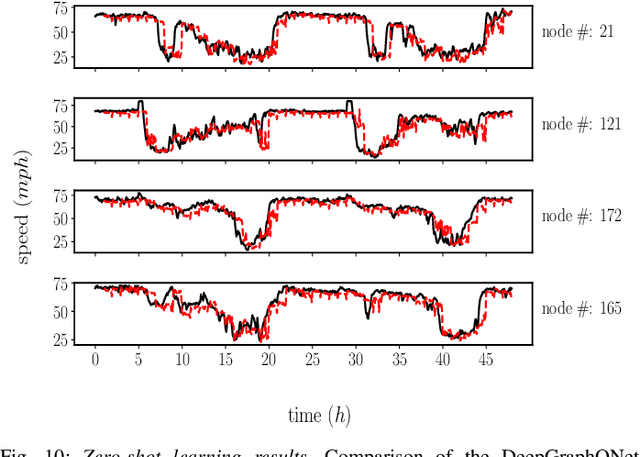
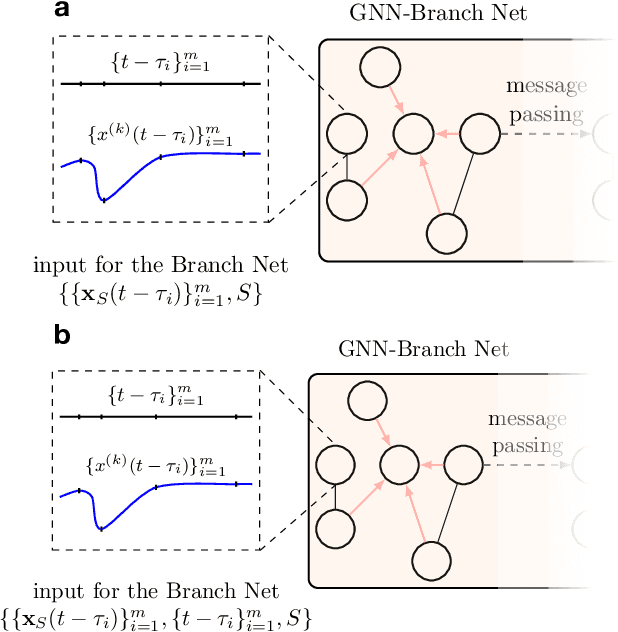
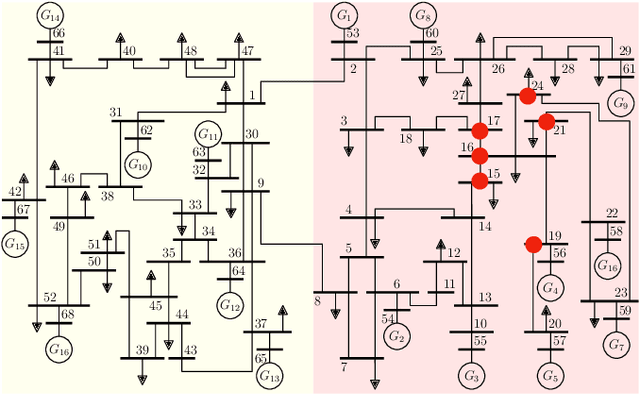
This paper develops a Deep Graph Operator Network (DeepGraphONet) framework that learns to approximate the dynamics of a complex system (e.g. the power grid or traffic) with an underlying sub-graph structure. We build our DeepGraphONet by fusing the ability of (i) Graph Neural Networks (GNN) to exploit spatially correlated graph information and (ii) Deep Operator Networks~(DeepONet) to approximate the solution operator of dynamical systems. The resulting DeepGraphONet can then predict the dynamics within a given short/medium-term time horizon by observing a finite history of the graph state information. Furthermore, we design our DeepGraphONet to be resolution-independent. That is, we do not require the finite history to be collected at the exact/same resolution. In addition, to disseminate the results from a trained DeepGraphONet, we design a zero-shot learning strategy that enables using it on a different sub-graph. Finally, empirical results on the (i) transient stability prediction problem of power grids and (ii) traffic flow forecasting problem of a vehicular system illustrate the effectiveness of the proposed DeepGraphONet.
COARSE3D: Class-Prototypes for Contrastive Learning in Weakly-Supervised 3D Point Cloud Segmentation
Oct 08, 2022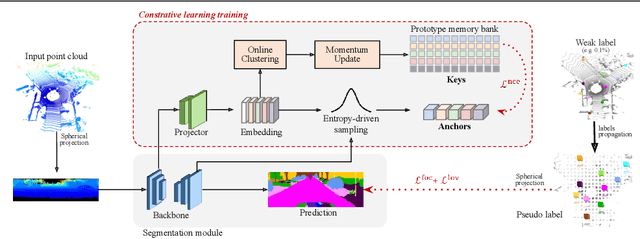
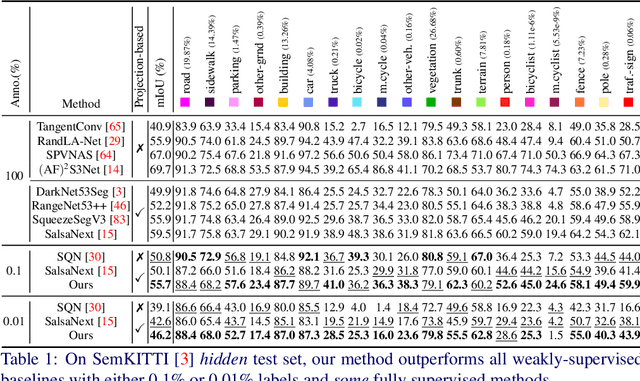
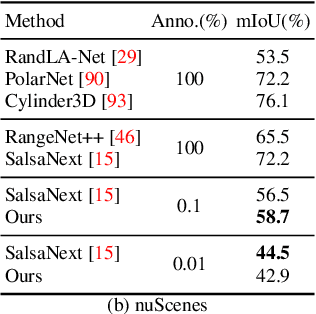
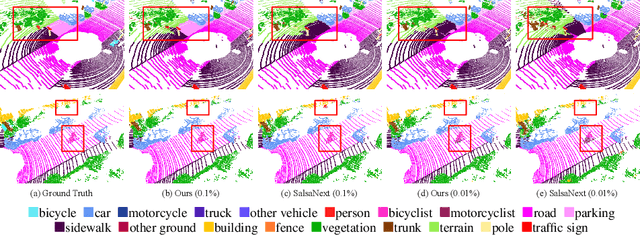
Annotation of large-scale 3D data is notoriously cumbersome and costly. As an alternative, weakly-supervised learning alleviates such a need by reducing the annotation by several order of magnitudes. We propose COARSE3D, a novel architecture-agnostic contrastive learning strategy for 3D segmentation. Since contrastive learning requires rich and diverse examples as keys and anchors, we leverage a prototype memory bank capturing class-wise global dataset information efficiently into a small number of prototypes acting as keys. An entropy-driven sampling technique then allows us to select good pixels from predictions as anchors. Experiments on three projection-based backbones show we outperform baselines on three challenging real-world outdoor datasets, working with as low as 0.001% annotations.
Learning Self-Supervised Representations from Vision and Touch for Active Sliding Perception of Deformable Surfaces
Sep 26, 2022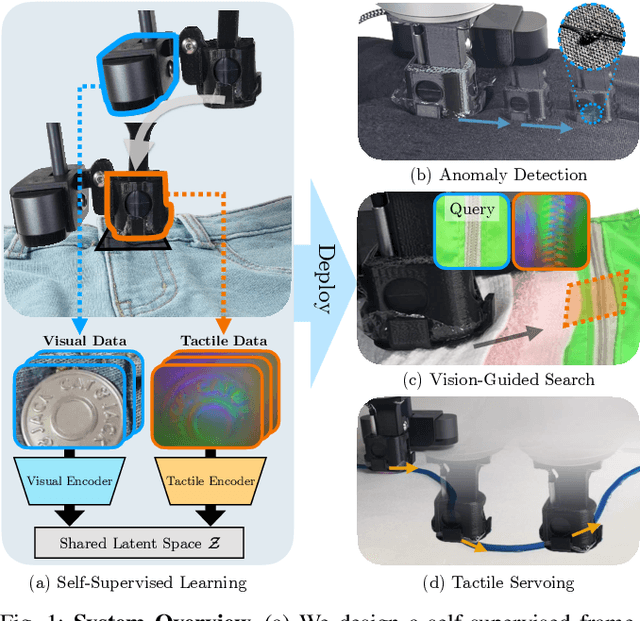
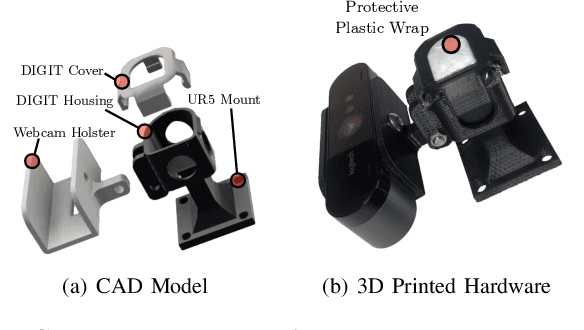

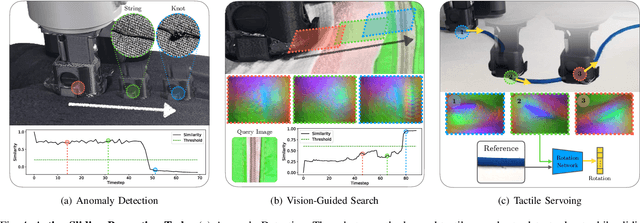
Humans make extensive use of vision and touch as complementary senses, with vision providing global information about the scene and touch measuring local information during manipulation without suffering from occlusions. In this work, we propose a novel framework for learning multi-task visuo-tactile representations in a self-supervised manner. We design a mechanism which enables a robot to autonomously collect spatially aligned visual and tactile data, a key property for downstream tasks. We then train visual and tactile encoders to embed these paired sensory inputs into a shared latent space using cross-modal contrastive loss. The learned representations are evaluated without fine-tuning on 5 perception and control tasks involving deformable surfaces: tactile classification, contact localization, anomaly detection (e.g., surgical phantom tumor palpation), tactile search from a visual query (e.g., garment feature localization under occlusion), and tactile servoing along cloth edges and cables. The learned representations achieve an 80% success rate on towel feature classification, a 73% average success rate on anomaly detection in surgical materials, a 100% average success rate on vision-guided tactile search, and 87.8% average servo distance along cables and garment seams. These results suggest the flexibility of the learned representations and pose a step toward task-agnostic visuo-tactile representation learning for robot control.
Learning based Age of Information Minimization in UAV-relayed IoT Networks
Mar 08, 2022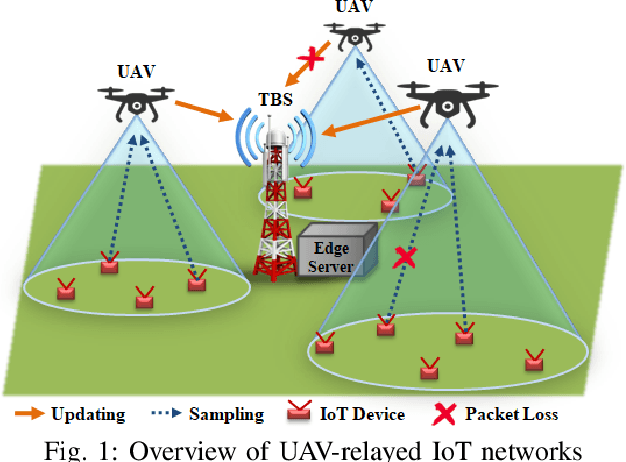
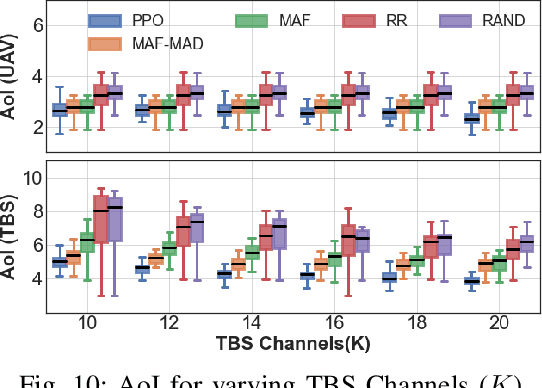
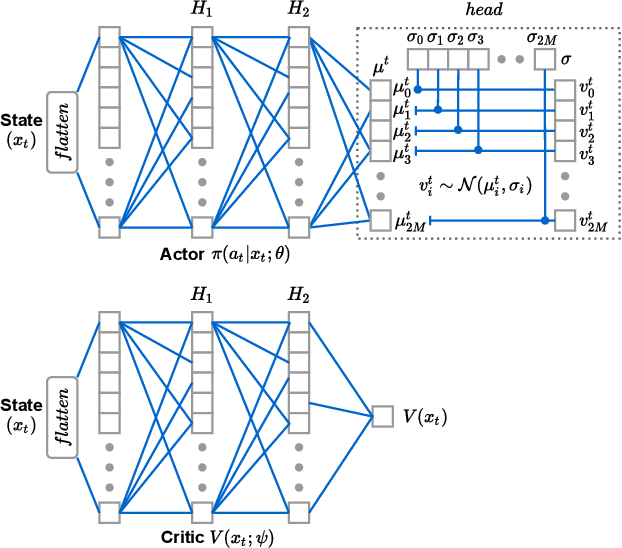
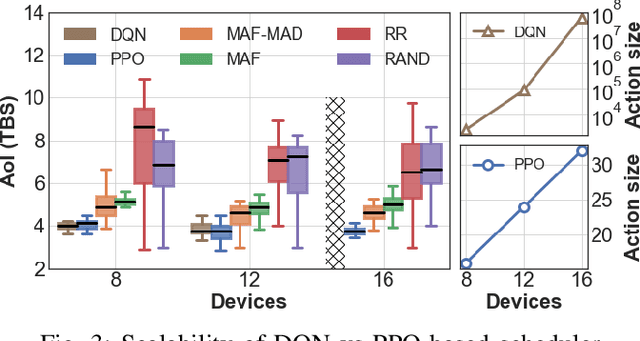
Unmanned Aerial Vehicles (UAVs) are used as aerial base-stations to relay time-sensitive packets from IoT devices to the nearby terrestrial base-station (TBS). Scheduling of packets in such UAV-relayed IoT-networks to ensure fresh (or up-to-date) IoT devices' packets at the TBS is a challenging problem as it involves two simultaneous steps of (i) sampling of packets generated at IoT devices by the UAVs [hop-1] and (ii) updating of sampled packets from UAVs to the TBS [hop-2]. To address this, we propose Age-of-Information (AoI) scheduling algorithms for two-hop UAV-relayed IoT-networks. First, we propose a low-complexity AoI scheduler, termed, MAF-MAD that employs Maximum AoI First (MAF) policy for sampling of IoT devices at UAV (hop-1) and Maximum AoI Difference (MAD) policy for updating sampled packets from UAV to the TBS (hop-2). We prove that MAF-MAD is the optimal AoI scheduler under ideal conditions (lossless wireless channels and generate-at-will traffic-generation at IoT devices). On the contrary, for general conditions (lossy channel conditions and varying periodic traffic-generation at IoT devices), a deep reinforcement learning algorithm, namely, Proximal Policy Optimization (PPO)-based scheduler is proposed. Simulation results show that the proposed PPO-based scheduler outperforms other schedulers like MAF-MAD, MAF, and round-robin in all considered general scenarios.
DBkWik++ -- Multi Source Matching of Knowledge Graphs
Oct 06, 2022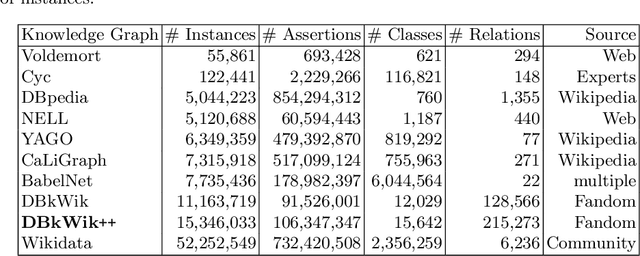
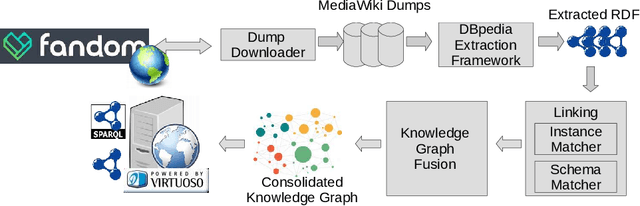
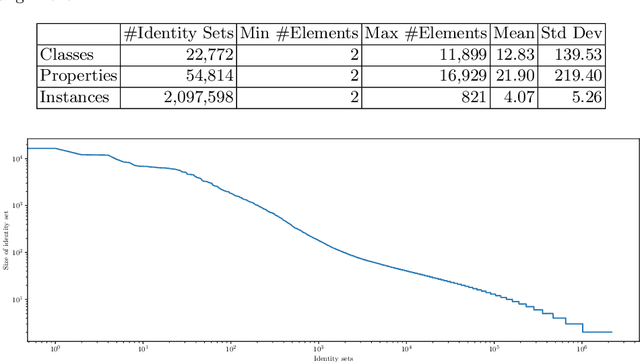
Large knowledge graphs like DBpedia and YAGO are always based on the same source, i.e., Wikipedia. But there are more wikis that contain information about long-tail entities such as wiki hosting platforms like Fandom. In this paper, we present the approach and analysis of DBkWik++, a fused Knowledge Graph from thousands of wikis. A modified version of the DBpedia framework is applied to each wiki which results in many isolated Knowledge Graphs. With an incremental merge based approach, we reuse one-to-one matching systems to solve the multi source KG matching task. Based on this alignment we create a consolidated knowledge graph with more than 15 million instances.
Monitoring and mapping of crop fields with UAV swarms based on information gain
Mar 22, 2022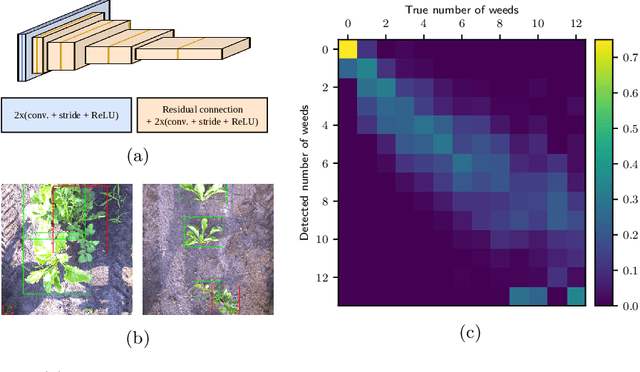
Monitoring crop fields to map features like weeds can be efficiently performed with unmanned aerial vehicles (UAVs) that can cover large areas in a short time due to their privileged perspective and motion speed. However, the need for high-resolution images for precise classification of features (e.g., detecting even the smallest weeds in the field) contrasts with the limited payload and ight time of current UAVs. Thus, it requires several flights to cover a large field uniformly. However, the assumption that the whole field must be observed with the same precision is unnecessary when features are heterogeneously distributed, like weeds appearing in patches over the field. In this case, an adaptive approach that focuses only on relevant areas can perform better, especially when multiple UAVs are employed simultaneously. Leveraging on a swarm-robotics approach, we propose a monitoring and mapping strategy that adaptively chooses the target areas based on the expected information gain, which measures the potential for uncertainty reduction due to further observations. The proposed strategy scales well with group size and leads to smaller mapping errors than optimal pre-planned monitoring approaches.