 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterfactual Reasoning for Fine-Grained Evidence Disentanglement in VideoQA
Jun 08, 2026Recent advances in video multimodal models have significantly improved VideoQA performance. However, these systems often rely on spurious statistical correlations rather than answer-relevant causal evidence, resulting in unfaithful and brittle reasoning, especially in complex real-world scenarios. Existing methods either rely on cross-modality correlations, costly curated training resources, or insufficient causal assumptions and constraints, and typically operate at the time-interval level. As a result, they fail to explicitly disentangle causal visual cues from confounders and provide limited fine-grained evidence localization. To address this issue, we propose a Counterfactual Reasoning framework for fine-grained Evidence Disentanglement (CREDiT). CREDiT formulates the VideoQA process using a structural causal model and learns cross-modality representations that are explicitly decomposed into causal and non-causal components under independence and minimality constraints. To facilitate faithful disentanglement, we introduce feature-level causal interventions and construct counterfactual inputs that approximate causal effects while suppressing non-causal correlations. Extensive experiments on NExT-GQA, SportsQA, and SPORTU-video demonstrate that CREDiT consistently improves answer accuracy and reasoning reliability across both generic and complex sports scenarios, leading to more trustworthy VideoQA systems.
KVNN: Learnable Multi-Kernel Volterra Neural Networks
Apr 16, 2026Higher-order learning is fundamentally rooted in exploiting compositional features. It clearly hinges on enriching the representation by more elaborate interactions of the data which, in turn, tends to increase the model complexity of conventional large-scale deep learning models. In this paper, a kernelized Volterra Neural Network (kVNN) is proposed. The key to the achieved efficiency lies in using a learnable multi-kernel representation, where different interaction orders are modeled by distinct polynomial-kernel components with compact, learnable centers, yielding an order-adaptive parameterization. Features are learned by the composition of layers, each of which consists of parallel branches of different polynomial orders, enabling kVNN filters to directly replace standard convolutional kernels within existing architectures. The theoretical results are substantiated by experiments on two representative tasks: video action recognition and image denoising. The results demonstrate favorable performance-efficiency trade-offs: kVNN consistently yields reduced model (parameters) and computational (GFLOPs) complexity with competitive and often improved performance. These results are maintained even when trained from scratch without large-scale pretraining. In summary, we substantiate that structured kernelized higher-order layers offer a practical path to balancing expressivity and computational cost in modern deep networks.
Proximal Vision Transformer: Enhancing Feature Representation through Two-Stage Manifold Geometry
Aug 23, 2025The Vision Transformer (ViT) architecture has become widely recognized in computer vision, leveraging its self-attention mechanism to achieve remarkable success across various tasks. Despite its strengths, ViT's optimization remains confined to modeling local relationships within individual images, limiting its ability to capture the global geometric relationships between data points. To address this limitation, this paper proposes a novel framework that integrates ViT with the proximal tools, enabling a unified geometric optimization approach to enhance feature representation and classification performance. In this framework, ViT constructs the tangent bundle of the manifold through its self-attention mechanism, where each attention head corresponds to a tangent space, offering geometric representations from diverse local perspectives. Proximal iterations are then introduced to define sections within the tangent bundle and project data from tangent spaces onto the base space, achieving global feature alignment and optimization. Experimental results confirm that the proposed method outperforms traditional ViT in terms of classification accuracy and data distribution.
Boosting Adversarial Robustness and Generalization with Structural Prior
Feb 02, 2025



This work investigates a novel approach to boost adversarial robustness and generalization by incorporating structural prior into the design of deep learning models. Specifically, our study surprisingly reveals that existing dictionary learning-inspired convolutional neural networks (CNNs) provide a false sense of security against adversarial attacks. To address this, we propose Elastic Dictionary Learning Networks (EDLNets), a novel ResNet architecture that significantly enhances adversarial robustness and generalization. This novel and effective approach is supported by a theoretical robustness analysis using influence functions. Moreover, extensive and reliable experiments demonstrate consistent and significant performance improvement on open robustness leaderboards such as RobustBench, surpassing state-of-the-art baselines. To the best of our knowledge, this is the first work to discover and validate that structural prior can reliably enhance deep learning robustness under strong adaptive attacks, unveiling a promising direction for future research.
Robustness Reprogramming for Representation Learning
Oct 06, 2024



This work tackles an intriguing and fundamental open challenge in representation learning: Given a well-trained deep learning model, can it be reprogrammed to enhance its robustness against adversarial or noisy input perturbations without altering its parameters? To explore this, we revisit the core feature transformation mechanism in representation learning and propose a novel non-linear robust pattern matching technique as a robust alternative. Furthermore, we introduce three model reprogramming paradigms to offer flexible control of robustness under different efficiency requirements. Comprehensive experiments and ablation studies across diverse learning models ranging from basic linear model and MLPs to shallow and modern deep ConvNets demonstrate the effectiveness of our approaches. This work not only opens a promising and orthogonal direction for improving adversarial defenses in deep learning beyond existing methods but also provides new insights into designing more resilient AI systems with robust statistics.
Accelerated Image-Aware Generative Diffusion Modeling
Aug 15, 2024We propose in this paper an analytically new construct of a diffusion model whose drift and diffusion parameters yield an exponentially time-decaying Signal to Noise Ratio in the forward process. In reverse, the construct cleverly carries out the learning of the diffusion coefficients on the structure of clean images using an autoencoder. The proposed methodology significantly accelerates the diffusion process, reducing the required diffusion time steps from around 1000 seen in conventional models to 200-500 without compromising image quality in the reverse-time diffusion. In a departure from conventional models which typically use time-consuming multiple runs, we introduce a parallel data-driven model to generate a reverse-time diffusion trajectory in a single run of the model. The resulting collective block-sequential generative model eliminates the need for MCMC-based sub-sampling correction for safeguarding and improving image quality, to further improve the acceleration of image generation. Collectively, these advancements yield a generative model that is an order of magnitude faster than conventional approaches, while maintaining high fidelity and diversity in generated images, hence promising widespread applicability in rapid image synthesis tasks.
Expansive Synthesis: Generating Large-Scale Datasets from Minimal Samples
Jun 25, 2024



The challenge of limited availability of data for training in machine learning arises in many applications and the impact on performance and generalization is serious. Traditional data augmentation methods aim to enhance training with a moderately sufficient data set. Generative models like Generative Adversarial Networks (GANs) often face problematic convergence when generating significant and diverse data samples. Diffusion models, though effective, still struggle with high computational cost and long training times. This paper introduces an innovative Expansive Synthesis model that generates large-scale, high-fidelity datasets from minimal samples. The proposed approach exploits expander graph mappings and feature interpolation to synthesize expanded datasets while preserving the intrinsic data distribution and feature structural relationships. The rationale of the model is rooted in the non-linear property of neural networks' latent space and in its capture by a Koopman operator to yield a linear space of features to facilitate the construction of larger and enriched consistent datasets starting with a much smaller dataset. This process is optimized by an autoencoder architecture enhanced with self-attention layers and further refined for distributional consistency by optimal transport. We validate our Expansive Synthesis by training classifiers on the generated datasets and comparing their performance to classifiers trained on larger, original datasets. Experimental results demonstrate that classifiers trained on synthesized data achieve performance metrics on par with those trained on full-scale datasets, showcasing the model's potential to effectively augment training data. This work represents a significant advancement in data generation, offering a robust solution to data scarcity and paving the way for enhanced data availability in machine learning applications.
Koopcon: A new approach towards smarter and less complex learning
May 22, 2024In the era of big data, the sheer volume and complexity of datasets pose significant challenges in machine learning, particularly in image processing tasks. This paper introduces an innovative Autoencoder-based Dataset Condensation Model backed by Koopman operator theory that effectively packs large datasets into compact, information-rich representations. Inspired by the predictive coding mechanisms of the human brain, our model leverages a novel approach to encode and reconstruct data, maintaining essential features and label distributions. The condensation process utilizes an autoencoder neural network architecture, coupled with Optimal Transport theory and Wasserstein distance, to minimize the distributional discrepancies between the original and synthesized datasets. We present a two-stage implementation strategy: first, condensing the large dataset into a smaller synthesized subset; second, evaluating the synthesized data by training a classifier and comparing its performance with a classifier trained on an equivalent subset of the original data. Our experimental results demonstrate that the classifiers trained on condensed data exhibit comparable performance to those trained on the original datasets, thus affirming the efficacy of our condensation model. This work not only contributes to the reduction of computational resources but also paves the way for efficient data handling in constrained environments, marking a significant step forward in data-efficient machine learning.
Implicit Bayes Adaptation: A Collaborative Transport Approach
Apr 17, 2023



The power and flexibility of Optimal Transport (OT) have pervaded a wide spectrum of problems, including recent Machine Learning challenges such as unsupervised domain adaptation. Its essence of quantitatively relating two probability distributions by some optimal metric, has been creatively exploited and shown to hold promise for many real-world data challenges. In a related theme in the present work, we posit that domain adaptation robustness is rooted in the intrinsic (latent) representations of the respective data, which are inherently lying in a non-linear submanifold embedded in a higher dimensional Euclidean space. We account for the geometric properties by refining the $l^2$ Euclidean metric to better reflect the geodesic distance between two distinct representations. We integrate a metric correction term as well as a prior cluster structure in the source data of the OT-driven adaptation. We show that this is tantamount to an implicit Bayesian framework, which we demonstrate to be viable for a more robust and better-performing approach to domain adaptation. Substantiating experiments are also included for validation purposes.
Fast OT for Latent Domain Adaptation
Oct 02, 2022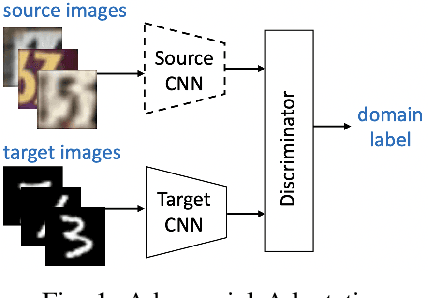
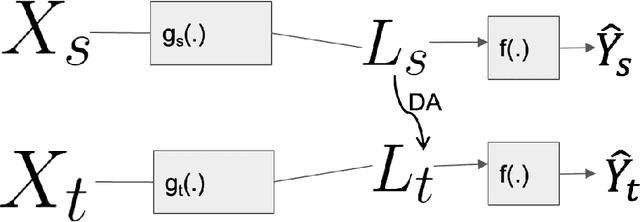
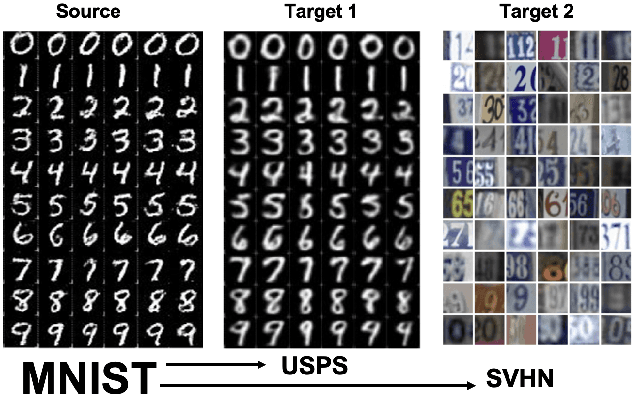
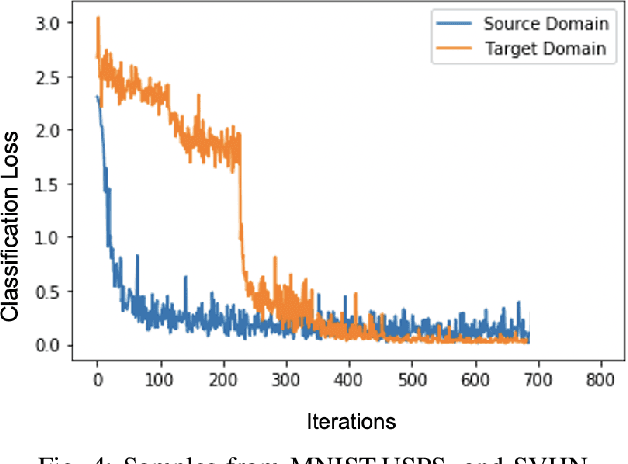
In this paper, we address the problem of unsupervised Domain Adaptation. The need for such an adaptation arises when the distribution of the target data differs from that which is used to develop the model and the ground truth information of the target data is unknown. We propose an algorithm that uses optimal transport theory with a verifiably efficient and implementable solution to learn the best latent feature representation. This is achieved by minimizing the cost of transporting the samples from the target domain to the distribution of the source domain.